Hudi cleaning-异步操作
发布时间:2023年12月17日
参数配置
设置参数,在建表的时候指定:
| 配置型 | 设定值 |
| hoodie.clean.automatic | false |
| hoodie.clean.async | true |
| hoodie.cleaner.commits.retained | 1 |
建表语句
create table small_file_hudi_cow (
id int,
name string,
age int,
city STRING,
date_str STRING
) using hudi
tblproperties (
type = 'cow',
primaryKey = 'id',
preCombineField = 'id',
'hoodie.clean.automatic' = 'false',
'hoodie.clean.async' = 'true',
'hoodie.cleaner.commits.retained' = '1'
)
partitioned by (date_str);操作执行计划
| 步骤 | 操作 | 文件系统 | 导入或者更新数据的命令 |
| 1 | insert | base file | INSERT INTO small_file_hudi_cow SELECT id, name, age, city, event_date FROM sample_data_partitioned where event_date='2023-11-03'; |
| 1 | update | base file | INSERT INTO small_file_hudi_cow SELECT id, name, age, city, event_date FROM sample_data_partitioned where event_date='2023-11-03'; |
| 1 | update | base file | INSERT INTO small_file_hudi_cow SELECT id, name, age, city, event_date FROM sample_data_partitioned where event_date='2023-11-03'; |
?第一步insert?
在第一次往表里面插入数据的时候,会产生第一个版本文件和时间记录信息,具体如下:

第二步 update数据
由于数据全量更新第一次的所有数据文件

第三步update?
由于全量更新第一次的所有数据文件,更新后添加对应的一组 file 信息。其文件信息及时间线如下:

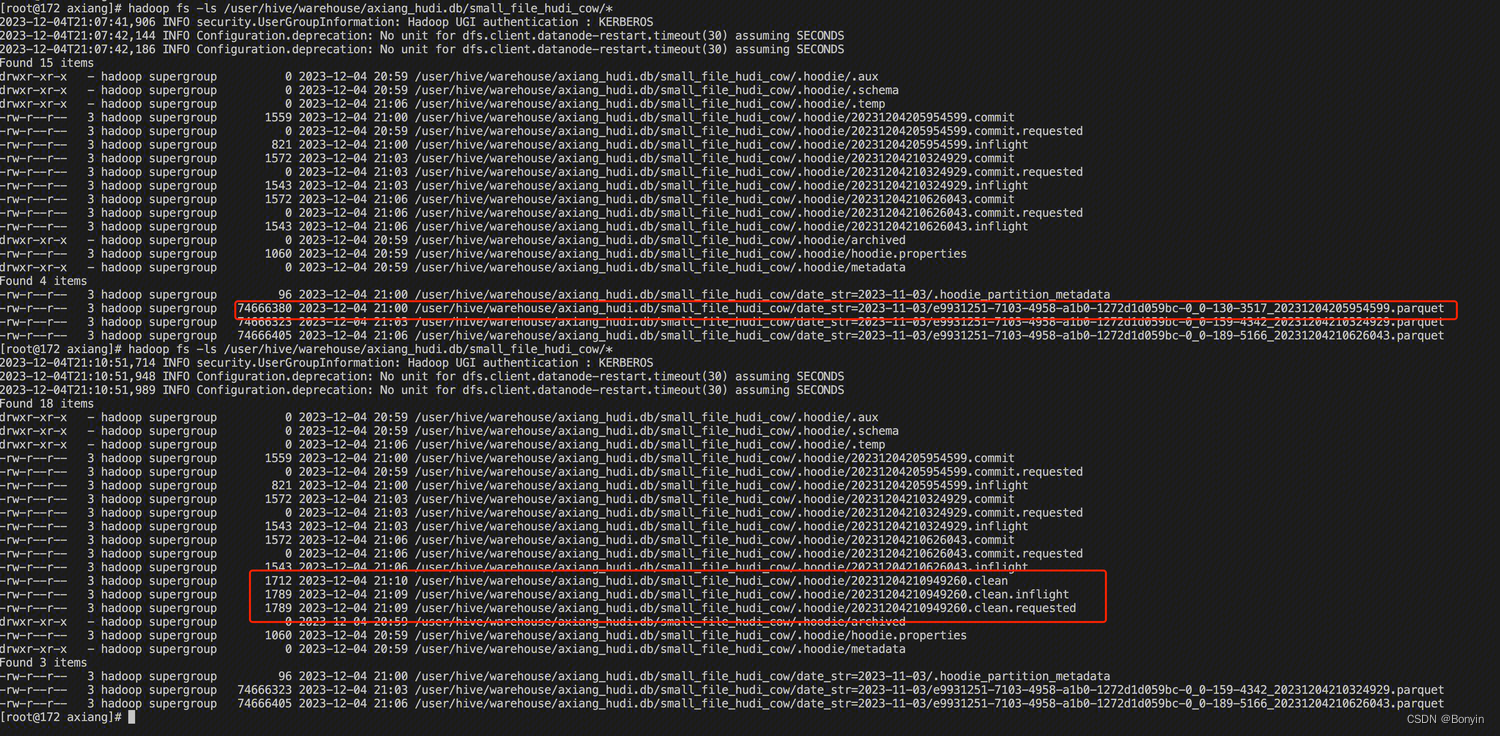
第四步?Cleaning
执行脚本:
spark-submit --class org.apache.hudi.utilities.HoodieCleaner /data/axiang/hudi-0.14.0/hudi-bundle/hudi-utilities-bundle_2.12-0.14.0.jar \
--target-base-path /user/hive/warehouse/axiang_hudi.db/small_file_hudi_cow/ \
--hoodie-conf hoodie.cleaner.policy=KEEP_LATEST_COMMITS \
--hoodie-conf hoodie.cleaner.commits.retained=1 \
--hoodie-conf hoodie.cleaner.parallelism=200 \
--hoodie-conf hoodie.clean.async=true \
--hoodie-conf hoodie.clean.automatic=false执行完成后,会生成一个clean 的时间线。同时删除历史版本的数据。其文件信息及时间线如下:
文章来源:https://blog.csdn.net/tryll/article/details/135047288
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【华为机试】2023年真题B卷(python)-工号不够用了怎么办
- 字节位移运算学习笔记
- Java中XML解析的方式介绍和实现
- 共享中药房新突破:亿发打造专业调度与强兼容性的智慧煎药平台
- Python从入门到精通 第六章(函数和代码复用)
- 基于智能手机的行人惯性追踪数据集模型与部署
- 小白数学建模 Mathtype 7.7傻瓜式下载安装嵌入Word/WPS以及深度使用教程
- Arthas
- Leetcode—216.组合总和III【中等】
- PHP代码审计之反序列化攻击链CVE-2019-6340漏洞研究