k8s的网络类型
部署 CNI 网络组件
部署 flannel
K8S 中 Pod 网络通信:
●Pod 内容器与容器之间的通信
在同一个 Pod 内的容器(Pod 内的容器是不会跨宿主机的)共享同一个网络命名空间,
相当于它们在同一台机器上一样,可以用 localhost 地址访问彼此的端口。
●同一个 Node 内 Pod 之间的通信
每个 Pod 都有一个真实的全局 IP 地址,同一个 Node 内的不同 Pod 之间可以直接采用对方 Pod 的 IP 地址进行通信,
Pod1 与 Pod2 都是通过 Veth 连接到同一个 docker0/cni0 网桥,网段相同,所以它们之间可以直接通信。
●不同 Node 上 Pod 之间的通信
Pod 地址与 docker0 在同一网段,docker0 网段与宿主机网卡是两个不同的网段,且不同 Node 之间的
通信只能通过宿主机的物理网卡进行。
要想实现不同 Node 上 Pod 之间的通信,就必须想办法通过主机的物理网卡 IP 地址进行寻址和通信。
因此要满足两个条件:Pod 的 IP 不能冲突;将 Pod 的 IP 和所在的 Node 的 IP 关联起来,
通过这个关联让不同 Node 上 Pod 之间直接通过内网 IP 地址通信。
Overlay Network:
叠加网络,在二层或者三层基础网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来。
通过Overlay技术(可以理解成隧道技术),在原始报文外再包一层四层协议(UDP协议),
通过主机网络进行路由转发。这种方式性能有一定损耗,主要体现在对原始报文的修改。目前Overlay主要采用VXLAN。
VXLAN:
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,
到达目的地后由隧道端点解封装并将数据发送给目标地址。
Flannel:
Flannel 的功能是让集群中的不同节点主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址。
Flannel 是 Overlay 网络的一种,也是将 TCP 源数据包封装在另一种网络包里面进行路由转发和通信,
目前支持 UDP、VXLAN、Host-gw 3种数据转发方式。
#Flannel UDP 模式的工作原理:
数据从主机 A 上 Pod 的源容器中发出后,经由所在主机的 docker0/cni0 网络接口转发到 flannel0 接口,
flanneld 服务监听在 flannel0 虚拟网卡的另外一端。
Flannel 通过 Etcd 服务维护了一张节点间的路由表。源主机 A 的 flanneld 服务将原本的数据内容封装到?
UDP 报文中, 根据自己的路由表通过物理网卡投递给目的节点主机 B 的 flanneld 服务,数据到达以后被解包,
然后直接进入目的节点的 flannel0 接口, 之后被转发到目的主机的 docker0/cni0 网桥,
最后就像本机容器通信一样由 docker0/cni0 转发到目标容器。
#ETCD 之 Flannel 提供说明:
存储管理Flannel可分配的IP地址段资源
监控 ETCD 中每个 Pod 的实际地址,并在内存中建立维护 Pod 节点路由表
由于 UDP 模式是在用户态做转发,会多一次报文隧道封装,因此性能上会比在内核态做转发的 VXLAN 模式差。
#VXLAN 模式:
VXLAN 模式使用比较简单,flannel 会在各节点生成一个 flannel.1 的?
VXLAN 网卡(VTEP设备,负责 VXLAN 封装和解封装)。
VXLAN 模式下封包与解包的工作是由内核进行的。flannel 不转发数据,仅动态设置 ARP 表和 MAC 表项。
UDP 模式的 flannel0 网卡是三层转发,使用 flannel0 时在物理网络之上构建三层网络,属于 ip in udp ;
VXLAN 模式是二层实现,overlay 是数据帧,属于 mac in udp 。
#Flannel VXLAN 模式跨主机的工作原理:
1、数据帧从主机 A 上 Pod 的源容器中发出后,经由所在主机的 docker0/cni0 网络接口转发到 flannel.1 接口
2、flannel.1 收到数据帧后添加 VXLAN 头部,封装在 UDP 报文中
3、主机 A 通过物理网卡发送封包到主机 B 的物理网卡中
4、主机 B 的物理网卡再通过 VXLAN 默认端口 4789 转发到 flannel.1 接口进行解封装
5、解封装以后,内核将数据帧发送到 cni0,最后由 cni0 发送到桥接到此接口的容器 B 中。
//在 node01 节点上操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tar
mkdir -p /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin//在 master01 节点上操作
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
kubectl apply -f kube-flannel.yml?
kubectl get pods -n kube-system
NAME ? ? ? ? ? ? ? ? ? ?READY ? STATUS ? ?RESTARTS ? AGE
kube-flannel-ds-hjtc7 ? 1/1 ? ? Running ? 0 ? ? ? ? ?7s
?部署 Calico
#k8s 组网方案对比:
●flannel方案
需要在每个节点上把发向容器的数据包进行封装后,
再用隧道将封装后的数据包发送到运行着目标Pod的node节点上。
目标node节点再负责去掉封装,将去除封装的数据包发送到目标Pod上。数据通信性能则大受影响。
●calico方案
Calico不使用隧道或NAT来实现转发,而是把Host当作Internet中的路由器,使用BGP同步路由,并使用iptables来做安全访问策略,完成跨Host转发。
采用直接路由的方式,这种方式性能损耗最低,不需要修改报文数据,但是如果网络比较复杂场景下,
路由表会很复杂,对运维同事提出了较高的要求。
#Calico 主要由三个部分组成:
Calico CNI插件:主要负责与kubernetes对接,供kubelet调用使用。
Felix:负责维护宿主机上的路由规则、FIB转发信息库等。
BIRD:负责分发路由规则,类似路由器。
Confd:配置管理组件。
#Calico 工作原理:
Calico 是通过路由表来维护每个 pod 的通信。Calico 的 CNI 插件会为每个容器设置一个 veth pair 设备, 然后把另一端接入到宿主机网络空间,由于没有网桥,CNI 插件还需要在宿主机上为每个容器的 veth pair 设备配置一条路由规则, 用于接收传入的 IP 包。
有了这样的 veth pair 设备以后,容器发出的 IP 包就会通过 veth pair 设备到达宿主机,然后宿主机根据路由规则的下一跳地址, 发送给正确的网关,然后到达目标宿主机,再到达目标容器。
这些路由规则都是 Felix 维护配置的,而路由信息则是 Calico BIRD 组件基于 BGP 分发而来。
calico 实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过 BGP 交换路由, 这些节点我们叫做 BGP Peer。
目前比较常用的CNI网络组件是flannel和calico,flannel的功能比较简单,
不具备复杂的网络策略配置能力,calico是比较出色的网络管理插件,
但具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,
所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,
未来网络可能需要加入更多设备,配置更多网络策略,则使用calico更好。
//在 master01 节点上操作
#上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
vim calico.yaml
#修改里面定义 Pod 的网络(CALICO_IPV4POOL_CIDR),需与前面 kube-controller-manager 配置文件指定的 cluster-cidr 网段一样
? ? - name: CALICO_IPV4POOL_CIDR
? ? ? value: "10.244.0.0/16" ? ? ? ?#Calico 默认使用的网段为 192.168.0.0/16
kubectl apply -f calico.yamlkubectl get pods -n kube-system
---------- node02 节点部署 ----------
//在 master02?节点上操作
cd /opt/
scp kubelet.sh proxy.sh root@192.168.10.30:/opt/
scp kubelet.sh proxy.sh root@192.168.10.40:/opt/
scp -r /opt/cni root@192.168.10.30:/opt/
scp -r /opt/cni root@192.168.10.40:/opt/
//在 node02 节点上操作
#启动kubelet服务
cd /opt/
chmod +x kubelet.sh
./kubelet.sh 192.168.10.40//在 master01 节点上操作
kubectl get csr#通过 CSR 请求
kubectl certificate approve??NAME#加载 ipvs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done#使用proxy.sh脚本启动proxy服务
cd /opt/
chmod +x proxy.sh
./proxy.sh 192.168.10.40#查看群集中的节点状态
kubectl get nodes
部署 CoreDNS
CoreDNS:可以为集群中的 service 资源创建一个域名与 IP 的对应关系解析。
service发现是k8s中的一个重要机制,其基本功能为:在集群内通过服务名对服务进行访问,
即需要完成从服务名到ClusterIP的解析。
k8s主要有两种service发现机制:环境变量和DNS。没有DNS服务的时候,k8s会采用环境变量的形式,
但一旦有多个service,环境变量会变复杂,为解决该问题,我们使用DNS服务。
CoreDNS 是一个用于 Kubernetes 集群的灵活的 DNS 服务器。它为集群中的服务资源提供域名解析,
使得可以通过域名来访问 Kubernetes 集群中的服务。
在 Kubernetes 中,每个 Service 都被分配一个 Cluster IP(Cluster IP 是 Service 的虚拟 IP 地址)。
CoreDNS 可以为这些 Cluster IP 分配域名,并提供 DNS 解析服务。通过 CoreDNS,你可以通过服务名称来访问服务,
而不必使用具体的 Cluster IP 地址。这对于在集群中进行服务发现和通信非常有用。
//在所有 node 节点上操作
#上传 coredns.tar 到 /opt 目录中
cd /opt
docker load -i coredns.tar//在 master01 节点上操作
#上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS?
cd /opt/k8s
kubectl apply -f coredns.yaml
kubectl get pods -n kube-system?#DNS 解析测试
kubectl create clusterrolebinding cluster-system-anonymous --clusterrole=cluster-admin --user=system:anonymous
kubectl run -it --rm dns-test --image=busybox:1.28.4 sh
/ # nslookup kubernetesmaster02 节点部署?
//从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点
scp -r /opt/etcd/ root@192.168.10.20:/opt/
scp -r /opt/kubernetes/ root@192.168.10.20:/opt
scp -r /root/.kube root@192.168.10.20:/root
scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service root@192.168.10.20:/usr/lib/systemd/system///修改配置文件kube-apiserver中的IP
vim /opt/kubernetes/cfg/kube-apiserver
KUBE_APISERVER_OPTS="--logtostderr=true \
--v=4 \
--etcd-servers=https://192.168.10.10:2379,https://192.168.10.30:2379,https://192.168.10.40:2379 \
--bind-address=192.168.10.20 \?? ??? ??? ??? ?#修改
--secure-port=6443 \
--advertise-address=192.168.10.20 \?? ??? ??? ?#修改
......
//在 master02 节点上启动各服务并设置开机自启
systemctl start kube-apiserver.service
systemctl enable kube-apiserver.service
systemctl start kube-controller-manager.service
systemctl enable kube-controller-manager.service
systemctl start kube-scheduler.service
systemctl enable kube-scheduler.service//查看node节点状态
ln -s /opt/kubernetes/bin/* /usr/local/bin/
kubectl get nodes
kubectl get nodes -o wide?? ??? ??? ?#-o=wide:输出额外信息;对于Pod,将输出Pod所在的Node名//此时在master02节点查到的node节点状态仅是从etcd查询到的信息,
而此时node节点实际上并未与master02节点建立通信连接,因此需要使用一个VIP把node节点与master节点都关联起来
负载均衡部署
//配置load balancer集群双机热备负载均衡(nginx实现负载均衡,keepalived实现双机热备)
##### 在lb01、lb02节点上操作 #####?
//配置nginx的官方在线yum源,配置本地nginx的yum源
cat > /etc/yum.repos.d/nginx.repo << 'EOF'
[nginx]
name=nginx repo
baseurl=http://nginx.org/packages/centos/7/$basearch/
gpgcheck=0
EOF
yum install nginx -y//修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
vim /etc/nginx/nginx.conf
events {
? ? worker_connections ?1024;
}#添加
stream {
? ? log_format ?main ?'$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
#日志记录格式?? ?
#$remote_addr: 客户端的 IP 地址。
#$upstream_addr: 上游服务器的地址。
#[$time_local]: 访问时间,使用本地时间。
#$status: HTTP 响应状态码。
#$upstream_bytes_sent: 从上游服务器发送到客户端的字节数。
? ??
?? ?access_log ?/var/log/nginx/k8s-access.log ?main;
? ? upstream k8s-apiserver {
? ? ? ? server 192.168.10.10:6443;
? ? ? ? server 192.168.10.20:6443;
? ? }
? ? server {
? ? ? ? listen 6443;
? ? ? ? proxy_pass k8s-apiserver;
? ? }
}
http {
......//检查配置文件语法
nginx -t ??//启动nginx服务,查看已监听6443端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx?//部署keepalived服务
yum install keepalived -y//修改keepalived配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
? ?# 接收邮件地址
? ?notification_email {
? ? ?acassen@firewall.loc
? ? ?failover@firewall.loc
? ? ?sysadmin@firewall.loc
? ?}
? ?# 邮件发送地址
? ?notification_email_from Alexandre.Cassen@firewall.loc
? ?smtp_server 127.0.0.1
? ?smtp_connect_timeout 30
? ?router_id NGINX_MASTER?? ?#lb01节点的为 NGINX_MASTER,lb02节点的为 NGINX_BACKUP
? ?#vrrp_strict ?#注释掉
}
#添加一个周期性执行的脚本
vrrp_script check_nginx {
? ? script "/etc/nginx/check_nginx.sh"?? ?#指定检查nginx存活的脚本路径
}
vrrp_instance VI_1 {
? ? state MASTER?? ??? ??? ?#lb01节点的为 MASTER,lb02节点的为 BACKUP
? ? interface ens33?? ??? ??? ?#指定网卡名称 ens33
? ? virtual_router_id 51?? ?#指定vrid,两个节点要一致
? ? priority 100?? ??? ??? ?#lb01节点的为 100,lb02节点的为 90
? ? advert_int 1
? ? authentication {
? ? ? ? auth_type PASS
? ? ? ? auth_pass 1111
? ? }
? ? virtual_ipaddress {
? ? ? ? 192.168.10.100/24?? ?#指定 VIP
? ? }
? ? track_script {
? ? ? ? check_nginx?? ??? ??? ?#指定vrrp_script配置的脚本
? ? }
}//创建nginx状态检查脚本?
vim /etc/nginx/check_nginx.sh
#!/bin/bash ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
/usr/bin/curl -I http://localhost &>/dev/null ? ?
if [ $? -ne 0 ];then ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
# ? ?/etc/init.d/keepalived stop
? ? systemctl stop keepalived
fi?chmod +x /etc/nginx/check_nginx.sh//启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)
systemctl start keepalived
systemctl enable keepalived
ip a?? ??? ??? ??? ?#查看VIP是否生成//修改node节点上的bootstrap.kubeconfig,kubelet.kubeconfig配置文件为VIP
cd /opt/kubernetes/cfg/
vim bootstrap.kubeconfig?
server: https://192.168.233.100:6443
? ? ? ? ? ? ? ? ? ? ??
vim kubelet.kubeconfig
server: https://192.168.233.100:6443
? ? ? ? ? ? ? ? ? ? ? ??
vim kube-proxy.kubeconfig
server: https://192.168.233.100:6443//重启kubelet和kube-proxy服务
systemctl restart kubelet.service?
systemctl restart kube-proxy.service//在 lb01 上查看 nginx 和 node 、 master 节点的连接状态
netstat -natp | grep nginx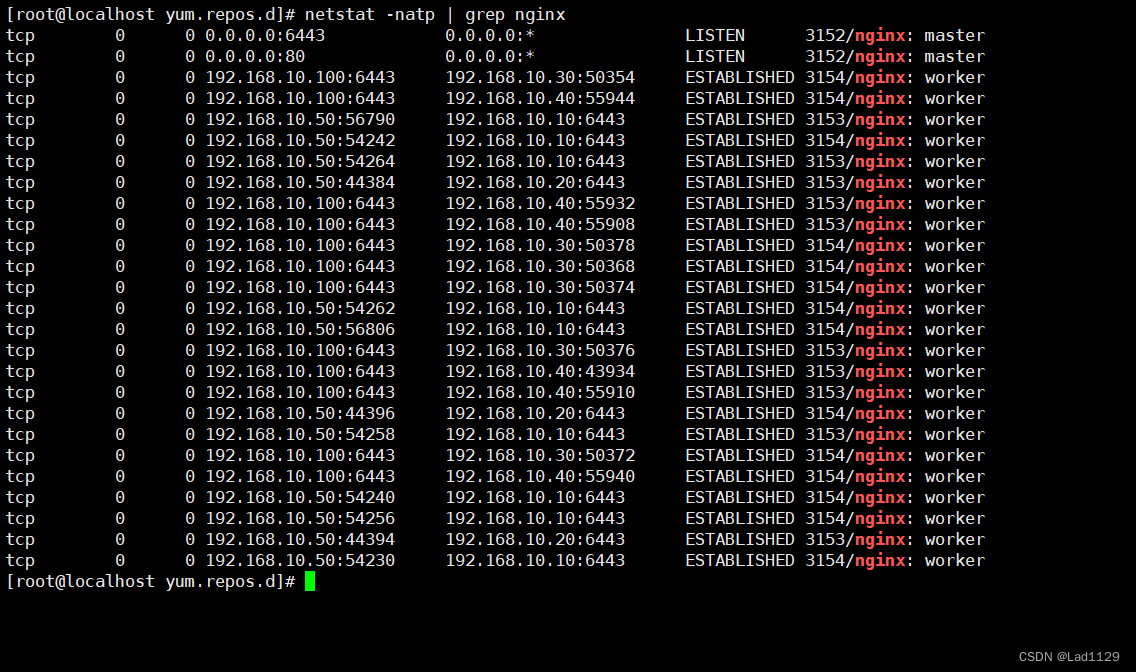
部署 Dashboard
Dashboard 介绍
仪表板是基于Web的Kubernetes用户界面。您可以使用仪表板将容器化应用程序部署到Kubernetes集群,
对容器化应用程序进行故障排除,并管理集群本身及其伴随资源。
您可以使用仪表板来概述群集上运行的应用程序,以及创建或修改单个Kubernetes资源
(例如deployment,job,daemonset等)。例如,您可以使用部署向导扩展部署,启动滚动更新,
重新启动Pod或部署新应用程序。仪表板还提供有关群集中Kubernetes资源状态以及可能发生的任何错误的信息。
//在 master01 节点上操作
#上传 recommended.yaml 文件到 /opt/k8s 目录中
?
cd /opt/k8s
recommended.yaml
#默认Dashboard只能集群内部访问,修改Service为NodePort类型,暴露到外部
kubectl apply -f recommended.yaml#创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-systemkubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin#获取token值
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')#使用输出的token登录Dashboard
https://192.168.10.30:30001
https://192.168.10.40:30001
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2023年终总结,2024新年计划
- 线性代数——(期末突击)行列式(下)-行列式按行展开、范德蒙行列式、克拉默法则
- 【零基础入门VUE】VueJS - 环境设置
- Oracle - 数据库的实例、表空间、用户、表之间关系
- 选择国产压测工具应注意什么?
- SpringBoot 中获取 Request 的四种方法
- 第04章_IDEA的安装与使用(下)(IDEA断点调试,IDEA常用插件)
- 2024年中级工程师职称论文怎么写?
- 【起草】【第九章】玩转新媒体运营!ChatGPT助你引爆流量狂潮
- 【快速开发】使用SvelteKit