Java基础面试
1.继承
里氏替换原则 :子类对象应该能够替换掉父类对象,并且程序不会出错或者产生其他意外行为。这个原则的核心思想在于,子类应该遵循父类定义的规范,而不是重新定义,否则就会破坏继承体系的完整性
原则包含以下方面:
1子类必须完全实现父类的方法,不能修改父类方法的定义,除非重写
2子类不能添加父类没有的方法,会破坏父类的接口
3子类可以添加自己的特有方法(不能重名)
2.编译时多态和运行时多态的区别:
编译时多态通过编译时类型来确定方法调用,而运行时多态通过实际类型来确定方法调用。编译时多态使用函数重载和函数模板,运行时多态使用继承和虚函数。
public class Animal {
public void eat() {
System.out.println("Animal is eating");
}
}
public class Dog extends Animal {
public void eat() {
System.out.println("Dog is eating");
}
}
public class Main {
public static void main(String[] args) {
Animal animal = new Dog(); // 编译时类型为Animal,实际类型为Dog
animal.eat(); // 调用的是Dog类的eat方法,因为编译时类型决定了方法的选择
}
}
在此示例中,我们定义了一个Animal类和一个继承自Animal的Dog类。在主函数中,我们创建了一个Animal对象animal,但实际上它引用的是一个Dog对象。当调用animal.eat()时,由于animal的编译时类型是Animal,编译器会根据编译时类型选择调用Animal类中的eat方法。然而,在运行时,由于实际类型是Dog,实际执行的是Dog类中的eat方法。这就是编译时多态的体现。
3.向上转型和向下转型的区别
1.向上转型是将子类对象转换为父类对象,而向下转型则是将父类对象转换为子类对象。
2.而向上转型的本质就是:父类的实例指向子类的对象->这样可以使得父类实例调用子类重写的方法,而向下转型就是使父类对象强制转为子类对象->以至于可以访问子类特有的方法
3.向上过程: 因为实例在编译时的类型是父类,而编译器会选择编译时的类型,而调用对应方法->在运行时,发现实际类型是子类,所以会调用子类重写的方法
public class Animal {
public void eat() {
System.out.println("Animal is eating");
}
}
public class Dog extends Animal {
public void bark() {
System.out.println("Dog is barking");
}
}
public class Main {
public static void main(String[] args) {
Animal animal = new Dog(); // 向上转型
Dog dog = (Dog) animal; // 向下转型
dog.bark(); // 调用子类方法
}
}
Dog is barking
数据类型
4.八个基本类型
1. boolean(1),byte(1字节8bit位),char(2字节,1位),short(2字节16位),int(4字节32位)
float(4字节,32位),long与double(8字节64位)
2. 另外,boolean类型在Java中占用的内存空间是不固定的
一般情况,编译器会将boolean类型转换为1个字节进行存储——>在一些特殊情况下,编译器会对其进行优化:(将多个boolean类型的变量压缩到同一字节中)
public class Main {
public static void main(String[] args) {
boolean a = true;
boolean b = false;
boolean c = true;
boolean d = false;
boolean e = true;
boolean f = false;
System.out.println("Size of boolean: " + Boolean.SIZE/8 + " bytes");
System.out.println("Value of a: " + a);
System.out.println("Value of b: " + b);
System.out.println("Value of c: " + c);
System.out.println("Value of d: " + d);
System.out.println("Value of e: " + e);
System.out.println("Value of f: " + f);
}
}
5.拆箱装箱与包装类
**包装类:**目的是将基本数据类型封装成对象,比如Integer,Boolean等
Integer x = 2; // 装箱
int y = x; // 拆箱
作用:
1提供对象化操作,允许基本数据类型像对象一般操作,可以调用方法
2提供泛型支持
3支持null
业务场景
装箱拆箱的区别在于数据类型的转换方向。装箱是将基本数据类型转换为包装类对象,而拆箱则是将包装类对象转换为基本数据类型。这种自动转换是由编译器在编译时完成的,而不需要程序员显式地进行操作。
需要注意的是,装箱拆箱会产生一定的性能开销,因为它涉及到对象的创建和销毁。在大量数据处理的情况下,建议使用基本数据类型而不是包装类,以提高性能。
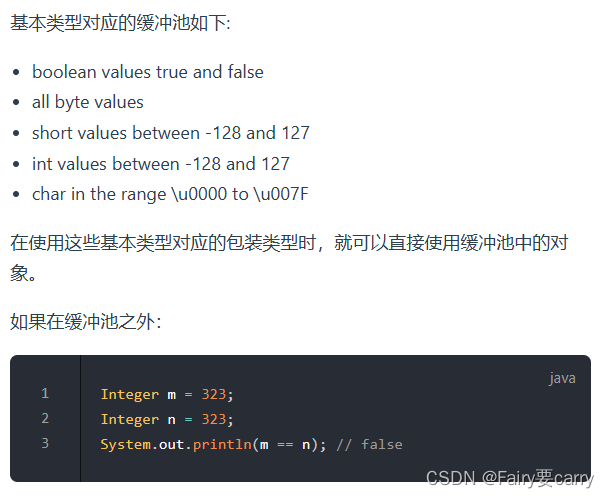
6.缓存池
new Integer(123)和Integer.valueOf(123)的区别:
1.new Integer(123) 每次都会新建一个对象
2.Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false
Integer z = Integer.valueOf(123);
Integer k = Integer.valueOf(123);
System.out.println(z == k); // true
Integer.ValueOf()的方法实现分析:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
注: 在java8中,Integer缓存池的大小默认是-128~127
7.缓冲池,包装类和装箱拆箱的结合
装箱(基本数据类型封装为类,使其能对象化)——>装箱过程的本质就是:调用valueOf()——>编译器会在缓冲池范围内的基本类型自动装箱,调用valueOf方法,所以多个Integer实例使用自动装箱来创建并且值相同
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true
(缓冲池之外需注意)
8.String
1.特点: 被声明为final,表示不可继承(private),不可变的(final),所以是安全的,而他的内部是西安是用char[]value
数组存储数据的
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
2.不可变的好处
1. 字符串池共享:由于String是不可变的,这说明相同值的字符串在内存中只会有一个实例——>也就是说多个引用指向同一个字符串对象(减少了因为对象的创建和销毁所带来的开销)——尤其适用大量字符串的场景:数据库连接等(因为:在实际开发中,通常需要多次连接不同的数据库,每个数据库的连接信息也可能不同。因此,在数据库连接相关的代码中大量使用字符串是非常常见的。
另外,数据库连接信息通常需要在代码中进行配置,而配置信息通常是以字符串的形式存储在配置文件中。因此,在读取配置文件时也需要大量使用字符串。)
2.在字符串进行拼接操作的时候,会将其转化为StringBuilder或者StringBuffer,而二者是可变的字符串类——可在原有的字符串对象基础之上进行修改,不需要创建新的对象,减少了因为频繁创建对象与销毁所带来的的开销
3.线程安全,String不可变,所以多个线程访问是安全的,允许多个线程访问共享String对象
4缓存hash值,String类在创建的时候会计算并缓存其Hash值,在频繁进行字符串比较的场景中,可以通过Hash值来提高性能。因为Hash值是被缓存的,而比较两个字符串Hash值效率>比较两个字符串本身更有效率
**例子:Map——>**字符串作为Map的键值。由于String的不可变性和缓存的Hash值,可以确保字符串作为Map的键值时的唯一性和稳定性。如果String是可变的,则修改String对象的值可能导致Map无法正常使用。
其次——>网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 对象的那一方以为现在连接的是其它主机,而实际情况却不一定是
9.String.intern()
s1.intern()会将s1所引用的对象放在字符串串池中,然会返回这个引用,导致二者引用的是同样一个字符串常量池对象
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
System.out.println(s1.intern() == s3); // true
如果是采用 "bbb" 这种使用双引号的形式创建字符串实例,会自动地将新建的对象放入String Pool中。
String s4 = "bbb";
String s5 = "bbb";
System.out.println(s4 == s5); // true
10.隐式类型转换
short s1 = 1;
// s1 = s1 + 1;
以上int的精度比short要高,所以不能将int类型向下转为short类型
但是可以使用隐式转换,相当于对结果进行了向下转型(强转)
s1 += 1;相等于s1 = (short) (s1 + 1);
11抽象类和接口的区别
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!