Redis设计与实现之压缩列表
目录
一、 压缩列表
Ziplist 是由一系列特殊编码的内存块构成的列表,一个 ziplist 可以包含多个节点(entry),每个节点可以保存一个长度受限的字符数组(不以 \0 结尾的 char 数组)或者整数,包括:
? 字符数组
– 长度小于等于 63 (26 ? 1)字节的字符数组
– 长度小于等于 16383 (214 ? 1)字节的字符数组
– 长度小于等于 4294967295 (232 ? 1)字节的字符数组
? 整数
– 4 位长,介于 0 至 12 之间的无符号整数 – 1 字节长,有符号整数
– 3 字节长,有符号整数
– int16_t 类型整数
– int32_t 类型整数
– int64_t 类型整数
因为 ziplist 节约内存的性质,它被哈希键、列表键和有序集合键作为初始化的底层实现来使 用。本章先介绍 ziplist 的组成结构,以及 ziplist 节点的编码方式,然后介绍 ziplist 的添加操作和 删除操作的执行过程,以及这两种操作可能引起的连锁更新现象,最后介绍 ziplist 的遍历方法 和节点查找方式。
1、ziplist的构成
下图展示了一个 ziplist的典型分布结构:

图中各个域的作用如下:

为了方便地取出 ziplist的各个域以及一些指针地址, ziplist模块定义了以下宏:

因为 ziplist header 部分的长度总是固定的( 4字节 +4字节 +2字节) ,因此将指针移动到表头节点的复杂度为常数时间;除此之外,因为表尾节点的地址可以通过 zltail计算得出,因此将指针移动到表尾节点的复杂度也为常数时间。
以下是用于操作 ziplist的函数:
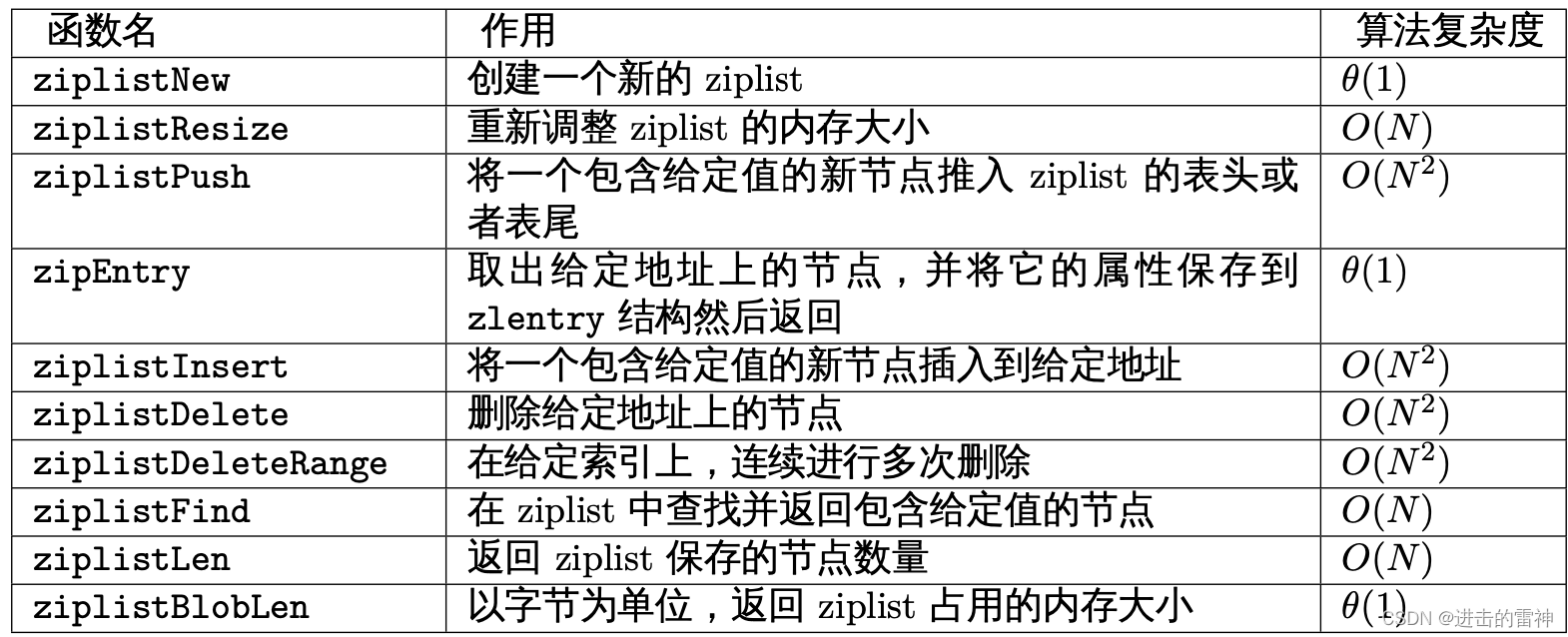
因为 ziplist 由连续的内存块构成,在最坏情况下,当 ziplistPush 、ziplistDelete 这类对 节点进行增加或删除的函数之后,程序需要执行一种称为连锁更新的动作来维持 ziplist 结构本 身的性质,所以这些函数的最坏复杂度都为 O(N2) 。不过,因为这种最坏情况出现的概率并不 高,所以大可以放心使用 ziplist ,而不必太担心出现最坏情况。
2、节点的构成
一个 ziplist 可以包含多个节点,每个节点可以划分为以下几个部分:?

以下几个小节将分别对这个四个部分进行介绍。
pre_entry_length
pre_entry_length 记录了前一个节点的长度,通过这个值,可以进行指针计算,从而跳转到 上一个节点。

上图展示了如何通过一个节点向前跳转到另一个节点:用指向当前节点的指针 e ,减去 pre_entry_length 的值(0000 0101 的十进制值,5),得出的结果就是指向前一个节点的地 址p。
根据编码方式的不同,pre_entry_length 域可能占用 1 字节或者 5 字节:
-
1 字节:如果前一节点的长度小于 254 字节,那么只使用一个字节保存它的值。
-
5 字节:如果前一节点的长度大于等于 254 字节,那么将第 1 个字节的值设为 254 ,然 后用接下来的 4 个字节保存实际长度。
作为例子,以下是一个长度为 1 字节的 pre_entry_length 域,域的值为 128 (二进制为 1000 0000 ):
 ?而以下则是一个长度为 5 字节的 pre_entry_length 域,域的第一个字节被设为 254 的二进制 1111 1110 ,而之后的四个字节则被设置为 10086 的二进制 10 0111 0110 0110 (多余的高 位用 0 补完):
?而以下则是一个长度为 5 字节的 pre_entry_length 域,域的第一个字节被设为 254 的二进制 1111 1110 ,而之后的四个字节则被设置为 10086 的二进制 10 0111 0110 0110 (多余的高 位用 0 补完):

encoding 和 length
encoding 和 length 两部分一起决定了 content 部分所保存的数据的类型(以及长度)。 其中,encoding 域的长度为两个 bit ,它的值可以是 00 、01 、10 和 11 :
? 00 、01 和 10 表示 content 部分保存着字符数组。
? 11 表示 content 部分保存着整数。
以 00 、01 和 10 开头的字符数组的编码方式如下:

?表格中的下划线 _ 表示留空,而变量 b 、x 等则代表实际的二进制数据。为了方便阅读,多个 字节之间用空格隔开。
11 开头的整数编码如下:

content
content 部分保存着节点的内容,它的类型和长度由 encoding 和 length 决定。 以下是一个保存着字符数组 hello world 的节点的例子:

encoding 域的值 00 表示节点保存着一个长度小于等于 63 字节的字符数组,length 域给出 了这个字符数组的准确长度——11 字节(的二进制 001011),content 则保存着字符数组值 hello world 本身(为了表示的简单,content 部分使用字符而不是二进制表示)。
以下是另一个节点,它保存着整数 10086 :

encoding 域的值 11 表示节点保存的是一个整数;而 length 域的值 000000 表示这个节点的 值的类型为 int16_t ;最后,content 保存着整数值 10086 本身(为了表示的简单,content 部分用十进制而不是二进制表示)。
3、创建新 ziplist
函数 ziplistNew 用于创建一个新的空白 ziplist ,这个 ziplist 可以表示为下图:


空白 ziplist 的表头、表尾和末端处于同一地址。
创建了 ziplist 之后,就可以往里面添加新节点了,根据新节点添加位置的不同,这个工作可以分为两类来进行:
1. 将节点添加到 ziplist 末端:在这种情况下,新节点的后面没有任何节点。
2. 将节点添加到某个/某些节点的前面:在这种情况下,新节点的后面有至少一个节点。
以下两个小节分别讨论这两种情况。
4、将节点添加到末端
将新节点添加到 ziplist 的末端需要执行以下三个步骤:
-
记录到达 ziplist 末端所需的偏移量(因为之后的内存重分配可能会改变 ziplist 的地址, 因此记录偏移量而不是保存指针)
-
根据新节点要保存的值,计算出编码这个值所需的空间大小,以及编码它前一个节点的长度所需的空间大小,然后对 ziplist 进行内存重分配。
-
设置新节点的各项属性:pre_entry_length、encoding、length和content。
-
更新 ziplist 的各项属性,比如记录空间占用的 zlbytes ,到达表尾节点的偏移量 zltail,以及记录节点数量的 zllen 。
举个例子,假设现在要将一个新节点添加到只含有一个节点的 ziplist 上,程序首先要执行步骤
1 ,定位 ziplist 的末端:

然后执行步骤 2 ,程序需要计算新节点所需的空间: 假设我们要添加到节点里的值为字符数组 hello world ,那么保存这个值共需要 12 字节的空
间:
? 11 字节用于保存字符数组本身;
? 另外 1 字节中的 2 bit 用于保存类型编码 00 ,而其余 6 bit 则保存字符数组长度 11 的二 进制 001011 。
另外,节点还需要 1 字节,用于保存前一个节点的长度 5 (二进制 101 )。
合算起来,为了添加新节点,ziplist 总共需要多分配 13 字节空间。以下是分配完成之后, ziplist 的样子:

?步骤三,更新新节点的各项属性(为了表示的简单,content 的内容使用字符而不是二进制来表示):

最后一步,更新 ziplist 的 zlbytes 、zltail 和 zllen 属性:

到这一步,添加新节点到表尾的工作正式完成。
Note: 这里没有演示往空 ziplist 添加第一个节点的过程,因为这个过程和上面演示的添加第 二个节点的过程类似;而且因为第一个节点的存在,添加第二个节点的过程可以更好地展示“将 节点添加到表尾”这一操作的一般性。
5、将节点添加到某个/某些节点的前面
比起将新节点添加到 ziplist 的末端,将一个新节点添加到某个/某些节点的前面要复杂得多,因为这种操作除了将新节点添加到 ziplist 以外,还可能引起后续一系列节点的改变。 举个例子,假设我们要将一个新节点 new 添加到节点 prev 和 next 之间:

程序首先为新节点扩大 ziplist 的空间:
 ?
?
然后设置 new 节点的各项值——到目前为止,一切都和前面介绍的添加操作一样: ?
?
现在,新的 new 节点取代原来的 prev 节点,成为了 next 节点的新前驱节点,不过,因为这时 next 节点的 pre_entry_length 域编码的仍然是 prev 节点的长度,所以程序需要将 new 节点 的长度编码进 next 节点的 pre_entry_length 域里,这里会出现三种可能:
1. next 的 pre_entry_length 域的长度正好能够编码 new 的长度(都是 1 字节或者都是 5 字节)
2. next 的 pre_entry_length 只有 1 字节长,但编码 new 的长度需要 5 字节
3. next 的 pre_entry_length 有 5 字节长,但编码 new 的长度只需要 1 字节 对于情况 1 和 3 ,程序直接更新 next 的 pre_entry_length 域。
如果是第二种情况,那么程序必须对 ziplist 进行内存重分配,从而扩展 next 的空间。然而, 因为 next 的空间长度改变了,所以程序又必须检查 next 的后继节点——next+1 ,看它的 pre_entry_length 能否编码 next 的新长度,如果不能的话,程序又需要继续对 next+1 进行 扩容。。
这就是说,在某个/某些节点的前面添加新节点之后,程序必须沿着路径一个个检查后续的节 点是否满足新长度的编码要求,直到遇到一个能满足要求的节点(如果有一个能满足,那么这 个节点之后的其他节点也满足),或者到达 ziplist 的末端 zlend 为止,这种检查操作的复杂度 为 O(N2) 。
不过,因为只有在新添加节点的后面有连续多个长度接近 254 的节点时,这种连锁更新才会发 生,所以可以普遍地认为,这种连锁更新发生的概率非常小,在一般情况下,将添加操作看成 是 O(N) 复杂度也是可以的。
执行完这三种情况的其中一种后,程序更新 ziplist 的各项属性,至此,添加操作完成。
Note: 在第三种情况中,程序实际上是可以执行类似于情况二的动作的:它可以一个个地检 查新节点之后的节点,尝试收缩它们的空间长度,不过 Redis 决定不这么做,因为在一些情况 下,比如前面提到的,有连续多个长度接近 254 的节点时,可能会出现重复的扩展——收缩 ——再扩展——再收缩的抖动(flapping)效果,这会让操作的性能变得非常差。
6、删除节点
删除节点和添加操作的步骤类似。
1) 定位目标节点,并计算节点的空间长度 target-size :

2) 进行内存移位,覆盖 target 原本的数据,然后通过内存重分配,收缩多余空间: ?
?
3) 检查 next 、next+1 等后续节点能否满足新前驱节点的编码。和添加操作一样,删除操作也 可能会引起连锁更新。
7、遍历
可以对 ziplist 进行从前向后的遍历,或者从后先前的遍历。
当进行从前向后的遍历时,程序从指向节点 e1 的指针 p 开始,计算节点 e1 的长度(e1-size), 然后将 p 加上 e1-size ,就将指针后移到了下一个节点 e2 。。一直这样做下去,直到 p 遇到 ZIPLIST_ENTRY_END 为止,这样整个 ziplist 就遍历完了:

当进行从后往前遍历的时候,程序从指向节点 eN 的指针 p 出发,取出 eN 的 pre_entry_length 值,然后用 p 减去 pre_entry_length ,这就将指针移动到了前一个节点 eN-1 。一直这样 做下去,直到 p 遇到 ZIPLIST_ENTRY_HEAD 为止,这样整个 ziplist 就遍历完了。

8、查找元素、根据值定位节点
这两个操作和遍历的原理基本相同,不再赘述。
二、小结
? ziplist 是由一系列特殊编码的内存块构成的列表,它可以保存字符数组或整数值,它还是哈希键、列表键和有序集合键的底层实现之一。 ? ziplist 典型分布结构如下:

? ziplist 节点的分布结构如下: ?? 添加和删除 ziplist 节点有可能会引起连锁更新,因此,添加和删除操作的最坏复杂度为 O(N2) ,不过,因为连锁更新的出现概率并不高,所以一般可以将添加和删除操作的复 杂度视为 O(N) 。
?? 添加和删除 ziplist 节点有可能会引起连锁更新,因此,添加和删除操作的最坏复杂度为 O(N2) ,不过,因为连锁更新的出现概率并不高,所以一般可以将添加和删除操作的复 杂度视为 O(N) 。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 3d建模软件有哪些?3d云渲染推荐
- Pandas实战100例 | 案例 55: 应用条件
- vue常用指令(v-text)
- Java AOP 代码实践
- 每日一练2023.12.23——考试座位号【PTA】
- Tomcat部署Activiti官方 流程设计器【数据库更换为Mysql !!!】
- Unity网格篇Mesh(二)
- 直播主播的三维能力
- 操作系统期末复习知识点二计算与应用
- 【hcie-cloud】【11】华为云Stack资源与服务扩建【云服务扩容、自动化变更平台&公共服务组件、华为云Stack典型高阶服务扩容简介、缩略词】【下】