七个值得实践的Kaggle机器学习项目 - 2024更上一层楼
Kaggle 是世界上最大的数据科学社区,拥有强大的工具和资源来帮助我们实现数据科学目标。企业和研究者可在其上发布数据,统计学者和数据挖掘专家可在其上进行竞赛以产生最好的模型。
实践出真知,为此我整理了 10 个值得在 2024 年学习的?Kaggle 机器学习项目,通过这些项目我们可以获得涵盖从数据预处理和探索性数据分析到高级机器学习模型开发数据科学等各个方面的全面学习体验和实践经验。
1 小狗品种分类
https://www.kaggle.com/datasets/jessicali9530/stanford-dogs-dataset
这个项目要求我们使用斯坦福狗数据集训练一个检测狗品种的深度学习模型,用户会输入一张小狗的图像,模型输出小狗的品种。我们可以通过学习这个经典的图像分类任务来了解深度学习的著名架构之一:卷积神经网络 (Convolutional Neural Networks,CNN) 及其在现实世界问题中的应用。

通过这个项目,你会掌握:
-
图像预处理
-
设计涉及不同层的 CNN 架构
-
使用 PyTorch 或者是其他你熟悉的深度学习框架实现 CNN 并训练模
-
使用准确性和混淆矩阵等评估指标来评估分类模型性能
2 使用 NLP 检测假新闻
https://www.kaggle.com/datasets/clmentbisaillon/fake-and-real-news-dataset

这本质上还是一个监督学习分类问题,不过现在是文本分类。我们需要训练一个能够发掘从不同社交媒体应用程序收集的真新闻和假新闻文章之间的差异模式的机器学习模型。
通过这个项目,你会掌握:
-
文本预处理、特征提取和分类
-
自然语言处理库(如 NLTK 或 spaCy)
-
朴素贝叶斯或 RNN 等机器学习,深度学习算法
-
使用精度、召回率和 F1 分数等指标评估模型性能
3 电影推荐系统
https://www.kaggle.com/datasets/grouplens/movielens-20m-dataset
这个项目的目标是为电影网站建立一个通过用户过去观看的内容自动向用户推荐电影或网剧的推荐系统。
通过这个项目,你会掌握:
-
协作过滤算法、矩阵分解以及 Surprise 或 LightFM 等推荐系统框架
-
探索 user-item 交互,构建推荐算法
-
使用平均绝对误差等指标评估其性能,并微调模型以获得更好的预测
4 客户细分
ttps://www.kaggle.com/datasets/carrie1/ecommerce-data

这是一种无监督学习问题,我们通过分析电子商务相关数据集,建立一个根据客户过去的购买行为对客户进行细分的机器学习模型。通过利用细分,公司可以针对所有客户进行营销和个性化服务。
技术:与无监督机器学习算法类别不同的聚类算法,例如 K 均值或分层聚类(分裂式或聚合式),用于根据客户的行为对客户进行细分。
通过这个项目,你会掌握:
-
处理交易数据,包括数据可视化
-
应用不同的聚类算法,根据模型形成的其他聚类可视化客户细分,分析每个细分的特征以获得营销数据信息
-
轮廓分数等不同的评估指标
5 股票价格预测
https://www.kaggle.com/code/faressayah/stock-market-analysis-prediction-using-lstm
股票的行为有点随机,但 A 股却稳定在 3000 点左右。我们尝试通过使用机器学习算法捕获数据的方差,使用历史财务数据来预测近似的股票价格。这个项目涉及时间序列分析和预测,以对银行、汽车等多个行业之间不同股票价格的动态进行建模。
通过这个项目,你会掌握:
-
分析时间序列数据的技术,例如自相关函数和预测模型,包括自回归积分移动平均(ARIMA)、长短期记忆(LSTM)网络等
-
使用均方误差、平均绝对误差或均方根误差等指标评估模型性能
6 语音情感识别
https://www.kaggle.com/datasets/uwrfkaggler/ravdess-emotional-speech-audio

在这个项目中,我们利用带有标记音频剪辑的数据集,例如包含情感语音录音的“RAVDESS”数据集,开发一个可以识别口语中不同类型的情绪(愤怒、快乐、疯狂等)的模型。其中涉及对从不同人捕获的音频数据进行处理并应用机器学习进行情绪分类技术。
通过这个项目,你会掌握:
-
用于音频分析的特征提取深度学习模型的信号处理技术
-
设计用于情感识别的神经网络
-
训练深度学习模型
-
使用准确性和混淆矩阵等指标评估其性能
7?信用卡欺诈检测
https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
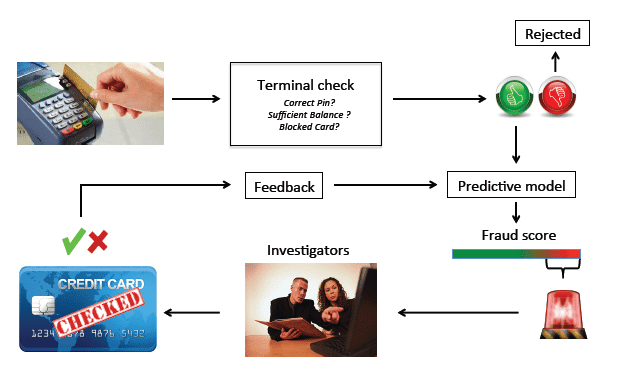
这是一个监督学习问题,我们通过分析欺诈(fraud)和非欺诈(non-fraud)交易案例的信用卡交易数据集,开发一个机器学习模型来检测欺诈性信用卡交易,这对于金融机构增强安全性、保护用户免受欺诈活动并使不同交易的环境变得非常容易至关重要。
通过这个项目,你会掌握:
-
异常检测算法、随机森林或支持向量机等分类模型
-
使用精度、召回率和 ROC-AUC 等分类评估指标来评估模型
总结
成为一名数据科学家不仅仅需要掌握算法或框架,还需要为复杂的问题制定解决方案,理解不同的数据集,并不断适应不断发展的技术格局。不断探索,保持好奇心!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 项目实战--Message Queue
- posixpath库----Python
- 【Java 基础篇】Java 文件及文件夹操作详解
- 【LMM 007】Video-LLaVA:通过投影前对齐以学习联合视觉表征的视频多模态大模型
- 基于gui控制的遗传算法优化BP神经网络回归系统
- JC/T 2080-2011 木铝复合门窗检测
- 特殊文件(properties和xml文件)及logback日志文件
- MacOS 14.1 配置kerberos认证
- 二维码图片生成
- 工厂方法模式