【LangChain学习之旅】—(1) 何谓 LangChain
发布时间:2023年12月17日
【LangChain学习之旅】— 何谓 LangChain
如何理解 LangChain
- 作为一种专为开发基于语言模型的应用而设计的框架,通过 LangChain,不仅可以通过 API 调用如 ChatGPT、GPT-4、Llama 2 等大型语言模型,还可以实现更高级的功能。
- 正有潜力且具有创新性的应用,不仅仅在于能通过 API 调用语言模型,更重要的是能够具备以下两个特性:
- 数据感知:能够将语言模型与其他数据源连接起来,从而实现对更丰富、更多样化数据的理解和利用。
- 具有代理性:能够让语言模型与其环境进行交互,使得模型能够对其环境有更深入的理解,并能够进行有效的响应。
- 因此,LangChain 框架的设计目标,是使这种 AI 类型的应用成为可能,并帮助我们最大限度地释放大语言模型的潜能。
总而言之,LangChain 是一个基于大语言模型(LLMs)用于构建端到端语言模型应用的框架,它可以让开发者使用语言模型来实现各种复杂的任务,例如文本到图像的生成、文档问答、聊天机器人等。LangChain 提供了一系列工具、套件和接口,可以简化创建由 LLMs 和聊天模型提供支持的应用程序的过程。
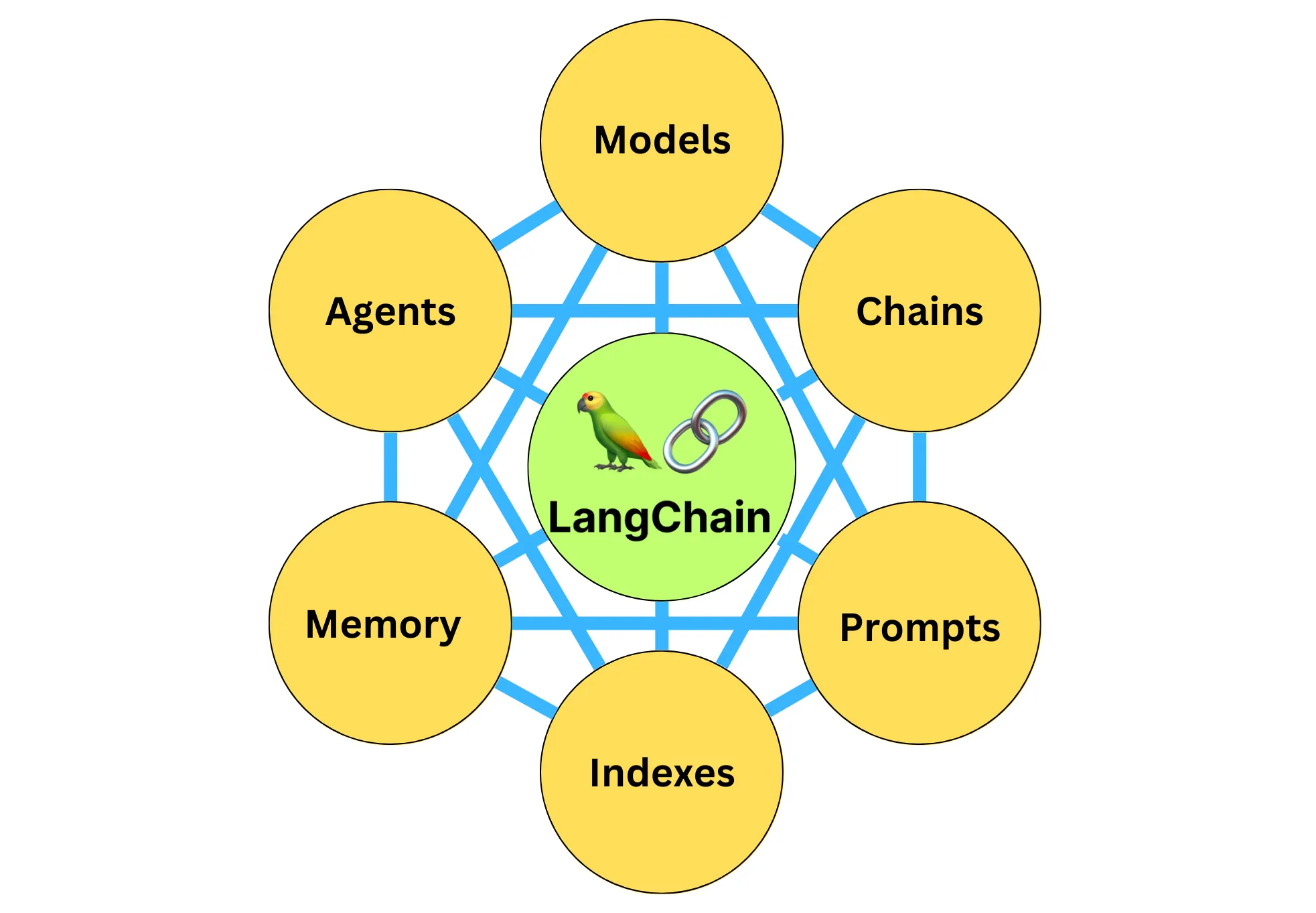
LangChain 中的具体组件
LangChain 中的具体组件包括:
- 模型(Models),包含各大语言模型的 LangChain 接口和调用细节,以及输出解析机制。
- 提示模板(Prompts),使提示工程流线化,进一步激发大语言模型的潜力。
- 数据检索(Indexes),构建并操作文档的方法,接受用户的查询并返回最相关的文档,轻松搭建本地知识库。
- 记忆(Memory),通过短时记忆和长时记忆,在对话过程中存储和检索数据,让 ChatBot 记住你是谁。
- 链(Chains),是 LangChain 中的核心机制,以特定方式封装各种功能,并通过一系列的组合,自动而灵活地完成常见用例。
- 代理(Agents),是另一个 LangChain 中的核心机制,通过“代理”让大模型自主调用外部工具和内部工具,使强大的“智能化”自主 Agent 成为可能!你的 App 将产生自驱力!
LangChain调用ChatGPT
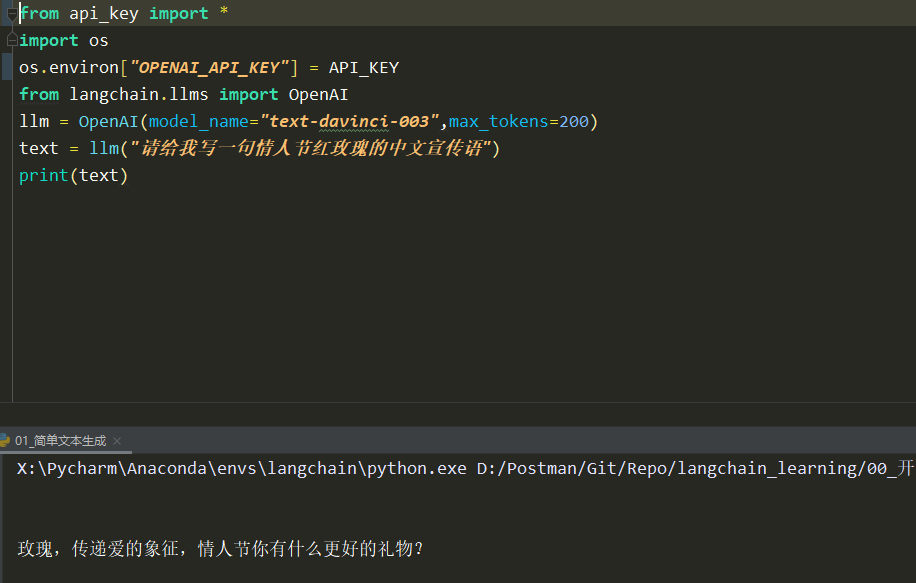
pip install langchain安装 LangChainpip install openai来安装 OpenAI- 在 OpenAI 网站注册属于自己的 OpenAI Key(淘宝1块钱可以买5$额度GPT3.5)。
import os
os.environ["OPENAI_API_KEY"] = '你的OpenAI Key'
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003",max_tokens=200)
text = llm("请问你是谁?")
print(text)
LangChain代理功能
你已经制作好了一批鲜花的推广海报,想为每一个海报的内容,写一两句话,然后 post 到社交平台上,以期图文并茂。这个需求,特别适合让 AI 帮你批量完成,不过,ChatGPT 网页可不能读图。下面,我们就用 LangChain 的“代理”调用“工具”来完成自己做不到的事情。
我们就用一段简单的代码实现上述功能。这段代码主要包含三个部分:
- 初始化图像字幕生成模型(HuggingFace 中的 image-caption 模型)。
- 定义 LangChain 图像字幕生成工具。
- 初始化并运行 LangChain Agent(代理),这个 Agent 是 OpenAI 的大语言模型,会自动进行分析,调用工具,完成任务。
不过,这段代码需要的包比较多。在运行这段代码之前,你需要先更新 LangChain 到最新版本,安装 HuggingFace 的 Transformers 库(开源大模型工具),并安装 Pillow(Python 图像处理工具包)和 PyTorch(深度学习框架)
pip install --upgrade langchain
pip install transformers
pip install pillow
pip install torch torchvision torchaudio
#---- Part 0 导入所需要的类
import os
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
from langchain.tools import BaseTool
from langchain import OpenAI
from langchain.agents import initialize_agent, AgentType
#---- Part I 初始化图像字幕生成模型
# 指定要使用的工具模型(HuggingFace中的image-caption模型)
hf_model = "Salesforce/blip-image-captioning-large"
# 初始化处理器和工具模型
# 预处理器将准备图像供模型使用
processor = BlipProcessor.from_pretrained(hf_model)
# 然后我们初始化工具模型本身
model = BlipForConditionalGeneration.from_pretrained(hf_model)
#---- Part II 定义图像字幕生成工具类
class ImageCapTool(BaseTool):
name = "Image captioner"
description = "为图片创作说明文案."
def _run(self, url: str):
# 下载图像并将其转换为PIL对象
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
# 预处理图像
inputs = processor(image, return_tensors="pt")
# 生成字幕
out = model.generate(**inputs, max_new_tokens=20)
# 获取字幕
caption = processor.decode(out[0], skip_special_tokens=True)
return caption
def _arun(self, query: str):
raise NotImplementedError("This tool does not support async")
#---- PartIII 初始化并运行LangChain智能代理
# 设置OpenAI的API密钥并初始化大语言模型(OpenAI的Text模型)
os.environ["OPENAI_API_KEY"] = '你的OpenAI API Key'
llm = OpenAI(temperature=0.2)
# 使用工具初始化智能代理并运行它
tools = [ImageCapTool()]
agent = initialize_agent(
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
tools=tools,
llm=llm,
verbose=True,
)
img_url = 'https://mir-s3-cdn-cf.behance.net/project_modules/hd/eec79e20058499.563190744f903.jpg'
agent.run(input=f"{img_url}\n请给出合适的中文文案")
根据输入的图片 URL,由 OpenAI 大语言模型驱动的 LangChain Agent,首先利用图像字幕生成工具将图片转化为字幕,然后对字幕做进一步处理,生成中文推广文案。
文章来源:https://blog.csdn.net/weixin_56462041/article/details/135044906
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- echart图表之温度计 bar 温度计超出范围颜色爆红
- 使用残差网络识别手写数字及MNIST 数据集介绍
- 【JavaEE】线程安全的集合类
- 手把手带你死磕ORBSLAM3源代码(五十四) MapDrawer.cc ParseViewerParamFile
- 性能测试工具Jmeter你所不知道的东西····
- 基于遗传算法的配电网故障重构研究【IEEE33节点】(Matlab代码实现)
- linux多进程基础(6):setitimer(间隔定时器)和signal(信号处理函数)
- HarmonyOS如何使用异步并发能力进行开发
- ts 浅谈
- react hooks笔记(1)