Swin UNetR:把 UNet 和 Swin Transformer 结合
Swin UNetR:把 UNet 和 Swin Transformer 结合
?
Swin UNetR 结合 Swin Transformer 的上下文建模能力和 U-Net 的像素级别预测能力,提高语义分割任务的性能。
- 把 2D Swin Transformer 变成 3D Swin Transformer
- 结合 UNet
通过引入 Swin Transformer 的注意力机制和窗口化卷积操作,可以更好地处理大尺寸图像,并捕捉全局上下文信息。同时,还可以通过 U-Net 的解码器结构进行精细的分割预测。
只改了几个层,唯一工作量大的只有 decoder 的 patch expand,做了几个消融实验。
论文地址:https://arxiv.org/abs/2105.05537
算代码目:https://github.com/HuCaoFighting/Swin-Unet
网络结构
Swin UNetR 长什么样子?
在 ViT 图上,加了一个解码器 Decoder:
- ViT 只用了 Transformer 的编码器
Enconder,UNetR 补上了解码器Decoder

UNet 形状的 Swin Transformer:
- 使用的基本模块是 Swin Transformer block

全局计算视角:
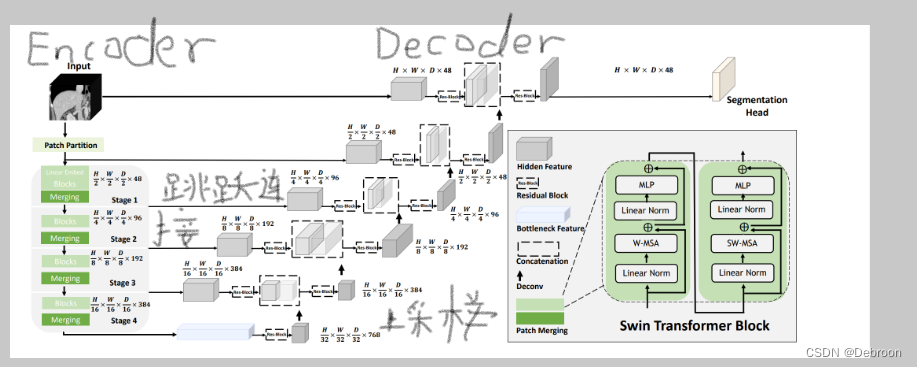
上图添加了关联,编码器Encoder、解码器Decoder、跳跃连接、UNet上采样,编码器部分使用了Swin Transformer。
下图显示,解码器部分是使用卷积网络:
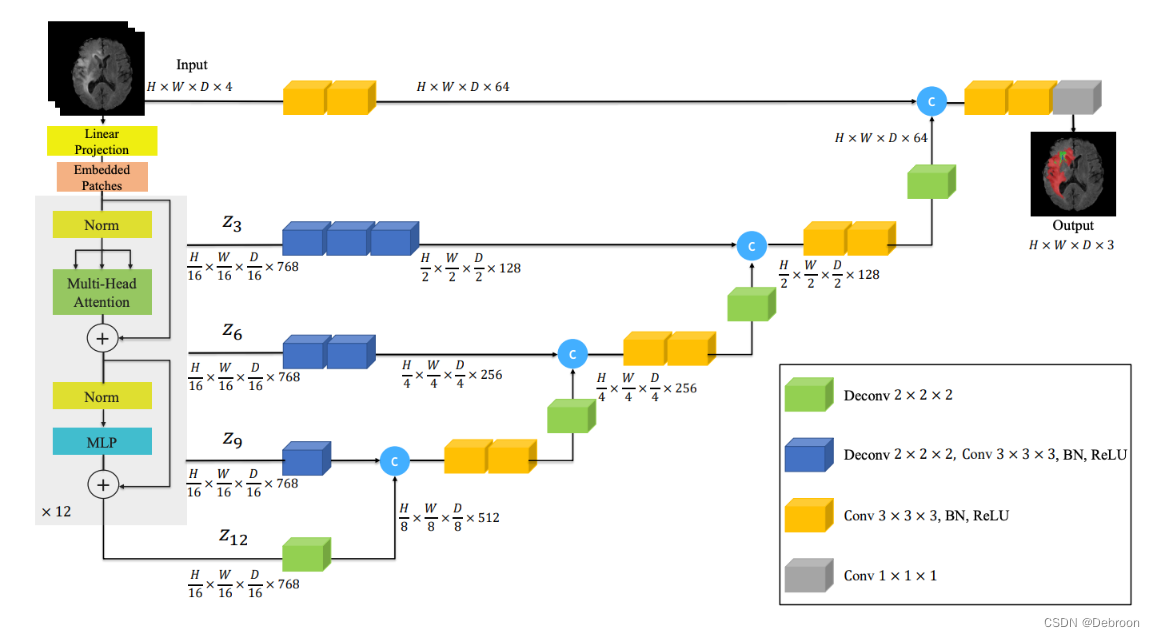
下图,突出子模块的关联:

Encoder:
-
将输入的图像分割成大小为特定分辨率的小块,称为tokenized inputs。这些tokenized inputs被送入两个连续的Swin Transformer块,用于学习表示。这两个Swin Transformer块的特征维度和分辨率与输入保持不变。
-
同时,在每个Swin Transformer块之间还有一个patch merge层。这个层的作用是将Token的数量减少,实现2倍的下采样,同时将特征维度增加到原始维度的2倍。这样可以在保持特征维度的同时,减少Token的数量,从而降低计算复杂度。
-
这个过程会在Encoder中重复3次,以逐渐减少分辨率和增加特征维度。通过这种方式,Encoder能够在每个阶段学习到不同尺度的特征表示,从而提供更丰富的上下文信息和多尺度感知能力。
Patch merging layer:
-
把输入的patch被分为四个部分,通常是按照水平和垂直方向平分。然后,这四个部分被连接在一起,形成一个更大的patch。这个操作导致特征分辨率降低了2倍,因为每个patch的尺寸减半。
-
同时,由于连接操作的结果是特征维度增加了4倍,为了保持维度一致性,会在连接的特征上添加一个线性层。这个线性层将特征的维度统一为原始维度的2倍,以便后续的处理和学习。
-
这样的处理可以在保持特征维度增加的同时,降低分辨率,以获取更广阔的上下文信息,并提供更丰富的特征表示能力。
Decoder:
-
使用了基于Swin Transformer块的对称结构。与编码器中的patch merge层不同,解码器中使用了patch expand层对提取的深度特征进行上采样。
-
patch expand层会将相邻维度的特征图重新塑造为更高分辨率的特征图,实现了2倍的上采样。同时,特征的维度也会相应地减半。
-
这个操作的目的是在解码器中进行上采样操作,以恢复图像的分辨率,同时减少特征的维度。这样可以保持特征的上下文信息,并为后续的特征融合和预测提供更多的细节和精度。
-
通过使用patch expand层,解码器可以将低分辨率的特征图上采样到高分辨率,并且减少特征维度,以逐渐恢复图像的细节和结构。这有助于生成更精细的分割结果。
Patch expanding layer:
-
用于对输入特征进行上采样。
-
以第1个Patch expanding layer为例,首先对输入特征添加一个线性层,将特征的维度增加到原始维度的2倍。这个线性层的作用是为了保持维度一致性,以便后续的处理和学习。
-
然后,利用rearrange操作,将输入特征的分辨率扩大到输入分辨率的2倍。rearrange操作是一种操作,它可以将特征的分布重新排列,从而实现上采样操作。通过这个操作,特征的分辨率增加了2倍,而特征的维度减少到输入维度的1/4。
-
这样的处理可以实现对特征的上采样,同时降低特征的维度。上采样可以恢复图像的细节和结构,而维度降低可以减少计算复杂度和内存消耗。
-
通过使用Patch expanding layer,解码器能够逐渐恢复图像的分辨率,并减少特征的维度,以提供更多的细节和精度,并为后续的特征融合和预测做准备。
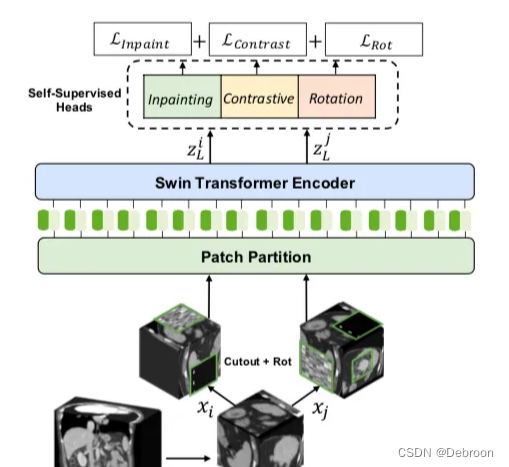
计算过程:
-
训练过程中,将输入切割为多个小的体素块,并对每个体素块进行两次不同的数据增强操作,然后将它们分别输入到网络的编码器中进行处理,并计算自监督损失。这个过程旨在增加训练数据的多样性和丰富性。
-
网络采用了U-Net结构,其中编码器部分使用了Swin Transformer,而解码器部分则使用了卷积网络。
-
编码器的具体操作。首先,使用Patch Partition层将输入划分为一个3D的token序列。然后,通过线性嵌入层将token投影到C维空间中,以便进行有效的交互建模。为了实现这个目的,输入被划分为不重叠的窗口,并在每个窗口内计算局部自注意。
-
编码器的具体参数和结构。编码器使用2x2x2的patch大小,特征维度为8(针对单输入通道的CT图像),嵌入空间维度为48。编码器由4个级别组成,每个级别包括两个Transformer块(L=8),在每个级别之间使用Patch Merge层来降低分辨率。
-
编码器和解码器之间的连接方式。编码器的输出通过跳跃连接连接到解码器的相应分辨率上,以创建一个"U型"网络结构。这种结构可以为下游任务(如分割)提供更多的上下文信息和多尺度特征。
-
分割任务的处理过程。将编码器的输出(即Swin Transformer)与经过处理的输入体积特征连接起来,并将它们输入到一个残块中。然后,通过一个具有适当激活函数(如softmax)的1x1x1卷积层,计算出分割概率。
-
网络的预训练和微调过程。在预训练阶段,编码器的输出端连接了三个任务头。在微调阶段,去掉了三个任务头,并添加了一个分割头。微调时会调整整个网络的参数。
-
预测头的具体结构。Inpainting任务的预测头是一个卷积层,而旋转任务和对抗任务的预测头是多层感知器(MLP)。
-
各个任务的损失函数。Inpainting任务使用L1损失,旋转任务使用交叉熵损失,对抗任务使用InfoNce损失。
-
Inpainting任务和旋转任务的一些具体操作。Inpainting任务从二维扩展到了三维,而旋转任务是沿着Z轴进行旋转。
-
训练过程中使用的混合损失。三个任务的损失函数被组合成一个混合损失来指导训练,每个损失的权重都为1,即平等对待三个任务的损失。
UNETR 使用指南:分割三维腹部多器官
monai:专为医学图像定制的框架。
英伟达的这款框架集成了很多医学方面的算法,Swin UNetR 也在里面,直接调用即可。
UNETR 实战:https://blog.csdn.net/u014264373/article/details/125192227
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Pointnet++改进系列:全网首发RepVGG结构重参数化 |即插即用,实现有效涨点
- 赛氪公开课|AI发展的影响与对策
- Unity 渲染顺序受哪些影响(相机depth、SortingLayer、Render Queue、透明)
- 抖店申请流程是什么?
- MySQL第二次作业
- 179. 八数码(A*启发式搜索)
- PDF修改技巧之:如何简单方便的编辑PDF文件?
- 谁是第一名
- 球形体积雾
- 图像质量评估:使用 SSIM 计算图像相似性