助力打造清洁环境,基于YOLOv7开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统
公共社区环境生活垃圾基本上是我们每个人每天几乎都无法避免的一个问题,公共环境下垃圾投放点都会有固定的值班时间,但是考虑到实际扔垃圾的无规律性,往往会出现在无人值守的时段内垃圾堆放垃圾桶溢出等问题,有些容易扩散的垃圾比如:碎纸屑、泡沫粒等等,一旦遇上大风天气往往就会被吹得遍地都是给垃圾清理工作带来负担。

本文的主要目的及时想要探索分析通过接入社区实时视频流数据来对公共环境下的垃圾投放点进行自动化的智能分析计算,当探测到异常问题比如:随意堆放垃圾、垃圾桶溢出等问题的时候结合一些人工业务预设的规则来自动通过短信等形式推送事件给相关的工作人员来进行及时的处置这一方案的可行性,博文主要是侧重对检测模型的开发实现,业务规则需要到具体的项目中去细化,这块就不作为文本的实践内容。
在前文中,我们已经陆续开发了相关的实践项目,感兴趣的话可以自行移步阅读即可:
《助力打造清洁环境,基于YOLOv3开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统》
《助力打造清洁环境,基于YOLOv4开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统》
《助力打造清洁环境,基于YOLOv5全系列模型【n/s/m/l/x】开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统》
《助力打造清洁环境,基于美团最新YOLOv6-4.0开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统》
本文主要是想要基于YOLOv7这一新的技术模型来开发实践性质的项目,首先看下实例效果:

YOLOv7是 YOLO 系列最新推出的YOLO 结构,在 5 帧/秒到 160 帧/秒范围内,其速度和精度都超过了大部分已知的目标检测器,在 GPU V100 已知的 30 帧/秒以上的实时目标检测器中,YOLOv7 的准确率最高。根据代码运行环境的不同(边缘 GPU、普通 GPU 和云 GPU),YOLOv7 设置了三种基本模型,分别称为 YOLOv7-tiny、YOLOv7和 YOLOv7-W6。相比于 YOLO 系列其他网络 模 型 ,YOLOv7 的 检 测 思 路 与YOLOv4、YOLOv5相似,YOLOv7 网络主要包含了 Input(输入)、Backbone(骨干网络)、Neck(颈部)、Head(头部)这四个部分。首先,图片经过输入部分数据增强等一系列操作进行预处理后,被送入主干网,主干网部分对处理后的图片提取特征;随后,提取到的特征经过 Neck 模块特征融合处理得到大、中、小三种尺寸的特征;最终,融合后的特征被送入检测头,经过检测之后输出得到结果。
YOLOv7 网络模型的主干网部分主要由卷积、E-ELAN 模块、MPConv 模块以及SPPCSPC 模块构建而成 。在 Neck 模块,YOLOv7 与 YOLOv5 网络相同,也采用了传统的 PAFPN 结构。FPN是YoloV7的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV7里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。Head检测头部分,YOLOv7 选用了表示大、中、小三种目标尺寸的 IDetect 检测头,RepConv模块在训练和推理时结构具有一定的区别。
简单看下实例数据情况:
?


如果对于如何从零开始基于YOLOv7模型来开发构建自己的个性化检测项目有疑问的,可以移步阅读我的超详细教程:
《YOLOv7基于自己的数据集从零构建模型完整训练、推理计算超详细教程》
这里主要是选择了yolov7l模型来进行开发训练,训练数据配置文件如下:
# txt path
train: ./dataset/images/train
val: ./dataset/images/test
test: ./dataset/images/test
# number of classes
nc: 3
# class names
names: ['trash_over', 'garbage', 'trash_no_full']
模型配置文件如下:
# parameters
nc: 3 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
训练启动,终端日志输出如下:



等待训练完成,我们来整体看下结果详情:
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能。F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
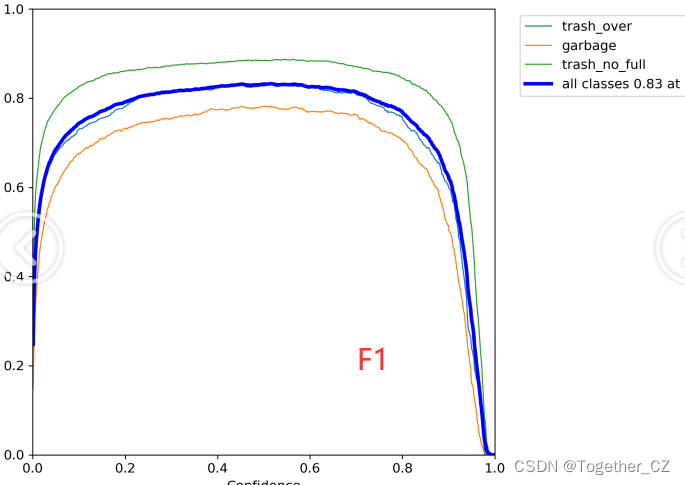
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。

【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
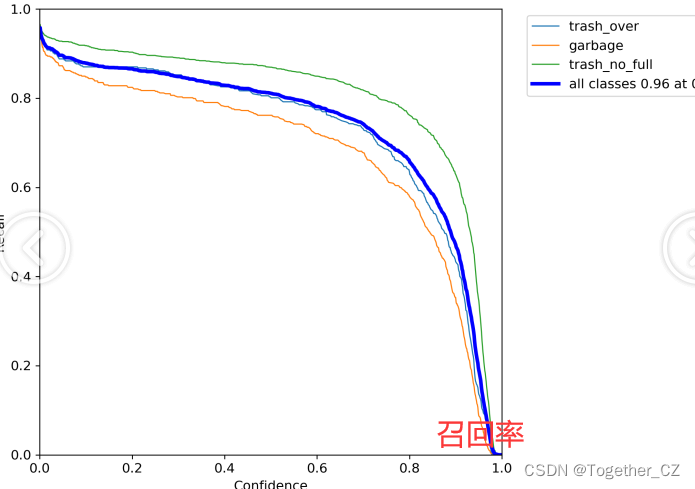
【PR曲线】
精确率-召回率曲线(Precision-Recall Curve)是一种用于评估二分类模型性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)和召回率(Recall)之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。

整体训练过程如下:

Batch实例如下:

离线实例推理如下所示:

这里抛砖引玉,感兴趣的话也可以动手实践下!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- pyDAL一个python的ORM(10) pyDAL的连接查询1
- 深圳市第三职业技术学校 | 柔性OLED拼接屏
- Rust 学习
- 八. 实战:CUDA-BEVFusion部署分析-环境搭建
- 跟这台计算机连接的一个USB设备运行不正常?造成这样的原因可能有这些
- Tomcat Log Time Format :1catalina.org.apache.juli.AsyncFileHandler.formatter
- Java两大集合:Collection 和 Map 源码及总结
- cdn引入React以及React-dom—数组遍历渲染时setExtraStackFrame报错
- 2023中国PostgreSQL数据库生态大会-核心PPT资料下载
- 【INTEL(ALTERA)】使用HDMI FPGA IP 2.0 TX 和 HDMI FPGA IP RX 2.1时为何 HDMI IP 没有视频输出?