三、MySQL库表操作
3.1 SQL语句基础(SQL命令)
3.1.1 SQL简介
SQL:结构化查询语言(Structured Query Language),在关系型数据库上执行数据操作,数据检索以及数据维护的标准化语言。使用SQL语句,程序员和数据库管理员可以完成如下的任务:
-
改变数据库的结构
-
更改系统的安全设置
-
增加用户对数据库或表的许可权限
-
在数据库中检索需要的信息
-
对数据库的信息进行更新 备份 还原
综上所述 :想要使用Mysql数据库 必须要学习Sql语言。
3.1.2 SQL语句的分类
MySQL致力于支持全套ANSI/ISO SQL标准。在MySQL数据库中,SQL语句主要可以划分为以下几类:
- DDL(Data Definition Language): 数据定义语言。定义对数据库对象(库、表、列、索引)的操作。
关键字:CREATE、DROP、ALTER、RENAME、 TRUNCATE等。- DML(Data Manipulation Language):数据操作语言。定义对数据库记录的操作。
关键字:INSERT、DELETE、UPDATE等。- DCL(Data Control Language):数据控制语言。定义对数据库、表、字段、用户的访问权限和安全级别。
关键字:GRANT、REVOKE等。- DQL(Data Query Language):数据查询语言。检索并获取数据。
关键字: SELECT。
3.1.3 SQL语句的书写规范
在数据库系统中,SQL语句不区分大小写(建议用大写) 。
字符串常量区分大小写。
SQL语句支持单行||多行书写,但必须以;结尾。
关键字||词汇不能跨行书写。
支持空格或缩进以提升语句的可读性。
子语句通畅位于独立行,便于编辑,提高可读性。
3.2 数据库操作
1、查看
SHOW DATABASES [LIKE wild] ;
功能:列出Mysql主机上的狭义数据库。
Mysql自带数据库(系统库):
information_schema:主要存储了系统中的一些数据库对象信息,如用户信息,列信息,权限信息,字符集信息,分区信息等(数据字典)
performance_schema:主要存储了数据库服务器的性能参数
mysql:主要存储了系统的用户权限信息和帮助文档
sys:5.7后新增产物,information_schema和performance_schema的结合体,并以视图形式显示出来的,查询出更加令人容易理解的数据。
原则: 不轻易访问,不轻易修改,不轻易删除!!
2、自建库
创建个人数据库
语法 CREATE DATABASE IF NOT EXISTS 数据库名;
CREATE DATABASE IF NOT EXISTS MySchool_db;
一个数据库(微观)是由 表 视图 函数 查询 备份所构成 重中之重是 表
3、切换数据库
使用USE 关键字进行切换 语法 : USE 数据库名;
作用:指定数据库为我们的默认数据库,用于后期建表或其他使用。
其他:
1 查看当前访问的数据库
SELECT DATABASE();
2 查看当前数据库服务器版本
SELECT VERSION();
3 查看当前登录用户
SELECT USER();
4 查看用户详细信息
SELECT User,Host [,PassWord] FROM mysql.user;
4、删库
DROP DATABASE [IF EXISTS] 数据库名;
功能:删除当前数据库>>>里面的结构 数据 全都没了(慎用)
3.3 MySQL字符集
MySQL字符集包括 基字符集(CHARACTER) && 校对规则 (COLLATION)这两个概念:
latin1支持西欧字符、希腊字符等
gbk支持中文简体字符
big5支持中文繁体字符
utf8几乎支持世界所有国家的字符。
utf8mb4是真正意义上的utf-8
可以使用命令 SHOW VARIABLES like ‘character%’; 查看当前数据库默认的字符集
character_set_client MySQL 客户机字符集。
character_set_connection 数据通信链路字符集,当MySQL客户机向服务器发送请求时,请求数据以
该字符集进行编码。
character_set_database 数据库字符集。
3.3.1 utf8和utf8mb4的区别
MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门用来兼容四字节的unicode。好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。当然,为了节省空间,一般情况下使用utf8也就够了。
既然utf8能够存下大部分中文汉字,那为什么还要使用utf8mb4呢? 原来mysql支持的 utf8 编码最大字符长度为 3 字节,如果遇到 4 字节的宽字符就会插入异常了。三个字节的 UTF-8 最大能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多文种平面(BMP)。也就是说,任何不在基本多文本平面的 Unicode字符,都无法使用 Mysql 的 utf8 字符集存储。包括 Emoji 表情(Emoji 是一种特殊的 Unicode 编码,常见于 ios 和 android 手机上),和很多不常用的汉字,以及任何新增的 Unicode 字符,如表情等等(utf8的缺点)。
因此在8.0之后,建议大家使用utf8mb4这种编码。
3.4 数据库设计与数据库对象
3.4.1数据库设计的步骤
为啥要进行数据库设计
糟糕的数据库设计 VS 成熟的数据库设计
数据冗余,存储空间造成浪费 VS 节省数据的存储空间
内存 日志 空间浪费 VS 完整性高,数据原子性强
数据的更新和插入时时刻刻伴随着风险和异常 VS 方便进行数据库应用和系统开发
那么如何进行数据库设计??

步骤:
1.需求分析阶段:旨在分析客户的业务和数据处理的需求
2.概要设计阶段:设计出数据库的E-R模型图,确认需求信息的正确和完整性
3.详细设计阶段:运用数据库三大范式越泽,规范审核数据库结构,形成数据库模型图
4.代码编写阶段:物理实现数据库,代码实现应用
5.测试阶段: 实践||实验
6.备份还原阶段:…
3.4.2 如何绘制数据库E-R图
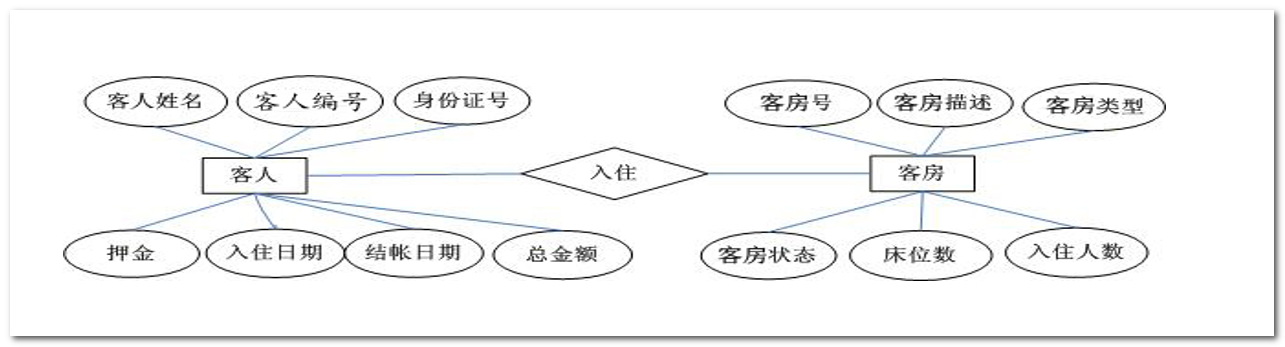
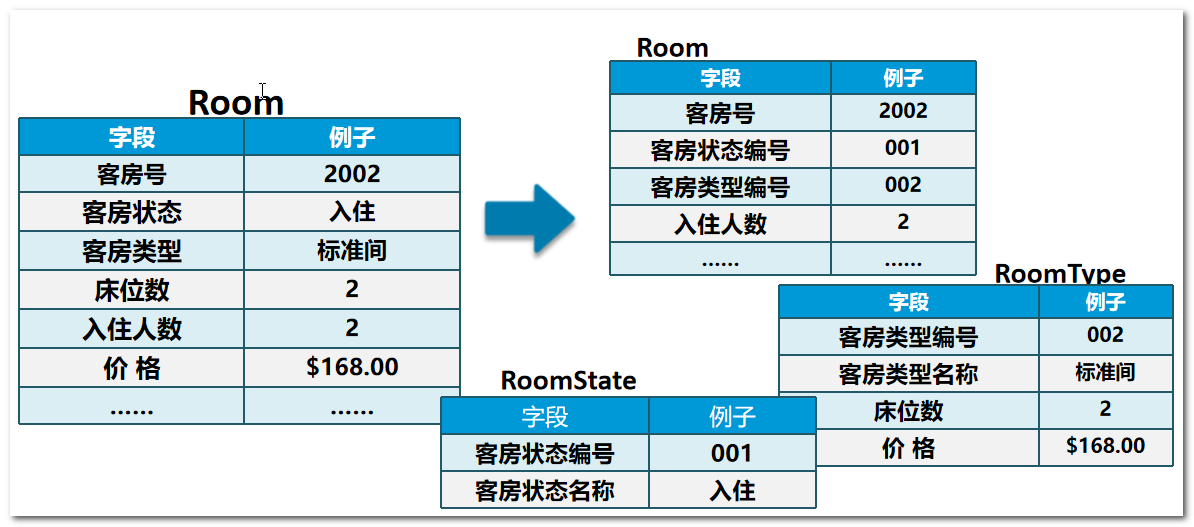
例题:酒店管理系统的基本功能:
1.收集信息:系统有关人员进行交流、座谈,充分了解用户需求,理解数据库需要完成的任务
- 旅客办理入住手续:后台数据库需要存放入住客人的信息和客房信息
- 客房信息:后台数据库需要存放客房的相关信息,如客房号、床位数、价格等
- 客房管理信息:后台数据库需要保存客房类型信息和客房当前状态信息
2.标识出实体:数据库要管理的关键对象或实体内容,实体通常情况下 是一个名词
- 客人:入住酒店的旅客。办理入职手续时,需填写用户信息。
- 客房:酒店为客人提供休息的住所。
3.标识出每个实体的属性:
- 客人属性:编号 姓名 身份证…
- 客房属性:编号 名称 床位 状态 类型…
4.标识出实体和实体之间的关系:
? 实体和实体之间的关系 通常用动词去描述
? 入住 关系
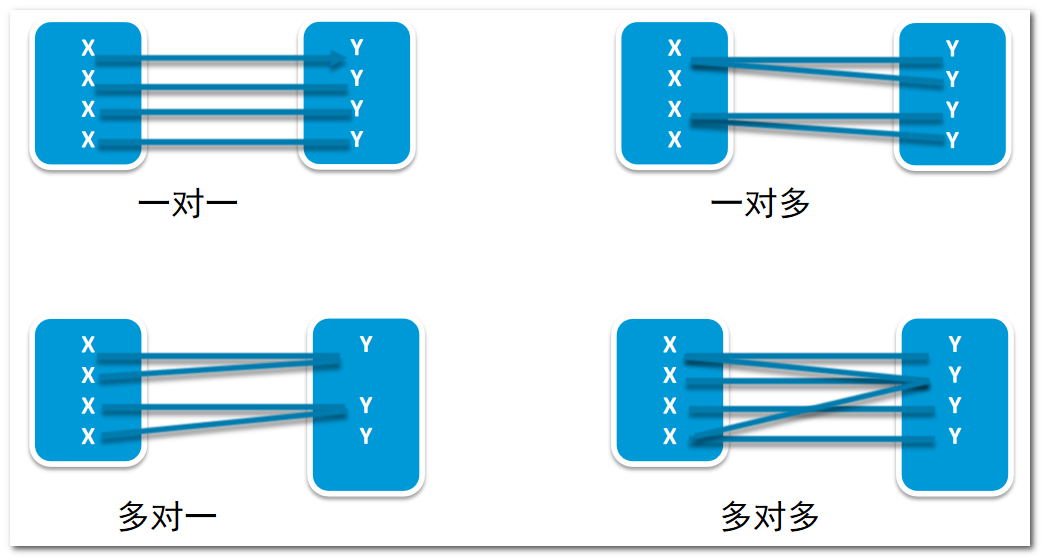
? 客房和客人之间 存在主从关系 ====> 客房是主1 客人是从N
? 1对N关系 ====> 被引用 引用关系
? 从设计角度上来说 就是 N个人可以住一个房子
? 客房被客人引用了 >>>> 客人引用了客房
绘制E-R 实体关系图(三要素)
| 符号 | 含义 |
|---|---|
| 矩形 | 实体,一般是名词 |
| 椭圆形 | 实体,一般是名词 |
| 菱形 | 关系,一般是动词 |
关系型数据库常见映射基数
转化E-R图形成数据库模型图
1 将各实体转化为对应的各表,将各属性对应成为各表的列。
2 标识出每个表的主键列(非空+唯一),一张表有且只有一个主键列。
3 在表之间建立主外键,形成引用被引用关系。

3.4.3使用三大范式实现数据库设计规范化
为什么要进行数据规范化设计
缺点:
- 信息重复
- 更新异常
- 插入异常_无法正确表示信息
- 删除异常_丢失有效信息
三大范式原则:
第一范式 (1st NF)
- 第一范式的目标是确保每列的原子性
- 如果每列都是不可再分的最小数据单元(也称为最小的原子单元),则满足第一范式(1NF)
第二范式(2st NF)
- 第二范式要求每个表只描述一件事情
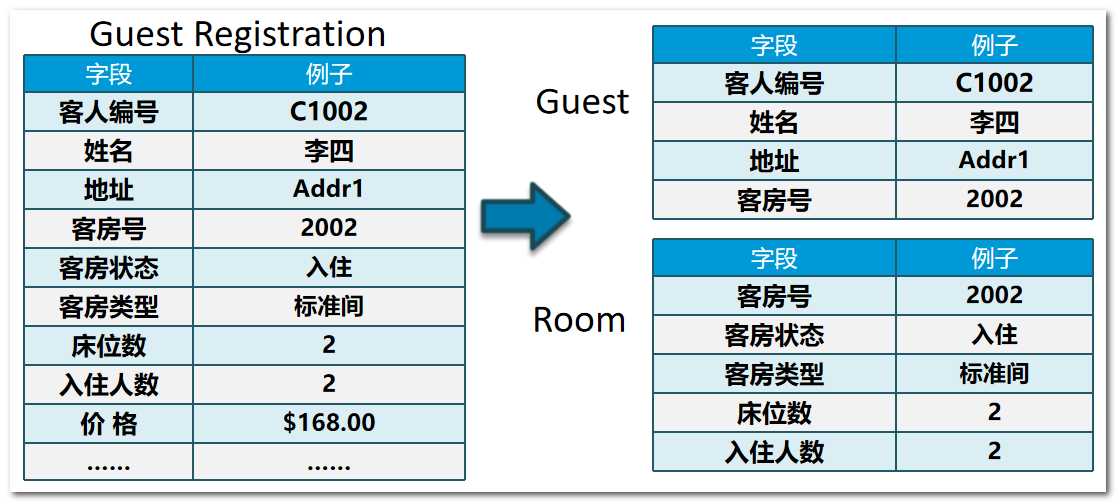
第三范式 (3st NF)
- 如果一个关系满足2NF,并且除了主键以外的其他列都不传递依赖于主键列,则满足第三范式(3NF)
规范化的酒店管理系统E-R图
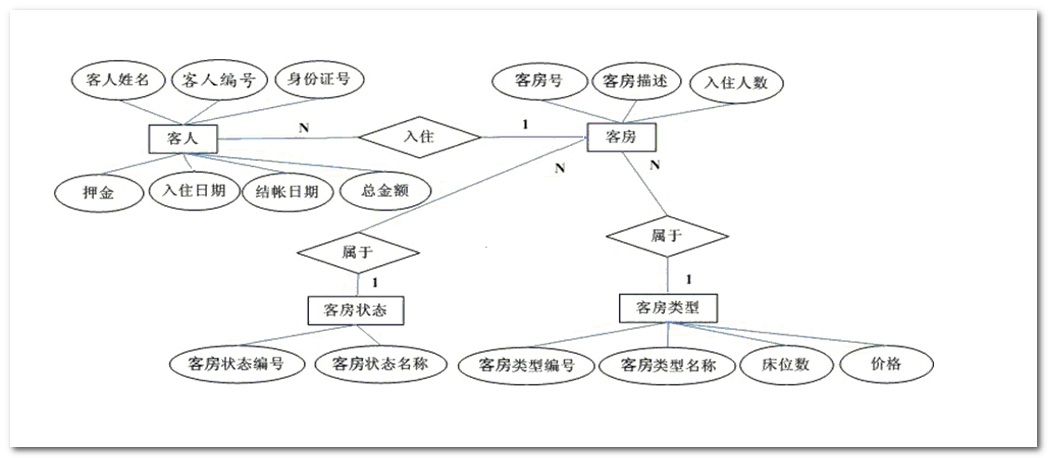
规范化的酒店管理系统数据库模型图
后面就可以开心的完成建表的操作了
3.4.5 课后练习题
某学校要设计一个数据库,学校的业务规则概括如下:
- 学校内班级若干,每个班级内又有学生若干。
- 学校开设课程若干,只有某些特定的班级能上指定的课程。
- 学生选修某些课程,但是在自身班级下的课程是必修。
- 学校定期组织考试,成绩囊括所有学生所有课程的考试成绩。
要求根据上述需求,完成E-R图的构建,并通过三大范式的规范设计出数据库模型图。
解答
实体
系 科目 学生 成绩
属性
系:系编号(PK) 系名称
科目:科目编号(PK) 科目名称 学习时长 系编号
学生:学号(PK) 密码 姓名 性别 系编号 联系电话 生日 邮箱 身份证号码 住址
成绩:学号(FK) 科目号(FK) 考试日期 考试成绩
关系
1系>>>N学生 主从关系
1系>>>N科目
1学生>>>N成绩
1科目>>>N成绩
=========================> N学生<<<>>>N科目
1:建库 MySchool_db
CREATE DATABASE Myschool_db;
2:建表(先主后从)
2.1创建年级表
CREATE TABLE grade(
GradeID INT NOT NULL AUTO_INCREMENT COMMENT '年级编号',
GradeName VARCHAR(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '年级名称',
PRIMARY KEY (GradeID)
) ENGINE = InnoDB AUTO_INCREMENT = 7 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci;
2.2创建科目表
DROP TABLE IF EXISTS subject;
CREATE TABLE subject (
SubjectNo int NOT NULL AUTO_INCREMENT COMMENT '课程编号',
SubjectName varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '课程名称',
ClassHour int NULL DEFAULT NULL COMMENT '学时',
GradeID int NULL DEFAULT NULL COMMENT '年级编号',
PRIMARY KEY (SubjectNo)
) ENGINE = InnoDB AUTO_INCREMENT = 17 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci
2.3创建学生表
DROP TABLE IF EXISTS student;
CREATE TABLE student (
StudentNo int(0) NOT NULL COMMENT '学号',
LoginPwd varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
StudentName varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '学生姓名',
Sex tinyint(1) NULL DEFAULT NULL COMMENT '性别,取值0或1',
GradeId int(0) NULL DEFAULT NULL COMMENT '年级编号',
Phone varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '联系电话,允许为空,即可选输入',
Address varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '地址,允许为空,即可选输入',
BornDate datetime(0) NULL DEFAULT NULL COMMENT '出生时间',
Email varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '邮箱账号,允许为空,即可选输入',
IdentityCard varchar(18) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL COMMENT '身份证号',
PRIMARY KEY (StudentNo) USING BTREE,
UNIQUE INDEX IdentityCard(IdentityCard) USING BTREE,
INDEX Email(Email) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci;
2.4创建成绩表
CREATE TABLE result (
StudentNo int(0) NOT NULL COMMENT '学号',
SubjectNo int(0) NOT NULL COMMENT '课程编号',
ExamDate datetime(0) NOT NULL COMMENT '考试日期',
StudentResult int(0) NOT NULL COMMENT '考试成绩',
INDEX SubjectNo(SubjectNo) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci;
>>>>>>
为subject表添加外键约束
ALTER TABLE subject ADD CONSTRAINT fk_subgra FOREIGN KEY (GradeID) REFERENCES grade (GradeID);
为student表添加外键约束
ALTER TABLE student ADD CONSTRAINT fk_stugra FOREIGN KEY (GradeID) REFERENCES grade (GradeID);
3.5 表的基本操作
3.5.1 创建表
建表的语法
标准的建表(table)语法(列定义之间以英文逗号,隔开):
数据表的每行称为一条记录(record),每一列称为一个字段(field):
主键(字段)列:唯一标识某一行的列:
CREATE TABLE 表名(
列名(字段名) 类型,
列名(字段名) 类型,
列名(字段名) 类型,
列名(字段名) 类型,
列名(字段名) 类型
) ENGINE = 存储结构;
表名采用大驼峰命名如 >>> Students Subject StudentResult
列名采用小驼峰命名如 >>> studentName subjectName resultDate
3.5.2 表物理存储结构
MyISAM || InnoDB(默认)
存储列相关信息,描述表结构文件,字段长度等
如果采用共存储模式的,数据信息和索引信息都存储在ibdata1中,
如果采用分区存储,还会有一个t.par文件(用来存储分区信息)。
3.5.3 数据类型
在mysql中,常用数据类型有三种:1、文本类型 2、数字类型 3、日期/时间类型
文本类型类型:
| 数据类型 | 描述 |
|---|---|
| CHAR(size) | 保存固定长度的字符串(可包含字母、数字以及特殊字 符)。在括号中指定字符串的长度。最多 255 个字符。 |
| VARCHAR(size) | 保存可变长度的字符串(可包含字母、数字以及特殊字 符)。在括号中指定字符串的最大长度。最多 255 个字 符。如果size>255,则类型会自动转换为TEXT类型。 |
| TEXT | 存放最大长度为 65,535 个字符的字符串。 |
| TINYTEXT | 存放最大长度为 255 个字符的字符串。 |
| MEDIUMTEXT | 存放最大长度为 16,777,215 个字符的字符串。 |
| LONGTEXT | 存放最大长度为 4,294,967,295 个字符的字符串。 |
| BLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 65,535 字节的数据。 |
| MEDIUMBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 16,777,215 字节的数据。 |
| LONGBLOB | 用于 BLOBs (Binary Large OBjects)。存放最多 4,294,967,295 字节的数据。 |
| ENUM | 枚举类型 |
数字类型:
| 数据类型 | 描述 |
|---|---|
| TINYINT(size) | -128 到 127 常规。 0 到 255 无符号*。在括号中规定最 大位数 |
| SMALLINT(size) | -32768 到 32767 常规。 0 到 65535 无符号*。在括号中 规定最大位数。 |
| MEDIUMINT(size) | -8388608 到 8388607 普通。 0 到 16777215 无符号*。在 括号中规定最大位数。 |
| INT(size) | -2147483648 到 2147483647 常规。 0 到 4294967295 无 符号*。在括号中规定最大位数。 |
| BIGINT(size) | -9223372036854775808 到 9223372036854775807 常规。 |
| FLOAT(size,d) | 带有浮动小数点的小数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DOUBLE(size,d) | 带有浮动小数点的大数字。在括号中规定最大位数。在 d 参数中规定小数点右侧的最大位数。 |
| DECIMAL(size,d) | 作为字符串存储的 DOUBLE 类型,允许固定的小数点。 |
时间\日期类型:
| 数据类型 | 描述 |
|---|---|
| DATE() | 日期。格式:YYYY-MM-DD 取值范围 ‘1000-01-01’ <<<>>> ‘9999-12-31’ |
| DATETIME() | 日期和时间的组合。格式: YYYY-MM-DD HH:MM:SS 注释:支持的范围是’1000-01-01 00:00:00’ <<<>>> ‘9999-12- 31 23:59:59’ |
| TIMESTAMP() | 时间戳。 TIMESTAMP 值使用 Unix 纪元(‘1970-01-01 00:00:00’ UTC) 至今的描述来存储。格式: YYYY-MM-DD HH:MM:SS 注释:支持的范围是从 ‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-09 03:14:07’ UTC |
| TIME() | 时间。格式: HH:MM:SS 注释:支持的范围是从 ‘-838:59:59’ 到 ‘838:59:59’ |
| YEAR() | 2 位或 4 位格式的年。 注释: 4 位格式所允许的值: 1901 到 2155。 2 位格式所允许 的值: 70 到69,表示从 1970 到 2069 |
常用数据类型:
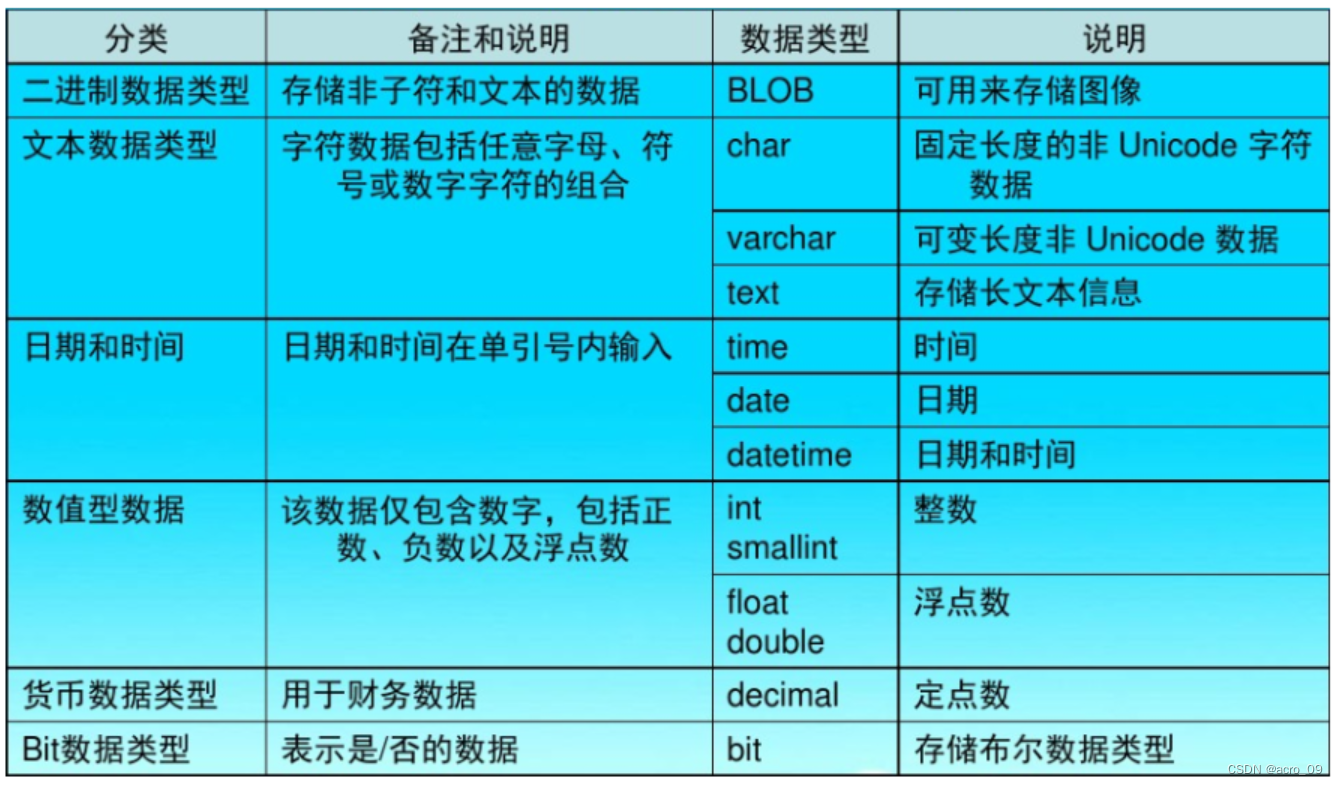
3.5.4 查看表
SHOW命令
语法:
SHOW TABLES [FROM 数据库名] [LIKE wild];
查看表结构:
SHOW COLUMNS FROM 表名
3.5.5 删除表
DROP TABLE [IF EXISTS] 表名
示例:
#创建学生表
CREATE TABLE Students(
studentNo INT(5),
studentName VARCHAR(50),
studentBirth DATE,
studentAddress VARCHAR(100),
studentTel VARCHAR(11),
studentEmail VARCHAR(50)
) ENGINE = InnoDB;
#查看表结构
SHOW COLUMNS FROM Students;
#删除表
DROP TABLE [IF EXISTS] Student;
3.5.6 修改表的结构
修改列类型
ALTER TABLE 表名 MODIFY 列名 列类型;
>>> ALTER TABLE Students MODIFY studentEmail TEXT;
添加列
ALTER TABLE 表名 ADD 列名 列类型;
>>> ALTER TABLE Students ADD studentGender CHAR(2);
删除列
ALTER TABLE 表名 DROP 列名; 删除时注意数据完整性
>>> ALTER TABLE Students DROP studentGender;
改列名
ALTER TABLE 表名 CHANGE 旧列名 新列名 列类型;
>>> ALTER TABLE Students CHANGE studentEmail studentEma VARCHAR(50);
改表名
ALTER TABLE 表名 RENAME 新表名;
RENAME TABLE 表名 TO 新表名;
3.5.7 复制表的结构(考虑到数据问题)
复制表的结构有两种手段
方式1:
在 CREATE TABLE 语句的末尾加入 LIKE 源表;
>>> CREATE TABLE Students1 LIKE Students;
方式2:
在 CREATE TABLE 语句末尾添加 SELECT 关键字;
>>> CREATE TABLE Students2 SELECT * FROM Students;
方法3:
如果已经有一张表了(结构一定要和源表一样)
>>> INSERT INTO 表名 SELECT * FROM 源表;
3.5.8 数据库字典
由 information_schema 数据库负责维护
tables-存放数据库里所有的数据表、以及每个表所在数据库。
schemata-存放数据库里所有的数据库信息
views-存放数据库里所有的视图信息。
columns-存放数据库里所有的列信息。
triggers-存放数据库里所有的触发器。
routines-存放数据库里所有存储过程和函数。
key_column_usage-存放数据库所有的主外键
table_constraints-存放数据库全部约束。
statistics-存放了数据表的索引。
3.5.9 表的约束
是在表上强制执行的数据校验规则。约束主要用于保证数据库的完整性。当表中数据有相互依赖性时,可以保护相关的数据不被删除。大部分数据库支持下面五类完整性约束:
非空约束 NOT NULL
唯一性约束 UNIQUE KEY
主键约束(非空+唯一) PRIMARY KEY
外键约束 FOREIGN KEY
检查约束 CHECK 检查语法
默认值约束 DEFAULT
.......
加入约束的三种时机
1,建表时期加入,直接符在声明的列后。
2,建表时期加入,所有列声明完成后,单独去重新声明列的约束性。
3,建表后加入,语法参考修改列类型语法完成约束的添加。
>>>>>>>>
约束作为数据库对象,存放在系统表中,也有自己的名字
创建约束的时机
在建表的同时创建
建表后创建(修改表)
可定义列级或表级约束
有单列约束和多列约束
定义约束的语法
方式1:列级约束:在定义列的同时定义约束
语法:列定义 约束类型,
方式2:表级约束:在定义了所有列之后定义的约束
语法:
列定义
[CONSTRAINT 约束名] 约束类型(列名)
约束名的取名规则
推荐采用:表名_列名_约束类型简介
方式3:约束可以在创建表时就定义,也可以在创建完后再添加
语法:
ALTER TABLE 表名 ADD CONSTRAINT 约束名 约束类型(要约束的列名)
表的约束示例
1.非空约束(NOT NULL)
列级约束,只能使用列级约束语法定义。
确保字段值不允许为空
只能在字段级定义
>>>
CREATE TABLE Students(
studentNo INT PRIMARY KEY AUTO_INCREMENT,
studentName VARCHAR(50) NOT NULL
);
2.唯一约束
唯一性约束条件确保所在的字段或者字段组合不出现重复值
唯一性约束条件的字段允许出现多个NULL
同一张表内可建多个唯一约束
唯一约束可由多列组合而成
建唯一约束时MySQL会为之建立对应的索引。
如果不给唯一约束起名,该唯一约束默认与列名相同。
CREATE TABLE Students(
studentNo INT PRIMARY KEY AUTO_INCREMENT,
studentName VARCHAR(18) UNIQUE NOT NULL
);
3.主键约束
主键从功能上看相当于非空且唯一
一个表中只允许一个主键
主键是表中唯一确定一行数据的字段
删除表的约束
自动增长和默认值
存储引擎
主键字段可以是单字段或者是多字段的组合
当建立主键约束时,MySQL为主键创建对应的索引
主键约束名总为PRIMARY。
CREATE TABLE tb_student(
studentNo INT PRIMARY KEY AUTO_INCREMENT,
studentName VARCHAR(18)
)
4.外键约束
外键是构建于一个表的两个字段或者两个表的两个字段之间的关系
外键确保了相关的两个字段的两个关系:
子(从)表外键列的值必须在主表参照列值的范围内,或者为空(也可以加非空约束,强制不允许为空)。
当主表的记录被子表参照时,主表记录不允许被删除。
外键参照的只能是主表主键或者唯一键,保证子表记录可以准确定位到被参照的记录。
格式FOREIGN KEY (外键列名)REFERENCES 主表(参照列)
#部门
CREATE TABLE tb_dept(
dept_id INT PRIMARY KEY,
NAME VARCHAR(18),
description VARCHAR(255)
);
#员工
CREATE TABLE tb_employee(
employee_id INT PRIMARY KEY,
NAME VARCHAR(18),
gender VARCHAR(10),
dept_id INT REFERENCES tb_dept(dept_id),
address VARCHAR(255)
);
5.检查约束
#注意检查约束在8.0之前,MySQL默认但不会强制的遵循check约束(写不报错,但是不生效,需要通触发器完成)
# 8之后就开始正式支持这个约束了。
create table t3(
id int,
age int check(age > 18),
gender char(1) check(gender in ('M','F'))
);
6.自动增长
auto_increment :自动增长
为新的行产生唯一的标识
一个表只能有一个auto_increment,且该属性必须为主键的一部分。auto_increment的属性可以是任何整数类型
7.默认值
default : 默认值
综合实践:
# 默认值
可以使用default关键字设置每一个字段的默认值。
-- 创建一张user表
CREATE TABLE User(
id INT(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
name VARCHAR(225) COMMENT '姓名',
sex TINYINT(1) DEFAULT 1 COMMENT '性别 1男 0女',
PRIMARY KEY (id)
) ENGINE=INNODB CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【zlm】针对单个设备的码率的设置
- 【51单片机系列】51单片机的中断系统使用总结一
- (2022|CVPR,非自回归,掩蔽图像生成,迭代译码)MaskGIT:掩蔽生成式图像 Transformer
- 自己用原生js写jquery能够达到寻找节点,调用方法的效果。
- Python seaborn-多重子图(Seaborn篇-05)
- codesys【程序】
- Baumer工业相机堡盟工业相机如何通过NEOAPI SDK实现Bitmap的图像转换功能(C++)
- Linux基础开发工具--vim
- 成倍提高生产力工具Notion
- 期货日数据维护与使用_日数据维护_主力合约计算逻辑