一文带你了解Quartz
写在文章开头
你好,我叫sharkchili,目前还是在一线奋斗的Java开发,经历过很多有意思的项目,也写过很多有意思的文章,是CSDN
Java领域的博客专家,也是Java
Guide的维护者之一,非常欢迎你关注我的公众号:写代码的SharkChili,这里面会有笔者精心挑选的并发、JVM、MySQL数据库专栏,也有笔者日常分享的硬核技术小文。

Quartz是一款轻量级且特性丰富的任务调度库,它是基于Java实现的调度框架,本文会针对日常任务调度的使用场景来演示Quartz的使用姿势。
实用Quartz的目的就是为了让认读调度更加丰富、高效且安全,只需调用几个接口进行一些简单配置,即可快速实现一个任务调度程序。
基础实用示例
首先自然是引入Quartz的依赖:
<!--quartz-->
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.2</version>
</dependency>
都说Quartz是任务调度框架,从源码就可以看出其本质也就是工作线程轮询并执行继续的调度任务:
public void run() {
qs.addInternalSchedulerListener(this);
try {
OperableTrigger trigger = (OperableTrigger) jec.getTrigger();
JobDetail jobDetail = jec.getJobDetail();
do {
JobExecutionException jobExEx = null;
Job job = jec.getJobInstance();
//略
// execute the job
try {
log.debug("Calling execute on job " + jobDetail.getKey());
job.execute(jec);
endTime = System.currentTimeMillis();
} catch (JobExecutionException jee) {
//略
} catch (Throwable e) {
//略
}
//略
break;
} while (true);
} finally {
qs.removeInternalSchedulerListener(this);
}
}
从源码可以看出Quartz将任务定义为Job,Job是工作任务调度的接口,该接口定义了execute方法,所以当我们需要提交任务给Quartz时,就需要继承Job接口并在execute方法里告知要执行的任务:
@Slf4j
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) {
String dateTime = LocalDateTime.now()
.format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
log.info("任务执行时间:{}", dateTime);
}
}
有了Job,就需要安排调度计划,在Quartz这个框架中,Trigger就是告知调度器如何进行任务触发的触发器,使用代码如下所示:
- 基于JobBuilder创建job,并声称job的名称。
- 定义触发器,该触发器立即启动并设置名称为testTrigger,触发器属于testTriggerGroup分组中,执行计划为1s1次。
最后就是声明scheduler将触发器和任务关联,通过scheduler的scheduleJob方法关联,就会形成一个以Job为工作内容,并按照触发器的安排进行任务的调度的任务定时被调度器执行。
注意该方法还会返回第一次执行的时间,一旦调用start,当前方法调度工作就正式开始了。
public static void main(String[] args) throws Exception {
// 获取任务调度的实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 定义任务调度实例, 并与TestJob绑定
JobDetail job = JobBuilder.newJob(MyJob.class)
.withIdentity("myJob", "myJobGroup")
.build();
// 定义触发器, 会马上执行一次, 接着1秒执行一次
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("testTrigger", "testTriggerGroup")
.startNow()
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(1))
.build();
// 使用触发器调度任务的执行 获取任务调度时间
Date date =scheduler.scheduleJob(job, trigger);
// 开启任务
scheduler.start();
}
对应的输出结果如下所示,任务不间断1s执行1次:
22:48:30.361 [main] INFO org.quartz.impl.StdSchedulerFactory - Quartz scheduler 'DefaultQuartzScheduler' initialized from default resource file in Quartz package: 'quartz.properties'
22:48:30.361 [main] INFO org.quartz.impl.StdSchedulerFactory - Quartz scheduler version: 2.3.2
22:48:30.370 [main] INFO org.quartz.core.QuartzScheduler - Scheduler DefaultQuartzScheduler_$_NON_CLUSTERED started.
22:48:30.416 [DefaultQuartzScheduler_Worker-1] INFO com.sharkchili.quartzExample.MyJob - 任务执行时间:2024-01-04 22:48:30
22:48:31.383 [DefaultQuartzScheduler_Worker-2] INFO com.sharkchili.quartzExample.MyJob - 任务执行时间:2024-01-04 22:48:31
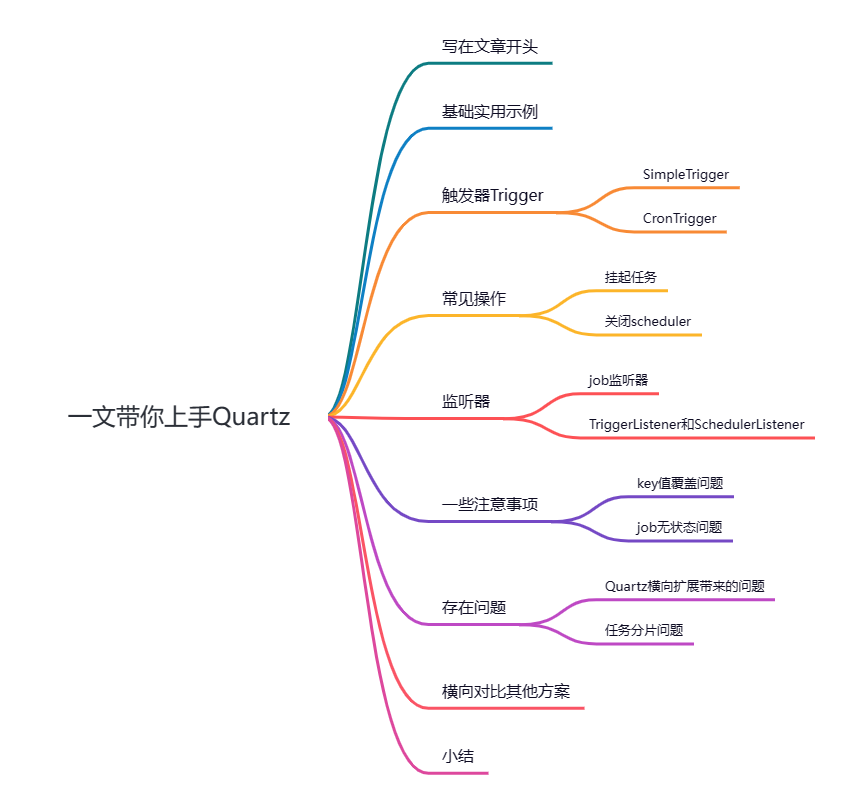
可以看出Quartz的工作核心就是,通过Job来指定任务的详情,结合触发器Trigger指定任务的执行时间和间隔还有次数等信息,再让调度器scheduler定期去执行前两者关联而生成的定时任务。
触发器Trigger
SimpleTrigger
默认情况下我们使用的都是SimpleTrigger,它支持设置任务触发起止时间,例如我们现在要求任务从现在开始执行,5s后直接停止,我们就可以通过startAt、endAt设置任务执行的时间区间,如此一来任务在执行5s后就不再触发了:
DateTime startTime = DateUtil.date();
DateTime endTime = DateUtil.offsetSecond(startTime, 5);
// 定义触发器, 会马上执行一次, 接着1秒执行一次
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("testTrigger", "testTriggerGroup")
.startNow()
.startAt(startTime)
.endAt(endTime)
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(1))
.build();
CronTrigger
如果我们希望使用Cron表达式调度任务,那么就可以使用CronTrigger,使用示例如下,笔者这里采用1s执行1次的表达式,更多cron表达式建议到这个工具网站生成:在线Cron表达式生成器
public static void cronTriggerExample() throws SchedulerException {
// 获取任务调度的实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 定义任务调度实例, 并与TestJob绑定
JobDetail job = JobBuilder.newJob(MyJob.class)
.withIdentity("myJob", "myJobGroup")
.usingJobData("count", 1)
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("testTrigger", "testTriggerGroup")
.withSchedule(CronScheduleBuilder.cronSchedule("* * * * * ?"))
.build();
// 使用触发器调度任务的执行
scheduler.scheduleJob(job, trigger);
// 开启任务
scheduler.start();
}
常见操作
挂起任务
将任务调度挂起,即将调度任务全部暂停。
scheduler.standby();
关闭scheduler
如果我们希望关闭scheduler,可以通过shutdown进行,注意:true表示等待所有正在执行的job执行完毕之后,再关闭Scheduler,而false则是强制关闭。
scheduler.shutdown(false);
监听器
job监听器
对于上述三者Quartz也为我们提供了监听器,通过监听器我们可以非常方便的官渡到事件的发生和一些调度意外的逻辑响应。
如果我们希望对job进行监听则可以通过继承JobListener 实现一个监听器,该监听器为我们提供了4个方法:
- getName:获取监听器名称。
- jobToBeExecuted:JobDetail被执行时调用该方法。
- jobExecutionVetoed:JobDetail即将被执行,但又被TriggerListerner否决时会调用该方法。
- jobWasExecuted:JobDetail执行之后会调用该方法。
@Slf4j
public class MyJobListener implements JobListener {
@Override
public String getName() {
String name = getClass().getSimpleName();
log.info("监听器的名称是:" + name);
return name;
}
@Override
public void jobToBeExecuted(JobExecutionContext context) {
String jobName = context.getJobDetail().getKey().getName();
log.info("Job的名称是:" + jobName + " Scheduler在JobDetail将要被执行时调用这个方法");
}
@Override
public void jobExecutionVetoed(JobExecutionContext context) {
String jobName = context.getJobDetail().getKey().getName();
log.info("Job的名称是:" + jobName + " Scheduler在JobDetail即将被执行,但又被TriggerListerner否决时会调用该方法");
}
@Override
public void jobWasExecuted(JobExecutionContext context, JobExecutionException jobException) {
String jobName = context.getJobDetail().getKey().getName();
log.info("Job的名称是:" + jobName + " Scheduler在JobDetail被执行之后调用这个方法");
}
}
对应的对于Job的监听器,我们可以按照下面这段示例进行添加:
// 创建并注册一个全局的Job Listener
scheduler.getListenerManager()
.addJobListener(new MyJobListener(),
EverythingMatcher.allJobs());
输出结果:
23:50:05.009 [DefaultQuartzScheduler_Worker-2] INFO com.sharkchili.quartzExample.MyJobListener - 监听器的名称是:MyJobListener
23:50:05.010 [DefaultQuartzScheduler_QuartzSchedulerThread] DEBUG org.quartz.core.QuartzSchedulerThread - batch acquisition of 1 triggers
23:50:05.010 [DefaultQuartzScheduler_Worker-2] INFO com.sharkchili.quartzExample.MyJobListener - Job的名称是:myJob Scheduler在JobDetail将要被执行时调用这个方法
23:50:05.010 [DefaultQuartzScheduler_Worker-2] DEBUG org.quartz.core.JobRunShell - Calling execute on job myJobGroup.myJob
23:50:05.010 [DefaultQuartzScheduler_Worker-2] INFO com.sharkchili.quartzExample.MyJob - 任务执行时间:2024-01-04 23:50:05 ,JobDataMap:{"count":3} name:null
23:50:05.010 [DefaultQuartzScheduler_Worker-2] INFO com.sharkchili.quartzExample.MyJobListener - 监听器的名称是:MyJobListener
23:50:05.010 [DefaultQuartzScheduler_Worker-2] INFO com.sharkchili.quartzExample.MyJobListener - Job的名称是:myJob Scheduler在JobDetail被执行之后调用这个方法
TriggerListener和SchedulerListener
对应的TriggerListener和SchedulerListener同理,这里就不多做解释了。
触发器监听器MyTriggerListener 示例代码如下,读者可参考日志的注释了解其每个监听回调的执行时间点:
@Slf4j
public class MyTriggerListener implements TriggerListener {
private String name;
public MyTriggerListener(String name) {
this.name = name;
}
@Override
public String getName() {
return name;
}
@Override
public void triggerFired(Trigger trigger, JobExecutionContext context) {
String triggerName = trigger.getKey().getName();
log.info(" 触发器:{} 被触发", triggerName);
}
@Override
public boolean vetoJobExecution(Trigger trigger, JobExecutionContext context) {
String triggerName = trigger.getKey().getName();
log.info(" {} 返回false,表示触发器并没有否决,该任务将被触发", triggerName);
return false; // true:表示不会执行Job的方法
}
@Override
public void triggerMisfired(Trigger trigger) {
String triggerName = trigger.getKey().getName();
log.info(" {}:错过触发", triggerName);
}
@Override
public void triggerComplete(Trigger trigger, JobExecutionContext jobExecutionContext, Trigger.CompletedExecutionInstruction completedExecutionInstruction) {
String triggerName = trigger.getKey().getName();
log.info("{}: 完成之后触发", triggerName);
}
}
对应的这里也给出监听器的设置示例:
// 创建并注册一个全局的Trigger Listener
scheduler.getListenerManager().addTriggerListener(new MyTriggerListener("simpleTrigger"), EverythingMatcher.allTriggers());
SchedulerListener 示例如下,读者可以参照注释调试理解:
@Slf4j
public class MySchedulerListener implements SchedulerListener {
@Override
public void jobScheduled(Trigger trigger) {
String jobName = trigger.getJobKey().getName();
log.info(jobName + " 完成部署");
}
@Override
public void jobUnscheduled(TriggerKey triggerKey) {
log.info(triggerKey + " 完成卸载");
}
@Override
public void triggerFinalized(Trigger trigger) {
log.info("触发器被移除 " + trigger.getJobKey().getName());
}
@Override
public void triggerPaused(TriggerKey triggerKey) {
log.info(triggerKey + " 正在被暂停");
}
@Override
public void triggersPaused(String triggerGroup) {
log.info("触发器组 " + triggerGroup + " 正在被暂停");
}
@Override
public void triggerResumed(TriggerKey triggerKey) {
log.info(triggerKey + " 正在从暂停中恢复");
}
@Override
public void triggersResumed(String triggerGroup) {
log.info("触发器组 " + triggerGroup + " 正在从暂停中恢复");
}
@Override
public void jobAdded(JobDetail jobDetail) {
log.info(jobDetail.getKey() + " 添加工作任务");
}
@Override
public void jobDeleted(JobKey jobKey) {
log.info(jobKey + " 删除工作任务");
}
@Override
public void jobPaused(JobKey jobKey) {
log.info(jobKey + " 工作任务正在被暂停");
}
@Override
public void jobsPaused(String jobGroup) {
log.info("工作任务组 " + jobGroup + " 正在被暂停");
}
@Override
public void jobResumed(JobKey jobKey) {
log.info(jobKey + " 正在从暂停中恢复");
}
@Override
public void jobsResumed(String jobGroup) {
log.info("工作任务组 " + jobGroup + " 正在从暂停中恢复");
}
@Override
public void schedulerError(String msg, SchedulerException cause) {
log.info("产生严重错误时调用: " + msg + " " + cause.getUnderlyingException());
}
@Override
public void schedulerInStandbyMode() {
log.info("调度器在挂起模式下调用");
}
@Override
public void schedulerStarted() {
log.info("调度器 开启时调用");
}
@Override
public void schedulerStarting() {
log.info("调度器 正在开启时调用");
}
@Override
public void schedulerShutdown() {
log.info("调度器 已经被关闭 时调用");
}
@Override
public void schedulerShuttingdown() {
log.info("调度器 正在被关闭 时调用");
}
@Override
public void schedulingDataCleared() {
log.info("调度器的数据被清除时调用");
}
}
对应的监听配置:
// 创建并注册一个全局的Trigger Listener
scheduler.getListenerManager().addTriggerListener(new MyTriggerListener("simpleTrigger"), EverythingMatcher.allTriggers());
// 创建SchedulerListener
scheduler.getListenerManager().addSchedulerListener(new MySchedulerListener());
一些注意事项
通过对上述基础示例的调试我们已经对Quartz的使用有了基本的了解。接下来我们就来了解一下Quartz使用的注意事项。
key值覆盖问题
当我们需要对当前任务传入一些定制化参数时,我们可以通过usingJobData方法将参数以键值对的形式存到这个任务的jobDataMap中:
public JobBuilder usingJobData(String dataKey, String value) {
jobDataMap.put(dataKey, value);
return this;
}
然后框架会将这个键值对通过反射的方式,设置到对应的成员变量中,就像下面这段代码,我们设置了name这个键值对,也就意味着Quartz启动后,对应name的键值对就会存到MyJob的name成员变量中:
@Slf4j
public class MyJob implements Job {
private String name;
public void setName(String name) {
this.name = name;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) {
String dateTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
log.info("任务执行时间:{} ,JobDataMap:{} name:{}", dateTime, JSONUtil.toJsonStr(jobExecutionContext.getJobDetail().getJobDataMap()), name);
}
}
但需要注意的是如果job和触发器trigger存在相同key时 (如下所示的name) ,执行时就会以后设置的为主。
/**
* job和trigger设置同一个key的情况下,反射后的值会以后者为主
*/
@SneakyThrows
public static void errorExamlme() {
// 获取任务调度的实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 定义任务调度实例, 并与TestJob绑定
JobDetail job = JobBuilder.newJob(MyJob.class)
.usingJobData("name", "JobDetail")
.withIdentity("myJob", "myJobGroup")
.build();
// 定义触发器, 会马上执行一次, 接着5秒执行一次
Trigger trigger = TriggerBuilder.newTrigger()
.usingJobData("name", "trigger")
.withIdentity("testTrigger", "testTriggerGroup")
.startNow()
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))
.build();
// 使用触发器调度任务的执行 获取任务调度时间
Date date =scheduler.scheduleJob(job, trigger);
// 开启任务
scheduler.start();
}
所以本次的输出name值为trigger设置的name值:
23:06:20.048 [DefaultQuartzScheduler_Worker-1] INFO com.sharkchili.quartzExample.MyJob - 任务执行时间:2024-01-04 23:06:20 ,JobDataMap:{"name":"JobDetail"} name:trigger
job无状态问题
有时候我们希望记录job的执行状态,例如没执行一次,job的count自增一下:
public class MyJob implements Job {
private String name;
public void setName(String name) {
this.name = name;
}
private Integer count;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) {
String dateTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
++count;
jobExecutionContext.getJobDetail().getJobDataMap().put("count", count);
log.info("任务执行时间:{} ,JobDataMap:{} name:{}", dateTime, JSONUtil.toJsonStr(jobExecutionContext.getJobDetail().getJobDataMap()), name);
}
}
但是这个任务执行之后却发现每次输出的count结果都是2,原因就是因为默认情况下job是无状态的,这也就意味每次执行的job都是一个全新的job实例。
@SneakyThrows
public static void errorExamlme() {
// 获取任务调度的实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
// 定义任务调度实例, 并与TestJob绑定
JobDetail job = JobBuilder.newJob(MyJob.class)
.usingJobData("name", "JobDetail")
.usingJobData("count", 1)
.withIdentity("myJob", "myJobGroup")
.build();
// 定义触发器, 会马上执行一次, 接着5秒执行一次
Trigger trigger = TriggerBuilder.newTrigger()
.usingJobData("name", "trigger")
.withIdentity("testTrigger", "testTriggerGroup")
.startNow()
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForever(5))
.build();
// 使用触发器调度任务的执行
scheduler.scheduleJob(job, trigger);
// 开启任务
scheduler.start();
}
要想解决这个问题,我们只需在job上加一个 @PersistJobDataAfterExecution 注解:
@Slf4j
@PersistJobDataAfterExecution
public class MyJob implements Job {
private String name;
public void setName(String name) {
this.name = name;
}
private Integer count;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public void execute(JobExecutionContext jobExecutionContext) {
String dateTime = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"));
++count;
jobExecutionContext.getJobDetail().getJobDataMap().put("count", count);
log.info("任务执行时间:{} ,JobDataMap:{} name:{}", dateTime, JSONUtil.toJsonStr(jobExecutionContext.getJobDetail().getJobDataMap()), name);
}
}
如此一来执行结果便是有效递增的:
23:22:42.952 [DefaultQuartzScheduler_Worker-1] INFO com.sharkchili.quartzExample.MyJob - 任务执行时间:2024-01-04 23:22:42 ,JobDataMap:{"name":"JobDetail","count":2} name:trigger
23:22:47.876 [DefaultQuartzScheduler_Worker-2] INFO com.sharkchili.quartzExample.MyJob - 任务执行时间:2024-01-04 23:22:47 ,JobDataMap:{"name":"JobDetail","count":3} name:trigger
存在问题
Quartz横向扩展带来的问题
虽说Quartz支持集群模式实现横向扩展,也就是我们常说的分布式调度,但需要业务方面通过一些手段实现节点任务执行的互斥和安全,从而避免任务重复执行等一些问题,常见的解决方案分别由数据库锁和分布式锁两种:
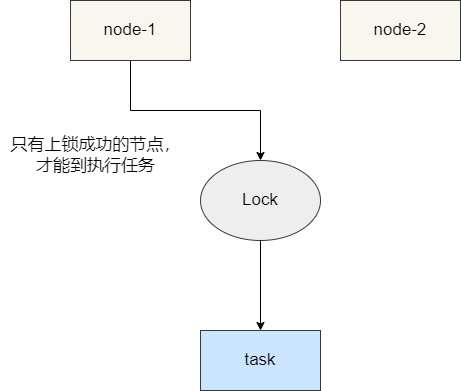
在调度进行任务争抢时先对数据库表上锁,只有拿到锁的节点才可以进行获取任务并调度,这种是常规情况下的解决方案,但这种实现方式有着很强的倾入性,且在高并发的场景性能表现也不是很出色,所以大部分情况下,我们不是很推荐通过数据表的形式实现分布式任务调度一致性。
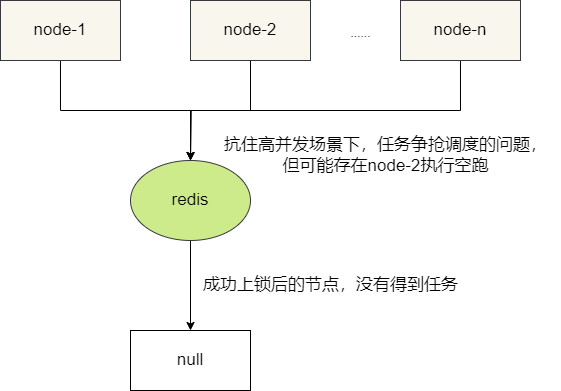
通常情况下,采用redis分布式锁是针对Quartz框架分布式任务调度的较好解决方案,通过在内存中进行任务争抢,大大提分布式调度性能,但还是存调度空跑问题,即先抢到锁的节点获取仅有的任务,而其他节点随后得锁后却没有执行任务,造成一次空跑。
任务分片问题
试想一个场景,原本一个节点负责调度全国系统的所有任务,随着业务激增我们将Quartz设置为集群模式,希望各个节点负责执行不同省份的任务。其他调度框架例如XXL-JOB,可以通过配置中心决定这个调度规则例如工具任务的编号知晓省份通过hash取模分配给不同的省份。
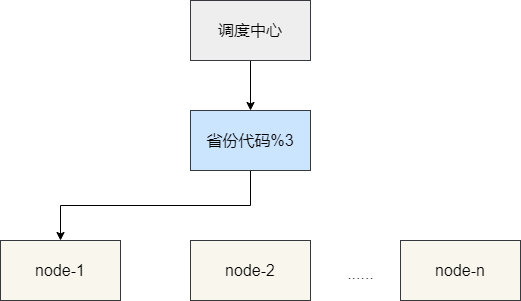
而Quartz因为没有对应的页面和配置中心,所以实现任务分片需要通过硬编码的形式来实现,有着很强的代码侵入以及实现的复杂性。
横向对比其他方案
所以对于简单且较为轻量的任务调度场景,我们可优先考虑Quartz,若希望在集群环境下实现分布式调度以及任务分片等复杂的需求时,可参照下面酌情考虑这些更高效中心化的任务调度中心xxl-job或者elastic-job:
| 对比项 | Quartz | elastic-job | xxl-job |
|---|---|---|---|
| 依赖 | mysql | jdk1.7+,zookeeper3.4.6+,maven3.0.4+,mesos | mysql,jdk1.7+,maven3.0+ |
| 集群、弹性扩容 | 多节点,部署,通过竞争数据库锁来保证只有一个节点执行任务 | 通过zookeeper的注册与发现,可以动态的添加服务器。支持水平扩容 | 使用Quartz基于数据库的分布式功能,服务器超出一定数量会给数据库造成一定的压力 |
| 任务分片 | 不支持 | 支持 | 支持 |
| 管理界面 | 无 | 支持 | 支持 |
| 高级功能 | 无 | 弹性扩容,多种作业模式,失效转移,运行状态收集,多线程处理数据,幂等性,容错处理,spring命名空间支持 | 弹性扩容,分片广播,故障转移,Rolling实时日志,GLUE(支持在线编辑代码,免发布),任务进度监控,任务依赖,数据加密,邮件报警,运行报表,国际化 |
| 缺点 | 没有管理界面,以及不支持任务分片等。不适用于分布式场景 | 需要引入zookeeper,mesos,增加系统复杂度,学习成本较高 | 调度中心通过获取DB锁来保证集群中执行任务的唯一性,如果短任务很多,随着调度中心集群数量增加,那么数据库的锁竞争会比较厉害,性能不好。 |
| 任务不能重复执行 | 数据库锁 | 将任务拆分为n个任务项后,各个服务器分别执行各自分配到的任务项。一旦有新的服务器加入集群,或现有服务器下线,elastic-job将在保留本次任务执行不变的情况下,下次任务开始前触发任重分片。 | 使用Quartz基于数据库的分布式功能 |
| 并行调度 | 采用任务分片方式实现。将一个任务拆分成n个独立的任务项,由分布式的服务器并行执行各自分配到的分片项。 | 调度系统多线程(默认10个线程)触发调度运行,确保调度精确执行,不被堵塞。 | |
| 失败处理策略 | 弹性扩容缩容在下次作业运行前重分片,但本次作业执行的过程中,下线的服务器所分配的作业将不会重新被分配。失效转移功能可以在本次作业运行中用空闲服务器抓取孤儿作业分片执行。同样失效转移功能也会牺牲部分性能。 | 调度失败时的处理策略,策略包括:失败告警(默认)、失败重试(界面可配置) | |
| 动态分片策略 | 支持多种分片策略,可自定义分片策略。 默认包含三种分片策略: 基于平均分配算法的分片策略、 作业名的哈希值奇偶数决定IP升降序算法的分片策略、根据作业名的哈希值对Job实例列表进行轮转的分片策略,支持自定义分片策略。elastic-job的分片是通过zookeeper来实现的。分片的分片由主节点分配,如下三种情况都会触发主节点上的分片算法执行:a、新的Job实例加入集群b、现有的Job实例下线(如果下线的是leader节点,那么先选举然后触发分片算法的执行)c、主节点选举” | 分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。 执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时传递分片参数;可根据分片参数开发分片任务; |
小结
这篇文章仅是笔者对于Quartz这个入门级调度框架的简单介绍,后续还会更新源码解析和其他调度框架的介绍,如有读者感兴趣或者需要完整的源码示例,读者可关注微信公众号:写代码的SharkChili,或扫描下方二维码关注,回复:QuartzExample,获取:

参考文章
Quartz 是什么?一文带你入坑:https://zhuanlan.zhihu.com/p/306591082
实现一个任务调度系统,看这篇就够了:https://juejin.cn/post/7056704703559630856
定时任务框架:quartz、elastic-job和xxl-job的分析对比。
:htps://blog.csdn.net/en_joker/article/details/104407313
定时任务框架:quartz、elastic-job和xxl-job的分析对比。
:https://blog.csdn.net/en_joker/article/details/104407313
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C练习——1到100的所有整数中出现多少次数字9
- 爱了!水浸监测这个技术,看了都说好!
- springboot/java/php/node/python葫芦卖菜管理系统【计算机毕设】
- Efficient Classification of Very Large Images with Tiny Objects(CVPR2022补1)
- 挂载mount、卸载umount,和rpm安装包
- PyQt5多线程使用
- JavaScript异常处理实战
- 跨年烟花-Html5实现_附完整源码【可直接运行】
- 基于JavaWeb+SSM+Vue微信小程序的移动学习平台系统的设计和实现
- 代码随想录算法训练营第四十三天|1049. 最后一块石头的重量 II、 494. 目标和、474.一和零