MySQL之复合查询
单表查询回顾
在讲解多表查询前,我们先回顾一下单表查询,这是因为多表查询本质上依然是单表查询(其原因在下文中讲解多表查询时再说明),只要掌握了单表查询,那么想掌握多表查询是非常简单的。
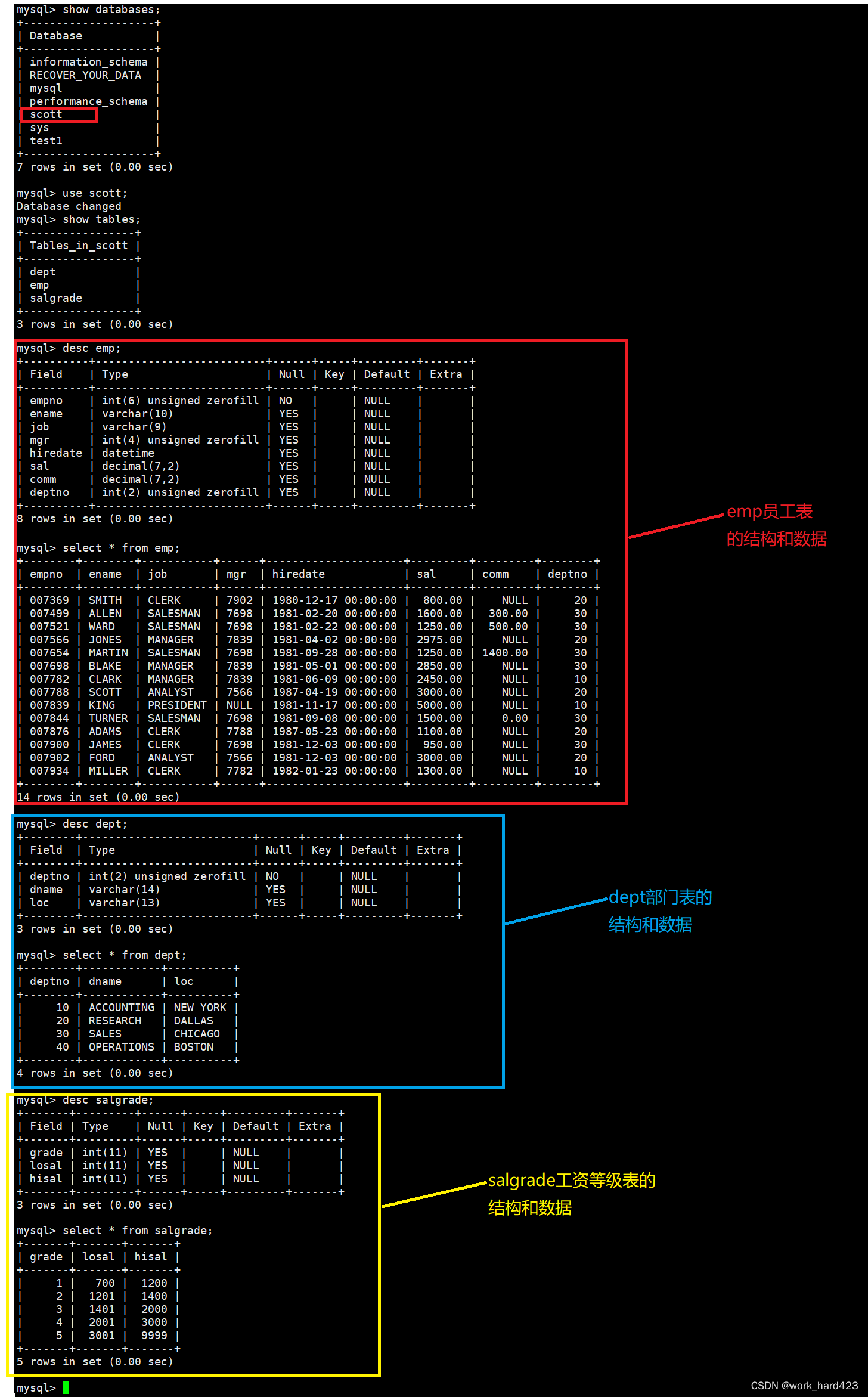
在<<MySQL之对表内容的增删查改>>一文中我们详细讲解过单表查询(注意该篇文章中的内容全是单表查询),为了回顾单表查询,咱们再把该篇文章中的emp员工表、dept部门表、salgrade工资等级表以及表中的数据全部照搬过来,至于如何照搬,咱们只需要通过【把下面的SQL语句拷贝到MySQL中执行一遍】即可做到。
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `scott`;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);
insert into dept (deptno, dname, loc)
values (10, 'ACCOUNTING', 'NEW YORK');
insert into dept (deptno, dname, loc)
values (20, 'RESEARCH', 'DALLAS');
insert into dept (deptno, dname, loc)
values (30, 'SALES', 'CHICAGO');
insert into dept (deptno, dname, loc)
values (40, 'OPERATIONS', 'BOSTON');
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7369, 'SMITH', 'CLERK', 7902, '1980-12-17', 800, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7499, 'ALLEN', 'SALESMAN', 7698, '1981-02-20', 1600, 300, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7521, 'WARD', 'SALESMAN', 7698, '1981-02-22', 1250, 500, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7566, 'JONES', 'MANAGER', 7839, '1981-04-02', 2975, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7654, 'MARTIN', 'SALESMAN', 7698, '1981-09-28', 1250, 1400, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7698, 'BLAKE', 'MANAGER', 7839, '1981-05-01', 2850, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7782, 'CLARK', 'MANAGER', 7839, '1981-06-09', 2450, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7788, 'SCOTT', 'ANALYST', 7566, '1987-04-19', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7839, 'KING', 'PRESIDENT', null, '1981-11-17', 5000, null, 10);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7844, 'TURNER', 'SALESMAN', 7698,'1981-09-08', 1500, 0, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7876, 'ADAMS', 'CLERK', 7788, '1987-05-23', 1100, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7900, 'JAMES', 'CLERK', 7698, '1981-12-03', 950, null, 30);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7902, 'FORD', 'ANALYST', 7566, '1981-12-03', 3000, null, 20);
insert into emp (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (7934, 'MILLER', 'CLERK', 7782, '1982-01-23', 1300, null, 10);
insert into salgrade (grade, losal, hisal) values (1, 700, 1200);
insert into salgrade (grade, losal, hisal) values (2, 1201, 1400);
insert into salgrade (grade, losal, hisal) values (3, 1401, 2000);
insert into salgrade (grade, losal, hisal) values (4, 2001, 3000);
insert into salgrade (grade, losal, hisal) values (5, 3001, 9999);如下图所示,执行完上面的SQL语句后,就有数据库scott和三张表、以及各个表中的数据了。?
准备工作完毕后,咱们进入正题。??
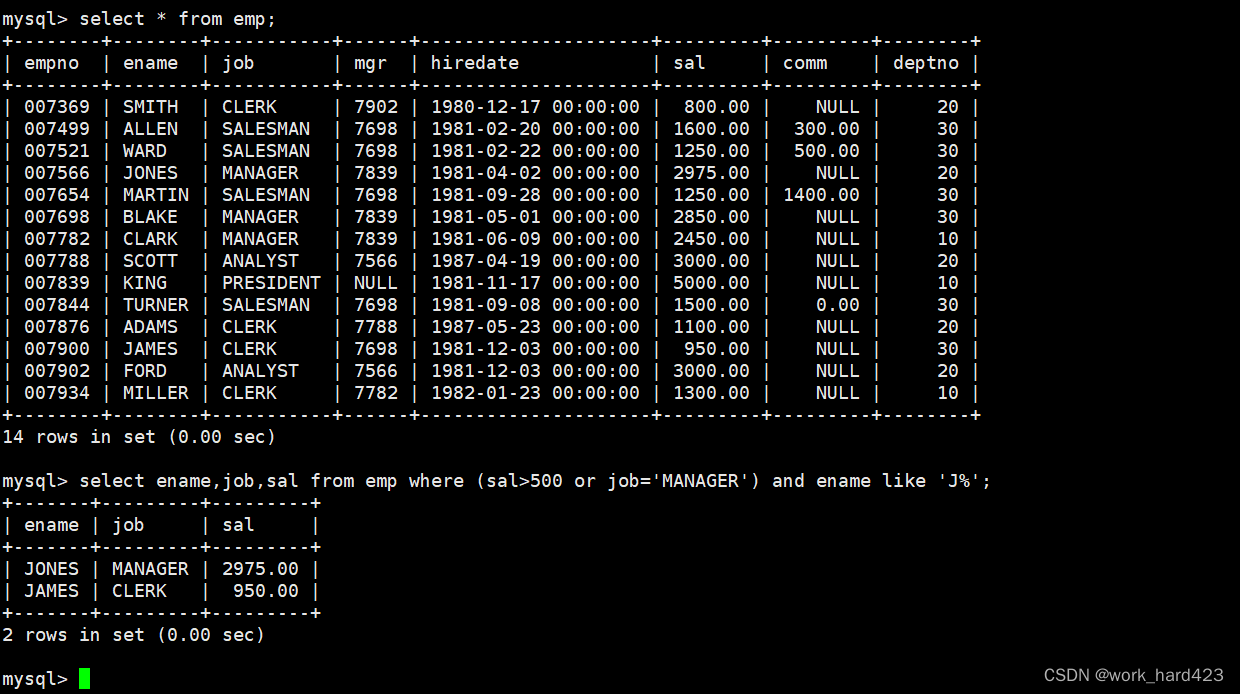
查询工资高于500或岗位为MANAGER的员工,同时要求员工姓名的首字母为大写的J,如下:
如下图所示,因为工资(即属性sal)、岗位(即属性job)、员工姓名(即属性ename)都存在于emp表中,所以我们选择select from emp查询emp表。然后要在where子句中指明筛选条件为工资高于500或岗位为MANAGER,并且通过模糊匹配指明筛选条件为员工姓名的首字母要是大写的J。
查询员工的姓名、部门号以及工资,按部门号升序并且员工工资降序的方式进行显示,如下:
如下图所示,因为员工姓名(即属性ename)、部门号(即属性deptno)、工资(即属性sal)都存在于emp表中,所以我们选择select from emp查询emp表。然后要在select的属性列表中指明要查询的属性为姓名、部门号和工资,要在order by子句中依次指明按部门号排升序和按员工工资排降序,即不同部门的员工按照部门号排升序,而同一部门的员工按员工工资排降序。

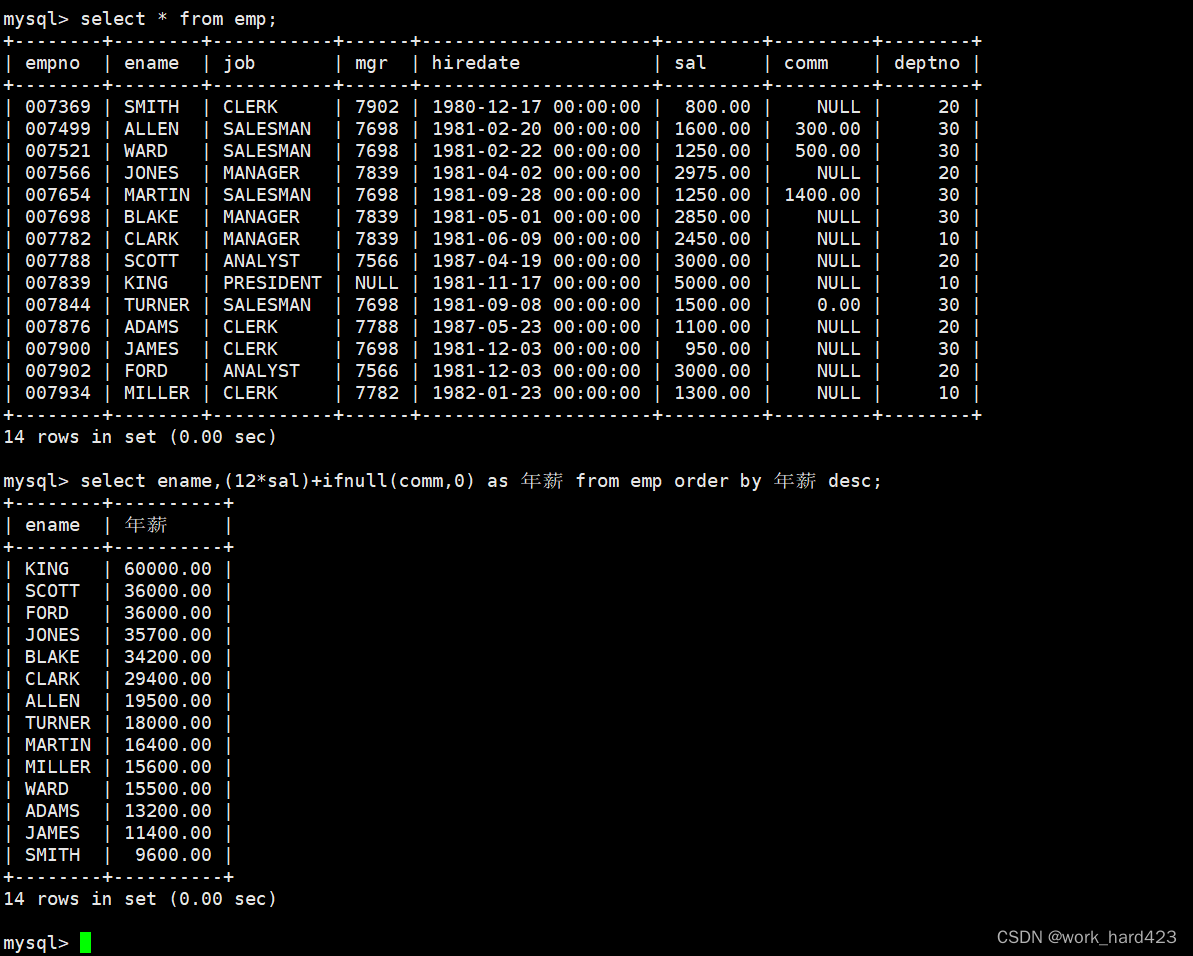
查询员工信息,按年薪降序显示,如下:
先说一下,【年薪=12个月的月薪+最后的年终奖】,而因为员工姓名(即属性ename)、月薪(即属性sal)、年终奖(即属性comm)都存在于emp表中,所以我们选择select from emp查询emp表。
然后注意,在<<MySQL之对表内容的增删查改>>一文中讲解聚合函数时证明过,NULL不参与计算和比较,任何值强行和NULL相加减乘除,都会得到NULL,而下图中有些员工的年终奖就是NULL,所以这时计算该员工的年薪时就不应该让该员工的12个月的月薪加上年终奖NULL,以避免计算出的年薪为NULL,而应该让12个月的月薪加上0,如何做到这一点呢?
答案:ifnull(val1,val2)函数具有的特性是,把表示年终奖的comm传给参数val1、把0传给参数val2后,未来如果comm的值是NULL,则该函数就会返回0,如果comm的值不是NULL,则该函数才会返回comm的值,所以我们就能根据ifnull函数的特性、通过表达式【年薪=12个月的月薪+ifnull(comm,0)】来正确地计算年薪了。
有了计算年薪的方案后,剩下的步骤就简单了,如下图所示,只需在select的属性列表中指明要查询的属性为姓名和年薪,然后在order by子句中指明按年薪进行降序排序即可。
查询工资最高的员工的姓名和岗位,如下:?
因为工资(即属性sal)、员工姓名(即属性ename)、岗位(即属性job)都存在于emp表中,所以我们选择select from emp查询emp表。
方式一:因为我们不知道表中的最高工资是多少,所以在查询工资最高的员工的姓名和岗位前,我们要先通过聚合函数max计算出表中的最高工资是多少,然后再通过where子句和该最高工资筛选出该员工的姓名和岗位,演示如下。

方式二:我们也可以使用子查询(关于子查询,会在下文中详细说明),将表示第一次查询的SQL语句用括号括起来,作为最高工资直接在表示第二次查询的SQL语句中使用。演示如下:

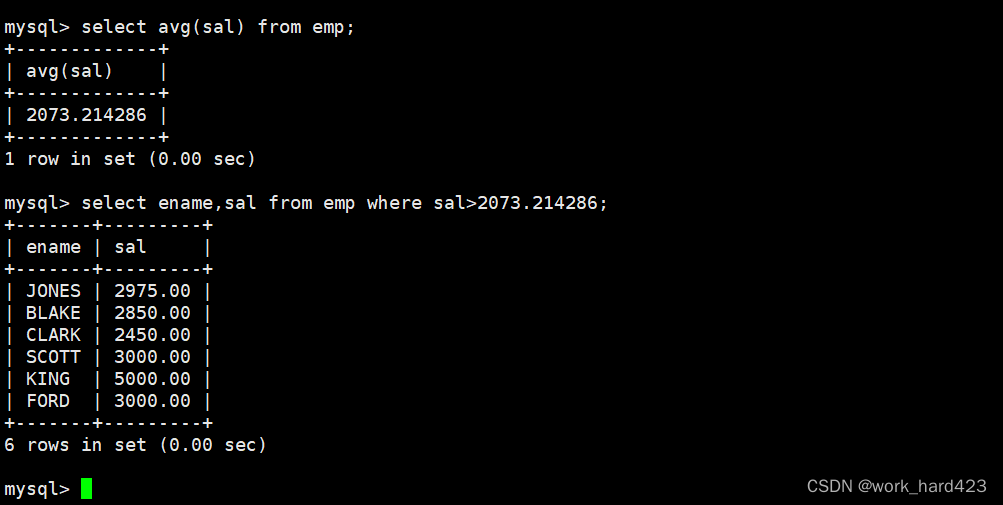
查询工资高于平均工资的员工的姓名和工资,如下:
因为工资(即属性sal)、员工姓名(即属性ename)都存在于emp表中,所以我们选择select from emp查询emp表。
方式一:因为我们不知道表中的平均工资是多少,所以在查询工资高于平均工资的员工的姓名和工资前,我们要先通过聚合函数avg计算出表中的平均工资是多少,然后再通过where子句和该平均工资筛选出该员工的姓名和工资,演示如下。
方式二:我们也可以使用子查询(关于子查询,会在下文中详细说明),将表示第一次查询的SQL语句用括号括起来,作为平均工资直接在表示第二次查询的SQL语句中使用。演示如下:

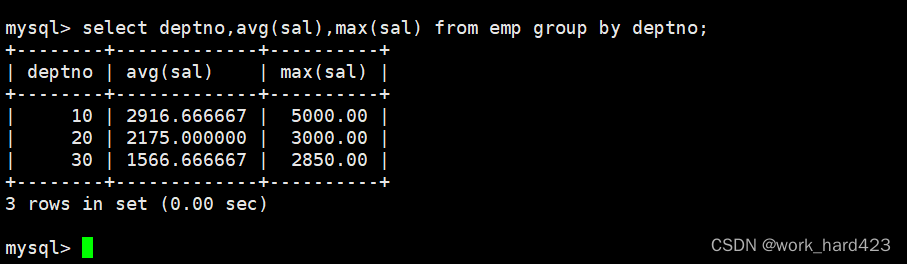
查询每个部门的平均工资和最高工资,如下:
如下图所示,因为工资(即属性sal)、部门编号(即属性deptno)都存在于emp表中,所以我们选择select from emp查询emp表。然后在group by子句中指明按照部门号进行分组,并在select语句中使用聚合函数avg和max分别查询每个部门的平均工资和最高工资即可。
查询平均工资低于2000的部门号和它的平均工资,如下:?
如下图所示,因为工资(即属性sal)、部门编号(即属性deptno)都存在于emp表中,所以我们选择select from emp查询emp表。然后在group by子句中指明按照部门号进行分组,在select语句中使用聚合函数avg查询每个部门的平均工资,并在having子句中指明筛选条件为平均工资小于2000即可得到最终结果。

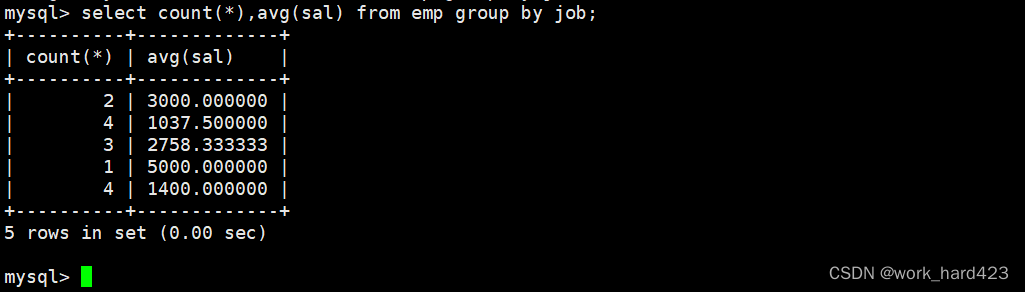
查询每种岗位的雇员总数和平均工资,如下:?
如下图所示,因为岗位(即属性job)、工资(即属性sal)都存在于emp表中,所以我们选择select from emp查询emp表。然后在group by子句中指明按照岗位进行分组,并在select语句中使用聚合函数count和avg分别查询每种岗位的雇员总数和平均工资即可。
多表查询
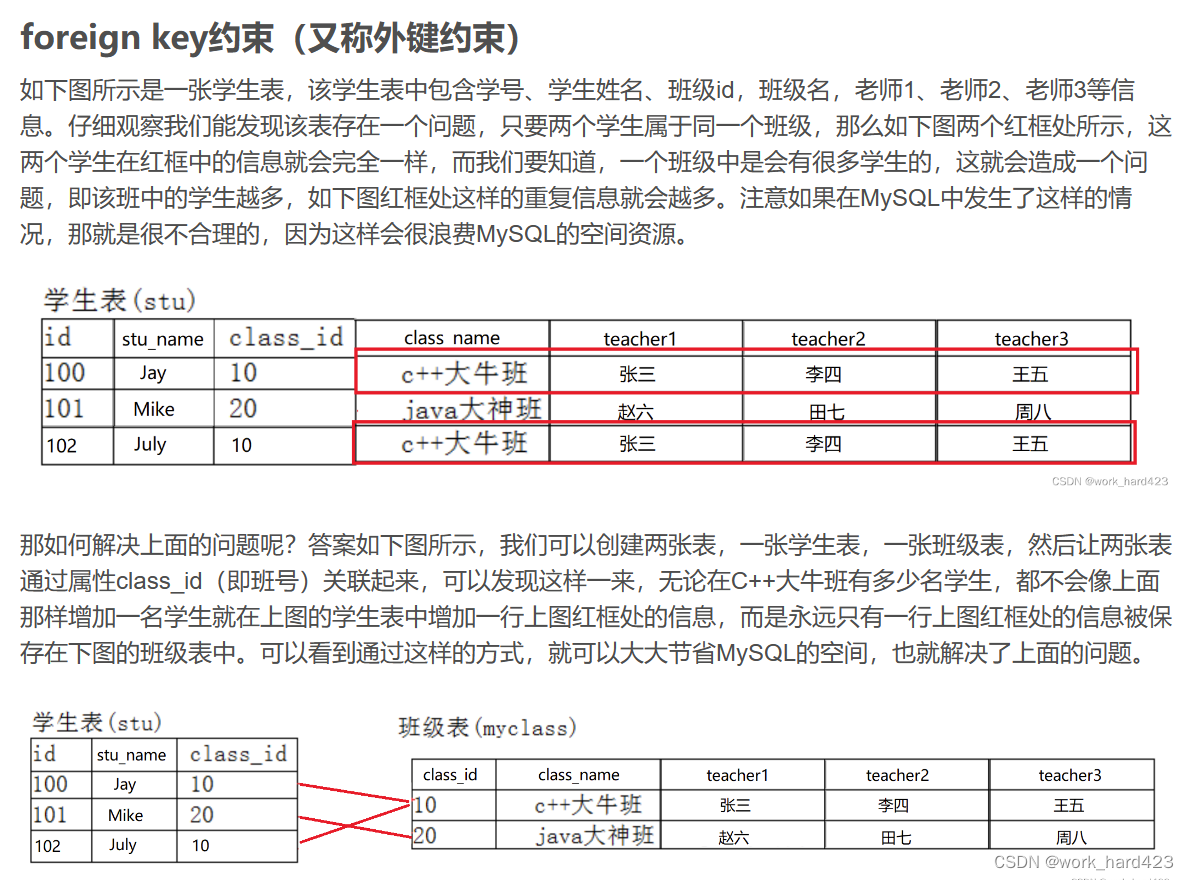
如下图所示,有时为了节省MySQL的空间资源,我们会把本可以用一张表存储的数据通过多张表存储起来,然后再将多张表通过某个在每张表中都存在的属性(如下图的class_id属性就在每张表中都存在)关联起来,这是我们曾经在讲解外键约束时说过的内容。
而当数据被分散在多张表中存储时,有时候会在MySQL中发生这样的情景:现在有一个需求,就是需要select语句将表1中的某些属性列和表2中的某些属性列在一张表中显示出来,那么很显然,此时不论是靠【select?from?表1】还是靠【select?from?表2】都无法解决问题,毕竟表1无从知晓表2中的属性,表2也无从知晓表1中的属性。
那么该怎么办呢?此时就需要通过多表查询才能做到这一点。咱们先介绍一下多表查询,如下。
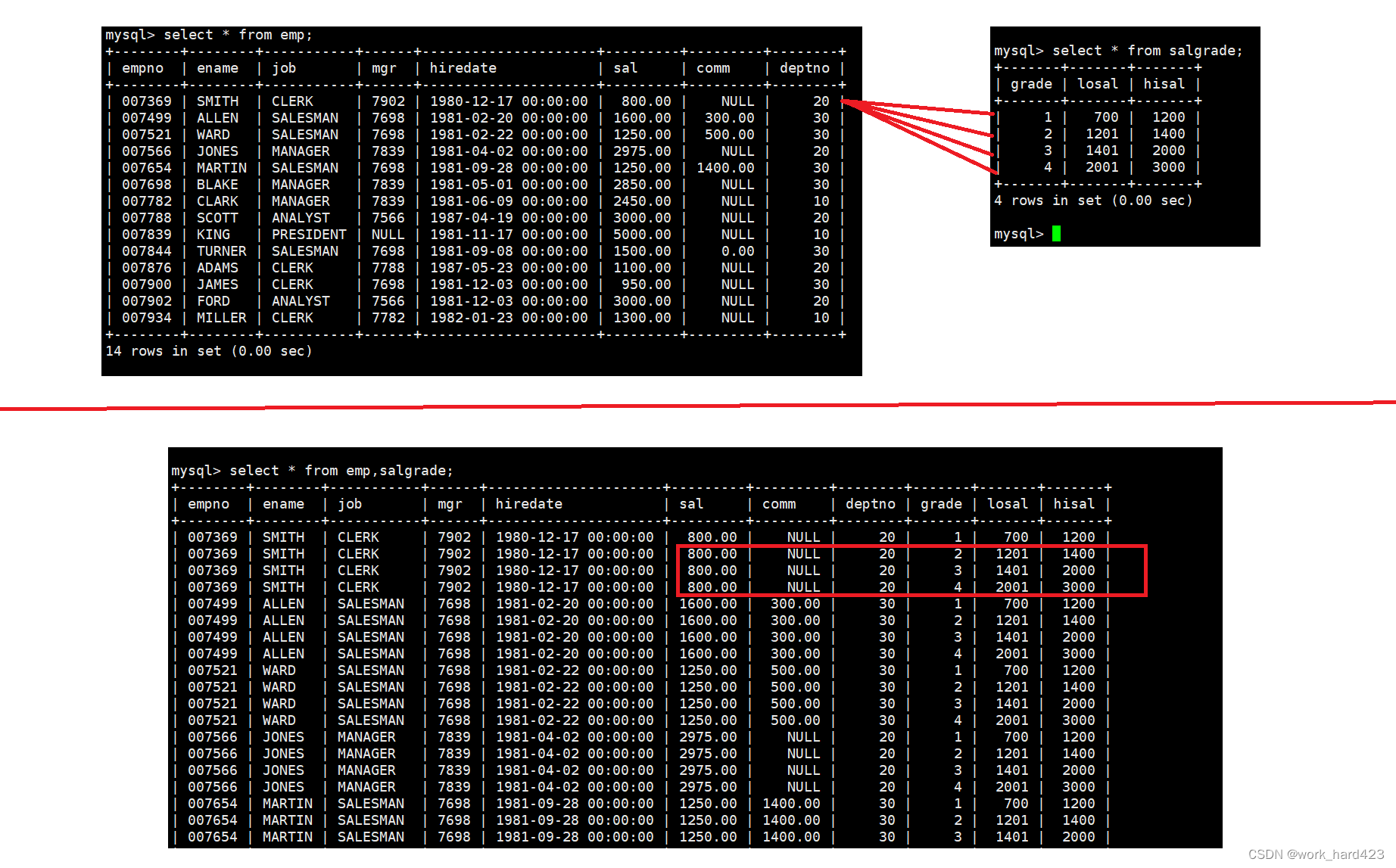
- 多表查询的SQL语法就是将多张表的表名依次放到from子句后,用逗号隔开,比如【select?from?表1,表2,... 】。这时MySQL将会对指定的这多张表取笛卡尔积作为多表查询的初始数据源(如下图上半部分画红线的地方所示,笛卡尔积就是,先将emp表中的第一条数据依次和dept表中的每一条数据进行拼接,然后再将emp表中的第二条数据依次和dept表中的每一条数据进行拼接,以此类推直至emp表中的每一条数据都完成了和dept表进行拼接。如下图的下半部分所示,这张大表就是对emp表和dept表取笛卡尔积得到的结果,也就是说在当前情景下,这张大表就作为多表查询的初始数据源)。

- 然后注意,emp表和dept表取笛卡尔积得到的大表中,并不是每一条数据都是有意义的,比如说如上图下半部分的红框处所示,在emp表中,该条数据的属性deptno的值是20,但在dept表中,该条数据的属性deptno的值是10,那这就不匹配、这条数据就没有意义,这是因为从语义上说,明明该员工是属于20号部门,但却在该员工的信息中拼接了10号部门的所有信息。那怎样的一条数据才有意义呢?实际上我们能很轻松地理解到,一个员工的信息只有和自己所属的部门的信息进行组合才是有意义的。
- 所以综上所述,我们是需要对多张表的笛卡尔积做数据过滤的。如何过滤呢?答案:如果需要做多表查询,则多张表通常都是有关联的(如果在多张表之间没有关联的情况下还做多表查询,则此时虽然也可以做多表查询,但此时多表查询就没有什么意义,只会导致很多重复的数据冗余在一起),多张表会通过某个在每张表中都存在的属性被关联起来。而哪个属性将多张表关联起来,我们就要通过哪个属性做数据过滤。比如说在上图的情况中,emp表和dept表中都有属性deptno,并且也是deptno属性将emp表和dept表关联起来,所以我们过滤的方式就是判断笛卡尔积中的属于emp表的deptno属性值和笛卡尔积中的属于dept表的deptno属性值是否相等,如果相等,则说明该条数据有意义,如果不相等,则说明该条数据没有意义、需要将该条数据过滤掉,演示如下图所示,下图中的表就是笛卡尔积进行过滤后的结果,这时表中的每一条数据才都有意义(注意因为笛卡尔积中有两个deptno属性,所以我们要通过emp.deptno和dept.deptno这样的方式将二者区分。说一下,如果一个属性同时存在于用于取笛卡尔积的多张表中,则这时在笛卡尔积里选中该属性时需要通过 表名.属性名 这样的方式进行指明,当然如果一个属性不同时存在于用于取笛卡尔积的多张表中,而是只存在于一个表中,那么在笛卡尔积里选中该属性时就无需通过这样的方式了)。
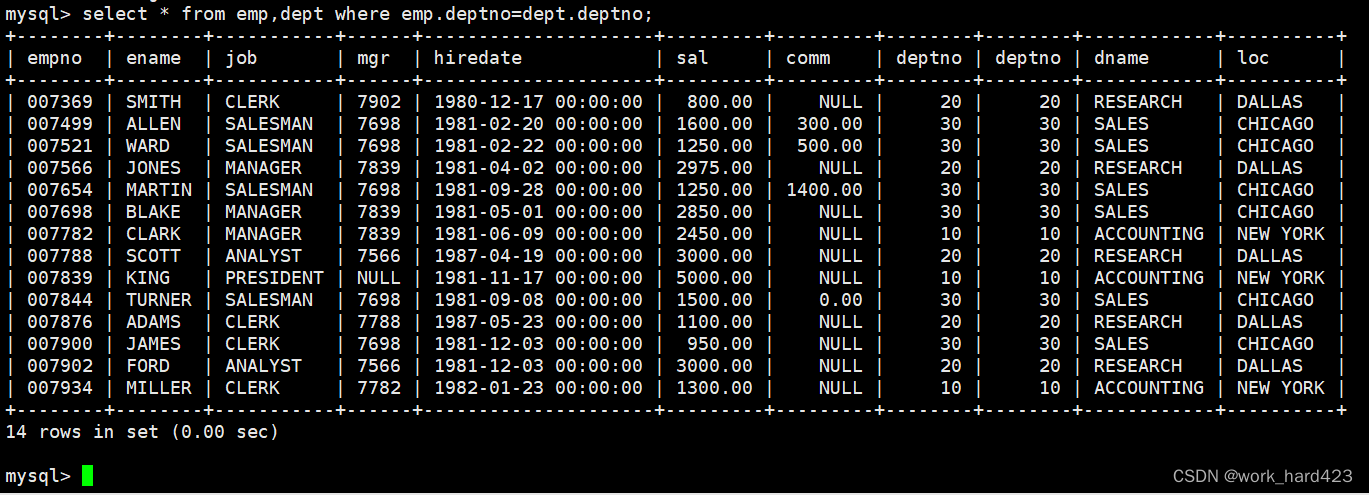
如上图所示,我们可以看到,通过多表查询这样的方式,我们就可以把表1和表2拼接在一起形成一张更大的表,所以这样一来,通过select语句将表1中的某些属性列和表2中的某些属性列放在一张表中显示出来的需求也就很好满足了,这就是上面提出的问题【那么该怎么办呢?】的答案。
同时注意,在本篇文章的第一段中说过【因为多表查询本质上依然是单表查询】这样一句话,走到这里我们就能深刻理解到,就是因为多表查询本质上只是将多张小表合并成一张大表,然后在这张大表中做查询,所以才说多表查询本质上依然是单表查询。
走到这里,对多表查询的基本介绍就进行完毕了,接下来咱们做一些多表查询的实操,如下。
显示部门号为10的部门名、员工名和员工工资,如下:
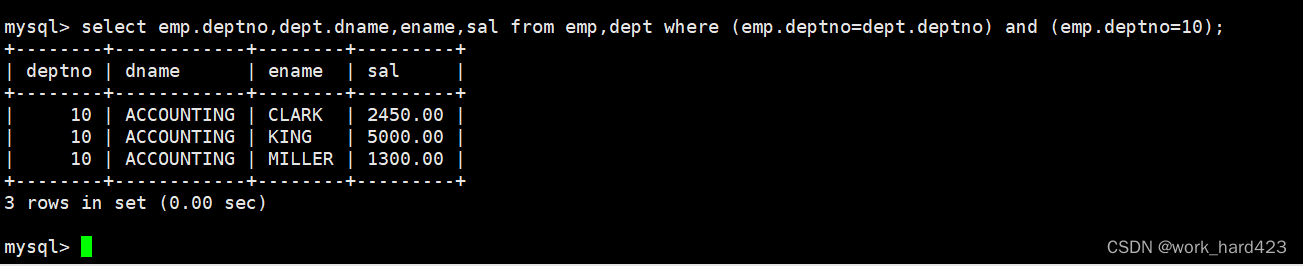
如下图所示,因为员工姓名(即属性ename)、工资(即属性sal)只存在于emp表中,部门名(即属性dname)只存在于dept表中,所以我们要【select from emp,dept】多表查询emp和dept表。然后要在where子句中指明筛选条件为员工表中的部门号等于部门表中的部门号(这是在过滤笛卡尔积中无意义的数据),并且指明要查询部门号为10的数据。
显示各个员工的姓名、工资和工资等级,如下:
因为员工姓名(即属性ename)、工资(即属性sal)只存在于emp表中,工资等级(即属性grade)只存在于salgrade表中,所以我们要【select from emp,salgrade】多表查询emp和salgrade表。
然后要知道的是,如下图所示(下图的上半部分是取两张表笛卡尔积的过程,下图的下半部分是两张表的笛卡尔积),在员工表和工资等级表的笛卡尔积中,是将员工表中的每一个员工的信息都和工资等级表中的所有工资等级信息进行了组合,而实际上一个员工的信息只有和自己工资对应的工资等级信息进行组合才是有意义的,如果一个员工的工资不属于某个工资等级,但却将该工资等级的所有信息拼接在了员工信息里,那这条数据就没有意义(比如下图下半部分红框处的数据就没有意义,因为明明这个员工的工资是800,不在1201到1400这个区间中,却将这个区间代表的工资等级的所有信息拼接在了该员工的信息中),因此需要拿着员工的工资根据工资等级表中的各个工资等级的最低工资和最高工资判断一个员工的工资是否属于该工资等级,进而筛选出有意义的数据。
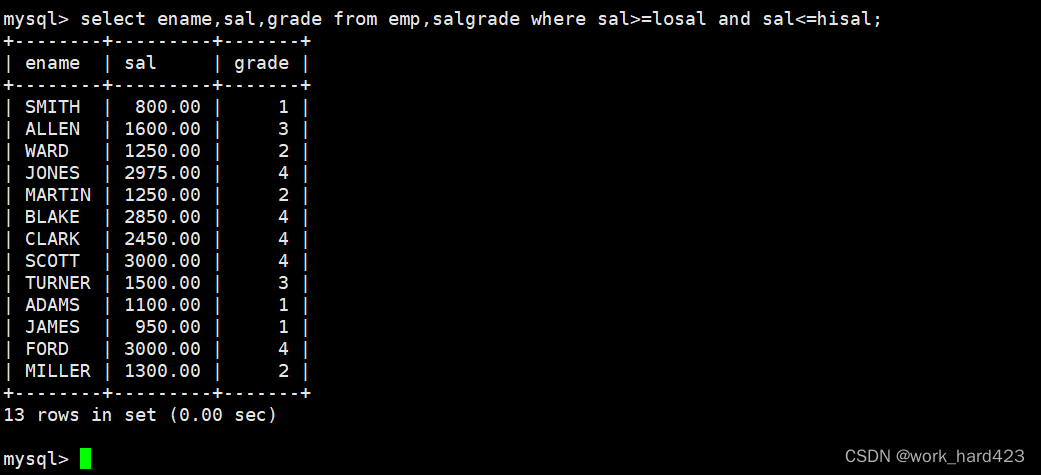
结合上面的思路,我们可知只需要在select from的时候多表查询emp表和salgrade表,并在where子句中指明筛选条件为员工的工资sal在losal和hisal之间(即如果sal在区间之内,则该条数据有意义,如果不在区间之内,则该条数据无意义,将其过滤掉),即可查询出最终结果,如下。
- 方式1如下。
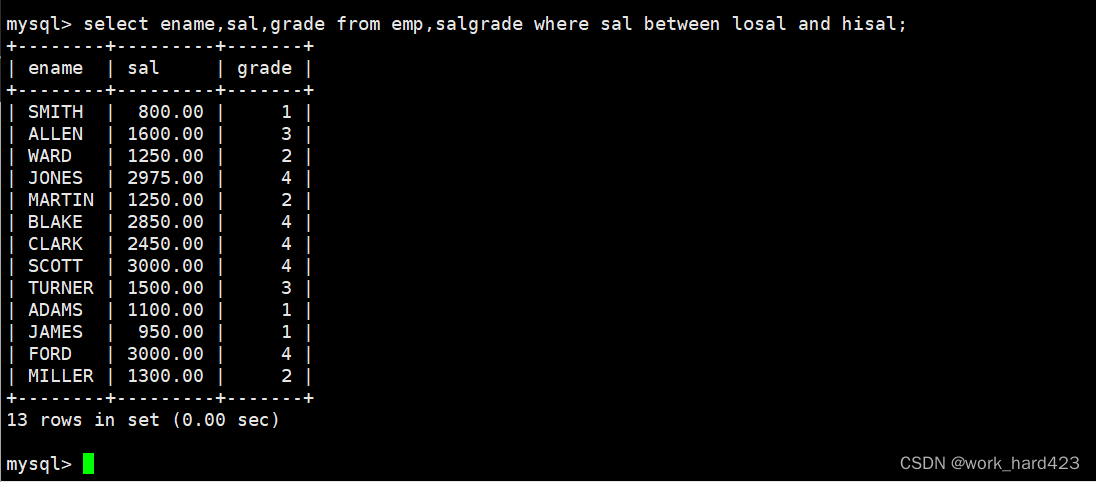
- 方式2如下。
自连接
注意,我们不仅可以多表查询不同的多张表(即取不同表的笛卡尔积),还可以多表查询相同的多张表(即对同一张表取笛卡尔积),而像这样多表查询相同的多张表的情况就叫做自连接。
那自连接有什么用呢?咱们直接通过实操来说明其作用,如下。
显示员工FORD的上级领导的编号和姓名,如下:
因为员工姓名(即属性ename)、员工的编号(即属性empno)都只存在于emp表中,所以我们选择select from emp查询emp表。
然后注意,因为员工FORD的上级领导本质也是一个员工,所以理论上领导的员工姓名(即属性ename)和员工编号(即属性empno)也一定存在于emp表中,如下图1所示,可以发现的确如此,并且员工FORD的信息和他的领导的信息位于不同的行上。
这时我们就可以通过将这张表自连接形成一个更大的表,以让这个更大的表中存在一条【由员工FORD的信息和他的领导的信息】组成的数据(注意,由于自连接是对同一张表取笛卡尔积,因此在进行自连接时至少需要给该表取一个别名,否则未来用户在选中一个属性时,MySQL会分不清该属性属于哪张表),如下图2的红框处所示,可以发现的确有这样的一条数据。
然后剩下的工作就简单了,我们只需在这个更大的表中通过where子句将该条数据筛选出来(如何筛选呢?先让where子句把ename等于FORD的数据晒出来,然后加上and关键字把【员工的领导编号mgr等于领导的员工号empno的数据】筛选出来即可,注意这一步是在过滤掉所有没有意义的数据),并按照题目的要求进行显示即可完成题目的要求,如下图3所示。
- 图1如下。

- 图2如下。
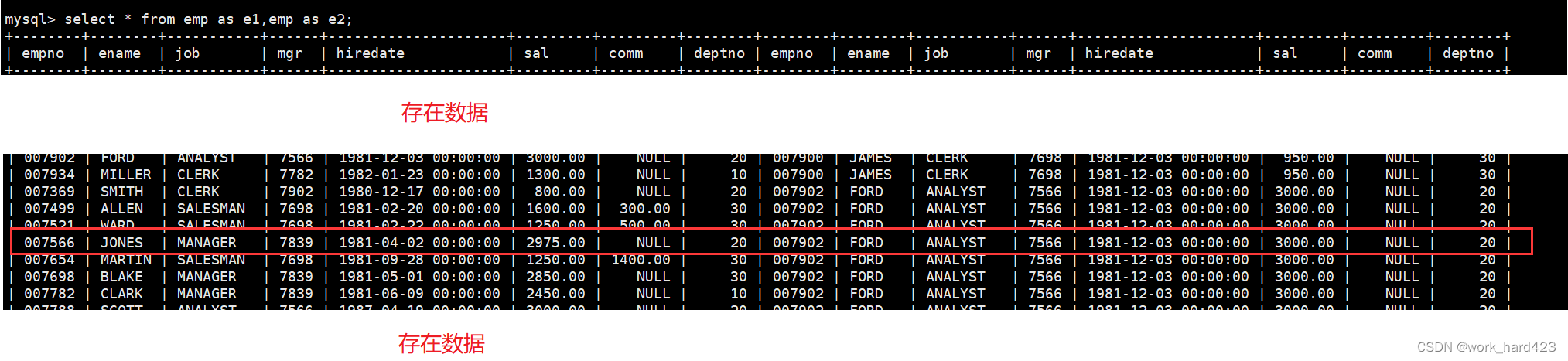
- 图3如下。??????????????
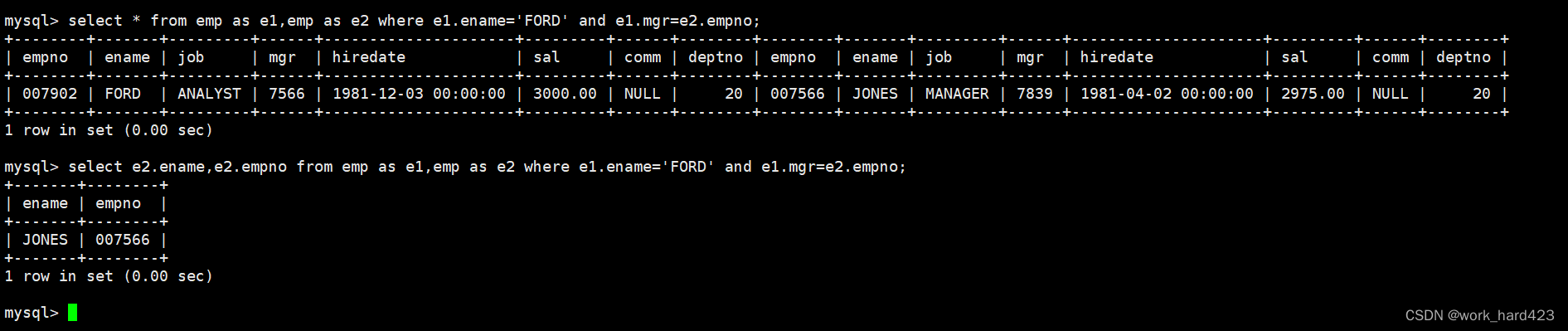
说一下,除了上面的方法外,咱们还可以通过子查询完成该题目,比如说先对员工表emp进行查询得到FORD的领导的编号,然后再根据领导的编号对员工表进行查询得到FORD领导的姓名。如下。
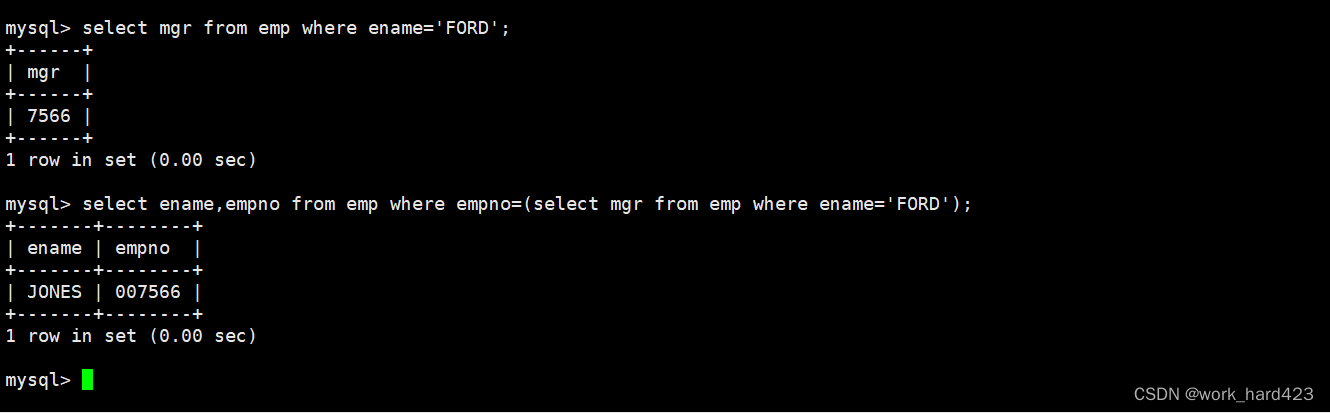
所以走到这里我们就能明白自连接的作用,即:如果在一张表中,某条数据A的某些属性和另一条数据B有关系(比如在上面的情景中,就是一个员工A的属性mgr和另一个员工B有关系),并且现在又有显示数据B的信息的需求,那么就可以通过自连接将表中通过该属性进行关联的两条数据组合起来形成一条数据,然后再将这条数据筛选出来并按需进行显示(再次强调一下,想要通过自连接的方式显示数据B的信息,则数据A必须有某些属性和数据B有关系,否则后序在筛选数据时就没有依据、自连接也就没有意义)。
子查询
先说一下,子查询可分为单行单列子查询、单行多列子查询、多行单列子查询、多行多列子查询、以及在from子句中使用的子查询。
单行单列不需要使用in、all是因为————
剩下的内容笔者稍后再补充~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 复试情报准备
- MIT 6s081 lab1:Xv6 and Unix utilities
- 独立式键盘的按键功能扩展:“以一当四“
- 折叠指定日期前的查询,让查询列表更简洁
- Uniapp多选Popup(弹出层)
- 大数据导论(2)---大数据与云计算、物联网、人工智能
- 交友网站的设计与实现(源码+数据库+论文+开题报告+说明文档)
- 【Kafka】Kafka介绍、架构和概念
- 华为OD机试真题【特异性双端队列 | 最小调整顺序次数】
- 四、Spring IoC实践和应用(基于XML配置方式组件管理)