4.3 媒资管理模块 - Minio系统上传图片与视频
一、上传图片
此模块涉及到修改/添加课程,之前已经写过接口了,在下面这篇文章中
1.1 需求分析
我们的文件要存储在minio文件系统中
在新增课程界面上传课程图片,也可以修改课程图片
这一步上传图片是请求的媒资服务接口,并不是内容管理服务接口
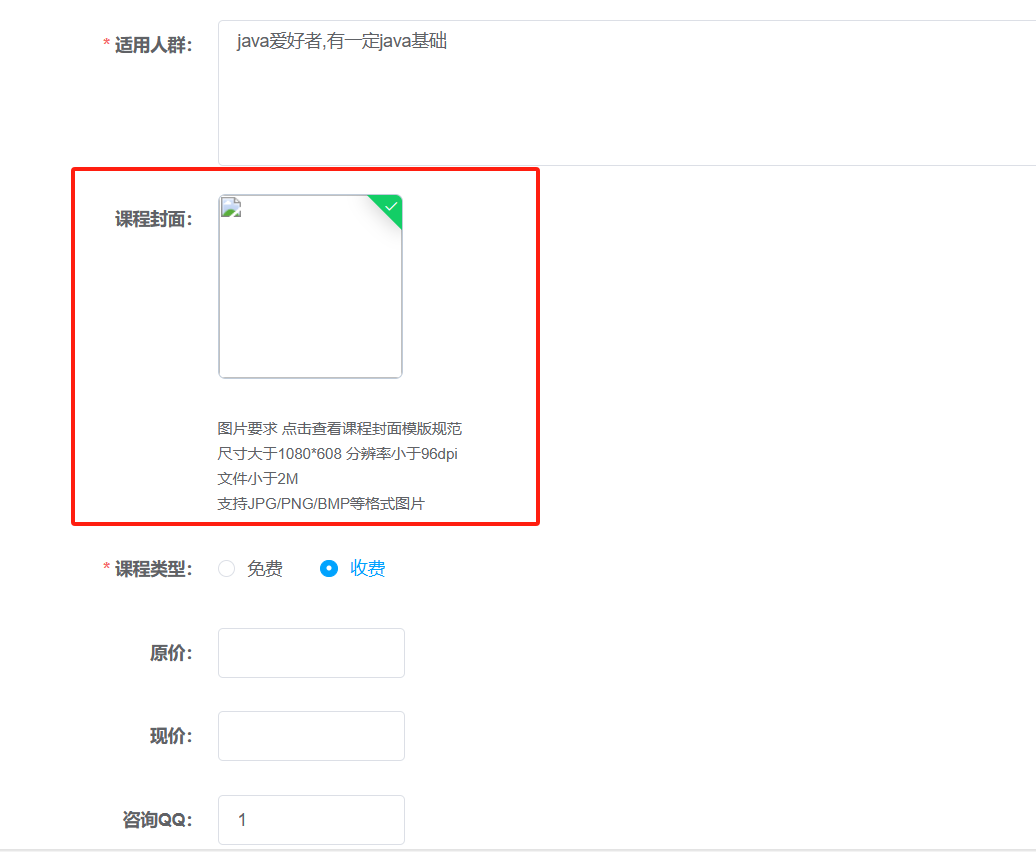
在课程基本信息中有一个“pic”字段,要存储图片的路径
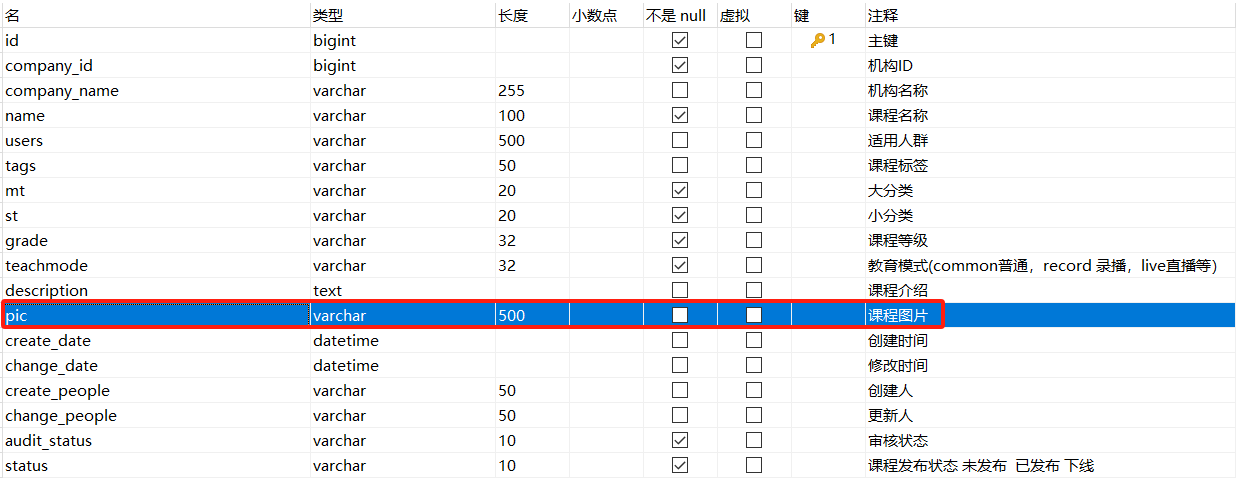
pic字段值类似“/mediafiles/2022/09/18/a16da7a132559daf9e1193166b3e7f52.jpg”,其中“mediafiles”就是桶,后面就是文件具体的对象名
在我们前端功能.env环境变量配置文件定义了图片服务器地址
如果想要展示图片,那就要将“http://192.168.101.65:9000”拼接上pic字段值
为什么不将“http://192.168.101.65:9000”直接写在数据库里?
因为如果上线之后,地址就不好修改了

为什么要单独设置一个媒资管理服务?
①管理文件的信息,我们使用media_files表记录文件信息
不管是图片、视频、文档,全会记录在这个表中
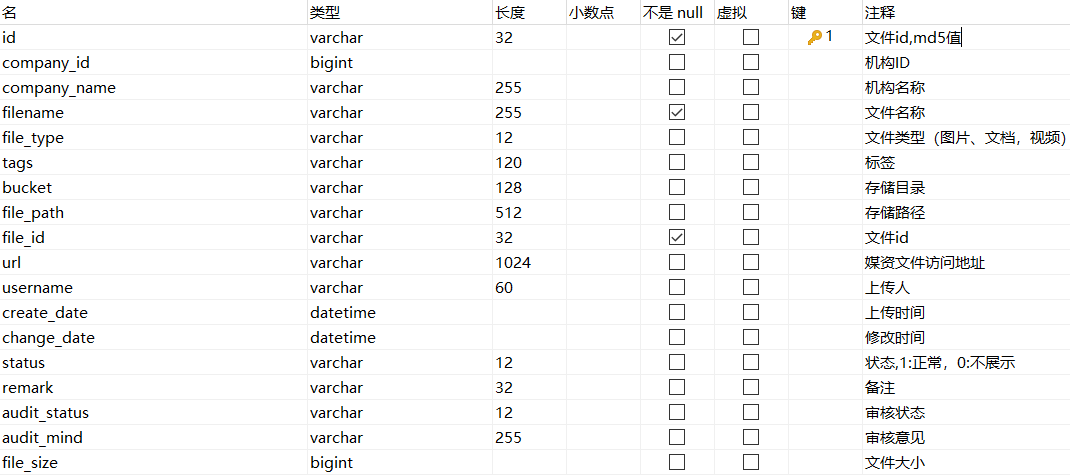
②把文件本身放在分布式文件系统(minio)中管理起来
方便管理,媒资服务就是一个统一的文件管理功能
详细流程
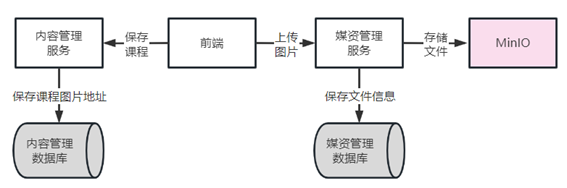
1、前端进入上传图片界面
2、上传图片,请求媒资管理服务。
3、媒资管理服务将图片文件存储在MinIO。
4、媒资管理记录文件信息到数据库。
5、前端请求内容管理服务保存课程信息,在内容管理数据库保存图片地址。
1.2 数据模型
我们怎么区分文件是否已经上传?
可以通过文件的MD5值,同一个文件的MD5值相同
前端上传的时候就会把文件MD5值传给我们后台,后台拿着MD5值去数据库查询,如果有这个MD5值了,说明文件已经上传成功了,不需要再上传了
1.2.1 media_files 媒资信息表

file_path存储路径,相当于java代码中的对象名
url:可以通过http访问文件的路径
url = /bucket/+file_path
但是有例外,如果是上传了一个avi视频的话,那file_path里面存的就是avi结尾的视频地址,但是avi的视频最终是不能播放的,我们需要把这个视频进行转码生成MP4格式的视频,此时url就是存储的MP4的视频地址、
如果是图片的话url = /bucket/+file_path这个等式是一个样子的
/**
* 媒资信息
*/
@Data
@TableName("media_files")
public class MediaFiles implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.ASSIGN_ID)
private String id;
/**
* 机构ID
*/
private Long companyId;
/**
* 机构名称
*/
private String companyName;
/**
* 文件名称
*/
private String filename;
/**
* 文件类型(文档,音频,视频)
*/
private String fileType;
/**
* 标签
*/
private String tags;
/**
* 存储目录
*/
private String bucket;
/**
* 存储路径
*/
private String filePath;
/**
* 文件标识
*/
private String fileId;
/**
* 媒资文件访问地址
*/
private String url;
/**
* 上传人
*/
private String username;
/**
* 上传时间
*/
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createDate;
/**
* 修改时间
*/
@TableField(fill = FieldFill.INSERT_UPDATE)
private LocalDateTime changeDate;
/**
* 状态,1:未处理,视频处理完成更新为2
*/
private String status;
/**
* 备注
*/
private String remark;
/**
* 审核状态
*/
private String auditStatus;
/**
* 审核意见
*/
private String auditMind;
/**
* 文件大小
*/
private Long fileSize;
}
除此之外还会涉及到课程基本信息表course_base,表中pic字段存储课程图片的路径
1.3 准备Minio环境
1.3.1 桶环境
-
mediafiles桶
视频以外的文件都存储在这个桶内
-
video 桶
存放视频
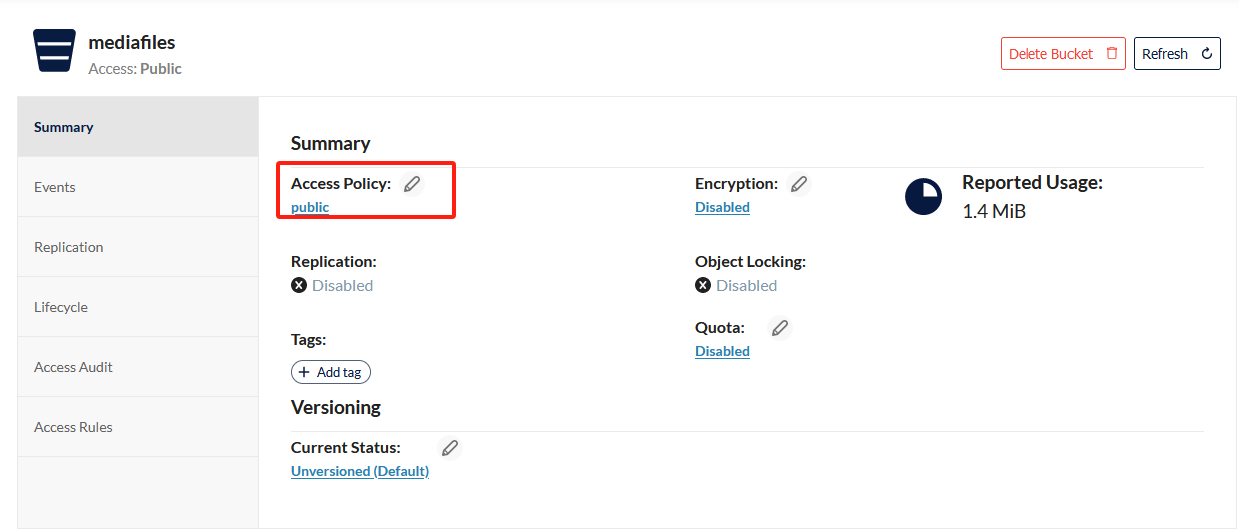
并且两个桶的Access Policy权限都要改成public
1.3.2 连接Minio参数
在media-service工程中配置minio的相关信息,要配置在nacos中
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.101.65:3306/xcplus_media?serverTimezone=UTC&userUnicode=true&useSSL=false&
username: root
password: mysql
cloud:
config:
#配置本地优先
override-none: true
minio:
#地址
endpoint: http://192.168.101.65:9000
#账号
accessKey: minioadmin
#密码
secretKey: minioadmin
#两个桶
bucket:
files: mediafiles
videofiles: video
本地bootstrap.yaml文件
spring:
application:
name: media-service
cloud:
nacos:
server-addr: 192.168.101.65:8848
discovery:
namespace: ${spring.profiles.active}
group: xuecheng-plus-project
config:
namespace: ${spring.profiles.active}
group: xuecheng-plus-project
file-extension: yaml
refresh-enabled: true
shared-configs:
- data-id: logging-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true
#profiles默认为dev
profiles:
active: dev
1.3.3 Minio配置类
在media-service工程中进行配置
@Configuration
public class MinioConfig {
@Value("${minio.endpoint}")
private String endpoint;
@Value("${minio.accessKey}")
private String accessKey;
@Value("${minio.secretKey}")
private String secretKey;
@Bean
public MinioClient minioClient() {
MinioClient minioClient =
MinioClient.builder()
.endpoint(endpoint)
.credentials(accessKey, secretKey)
.build();
return minioClient;
}
}
1.4 接口定义
下面的内容其实是完成标红的地方
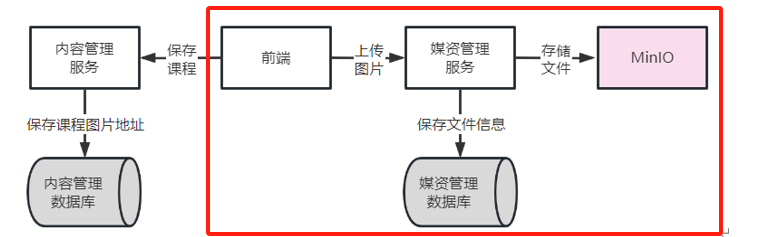
做这一部分的时候可能发现course_base课程基本信息表和media_files表没有关联,那怎么将图片的url存放到course_base课程基本信息表中的pic字段呢?
当上传完图片之后,会点击保存,这个时候就会对course_base表中的各种信息进行操作了
但是我感觉没有很好的方法让course_base表
1.4.1 上传图片接口请求参数
和media_file相关的文件上传的基本信息
/**
* @description 上传普通文件请求参数
*/
@Data
public class UploadFileParamsDto {
/**
* 文件名称
*/
private String filename;
/**
* 文件类型(文档,音频,视频)
*/
private String fileType;
/**
* 文件大小
*/
private Long fileSize;
/**
* 标签
*/
private String tags;
/**
* 上传人
*/
private String username;
/**
* 备注
*/
private String remark;
}
1.4.2 上传图片接口返回值
这些信息其实是文件表中的信息
{
"id": "a16da7a132559daf9e1193166b3e7f52",
"companyId": 1232141425,
"companyName": null,
"filename": "1.jpg",
"fileType": "001001",
"tags": "",
"bucket": "/testbucket/2022/09/12/a16da7a132559daf9e1193166b3e7f52.jpg",
"fileId": "a16da7a132559daf9e1193166b3e7f52",
"url": "/testbucket/2022/09/12/a16da7a132559daf9e1193166b3e7f52.jpg",
"timelength": null,
"username": null,
"createDate": "2022-09-12T21:57:18",
"changeDate": null,
"status": "1",
"remark": "",
"auditStatus": null,
"auditMind": null,
"fileSize": 248329
}
根据上面返回信息封装一个Dto
但是我们不会直接使用media_files的实体类,假如前端多需要几个参数的话,我们还需要修改
在media-model工程中添加如下实体类
@Data
public class UploadFileResultDto extends MediaFiles {
}
1.4.3 接口代码
/**
* 对于请求内容:Content-Type: multipart/form-data;
* 前端向后端传输一个文件,那后端程序就属于一个消费者,我们指定一下类型
* form-data; name="filedata"; filename="具体的文件名称"
* <p>
* 我们可以使用@RequestPart指定一下前端向后端传输文件的名称
* 用MultipartFile类型接收前端向后端传输的文件
*/
@ApiOperation("上传图片")
@PostMapping(value = "/upload/coursefile", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public UploadFileResultDto upload(@RequestPart("filedata") MultipartFile filedata) throws IOException {
//此时已经接收到文件了,目前作为临时文件存储在内存中
//1.创建一个临时文件,前缀是"minio",后缀是“.temp”
File tempFile = File.createTempFile("minio", ".temp");
//2.将上传后的文件传输到临时文件中
filedata.transferTo(tempFile);
//3.取出临时文件的绝对路径
String localFilePath = tempFile.getAbsolutePath();
Long companyId = 1232141425L; //先写死,写认证授权系统时再进行
//4.准备上传文件的信息
UploadFileParamsDto uploadFileParamsDto = new UploadFileParamsDto();
//filedata.getOriginalFilename()获取原始文件名称
uploadFileParamsDto.setFilename(filedata.getOriginalFilename());
//文件大小
uploadFileParamsDto.setFileSize(filedata.getSize());
//文件类型 001001在数据字典中代表图片
uploadFileParamsDto.setFileType("001001");
//调用service上传图片
return mediaFileService.uploadFile(companyId, uploadFileParamsDto, localFilePath);
}
1.5 MediaFilesMapper
我们需要保存文件信息
/**
* 媒资信息 Mapper 接口
*/
public interface MediaFilesMapper extends BaseMapper<MediaFiles> {
}
1.6 MediaFileServiceImpl
媒资管理业务类 - 下面的代码其实就做了上传图片与文件信息入库
@Autowired
private MinioClient minioClient;
//除了视频文件以外的桶
@Value("${minio.bucket.files}")
private String bucket_medialFiles;
//视频文件桶
@Value("${minio.bucket.videofiles}")
private String bucket_video;
/**
* 上传文件
*
* @param companyId 机构id
* @param uploadFileParamsDto 上传文件信息
* @param localFilePath 文件磁盘路径
* @return 文件信息
*/
@Transactional
@Override
public UploadFileResultDto uploadFile(Long companyId, UploadFileParamsDto uploadFileParamsDto, String localFilePath) {
//TODO 1.将文件上传到Minio
//TODO 1.1 获取文件扩展名
String filename = uploadFileParamsDto.getFilename();
String extension = filename.substring(filename.lastIndexOf("."));
//TODO 1.2 根据文件扩展名获取mimeType
String mimeType = this.getMimeType(extension);
//TODO 1.3 bucket,从nacos中读取
//TODO 1.4 ObjectName约定在MinIo系统中存储的目录是年/月/日/图片文件
//得到文件的路径defaultFolderPath
String defaultFolderPath = this.getDefaultFolderPath();
//最终存储的文件名是MD5值
String fileMd5 = this.getFileMd5(new File(localFilePath));
String ObjectName = defaultFolderPath + fileMd5 + extension;
//TODO 1.5 上传文件到Minio
boolean result = this.addMediaFilesToMinIO(localFilePath, bucket_medialFiles, ObjectName, mimeType);
if (!result) {
XueChengPlusException.cast("上传文件失败");
}
//TODO 2.将文件信息保存到数据库
MediaFiles mediaFiles = this.addMediaFilesToDb(companyId, fileMd5, uploadFileParamsDto, bucket_medialFiles, ObjectName);
if (mediaFiles == null){
XueChengPlusException.cast("文件上传后保存信息失败");
}
UploadFileResultDto uploadFileResultDto = new UploadFileResultDto();
BeanUtils.copyProperties(mediaFiles, uploadFileResultDto);
return uploadFileResultDto;
}
/**
* @param companyId 机构id
* @param fileMd5 文件md5值
* @param uploadFileParamsDto 上传文件的信息
* @param bucket 桶
* @param objectName 对象名称
* @return com.xuecheng.media.model.po.MediaFiles
* @description 将文件信息添加到文件表
*/
public MediaFiles addMediaFilesToDb(Long companyId, String fileMd5, UploadFileParamsDto uploadFileParamsDto, String bucket, String objectName) {
//根据文件MD5值向数据库查找文件信息
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if (mediaFiles == null) {
mediaFiles = new MediaFiles();
BeanUtils.copyProperties(uploadFileParamsDto, mediaFiles);
mediaFiles.setId(fileMd5);//文件信息的主键是文件的MD5值
mediaFiles.setCompanyId(companyId);//机构ID
mediaFiles.setBucket(bucket);//桶
mediaFiles.setFilePath(objectName);//对象名
mediaFiles.setFileId(fileMd5);//file_id字段
mediaFiles.setUrl("/" + bucket + "/" + objectName);//url
mediaFiles.setCreateDate(LocalDateTime.now());//上传时间
mediaFiles.setStatus("1");//状态 1正常 0不展示
mediaFiles.setAuditStatus("002003");//审核状态 002003审核通过
int insert = mediaFilesMapper.insert(mediaFiles);
if (insert <= 0) {
log.debug("向数据库保存文件失败bucket:{},objectName:{}", bucket, objectName);
}
}
return mediaFiles;
}
/**
* 将文件上传到MinIo
*
* @param bucket 桶
* @param localFilePath 文件在本地的路径
* @param objectName 上传到MinIo系统中时的文件名称
* @param mimeType 上传的文件类型
*/
private boolean addMediaFilesToMinIO(String localFilePath, String bucket, String objectName, String mimeType) {
try {
UploadObjectArgs uploadObjectArgs = UploadObjectArgs.builder()
//桶,也就是目录
.bucket(bucket)
//指定本地文件的路径
.filename(localFilePath)
//上传到minio中的对象名,上传的文件存储到哪个对象中
.object(objectName)
.contentType(mimeType)
//构建
.build();
minioClient.uploadObject(uploadObjectArgs);
log.debug("上传文件到minio成功,bucket:{},objectName:{}", bucket, objectName);
return true;
} catch (Exception e) {
e.printStackTrace();
log.info("上传文件出错,bucket:{},objectName:{},错误信息:{}", bucket, objectName, e.getMessage());
return false;
}
}
/**
* 根据扩展名获取mimeType
*
* @param extension 扩展名
*/
private String getMimeType(String extension) {
if (extension == null) {
//目的是防止空指针异常
extension = "";
}
ContentInfo extensionMatch = ContentInfoUtil.findExtensionMatch(extension);
//通用mimeType,字节流
String mimeType = MediaType.APPLICATION_OCTET_STREAM_VALUE;
if (extensionMatch != null) {
mimeType = extensionMatch.getMimeType();
}
return mimeType;
}
/**
* @return 获取文件默认存储目录路径 年/月/日
*/
private String getDefaultFolderPath() {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
return sdf.format(new Date()).replace("-", "/") + "/";
}
/**
* 获取文件的md5
*
* @param file 文件
* @return MD5值
*/
private String getFileMd5(File file) {
try (FileInputStream fileInputStream = new FileInputStream(file)) {
return DigestUtils.md5Hex(fileInputStream);
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
1.7 事物优化
在下面这篇文章中也有事物的方法,感兴趣的话可以查看一下1.6
我在uploadFile上传文件的方法中加了@Transactional方法
也就是说在uploadFile方法执行之前就会开启事物
但是addMediaFilesToMinIO方法会通过网络访问Minio分布式文件系统上传文件,但是通过网络访问的话这个时间可长可短,假如说网络访问时间长的话,事物的时间就会比较长,占用数据库资源的时间就会长,极端情况下会导致数据库的连接不够用
所在当方法中有网络访问的话,千万不要使用数据库的@Transactional事物进行控制
所以此时我们在addMediaFilesToDb方法上添加@Transactional控制事物的方法就好了
public MediaFiles addMediaFilesToDb(Long companyId, String fileMd5, UploadFileParamsDto uploadFileParamsDto, String bucket, String objectName) {
....
}
但是现在也会出现一个问题,我们在uploadFile方法中调用addMediaFilesToDb方法的时候并不会触发addMediaFilesToDb方法上的@Transactional,这种情况也是事物失效的场景之一
分析一下这种情况出现的原因:
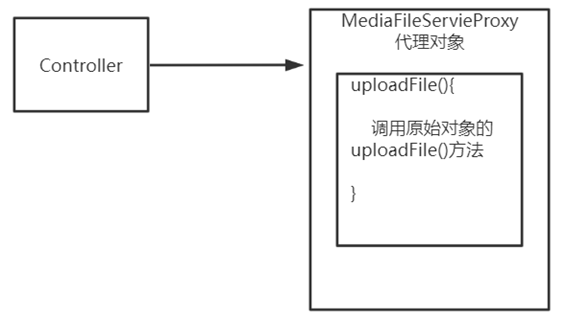
在uploadFile方法上添加@Transactional注解,代理对象执行此方法前会开启事务
如果在uploadFile方法上没有@Transactional注解,代理对象执行此方法前不进行事务控制
断该方法是否可以事务控制必须保证是通过代理对象调用此方法,且此方法上添加了@Transactional注解
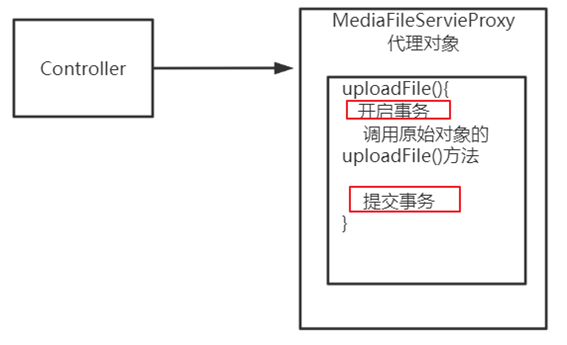
在addMediaFilesToDb方法上添加@Transactional注解,也不会进行事务控制是因为并不是通过代理对象执行的addMediaFilesToDb方法
如下图所示,在addMediaFilesToDb方法中的this指代的并不是代理对象,uploadFile方法中this指代的也不是代理对象
我们在Controller使用@AutoWired的注解引入的MediaFileService对象是代理对象,怎么在调用的时候就不是了呢?
在MediaFileServiceImpl类中this指代的就是当前类,不是代理对象
代理对象其实是在原始对象上包了一层,然后调用原始对象上的方法而已

为了解决这个问题,我们可以在uploadFile方法中使用代理的方式调用addMediaFilesToDb方法,使其能触发@Transactional注解
不同担心循环依赖的问题,spring有三级缓存
@Autowired
MediaFileService currentProxy;
将addMediaFilesToDb方法提成接口
/**
* @description 将文件信息添加到文件表
* @param companyId 机构id
* @param fileMd5 文件md5值
* @param uploadFileParamsDto 上传文件的信息
* @param bucket 桶
* @param objectName 对象名称
* @return com.xuecheng.media.model.po.MediaFiles
*/
public MediaFiles addMediaFilesToDb(Long companyId, String fileMd5, UploadFileParamsDto uploadFileParamsDto, String bucket, String objectName);
调用addMediaFilesToDb方法的代码处改为如下
//TODO 2.将文件信息保存到数据库
MediaFiles mediaFiles = currentProxy.addMediaFilesToDb(companyId, fileMd5, uploadFileParamsDto, bucket_medialFiles, ObjectName);
if (mediaFiles == null){
XueChengPlusException.cast("文件上传后保存信息失败");
}
此时就是通过CGLB生成的代理对象,挺完美的

1.8 测试
测试上传文件

二、上传视频
上传视频的位置如下所示

2.0 响应结果类
/**
* 通用结果类
*/
@Data
@ToString
public class RestResponse<T> {
/**
* 响应编码,0为正常,-1错误
*/
private int code;
/**
* 响应提示信息
*/
private String msg;
/**
* 响应内容
*/
private T result;
public RestResponse() {
this(0, "success");
}
public RestResponse(int code, String msg) {
this.code = code;
this.msg = msg;
}
/**
* 错误信息的封装
*
* @param msg
* @param <T>
* @return
*/
public static <T> RestResponse<T> validfail(String msg) {
RestResponse<T> response = new RestResponse<T>();
response.setCode(-1);
response.setMsg(msg);
return response;
}
public static <T> RestResponse<T> validfail(T result, String msg) {
RestResponse<T> response = new RestResponse<T>();
response.setCode(-1);
response.setResult(result);
response.setMsg(msg);
return response;
}
/**
* 添加正常响应数据(包含响应内容)
*
* @return RestResponse Rest服务封装相应数据
*/
public static <T> RestResponse<T> success(T result) {
RestResponse<T> response = new RestResponse<T>();
response.setResult(result);
return response;
}
public static <T> RestResponse<T> success(T result, String msg) {
RestResponse<T> response = new RestResponse<T>();
response.setResult(result);
response.setMsg(msg);
return response;
}
/**
* 添加正常响应数据(不包含响应内容)
*
* @return RestResponse Rest服务封装相应数据
*/
public static <T> RestResponse<T> success() {
return new RestResponse<T>();
}
public Boolean isSuccessful() {
return this.code == 0;
}
}
2.1 断点续传
假如说用户上传了一个大文件,但是用户的网不是很好,上传了一部分网断了,这个时候就需要一个断点续传的需求了
通常视频文件都比较大,所以对于媒资系统上传文件的需求要满足大文件的上传要求。
http协议本身对上传文件大小没有限制,但是客户的网络环境质量、电脑硬件环境等参差不齐,如果一个大文件快上传完了网断了没有上传完成,需要客户重新上传,用户体验非常差,所以对于大文件上传的要求最基本的是断点续传
断点续传:在下载或上传时,将下载或上传任务(一个文件或一个压缩包)人为的划分为几个部分,每一个部分采用一个线程进行上传或下载,如果碰到网络故障,可以从已经上传或下载的部分开始继续上传下载未完成的部分,而没有必要从头开始上传下载,断点续传可以提高节省操作时间,提高用户体验性
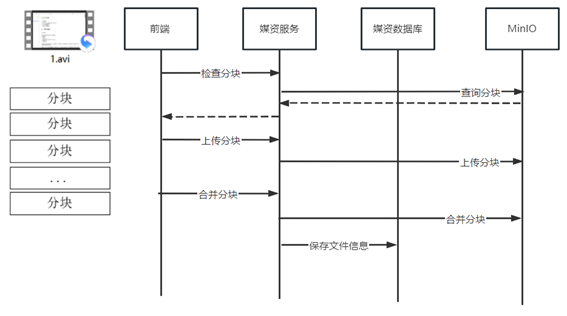
流程如下:
1、前端对文件进行分块
2、前端上传分块文件前请求媒资服务检查文件是否存在,如果已经存在则不再上传
3、如果分块文件不存在则前端开始上传
4、前端请求媒资服务上传分块
5、媒资服务将分块上传至MinIO
6、前端将分块上传完毕请求媒资服务合并分块
7、媒资服务判断分块上传完成则请求MinIO合并文件
8、合并完成校验合并后的文件是否完整,如果不完整则删除文件
2.2 测试Demo
2.2.1 分块测试
/**
* 测试分块
*/
@Test
public void testChunk() throws Exception {
//TODO 1.获取源文件
File sourceFile = new File("E:\\歌.mp4");
//TODO 2.定义基本参数
//2.1 分块文件存储路径
String chunkFilePath = "E:\\chunk\\";
//2.2 分块文件的大小 1024*1024*1 代表1M,5M的话乘5即可(也就是最小单位是字节byte 1024个byte是1k)
int chunkSize = 1024 * 1024 * 1;
//2.3 分块文件大小
//Math.ceil表示向上取整
//sourceFile.length()是获取文件的大小是多少byte字节
int chunkNum = (int) Math.ceil((sourceFile.length() * 1.0) / chunkSize);
//TODO 3.从源文件中读数据,向分块文件中写数据
//RandomAccessFile流既可以读又可以写
//参数一:File类型 参数二:是读(“r”)还是写"rw"
RandomAccessFile raf_r = new RandomAccessFile(sourceFile, "r");
//缓存区,1k
byte[] bytes = new byte[1024];
//TODO 3.1 创建分块文件
for (int i = 0; i < chunkNum; i++) {
File chunkFile = new File(chunkFilePath + i);
//分块文件写入流
RandomAccessFile raf_rw = new RandomAccessFile(chunkFile, "rw");
int len = -1;
//将数据读取到缓冲区中raf_r.read(bytes)
while ((len = raf_r.read(bytes)) != -1) {
//向临时文件中进行写入
raf_rw.write(bytes, 0, len);
//如果分块文件chunkFile的大小大于等于我们规定的分块文件的chunkSize大小,就不要再继续了
if (chunkFile.length() >= chunkSize) {
break;
}
}
raf_rw.close();
}
raf_r.close();
}

2.2.2 合并测试
/**
* 测试合并
*/
@Test
public void testMerge() throws Exception {
//TODO 1.基本参数
//分块文件目录
File chunkFolder = new File("E:\\chunk\\");
//源文件
File sourceFile = new File("E:\\歌.mp4");
//合并后的文件在哪里
File mergeFile = new File("E:\\chunk\\歌Copy.mp4");
//TODO 2.取出所有分块文件,此时的顺序可能是无序的
File[] files = chunkFolder.listFiles();
//将数组转换成List
List<File> fileList = Arrays.asList(files);
//利用Comparator进行排序
Collections.sort(fileList, new Comparator<File>() {
@Override
public int compare(File o1, File o2) {
//升序
return Integer.parseInt(o1.getName()) - Integer.parseInt(o2.getName());
}
});
//TODO 3.合并分块文件
//缓存区,1k
byte[] bytes = new byte[1024];
//向合并分块的流
RandomAccessFile raf_rw = new RandomAccessFile(mergeFile, "rw");
for (File file : fileList) {
//向读取分块文件
RandomAccessFile raf_r = new RandomAccessFile(file, "r");
int len = -1;
while ((len = raf_r.read(bytes)) != -1) {
raf_rw.write(bytes, 0, len);
}
raf_r.close();
}
raf_rw.close();
//TODO 校验是否合并成功
//合并文件完成后比对合并的文件MD5值域源文件MD5值
FileInputStream fileInputStream = new FileInputStream(sourceFile);
FileInputStream mergeFileStream = new FileInputStream(mergeFile);
//取出原始文件的md5
String originalMd5 = DigestUtils.md5Hex(fileInputStream);
//取出合并文件的md5进行比较
String mergeFileMd5 = DigestUtils.md5Hex(mergeFileStream);
if (originalMd5.equals(mergeFileMd5)) {
System.out.println("合并文件成功");
} else {
System.out.println("合并文件失败");
}
}

2.3 测试MinIo
MinioClient minioClient =
MinioClient.builder()
//这个地方是运行minio后展示的地址
.endpoint("http://192.168.101.65:9000")
//账号和密码
.credentials("minioadmin", "minioadmin")
.build();
2.3.1 上传分块
将分块文件上传至MinIo
/**
* 将分块文件上传到minio
*/
@Test
public void uploadChunk() throws Exception {
//获取所有的分块文件
File file = new File("E:\\chunk\\");
File[] files = file.listFiles();
for (File chunkFile : files) {
minioClient.uploadObject(
UploadObjectArgs.builder()
//桶,也就是目录
.bucket("testbucket")
//指定本地文件的路径
.filename(chunkFile.getAbsolutePath())
//对象名
.object("chunk/"+chunkFile.getName())
//构建
.build());
System.out.println("上传分块"+chunkFile.getName()+"成功");
}
}
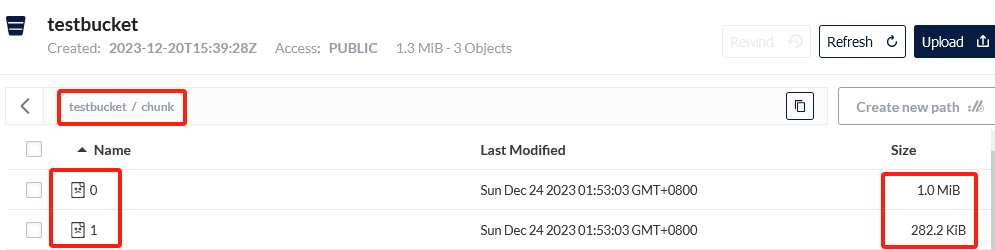
2.3.2 合并分块
分块已经在Minio了,我们调用Minio提供的SDK即可合并分块
/**
* 调用minio接口合并分块
*/
@Test
public void merge() throws ServerException, InsufficientDataException, ErrorResponseException, IOException, NoSuchAlgorithmException, InvalidKeyException, InvalidResponseException, XmlParserException, InternalException {
//分块文件集合
List<ComposeSource> sources = new ArrayList<>();
sources.add(ComposeSource.builder()
//分块文件所在桶
.bucket("testbucket")
//分块文件名称
.object("chunk/0")
.build());
sources.add(ComposeSource.builder()
//分块文件所在桶
.bucket("testbucket")
//分块文件名称
.object("chunk/1")
.build());
ComposeObjectArgs composeObjectArgs = ComposeObjectArgs.builder()
//指定合并后文件在哪个桶里
.bucket("testbucket")
//最终合并后的文件路径及名称
.object("merge/merge01.mp4")
//指定分块源文件
.sources(sources)
.build();
//合并分块
minioClient.composeObject(composeObjectArgs);
}
出现这个文件说明我们分块的文件太小了,要大于5242880byte,也就是5M,我们上传的文件才1048576byte,也就是1M
Minio默认的分块文件大小是5M
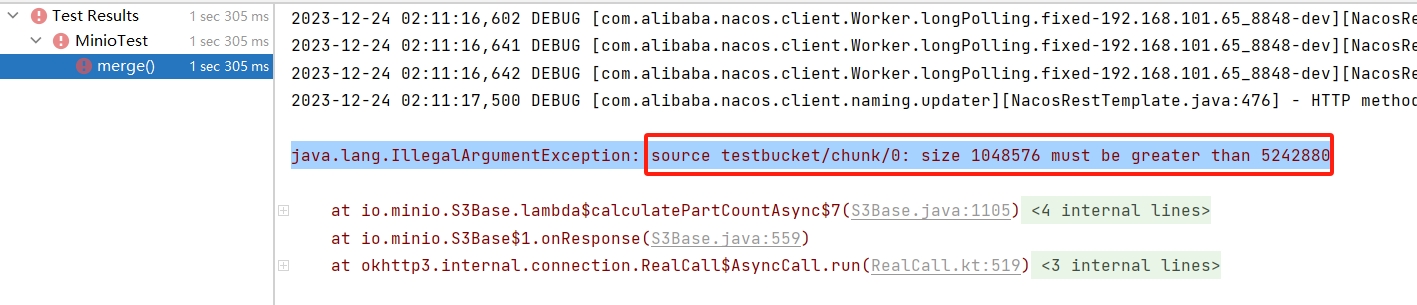
2.4 上传视频
-
前端上传视频之前,需要先检查文件是否已经上传过,我们只需要拿着文件的MD5值去数据库查询即可,如果查到了就说明之前已经上传完成了
-
假如说文件没有上传过,前端开始对视频进行分块然后将分块传输给后端,但是后端不会立即将分块上传到Minio系统,而是先检查此分块是否从前上传到在Minio系统
我们知道文件的MD5值及分块的序号,就可以知道这个分块在不在Minio系统
因为我们是根据文件的MD5值及分块的序号在Minio系统中存储的
- 等所有的分块文件都上传完毕后,前端就可以请求后端接口进行合并分块
我们某个文件的分块都是在一个目录下的,也就是说一个分块是在一个目录,不用担心分块文件会重复
2.4.1 文件上传前校验
分为“文件上传前检查文件”与“分块文件上传前的检测”两个接口
2.4.1.1 BigFilesController
/**
* 1.检查文件数据库有没有
* 2.如果数据库有了再检查minio系统当用有没有(可能存在脏数据,数据库中有但是minio没有那也要传输)
*/
@ApiOperation(value = "文件上传前检查文件")
@PostMapping("/upload/checkfile")
public RestResponse<Boolean> checkfile(@RequestParam("fileMd5") String fileMd5) {
return mediaFileService.checkFile(fileMd5);
}
/**
* 分块在数据库中是不存储的,但是可以向minio中查询分块是否存在
* minio中有了就不再传了,若没有的话再传
*/
@ApiOperation(value = "分块文件上传前的检测")
@PostMapping("/upload/checkchunk")
public RestResponse<Boolean> checkChunk(@RequestParam("fileMd5") String fileMd5,
@RequestParam("chunk") int chunk) throws Exception {
return mediaFileService.checkChunk(fileMd5,chunk);
}
2.4.1.2 MediaFileServiceImpl
/**
* 1.首先查询数据库,如果文件不在数据库中表明文件不在
* 2.如果文件在数据库中再查询minio系统,
*
* @param fileMd5 文件的md5
* @return com.xuecheng.base.model.RestResponse<java.lang.Boolean> false不存在,true存在
* @description 检查文件是否存在
*/
@Override
public RestResponse<Boolean> checkFile(String fileMd5) {
//TODO 1.查询数据库
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
//TODO 2.如果数据库存在再查询minio
if (mediaFiles != null) {
GetObjectArgs getObjectArgs = GetObjectArgs.builder()
//mediaFiles会有记录
.bucket(mediaFiles.getBucket())
.object(mediaFiles.getFilePath())
.build();
try {
FilterInputStream inputStream = minioClient.getObject(getObjectArgs);
if (inputStream != null) {
//文件已经存在
return RestResponse.success(true);
}
} catch (Exception e) {
e.printStackTrace();
}
}
//文件不存在
return RestResponse.success(false);
}
private String getChunkFileFolderPath(String fileMd5) {
return fileMd5.substring(0, 1) + "/" + fileMd5.substring(1, 2) + "/" + fileMd5 + "/chunk/";
}
检查分块是否存在
对于Service的checkChunk分块文件校验方法我觉得还有另外一个见解思路
课程中对分块文件的校验思路只是检查一下minio系统中有没有对应的minio文件,如果没有的话就上传分块
但是我觉得这个地方可以改一改
有化成根据fileMd5去数据库查一下是否存在这个文件,然后得到这个文件的getFilePath,查看一下是否有完整的视频文件,如果有的话直接不用检查Minio分块文件是否存在了,假如说Minio没有完整的文件,那再上传对应的分块文件
可能有的人会问,我们明明已经在checkFile中校验了,为什么还要校验?
因为我在学习这个课程的时候我发现一个bug,就是我无法重复上传同一个文件,显然是不合理的
我说的重复上传的意思是毫无征兆的上传不上,前端也不会给什么提示信息,一直卡在百分之九十多的位置不动,为了优化这个地方我才采用了我这个思路
而且我不明白课程中checkFile明明已经校验为true文件存在了,还要进行checkChunk检查分块、合并分块的逻辑
如果是我做前端的话,我就当checkFile返回true时也不进行checkchunk检查分块,更不会合并分块

下面的TODO 1便是我新添加上的,只需要加载Todo2之前即可
2.4.3 合并分块文件模块也要加
//TODO 1.判断fileMd5对应的文件已经合并成一个完整的文件了,如果有了的话,那也不需要检查分块了
//判断Minio系统中是否有已经有合并的文件了,如果有的话没有分块所在路径也无所谓
RestResponse<Boolean> booleanRestResponse = this.checkFile(fileMd5);
if (booleanRestResponse.getResult()){
//文件已经存在
return RestResponse.success(true);
}
/**
* 分块不会存在于数据库,直接查询minio系统即可
*
* @param fileMd5 文件的md5
* @param chunkIndex 分块序号
* @return com.xuecheng.base.model.RestResponse<java.lang.Boolean> false不存在,true存在
* @description 检查分块是否存在
*/
@Override
public RestResponse<Boolean> checkChunk(String fileMd5, int chunkIndex) {
//TODO 2.根据MD5得到分块文件的目录路径
//分块存储路径:md5前两位为两个目录,MD5值也是一层目录,chunk目录存储分块文件
String chunkFileFolderPath = this.getChunkFileFolderPath(fileMd5);
GetObjectArgs getObjectArgs = GetObjectArgs.builder()
//视频的桶
.bucket(bucket_video)
//文件名是目录路径+分块序号
.object(chunkFileFolderPath+chunkIndex)
.build();
try {
FilterInputStream inputStream = minioClient.getObject(getObjectArgs);
if (inputStream != null) {
//文件已经存在
return RestResponse.success(true);
}
} catch (Exception e) {
e.printStackTrace();
}
return RestResponse.success(false);
}
2.4.2 上传分块文件
2.4.2.1 BigFilesController
@ApiOperation(value = "上传分块文件")
@PostMapping("/upload/uploadchunk")
public RestResponse uploadChunk(@RequestParam("file") MultipartFile file,
@RequestParam("fileMd5") String fileMd5,
@RequestParam("chunk") int chunk) throws Exception {
//1.创建一个临时文件,前缀是"minio",后缀是“.temp”
File tempFile = File.createTempFile("minio", ".temp");
file.transferTo(tempFile);
return mediaFileService.uploadChunk(fileMd5,chunk,tempFile.getAbsolutePath());
}
2.4.2.2 MediaFileServiceImpl
/**
* @param fileMd5 文件md5
* @param chunk 分块序号
* @param localChunkFilePath 本地文件路径
* @return com.xuecheng.base.model.RestResponse
* @description 上传分块
*/
@Override
public RestResponse uploadChunk(String fileMd5, int chunk, String localChunkFilePath) {
//TODO 将分块文件上传到minio
//传空默认返回类型MediaType.APPLICATION_OCTET_STREAM_VALUE application/octet-stream未知流类型
String mimeType = getMimeType(null);
//获取分块文件的目录
String chunkFileFolderPath = this.getChunkFileFolderPath(fileMd5);
boolean b = this.addMediaFilesToMinIO(localChunkFilePath, bucket_video, chunkFileFolderPath + chunk, mimeType);
if (!b) {
//false
return RestResponse.validfail(false, "上传分块文件{" + fileMd5 + "/" + chunk + "}失败");
}
//上传分块文件成功
return RestResponse.success(true);
}
/**
* 将文件上传到MinIo
*
* @param bucket 桶
* @param localFilePath 文件在本地的路径
* @param objectName 上传到MinIo系统中时的文件名称
* @param mimeType 上传的文件类型
*/
private boolean addMediaFilesToMinIO(String localFilePath, String bucket, String objectName, String mimeType) {
try {
UploadObjectArgs uploadObjectArgs = UploadObjectArgs.builder()
//桶,也就是目录
.bucket(bucket)
//指定本地文件的路径
.filename(localFilePath)
//上传到minio中的对象名,上传的文件存储到哪个对象中
.object(objectName)
.contentType(mimeType)
//构建
.build();
minioClient.uploadObject(uploadObjectArgs);
log.debug("上传文件到minio成功,bucket:{},objectName:{}", bucket, objectName);
return true;
} catch (Exception e) {
e.printStackTrace();
log.info("上传文件出错,bucket:{},objectName:{},错误信息:{}", bucket, objectName, e.getMessage());
return false;
}
}
2.4.3 合并分块文件
-
找到分块文件
-
调用Minio的SDK,将分块文件进行合并
-
校验合并后的文件与原文件是否一致
合并后的文件来源于分块文件,如果上传分块的过程中有问题导致数据丢失,那合并后的文件肯定是不完整的
合并后的文件与原文件一致,才可以说视频是上传成功的
-
将文件信息入库
-
最后清理Minio的分块文件
2.4.3.1 BigFilesController
/**
* @param fileMd5 文件md5值
* @param fileName 合并分块之后要入库,fileName原始文件名要写在数据库
* @param chunkTotal 总共分块数
*/
@ApiOperation(value = "合并文件")
@PostMapping("/upload/mergechunks")
public RestResponse mergeChunks(@RequestParam("fileMd5") String fileMd5,
@RequestParam("fileName") String fileName,
@RequestParam("chunkTotal") int chunkTotal) throws Exception {
Long companyId = 1232141425L;
//文件信息对象
UploadFileParamsDto uploadFileParamsDto = new UploadFileParamsDto();
uploadFileParamsDto.setFilename(fileName);
uploadFileParamsDto.setTags("视图文件");
uploadFileParamsDto.setFileType("001002");//数据字典代码 - 001002代表视频
return mediaFileService.mergeChunks(companyId, fileMd5, chunkTotal, uploadFileParamsDto);
}
2.4.3.2 MediaFileServiceImpl
其实和2.4.1模块同理
可以在mergeChunks放大TODO1之前下面添加这一段代码
假如说合并后的文件已经存在了,就不需要进行合并了
//TODO 0.如果已经有了合并分块后对应的文件的话,就不用再合并了
//判断Minio系统中是否有已经有合并的文件了,如果有的话没有分块所在路径也无所谓
RestResponse<Boolean> booleanRestResponse = this.checkFile(fileMd5);
if (booleanRestResponse.getResult()){
//文件已经存在
return RestResponse.success(true);
}
/**
* 为什么又companyId 机构ID?
* 分布式文件系统空间不是随便使用的,比如某个机构传输的课程很多很多,那我们就可以收费了(比如超过1Tb便开始收费)
* 知道了companyId我们就知道是谁传的,也知道这些机构用了多少GB
*
* @param companyId 机构id
* @param fileMd5 文件md5
* @param chunkTotal 分块总和
* @param uploadFileParamsDto 文件信息(要入库)
* @return com.xuecheng.base.model.RestResponse
* @description 合并分块
*/
@Override
public RestResponse mergeChunks(Long companyId, String fileMd5, int chunkTotal, UploadFileParamsDto uploadFileParamsDto) {
//TODO 1.获取所有分块文件
List<ComposeSource> sources = new ArrayList<>();
//1.1 分块文件路径
String chunkFileFolderPath = this.getChunkFileFolderPath(fileMd5);
for (int i = 0; i < chunkTotal; i++) {
sources.add(ComposeSource.builder()
//分块文件所在桶
.bucket(bucket_video)
//分块文件名称
.object(chunkFileFolderPath + i).build());
}
//1.2 指定合并后文件存储在哪里
String filename = uploadFileParamsDto.getFilename();
String fileExt = filename.substring(filename.lastIndexOf("."));
//1.3 获取对象存储名
String filePathByMD5 = this.getFilePathByMD5(fileMd5, fileExt);
ComposeObjectArgs composeObjectArgs = ComposeObjectArgs.builder()
//指定合并后文件在哪个桶里
.bucket(bucket_video)
//最终合并后的文件路径及名称
.object(filePathByMD5)
//指定分块源文件
.sources(sources).build();
//TODO 2.合并分块
try {
minioClient.composeObject(composeObjectArgs);
} catch (Exception e) {
e.printStackTrace();
log.error("合并文件出错:bucket:{},objectName:{},错误信息:{}", bucket_video, filePathByMD5, e.getMessage());
return RestResponse.validfail(false, "合并文件出错");
}
//TODO 3.校验合并后的文件与原文件是否一致
//3.1校验时先要把文件下载下来
File tempFile = this.downloadFileFromMinIO(bucket_video, filePathByMD5);
//3.2 比较原文件与临时文件的MD5值
//将FileInputStream放在括号里,当try..catch执行结束后会自动关闭流,不用加finally了
try (FileInputStream fis = new FileInputStream(tempFile)) {
String mergeFile_md5 = DigestUtils.md5Hex(fis);
if (!fileMd5.equals(mergeFile_md5)) {
log.error("校验合并文件md5值不一致,原始文件{},合并文件{}", fileMd5, mergeFile_md5);
return RestResponse.validfail(false, "文件校验失败");
}
//保存一下文件信息 - 文件大小
uploadFileParamsDto.setFileSize(tempFile.length());
} catch (IOException e) {
e.printStackTrace();
return RestResponse.validfail(false, "文件校验失败");
}
//TODO 4.文件信息
MediaFiles mediaFiles = currentProxy.addMediaFilesToDb(companyId, fileMd5, uploadFileParamsDto, bucket_video, filePathByMD5);
if (mediaFiles == null) {
return RestResponse.validfail(false, "文件入库失败");
}
//TODO 5.清理分块文件
//5.1获取分块文件路径
//this.getChunkFileFolderPath(fileMd5);
this.clearChunkFiles(chunkFileFolderPath, chunkTotal);
return RestResponse.success(true);
}
/**
* 清除分块文件
*
* @param chunkFileFolderPath 分块文件路径
* @param chunkTotal 分块文件总数
*/
private void clearChunkFiles(String chunkFileFolderPath, int chunkTotal) {
//需要参数removeObjectsArgs
//Iterable<DeleteObject> objects =
List<DeleteObject> objects = Stream.iterate(0, i -> ++i)
.limit(chunkTotal)
//String.concat函数用于拼接字符串
.map(i -> new DeleteObject(chunkFileFolderPath.concat(Integer.toString(i))))
.collect(Collectors.toList());
RemoveObjectsArgs removeObjectsArgs = RemoveObjectsArgs.builder()
//指定要清理的分块文件的桶
.bucket(bucket_video)
//需要一个Iterable<DeleteObject>迭代器
.objects(objects)
.build();
//执行了这段方法并没有真正的删除,还需要遍历一下
Iterable<Result<DeleteError>> results = minioClient.removeObjects(removeObjectsArgs);
results.forEach(f->{
try {
//get方法执行之后才是真正的删除了
DeleteError deleteError = f.get();
} catch (Exception e) {
e.printStackTrace();
}
});
// 或者是下面这种遍历方式,都是可以的
// for (Result<DeleteError> deleteError:results){
// DeleteError error = deleteError.get();
// }
}
最终合并后的路径是在getFilePathByMD5中
/**
* @param fileMd5 文件md5值
* @param fileExt 文件扩展名
*/
private String getFilePathByMD5(String fileMd5, String fileExt) {
return fileMd5.substring(0, 1) + "/" + fileMd5.substring(1, 2) + "/" + fileMd5 + "/" + fileMd5 + fileExt;
}
2.4.4 测试
- 首先修改Springboot-web默认上传文件大小
前端对文件分块的大小为5MB,SpringBoot web默认上传文件的大小限制为1MB,这里需要在media-api工程修改配置如下:
spring:
servlet:
multipart:
max-file-size: 50MB
max-request-size: 50MB
max-file-size
指定单个文件上传的最大大小限制,单个文件的大小如果超过了这个配置的值,将会导致文件上传失败
max-request-size
指定整个 HTTP 请求的最大大小限制,包括所有上传文件和其他请求数据,请求的总大小超过了这个配置的值,将会导致整个请求失败
两个配置项的值可以使用标准的大小单位,比如
KB(千字节)、MB(兆字节)等。在你的例子中,50MB表示最大文件大小和最大请求大小都被限制为 50 兆字节
- 点击“上传视频”按钮
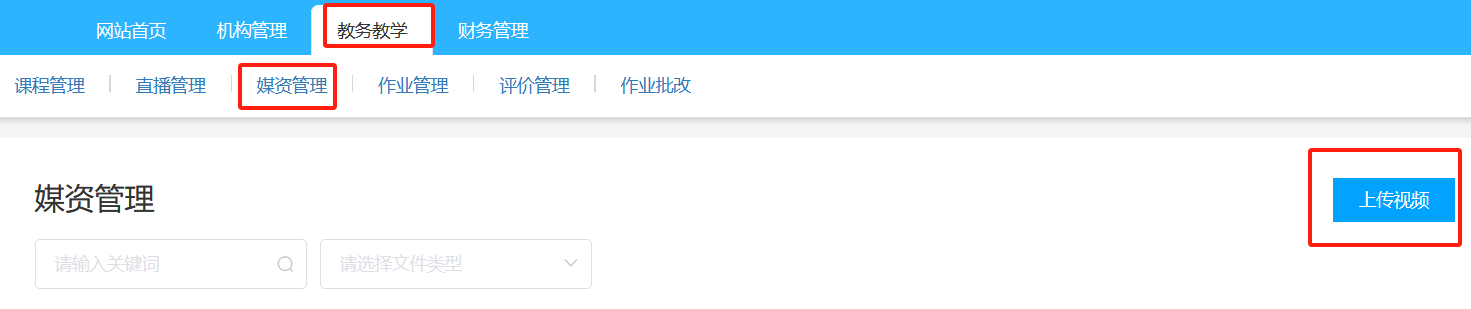
- 点击“添加文件”按钮
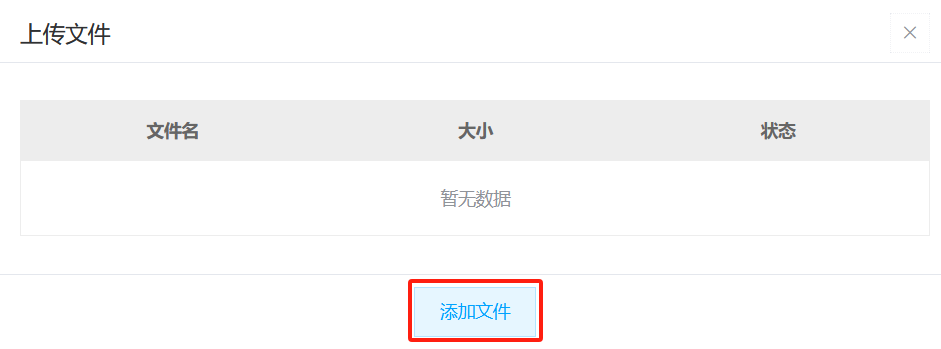
- 上传文件
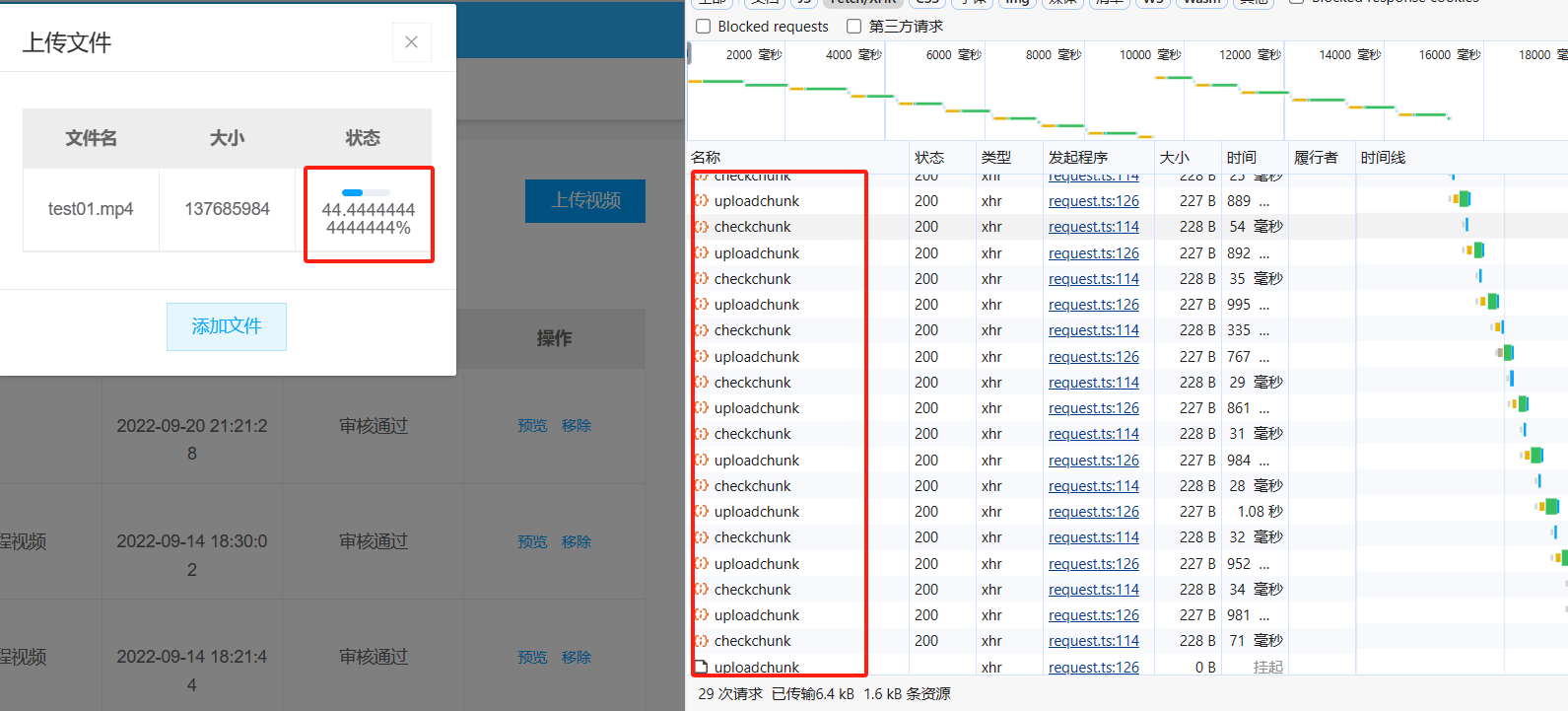
-
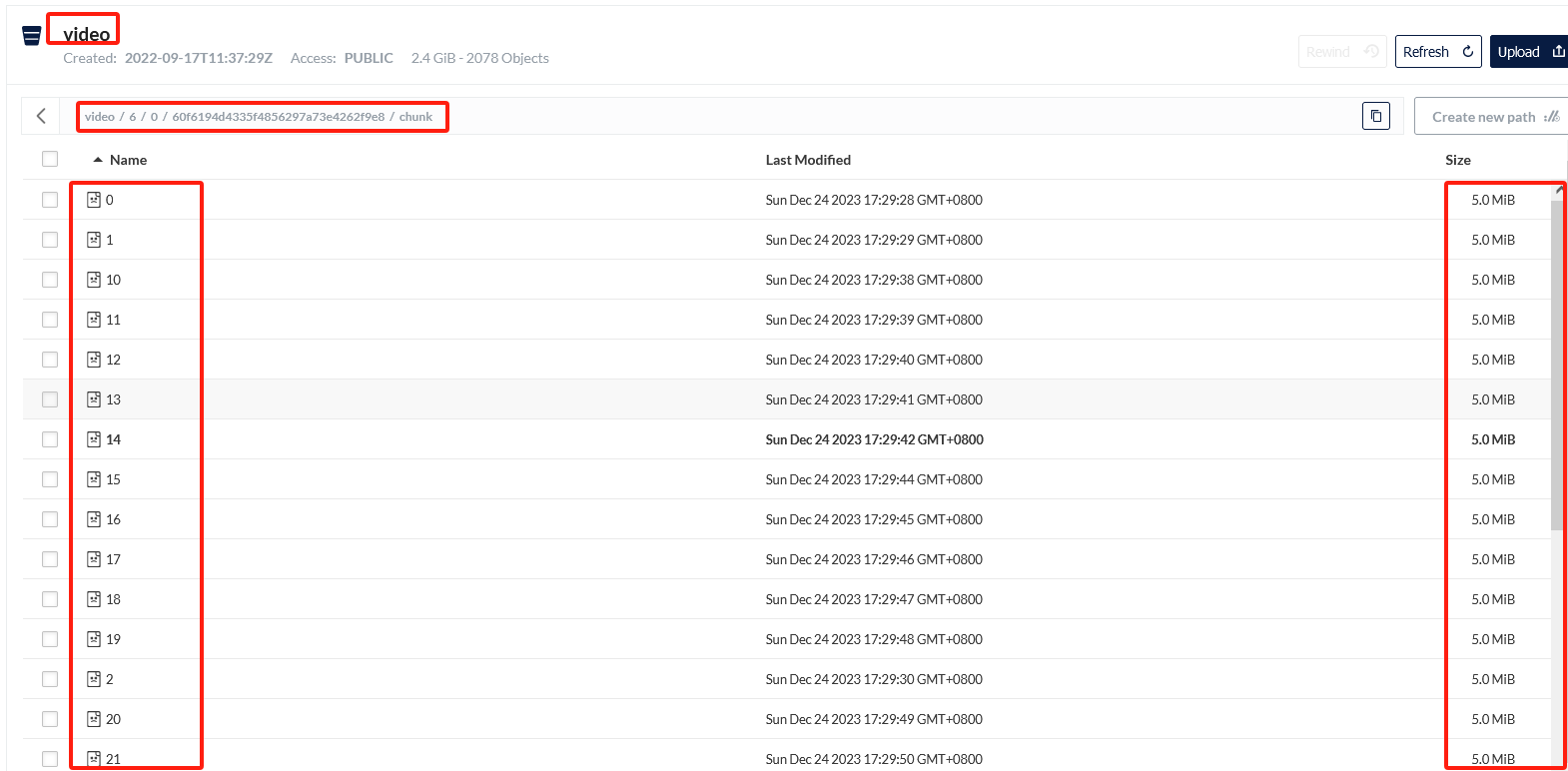
查看Minio系统
分块上传挺成功的
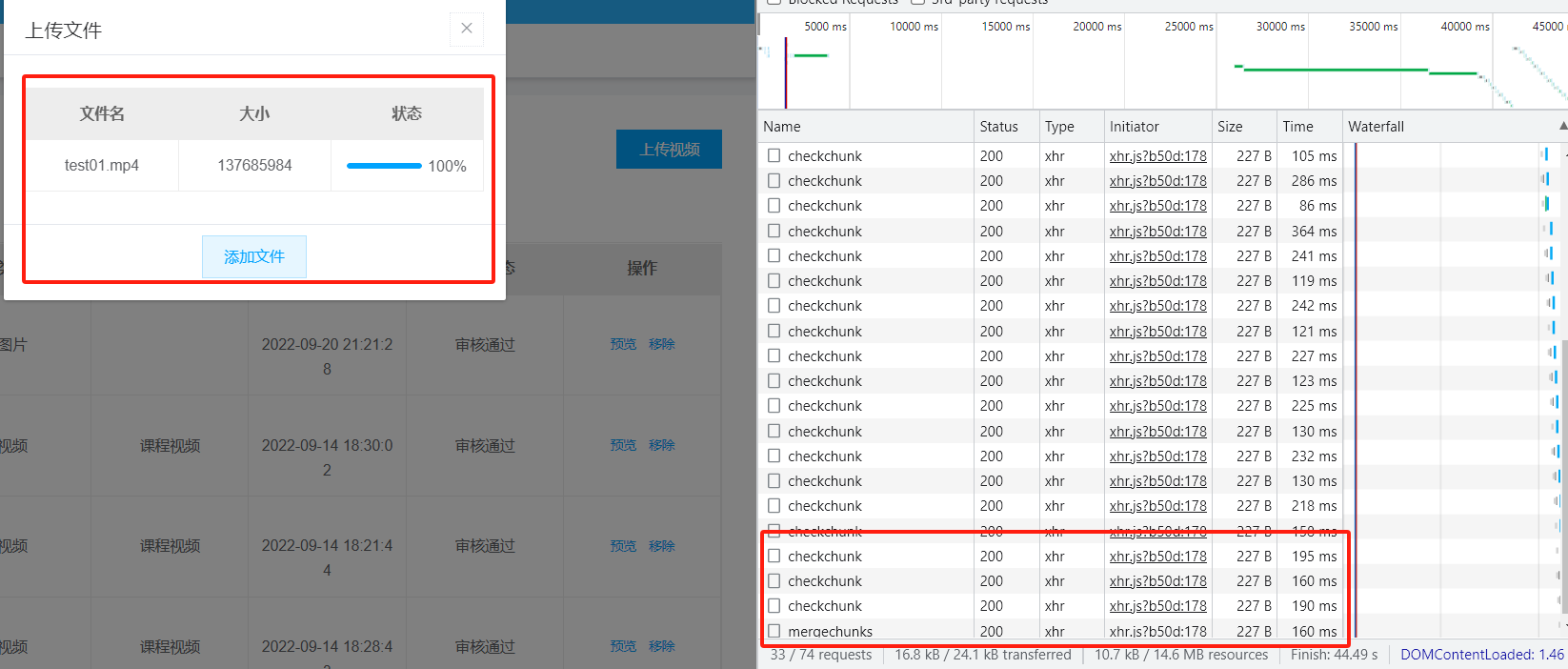
-
合并分块之后
所有的分块都被清理了,然后合并成一个文件
-
经过我的2.4.3与2.4.1优化之后,上传挺正常了
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 树莓派ubuntu:vscode远程SSH开发调试
- consul
- 未来城市之畅想
- 石头剪刀布游戏(100%用例)C卷 (Java&&Python&&C语言&&C++)
- OpenAI亲授ChatGPT “屠龙术”!官方Prompt 工程指南来啦
- [LitCTF 2023]Vim yyds
- github提交代码报错22或443超时
- 到底有多好用?在IT行业人人都知道的Ansible详解,建议收藏
- HCLA从基础到成熟
- 【教程】React-Native代码规范与加固详解