转转OLAP自助分析实践
文章目录
1.导读
本次分享介绍转转在OLAP自助分析场景的实践。主要围绕背景介绍、技术实现、问题优化展开和大家聊聊转转为什么要做自助分析,以及期间踩过的一些坑,希望能给读者朋友带来一些参考。
2.背景介绍
这一部分先给大家交代一下转转为什么要做自助分析,自助分析核心解决了什么问题,建设过程中遇到的卡点。帮助大家对转转做OLAP自助分析这个事情有个基本的了解,以及对照自己的业务场景怎么更好的避坑。
2.1 为什么要做自助分析
做大数据开发的朋友是否有这样的困扰:
随着业务的快速发展,业务侧看数的需求更是变化频繁,很多线上的看板是改了又改,今天加个指标、明天加个维度、同样的指标换个维度组合又是一个新的看板需求,极大的增加了数仓RD在应用层建设的工作量,分析师也成了存粹的提数工具人,很难聚焦在业务数据的分析上。
在看板开发、分析师取数的效率上也不容乐观,从排期到上线往往都需要比较长的周期,短则几天,长则一两周甚至更久。
基于上述场景,我们开始筹划建设自助分析平台,期望将数仓RD和分析师从这种境况解脱出来去做些更有意义的事情。
2.2 核心解决的问题
- 满足业务侧灵活组合各种维度进行业务指标分析的诉求
- 提升业务侧获取数据的效率
- 减少数仓RD同学在固定看板需求开发和迭代上的时间投入
- 减少分析师在日常取数需求上的时间投入
2.3 建设初期的卡点
- 要求上手简单易理解
因为自助分析是要直接给到业务侧品类运营、供应链运营、产品运营等团队使用,对于平台的易用性和数据的可理解性就要求比较高,对于从0到1去搭建一个这样的平台,其实是一个蛮大的挑战。
- 时间紧、任务重
从规划做自助分析到一期预期上线的时间,前后就一个多月,加上前后端的开发资源比较紧张,能够投入到这个事情上的数仓RD也只有1-2人,对于整个项目的研发来说时间是非常紧的,开发的压力也比较大。
3.技术实现
鉴于上一部分提到的一些背景,如果采用纯自研的方案,很难在那么短的时间并且投入那么少的研发资源的前提下取的很好的效果,结合我们本身就一直在使用Quick BI进行数据可视化分析现状,最终选择了BI工具+OLAP数据库的组合,从另一个角度解决上述提到的卡点,达到了预期的效果。
一句话概括就是:利用Quick BI灵活的托拉拽图表配置及自动生成查询SQL的能力 + StarRocks数据库强大的数据计算能力,实现基于高度冗余的业务数据明细大宽表数据集为基础的、灵活的自助分析。
3.1 技术架构
项目建设初期是以离线作为切入点的,二期才陆续迭代了实时数据集的能力。使用到的产品及组件有Quick BI、StarRocks、Hive、Spark、Flink、kafka等。
架构图如下:
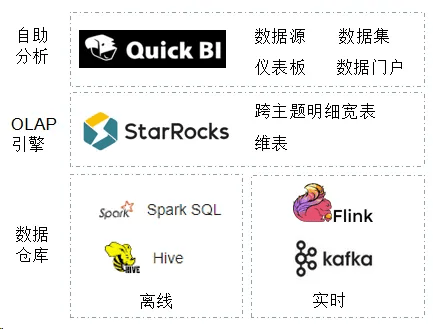
数据链路如下:

3.2 基于Quick BI+StarRocks的自助分析功能实现
开始这部分介绍前,先给大家讲讲Quick BI是个啥。Quick BI是阿里云旗下的智能BI服务平台,我们使用的是私有化部署的版本。它可以提供海量数据实时在线分析服务,支持拖拽式操作和丰富的可视化效果,帮助用户轻松自如地完成数据分析、业务数据探查、报表制作等工作。具体怎么使用以及它的功能特性可以自行到官网查看学习,下面是它的产品功能架构供大家了解:
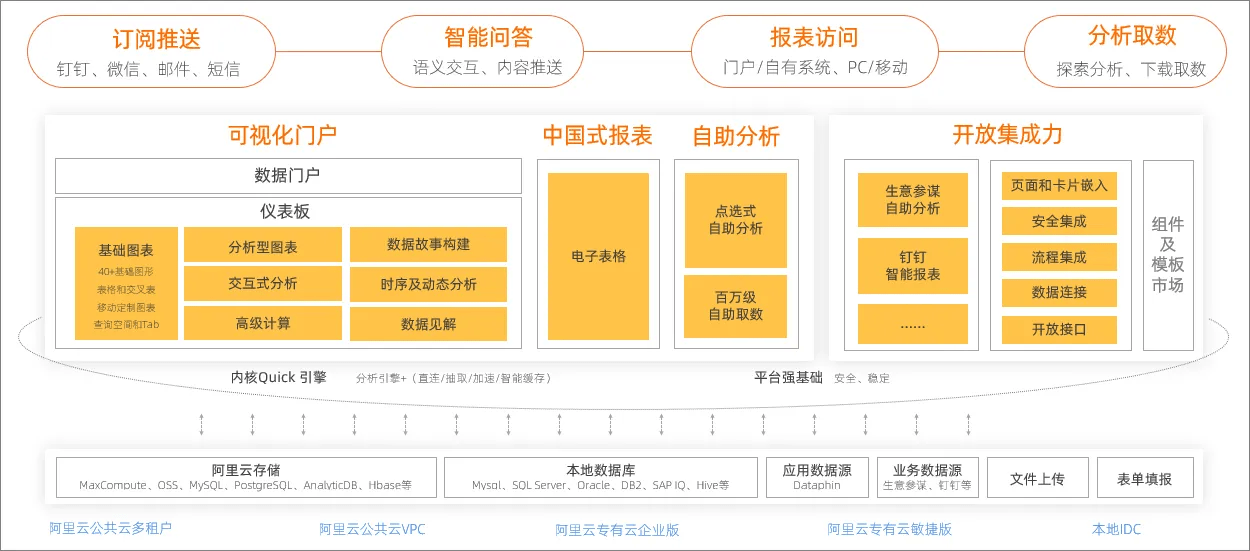
接下来我们重点展开说说使用Quick BI进行自助分析的功能实现需要做哪些事情,总结成一句话就是:创建数据源用于链接StarRocks数据库;然后读取StarRocks表创建数据集,同时进行维度和指标的定义;最后创建仪表板即可进行数据的自助分析。
这里可以看到,跟大多数BI一样,无非就是获取数据、创建数据集、托拉拽图表进行数据可视化。
重点说说,为了满足易用和易理解的诉求,我们在数据集层面做的一些设计。
数据结构设计如下:
核心三类字段,分别是data_type、维度字段、原子指标字段。
data_type用于区分不同的数据,不同data_type具备不同的维度和原子指标,对不支持的维度和原子指标直接存储为null。
| data_type | 维度1 | 维度… | 维度n | DAU | 曝光pv | 曝光uv | 商详pv | 商详uv | … | 原子指标n |
|---|---|---|---|---|---|---|---|---|---|---|
| DAU | 枚举值 | null | null | token | null | null | null | null | … | … |
| 曝光 | 枚举值 | 枚举值 | null | null | token | token | null | null | … | … |
| 商详 | 枚举值 | 枚举值 | null | null | null | null | token | token | … | … |
| 确单 | 枚举值 | 枚举值 | null | null | null | null | null | null | … | … |
| … | 枚举值 | null | 枚举值 | null | null | null | null | null | … | … |
这样的结构高度冗余,虽然不易于维护,但是好处也很明显:一个数据集即可拿到几乎所有业务过程的数据,以及相关联的各个维度和指标。
对于维度和指标体系,运营同学是相对比较熟悉的,这样做的好处就体现出来了:他们不需要去理解那么多的数据集,不用去根据分析的场景判断要用哪个数据集,只要知道自己想到什么维度组合、分析什么指标即可,极大的简化了运营理解数据的成本,降低了使用难度。
数据集SQL示例:
select 维度1
...
,维度n
,case when t.data_type = 'DAU' then DAU end as DAU
,case when t.data_type = '曝光' then 曝光pv end as 曝光pv
,case when t.data_type = '曝光' then 曝光uv end as 曝光uv
,case when t.data_type = '商详' then 商详pv end as 商详pv
,case when t.data_type = '商详' then 商详uv end as 商详uv
...
,原子指标n
from sr_table t
这里再补充一点,数据集SQL定义了原子指标的逻辑,聚合的方式是可以在Quick BI的数据集里面进行配置,包括求和、求均值、计数、去重计数等都是支持的。在维度、原子指标的基础上,还可以进行计算字段的加工,衍生出更多的维度和派生指标。由于时间关系,就不展开讲解怎么配置,大家感兴趣可以去看一下官方文档。
最后一步,就是最终的目标自助分析了。
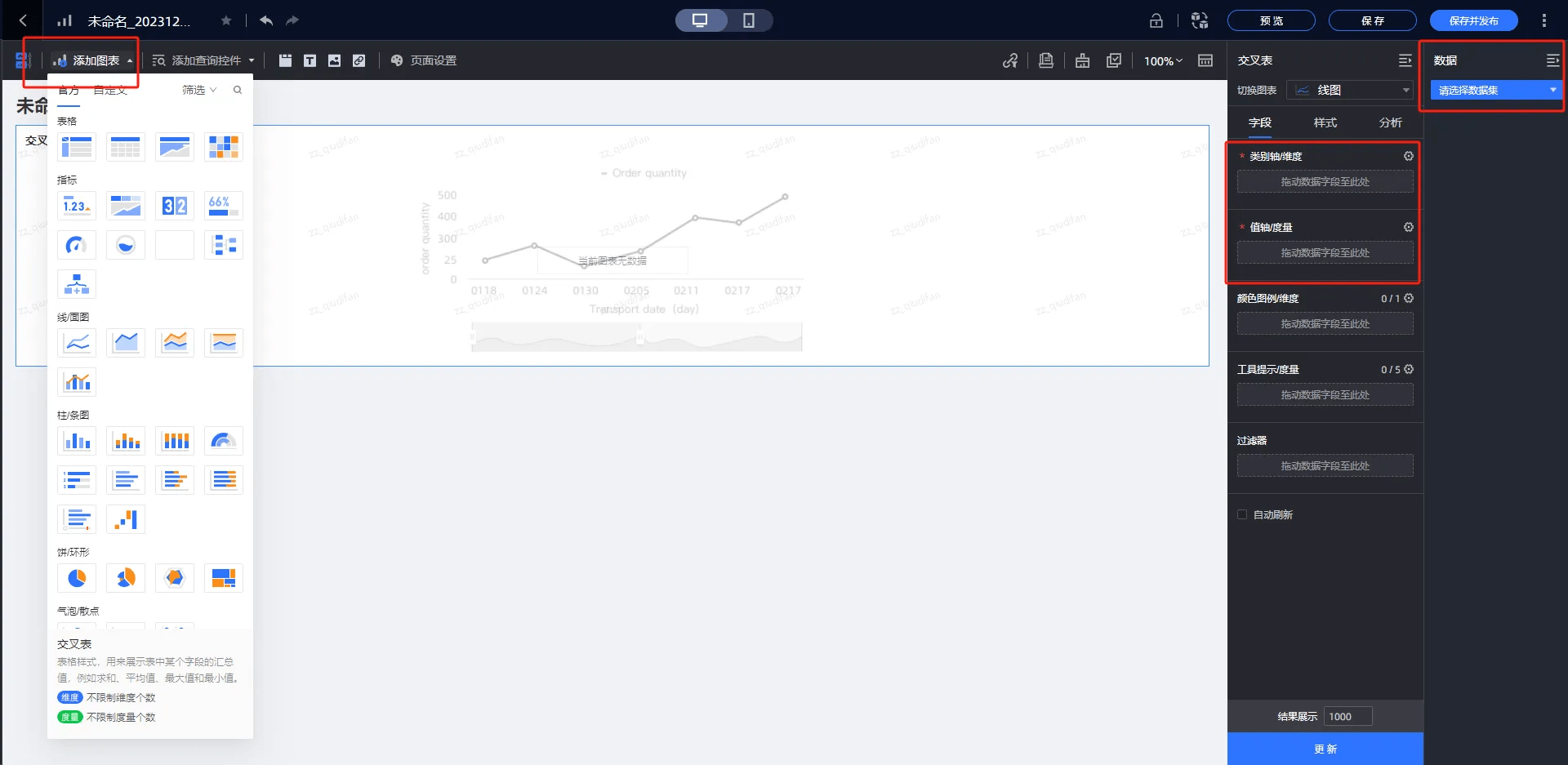
整体流程如下:

简单概括一下就是: 创建仪表板>添加可视化图表>选择数据集>绑定维度和度量(指标)。
目前支持40余种图表样式,包含了表格类、指标类、线/面图类、柱/条图类、饼/环类、气泡/散点类、漏斗/转化关系类、地理类和其他类;涵盖了趋势、比较、分布、关系、空间、时序6个分析大类,同时支持自定义图表类型,基本覆盖了常见的可视化分析方式。
最终呈现的形式:
3.3 为什么选择StarRocks作为OLAP引擎
关于这个问题,起初我们用过一段时间的ClickHouse,受限于集群规模,在我们的数据体量和使用场景下,出现了明显的性能瓶颈(ps:单数据集近200亿行数据,300+维度和指标;长时间周期且比较多维度指标的基于明细数据的复杂查询)。
后面经过测试,StarRocks在我们这个场景下性能要优于ClickHouse,并且在一些特性上更加友好,后面就统一将业务切到了StarRocks上。因为前后业务体量有些差异,加上集群规模也不完全一致,就不贴具体的测试结果,避免引起不必要的误会。但是有几个点,在我们使用的感受上,StarRocks是要明显优于ClickHouse的:
- StarRocks 兼容 MySQL 协议,支持标准 SQL 语法,这点在自助分析的场景实在是太友好了,相比于ClickHouse来说,极大的简化了业务侧运营人员创建计算字段的难度。
- StarRocks 在弹性扩缩容的支持上比ClickHouse要更加友好。
- StarRocks 对Join的操作支持更加友好。
- StarRocks 对多并发的场景支持更好。
- StarRocks 的数据类型跟Hive非常接近,进行数据回导的时候映射更加简单。
(StarRocks集群规模:3FE节点 + 14BE节点)
3.4 上线效果
- 业务侧获取数据的效率提升。原本提一个维度组合的迭代、或者探索性的业务看板需求、分析师取数需求可能需要一周以上的时间才能满足,现在只需要一天甚至几个小时就可以自助获取到想要数据。
- **释放数仓RD和分析师部分精力。**由于业务侧运营同学很多数据需求都可自助满足,提到我们的需求就少了很多,释放出来的精力可以投入到底层数仓的建设和业务数据的分析上。
- **走通了一条可以快速复制的自助分析模式。**以B2C自助分析作为探索,取得一些不错的效果之后,快速的复用到客服、上门等业务。后续有类似的场景都可以依葫芦画瓢快速实现。
- **查询性能和时效性能够满足使用。**目前集群整体的平均查询耗时可以做到秒级,40%左右的查询可以在亚秒级内处理完;实时数据全链路的时效性大概是10S左右。
4.优化案例
这一部分主要介绍一下我们建设自助分析过程中遇到的一些问题,分享一下我们的解决思路。
4.1 内存超限问题优化
由于StarRocks使用的MPP架构,当查询的数据量比较大时,就很容易触发内存超限的问题:Memory of process exceed limit. Pipeline Backend: *.*.*.*, fragment: f7ee1d9e-3bde-11ee-a999-0ab213ea0003 Used: 109007523400, Limit: 109000207318. Mem usage has exceed the limit of BE
从 v3.0.1 开始,StarRocks 支持将一些大算子的中间结果落盘。 使用此功能,您可以在牺牲一部分性能的前提下,大幅降低大规模数据查询上的内存消耗,进而提高整个系统的可用性。开启方法可参考:https://docs.starrocks.io/zh/docs/administration/spill_to_disk/
开启中间结果落盘之后,一定程度上可以缓解内存超限的问题出现,但是只能治标,并不能治本,从根本上还需要减少大查询的产生,核心还是慢查询的治理。
4.2 慢查询问题优化
业务侧配置图表时不规范,很容易就会产生大量的慢查询,经过对慢SQL的分析,发现往往都是没有进行有效的数据裁剪导致全表去查所有数据,从而出现大量的慢查询。
**有效的数据裁剪:**首先是要求业务侧使用自助分析时,日期维度是必须要限制的,其次是对data_type过滤不需要查看的数据类型;在技术层面对日期维度、和data_type维度没有入参时,传递默认值查询返回null结果;其次是在对日期和data_type进行过滤的时候,不要在这两个字段上套函数和处理逻辑,这样才能够正常命中索引。实测进行有效的数据裁剪之后,查询性能可以得到几十倍的提升,极大的减少了慢查询的出现。
**谓词下推机制:**谓词下推是很多OLAP数据库都支持的能力,这里提一下主要是因为Quick BI的数据集是通过SQL创建的,前端托拉拽配置图表生成查询SQL时,是把数据集SQL作为一个子查询去拼接的。带来的一个问题就是如果不能合理利用谓词下推的机制,就会导致索引失效从而全表扫描数据,影响整体的查询体验。实测只要最外层的维度没有额外的转换动作,即可触发谓词下推的机制,从而正常走索引查询。
大致的效果如下:
-- 假如有一张表table
-- table表有一个字段a,a字段有索引
-- SQL1,常规写法,先过滤数据再做进一步的处理
-- 这样写可以命中索引,可以避免加载过多的数据到内存
select *
from (
select *
from table
where a = 'aaa'
) t
;
-- SQL2,当子查询不能提前过滤,但不对维度字段做转换操作
-- 同样可以命中索引,可以避免加载过多的数据到内存
-- 性能等同于SQL1
select *
from (
select *
from table
) t
where t.a = 'aaa'
;
-- SQL3,因为对a增加了转换操作,不能够开启谓词下推
-- 导致无法命中索引,将全表数据加载到内存
select *
from (
select *
from table
) t
where trim(t.a) = 'aaa'
;
如果没有谓词下推机制的话,SQL2也是不能够命中索引的,会去全表扫描。这个机制利用的好可以避免Quick BI的一些坑,在日常数据查询的时候也很有用。特别是使用Quick BI处理一些日期或时间字段拼接SQL的时候,需要格外注意这个问题。
4.3 维值加载慢问题优化
我们经常还会收到过滤器、查询控件中维度的枚举值加载慢的问题反馈,根本的原因是Quick BI通过distinct全表的方式去获取枚举值。针对这种场景,我们的解法是按照用户、订单、商品、流量等主题拆分了若干维表,配合Quick BI的维值加速功能,使仪表板配置和使用过程统一走维表检索枚举值,实现维值毫秒级响应。
4.4 高峰期查询慢问题优化
业务使用高峰时,查询耗时普遍会比日常要慢不少,核心原因在于扎堆使用导致StarRocks集群的负载比较大。经过调研发现,查询高峰主要集中在周一或者月初,出周报、月报需要自助分析一些数据,并且很多都是根据提前配置好的仪表板查询一次对应的数据即可,但是因为查询数据库都是发生在访问页面时,所以伴随扎堆的使用出现了该问题。基于这种场景,我们想到了一个错峰查询的办法:在低峰时(9点前),通过selenium模拟访问仪表板列表,提前将请求的SQL和结果缓存起来。这样一来,减少了高峰期时对StarRocks的查询操作,缓解了集群压力,整体的查询性能也得到保障,业务也优先通过缓存获取到对应的周报、月报数据,提升了用户体验。
大致的方案:部署一个定时调度的python脚本,通过selenium遍历提前配置好的仪表板列表,模拟用户的访问行为去进行翻页,需要控制好翻页的频率,使页面懒加载的内容也能够加载出来。整个过程要控制好停留的时间以及并发,避免把StarRocks查挂了。
4.5 数据写入参数优化
- 实时写入时效性优化。
通过Flink往StarRocks实时写入数据时,要控制好StarRocks的batch_max_rows、batch_max_bytes,以及Flink的Checkpoint参数的大小,否则会出现写入过慢或者集群写蹦的问题,具体要根据自己的数据量和集群规模去调整。因为写入数据较为频繁,并且当batch_max_rows、batch_max_bytes设置太大时,数据的时效性就会变低,因此这几个参数都会设置的较小,当前配置的为:
batch_max_rows = 10000
batch_max_bytes = 58864
Checkpoint = 1
- 离线数据写入优化。
离线导入使用的Apache SeaTunnel,同样需要控制好StarRocks的batch_max_rows、batch_max_bytes参数的大小以及SeaTunnel任务的并行度parallelism,否则也会出现过慢或者集群写蹦的问题。因为考虑到离线数据写入不频繁,一次性写入的数据量较大,所以参数配置的会比较大,当前的配置为:
batch_max_rows = 1500000
batch_max_bytes = 335544320
parallelism = 90
5.写在最后
本文提到的解决方案,绝不是OLAP自助分析的最优解,更不是唯一的答案,只是转转在业务发展过程中,结合当前现状选择的比较适合我们的一种实现方式,且已经在B2C、客服等多个场景中取得了一些成果。希望能够给各位读者带来一些参考价值。
这个解决方案的优点是开发周期短、见效快;缺点就是需要配合比较好用的BI工具实现(业内比较好用的BI工具基本都是收费的,如果公司内部原本没有在用的BI,可能需要额外的采购成本),另外就是数据集的维护成本较高且需要随着业务发展持续迭代。
在OLAP和自助分析探索的道路上,我们也才刚刚开始,后续也将继续聚焦业务痛点,尝试更多的解法。道阻且长,行则将至,大家共勉。
如果本篇文章对大家有所帮助请帮忙点个赞,也欢迎大家在评论区交流~~
参考文档:
Quick BI官方文档:
https://help.aliyun.com/zh/quick-bi
StarRocks官方文档:
https://docs.starrocks.io/zh/docs/introduction/StarRocks_intro/
关于作者
邱狄凡,转转大数据开发工程师,线上业务数仓负责人,主要负责新媒体、B2C、供应链等业务主题数仓建设。
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 吾爱破解置顶的“太极”,太好用了吧!
- Netty通信中的粘包半包问题(五)
- Hubery-个人项目经历记录
- windows服务器相关操作
- 基于muduo库的RtmpServer
- 新年快乐!学习Java第84天,Maven工程继承和聚合关系
- 为什么要用云渲染?3d Max云渲染怎么使用?
- 二、arcgis 点shp数据处理
- 【算法专题】动态规划之路径问题
- labelimg:未找到命令 | 标注工具 labelImg 安装及使用问题解决