集成学习算法
集成学习的核心思想
集成学习的核心思想是,通过组合多个模型,可以弥补单个模型的局限性,减少模型的偏差和方差,从而获得更稳定、更准确的预测。每个基本模型可能对问题的不同方面有不同的专长,通过集成,可以充分利用它们的优势。
ensemble集成
“ensemble”(集成)通常指的是一组基本模型的组合,旨在通过集体决策来提高模型的性能和泛化能力。
常见的集成方法:
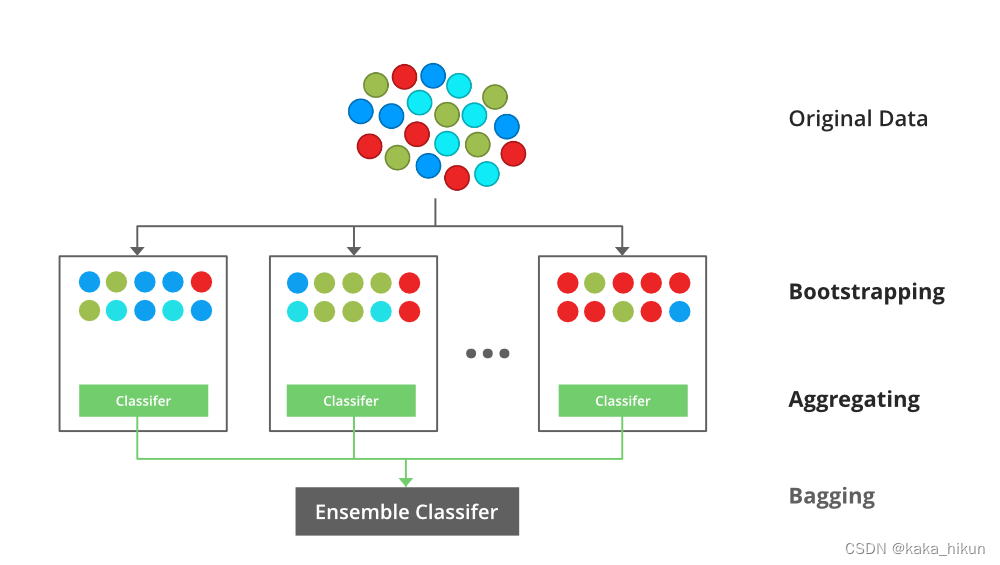
Bagging
通过自助采样的方法,每次从数据集中随机选择一个subset,然后放回初始数据 ,下次取时,该样本仍然有一定概率取到。然后根据对每个subset训练出一个基学习器,然后将这些基学习器进行结合。对于分类任务可以通过vote来输出结果回归任务可以求平均值。
伪代码
- 给定一个大小为n训练集T
- Bagging通过从T中进行有放回采样,得到n’个新的训练集Ti,每个Ti的大小为m;
- 将得到的n’个新训练集,分别用于训练分类器,得到n’个结果;
- 将n’个结果进行投票,票数多的为最终分类值。
Boosting
- Boosting是一种将弱学习器转换为强学习器的算法
- 用一种迭代的方法:
先从初始训练集训练出一个基学习器,然后根据基学习器的表现对训练样本进行调整,使得先前基学习器做错的训练样本在后续受到更多的关注,然后基于调整后的样本分布来训练下一个基学习器。Boosting 的代表是Adam Boosting
伪代码
- 在训练集T上,训练一个弱分类器
- 根据上一步的结果对训练集T进行权值调整,训练集T中数据被赋予新的权值:对错分的样本数据增加权重,对正确分类的样本数据进行降低权重;得到权值调整后,更新好的训练集T’
- 在权值调整后的训练集T’上,进行弱分类器的学习训练;
- 选代步骤2,直到弱学习器数达到事先指定的数目X
- 最终将这X个弱学习器通过结合策略进行整合,得到最终的强学习器。

Adaboost自适应增强
是一种迭代算法,通过逐步提高错误分类样本的权重来训练一系列弱分类器,并对它们的预测结果进行加权组合。
主要步骤
初始化样本权重:将每个训练样本的权重初始化为相等的值,确保初始时每个样本对模型的影响相同。
迭代训练基本模型:Adaboost 使用一系列弱分类器(通常是决策树、支持向量机、朴素贝叶斯等),在每一轮迭代中,它选择一个基本模型,并对训练数据进行训练。训练完成后,它会计算错误分类的样本的权重,并提高这些错误分类样本的权重,以便下一轮迭代中更关注它们。
计算基本模型的权重:对于每个基本模型,Adaboost 会计算一个权重,表示这个模型在最终预测中的重要性。权重取决于模型的分类准确性。
加权组合:在最终的预测中,Adaboost 将每个基本模型的预测结果按照其权重进行组合,从而得到最终的分类结果。
RegionBoost(区域增强)
-
Adaboost的一种扩展和改进版本,旨在改善目标检测问题中的性能。
-
RegionBoost 强调对目标区域的分类,而不仅仅是对单个像素或特征的分类。它在每一轮迭代中选择具有最大增强权重的区域,并为该区域训练一个弱分类器。然后,将这些弱分类器组合成级联分类器,以便逐渐提高目标区域的检测性能。
主要步骤:
初始化权重:初始化每个图像区域(通常是固定大小的矩形区域)的权重,初始时所有权重相等。
迭代训练:在每一轮迭代中,RegionBoost 选择具有最大增强权重的区域,然后为该区域训练一个弱分类器。训练过程中,会调整区域的权重,使错误分类的区域在下一轮中得到更多的关注。这个过程类似于Adaboost,但它关注的是区域级别的分类。
级联分类器:通过组合所有弱分类器,构建一个级联分类器。级联分类器根据一系列弱分类器的决策来决定每个区域是否包含目标对象。
增强性能:RegionBoost 不断迭代,直到达到一定的性能或停止条件。通过迭代训练,它逐渐提高了目标检测的性能,减少了误报率。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 作为Java程序员还不知道Spring中Bean创建过程和作用?
- Uboot
- 【Python】如何快速知道当前python所用库的路径
- Visual Studio 代码 怎么快速多行注释和取消注释
- rk3588中编译带有ffmpeg的opencv
- BM100系列开关量信号隔离器在水泥厂的应用
- dbus-monitor使用详解
- Golang 搭建 WebSocket 应用(八) - 完整代码
- 【Unity入门】物体5种移动方法
- flac是什么文件格式?如何获取?如何转换成MP3?