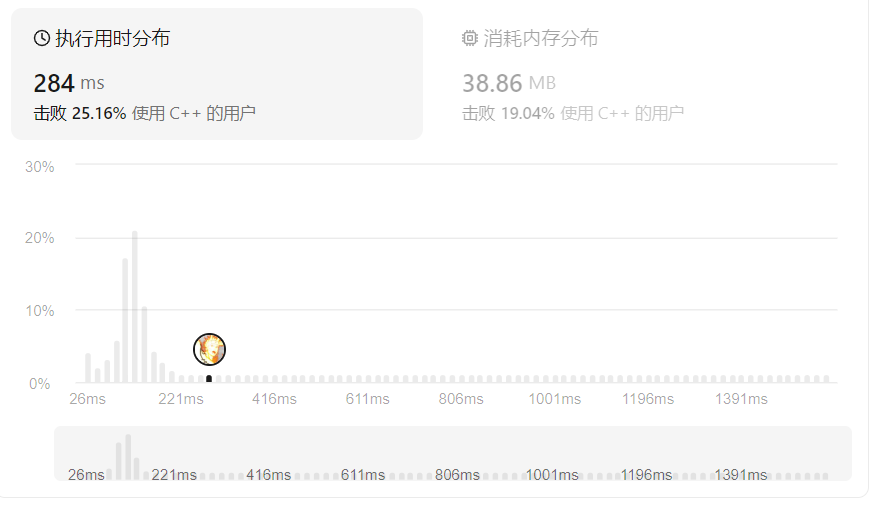
力扣:127. 单词接龙 题解
发布时间:2024年01月07日
Problem: 127. 单词接龙
前言
好好好!又做出来一道困难题,逐渐在进步,莫西莫西!!!
预备知识
此题用到了广度优先搜索遍历,以及哈希表的运用。c++中哈希表是unordered_map。如果对此不了解的uu,建议查看相关介绍博客和更简单的题目!!!
解题思路
该题解法为:广度优先搜索遍历 + 哈希表的运用。
- 我们先用一个哈希集合去存储wordlist所有字符串,让之后的查询复杂度降为O(1)。

- 再次遍历wordlist,对每个s的下一个状态进行查询,复杂度为260,并且将每个s的下一个状态存储到一个哈希表mm(unordered_map<string, vector>)中,具有记忆化功能,之后查询为O(1)。
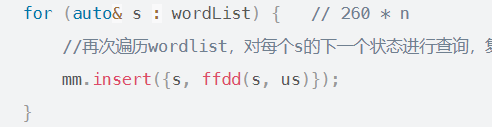
- 在ffdd查询s下一个状态的函数中主要遍历有以下功能:
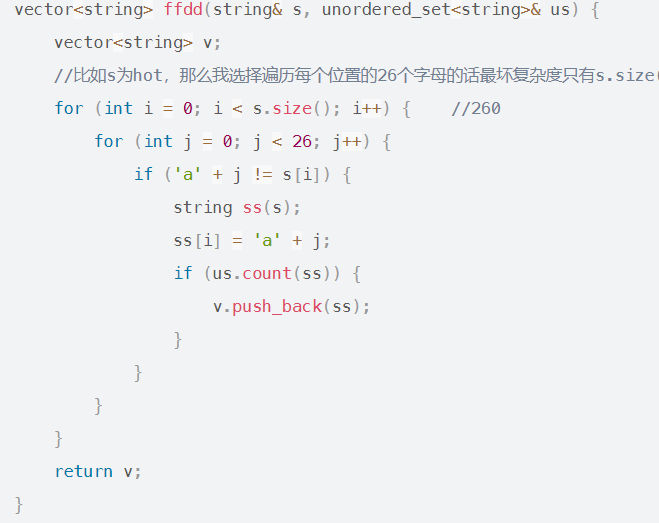
比如s为hot,那么我选择遍历每个位置的26个字母的话最坏复杂度只有s.size() * 26,即10 * 26,但是我如果选择遍历wordlist中的话,就麻烦多了,首先是5000的长度,况且找到之后怎么确定是s的下一个状态,时间复杂度肯定不是O(1)。因此如果用一个哈希表记录wordlist,在用260的复杂度便可以找到s的下一个状态的所有字符串。
- 对于beginword,我单独进行了一次查找下一个状态的操作。

- 最后使用广度优先搜索进行所有下一个状态的处理与弹出,最多5000下一个状态。

复杂度
时间复杂度:
O(260 * n)
空间复杂度:
O(5000 * 3),只计算了mm,us,fd。
Code
class Solution {
public:
unordered_map<string, vector<string>> mm;
vector<string> ffdd(string& s, unordered_set<string>& us) {
vector<string> v;
//比如s为hot,那么我选择遍历每个位置的26个字母的话最坏复杂度只有s.size() * 26,即10 * 26,但是我如果选择遍历wordlist中的话,就麻烦多了,首先是5000的长度,况且找到之后怎么确定是s的下一个状态,时间复杂度肯定不是O(1)。因此如果用一个哈希表记录wordlist,在用260的复杂度便可以找到s的下一个状态的所有字符串。
for (int i = 0; i < s.size(); i++) { //260
for (int j = 0; j < 26; j++) {
if ('a' + j != s[i]) {
string ss(s);
ss[i] = 'a' + j;
if (us.count(ss)) {
v.push_back(ss);
}
}
}
}
return v;
}
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> us, fd;
for (auto& s : wordList) { //n
//我们先用一个哈希集合去存储wordlist所有字符串,让之后的查询复杂度降为O(1)。
us.insert(s);
}
for (auto& s : wordList) { // 260 * n
//再次遍历wordlist,对每个s的下一个状态进行查询,复杂度为260,并且将每个s的下一个状态存储到一个哈希表mm(unordered_map<string, vector<string>>)中,具有记忆化功能,之后查询为O(1)。
mm.insert({s, ffdd(s, us)});
}
int cnt = 0;
//进行广度优先搜索的存储节点的队列
queue<string> q;
//对于beginword,我单独进行了一次查找下一个状态的操作
for (int i = 0; i < beginWord.size(); i++) { //260
for (int j = 0; j < 26; j++) {
if ('a' + j != beginWord[i]) {
string ss(beginWord);
ss[i] = 'a' + j;
if (us.count(ss)) {
q.push(ss);
//再使用一个哈希集合确保是beginword的下一个状态并且进入队列的字符串不会再次被放入队列中,这样的话push的操作最多执行5000次。
fd.insert(ss);
}
}
}
}
cnt++;
while (!q.empty()) {
int size = q.size();
//5000
cnt++;
for (int ii = 0; ii < size; ii++) {
string s = q.front();q.pop();
//cnt必须先++,因为这找到endword就会return了
if (s == endWord) return cnt;
for (int i = 0; i < mm[s].size(); i++) {
if (fd.count(mm[s][i]) == 0) {
q.push(mm[s][i]);
//再使用一个哈希集合确保是mm[s][i]的下一个状态并且进入队列的字符串不会再次被放入队列中,这样的话push的操作最多执行5000次。
fd.insert(mm[s][i]);
}
}
}
}
return 0;
}
};
其它细节
可以尝试用输出日志的方式来获得局部代码的正确性。对于比较长的代码,我们应该在写完整个代码之前,已经完成多个地方的日志输出。多加练习能够提高自己写代码的正确性。
for (auto& [a, b] : pp) {
//调试bug的时候可以用输出的方法
cout << a << b << endl;
}
推荐博客或题目
博客
题目
深广度优先搜索
- 所有可能的路径 难度:++
- 钥匙和房间 难度:++
- 岛屿的周长 难度:+++
- 岛屿数量 难度:+++
- 岛屿的最大面积 难度:+++
- 被围绕的区域 难度:+++
- 太平洋大西洋水流问题 难度:++++
- 最大人工岛 难度:++++
哈希表
文章来源:https://blog.csdn.net/weixin_62021811/article/details/135384019
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 无人机航迹规划(四):七种元启发算法(DBO、LO、SWO、COA、LSO、KOA、GRO)求解无人机路径规划(提供MATLAB代码)
- 常见位运算模板方法总结(包含五道例题)
- 抖音详情API:开发环境搭建与工具选择
- AI绘画资源分享
- 一文初识Linux进程(超详细!)
- linux如何清理磁盘,使得数据难以恢复
- 墙地砖外形检测的技术方案-图像形态学
- 微信小程序chooseAvatar获取头像
- 考研复试复习-数据库原理(1绪论)
- 《JSR303参数校验》