Spark Core基础知识
一.RDD的基本介绍
1.什么是RDD
RDD:英文全称Resilient Distributed Dataset,叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变,可分区,里面的元素可并行计算的集合.
Resilient弹性:RDD的数据可以存储在内存或者磁盘当中,RDD的数据可以分区
Distributed分布式:RDD的数据可以分布式存储,可以进行并行计算
Dataset数据集:一个用于存放数据的集合
2.RDD的五大特性
①RDD是由一系列分区组成的(必须的)
②对RDD做计算,相当于对RDD的每个分区做计算(必须的)
③RDD之间存在着依赖关系,宽依赖和窄依赖(必须的)
④对于KV类型的RDD,我们可以进行自定义分区方案(可选的)
⑤移动数据不如移动计算,让计算程序离数据越近越好(可选的)
3.RDD的五大特点
①分区:RDD逻辑上是分区的,仅仅是定义分区的规则,并不是直接对数据进行分区操作,因为RDD本身不存储数据.
②只读:RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD
③依赖:RDD之间存在依赖关系,宽依赖和窄依赖
④缓存:如果在应用程序中多次使用同一个RDD,可以将该RDD缓存起来,该RDD只有在第一次计算的时候会根据血缘关系得到分区的数据.
⑤checkpoint:与缓存类似,都是将中间一个RDD结果保存起来,只不过checkpoint支持持久化保存
二.如何构建RDD
构建RDD对象的方式主要有两种:
1).通过textFile(data):通过读取外部文件的方式来初始化RDD对象,实际工作中经常使用.
2).通过parallelize(data):通过自定义列表的方式来初始化RDD对象,一般用于测试.
1.并行化本地集合方式
from pyspark import SparkConf, SparkContext
import os
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("并行化本地集合创建RDD")
# 1- 创建SparkContext对象
conf = SparkConf().setAppName('parallelize_rdd').setMaster('local[1]')
sc = SparkContext(conf=conf)
# 2- 数据输入
# 并行化本地集合得到RDD
init_rdd = sc.parallelize([1,2,3,4,5], numSlices=6)
# 3- 数据处理
# 4- 数据输出
# 获取分区数
print(init_rdd.getNumPartitions())
# 获取具体分区内容
print(init_rdd.glom().collect())
# 5- 释放资源
sc.stop()相关的API:
# parallelize(参数1,参数2)
使用本地数据构建RDD.参数1:本地数据列表;参数2:可选的,表示有多少个分区
# getNumPartitions
查看RDD的分区数量
# glom
查看每个分区的数据内容
通过本地列表的方式构建RDD,对应分区数量如何确定:
?1-默认和setMaster('local[num]')中的num数量有关.如果是*,就是和机器的CPU核数相同,另外可以指定具体的数字,数字是多少,那么分区数就是多少.
2-parallelize()中第二个参数numSlices可以手动指定RDD的分区数,如果同时设置了local和numSlices,numSlices的优先级高一些
?2.读取外部数据源方式
TextFile API的方式实现:
from pyspark import SparkConf, SparkContext
import os
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("读取文件创建RDD")
# 1- 创建SparkContext对象
conf = SparkConf().setAppName('textfile_rdd').setMaster('local[1]')
sc = SparkContext(conf=conf)
# 2- 数据输入
# 读取文件得到RDD
init_rdd = sc.textFile("file:///export/data/gz16_pyspark/01_spark_core/data/content.txt",minPartitions=4)
# 3- 数据处理
# 4- 数据输出
# 获取分区数
print(init_rdd.getNumPartitions())
# 获取具体分区内容
print(init_rdd.glom().collect())
# 5- 释放资源
sc.stop()通过读取外部数据源的方式构建RDD,其对应分区数量如何确定的:
到底有多少个分区,一切以getNumPartitions结果为准
1-分区数据量,当调大local[num]中的num的值时候,不生效;调小的时候生效
2-可以在textFile算子中设置另外一个参数minPartitions,该参数用来设置RDD的最小分区数,因此最终的分区数量是>=minPartitions
3.处理小文件的操作
常规处理文件的办法:
1-大数据框架提供的现有的工具或者命令
? ? ? ? 1.1- hadoop fs -getmerge /input/small_files/*.txt /output/merged_file.txt
?? ?????1.2- hadoop archive -archiveName myhar.har -p /small_files /big_files2-可以通过编写自定义的代码,将小文件取进来,在代码中输出的时候,输出形成大的文件.
?
from pyspark import SparkConf, SparkContext
import os
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("读取小文件创建RDD")
# 1- 创建SparkContext对象
conf = SparkConf().setAppName('wholetextfile_rdd').setMaster('local[*]')
sc = SparkContext(conf=conf)
# 2- 数据输入
# 读取文件得到RDD
"""
[
[
('file:/export/data/gz16_pyspark/01_spark_core/data/content.txt', 'hello hello spark\r\nhello heima spark'),
('file:/export/data/gz16_pyspark/01_spark_core/data/content1.txt', 'hello hello spark\r\nhello heima spark'),
('file:/export/data/gz16_pyspark/01_spark_core/data/content2.txt', 'hello hello spark\r\nhello heima spark')
],
[
('file:/export/data/gz16_pyspark/01_spark_core/data/content3.txt', 'hello hello spark\r\nhello heima spark'),
('file:/export/data/gz16_pyspark/01_spark_core/data/content4.txt', 'hello hello spark\r\nhello heima spark')
]
]
"""
# init_rdd = sc.wholeTextFiles("file:///export/data/gz16_pyspark/01_spark_core/data")
init_rdd = sc.wholeTextFiles("file:///export/data/gz16_pyspark/01_spark_core/data",minPartitions=7)
# 3- 数据处理
# 4- 数据输出
# 获取分区数
print(init_rdd.getNumPartitions())
# 获取具体分区内容
print(init_rdd.glom().collect())
# 5- 释放资源
sc.stop()wholeTextFiles:读取小文件
1-支持本地文件系统和HDFS文件系统.参数minPartitions指定最小的分区数
2-通过该方式读取文件,会尽可能使用少的分区数,可能会将多个小文件的数据放到同一个分区中进行处理
3-一个文件要完整的存放在一个元组中,也就是不能将一个文件分成多个进行读取,文件是不可分割的.
4-RDD分区数量既受到minPartitions参数的影响,同时受到小文件个数的影响
4.RDD分区数量如何确定
?
1-RDD的分区数量,一般设置为机器CPU核数的2-3倍,为了充分利用服务器的硬件资源
2-RDD的分区数据量受到多个因素的影响.例如:机器CPU的核数,调用的算子,算子中参数的设置,集群的类型等.RDD具体有多少个分区,直接通过getNumPartitions查看
3-当初始化SparkContext对象的时候,其实就确定了一个参数spark.default.parallelism,默认为CPU的核数.如果是本地集群,就取决于local[num]中设置的数字大小,如果是集群,默认至少有2个分区
4-通过parallelize来构建RDD,如果没有指定分区数,默认就取spark.default.parallelism参数值;如果指定了分区数,也就是numSlices参数,那么numSlices的优先级会更高一些,最终RDD的分区数取该参数的值
5-通过textFile来构建RDD
5.1首先确认defaultMinPartition参数的值,该参数的值,如果没有指定textFile的minPartition参数,那么就根据公式min(spark.default.parallelism,2);如果有指定textFile的minPartition参数,那么就取设置的值.
5.2再根据读取文件所在的文件系统的不同,来决定最终RDD的分区数:
5.2.1-本地文件系统:RDD分区数 = max(本地文件分片数,defaultMinPartition)
5.2.2-HDFS文件系统:RDD分区数 = max(文件block块的数量,defaultMinPartition)
三.RDD的相关算子
1.RDD算子的分类
整个RDD算子,共分为两大类:
Transformation(转换算子):
返回值:是一个新的RDD
特点:转换算子只是定义数据的处理规则,并不会立即执行,是lazy(惰性)的,需要由Action算子触发.
Action(动作算子):
返回值:要么没有返回值None,或者返回非RDD类型的数据
特点:动作算子都是立即执行,执行的时候,会将它上游的其他算子一同触发执行
2.RDD的转换算子
2.1单值类型算子
map算子:map(fn)
作用:主要根据传入的函数,对数据进行一对一的转换操作,传入一行,返回一行
输入: init_rdd = sc.parallelize([0,1,2,3,4,5,6,7,8,9])
需求: 数字加一后返回
代码: init_rdd.map(lambda num:num+1).collect()
结果: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
?groupBy算子:groupBy(fn)
作用:根据用户传入的自定义函数,对数据进行分组操作
输入: init_rdd = sc.parallelize([0,1,2,3,4,5,6,7,8,9])
需求: 将数据分成奇数和偶数
代码: init_rdd.groupBy(lambda num:"偶数" if num%2==0 else "奇数").mapValues(list).collect()
结果: [('偶数', [0, 2, 4, 6, 8]), ('奇数', [1, 3, 5, 7, 9])]
总结: mapValues(list)将数据类型转成List列表
?filter算子:filter(fn)
说明:根据用户传入的自定义函数对数据进行过滤操作,自定义函数的返回值是bool类型,True表示满足过滤条件,会将数据保留下来;False会将数据丢弃掉.
输入: init_rdd = sc.parallelize([0,1,2,3,4,5,6,7,8,9])
需求: 过滤掉数值<=3的数据
代码: init_rdd.filter(lambda num:num>3).collect()
结果: [4, 5, 6, 7, 8, 9]
flatMap算子:flatMap(fn)?
说明:在map算子的基础上,加入一个压扁的操作,主要适用于一行中包含多个内容的操作,实现一转多的操作.
输入: init_rdd = sc.parallelize(['张三 李四 王五','赵六 周日'])
需求: 将姓名一个一个的输出
代码: init_rdd.flatMap(lambda line:line.split()).collect()
结果: ['张三', '李四', '王五', '赵六', '周日']
说明: split()默认会按照空白字符对内容进行切分处理。例如:空格、制表符、回车。还是推荐大家明确指定你所需要分割的符号。
https://www.runoob.com/python3/python3-tutorial.html
2.2 双值类型算子
union(并集)和intersection(交集)
格式:rdd1.union(rdd2)?
输入: rdd1 = sc.parallelize([3,3,2,6,8,0])
?? ? rdd2 = sc.parallelize([3,2,1,5,7])并集: rdd1.union(rdd2).collect()
结果: [3, 3, 2, 6, 8, 0, 3, 2, 1, 5, 7]
说明: union取并集不会对重复出现的数据去重对并集的结果进行去重: rdd1.union(rdd2).distinct().collect()
结果: [8, 0, 1, 5, 2, 6, 3, 7]
说明: distinct()是转换算子,用来对RDD中的元素进行去重处理交集: rdd1.intersection(rdd2).collect()
结果: [2, 3]
说明: 交集会对结果数据进行去重处理
2.3 key-value数据类型算子
groupByKey()
作用:对键值对类型的RDD中的元素按照键key进行分组操作,只会进行分组
?输入: rdd = sc.parallelize([('c01','张三'),('c02','李四'),('c02','王五'),('c01','赵六'),('c03','田七'),('c03','周八'),('c02','李九')])
需求: 对学生按照班级分组统计
代码: rdd.groupByKey().mapValues(list).collect()
结果: [('c01', ['张三', '赵六']), ('c02', ['李四', '王五', '李九']), ('c03', ['田七', '周八'])]
reduceByKey
作用:根据key进行分组,将一个组内的value数据放置到一个列表中,对这个列表基于fn进行聚合计算操作
?输入: rdd = sc.parallelize([('c01','张三'),('c02','李四'),('c02','王五'),('c01','赵六'),('c03','田七'),('c03','周八'),('c02','李九')])
需求: 统计每个班级学生人数
代码: rdd.map(lambda tup:(tup[0],1)).reduceByKey(lambda agg,curr:agg+curr).collect()
结果: [('c01', 2), ('c02', 3), ('c03', 2)]
sortByKey()
作用:根据key进行排序操作,默认按照key进行升序排序,如果需要降序,设置ascending参数的值为False
?
输入: rdd = sc.parallelize([(10,2),(15,3),(8,4),(7,4),(2,4),(12,4)])
需求: 根据key进行排序操作,演示升序
代码: rdd.sortByKey().collect()
结果: [(2, 4), (7, 4), (8, 4), (10, 2), (12, 4), (15, 3)]需求: 根据key进行排序操作,演示降序
代码: rdd.sortByKey(ascending=False).collect()
结果: [(15, 3), (12, 4), (10, 2), (8, 4), (7, 4), (2, 4)]
输入: rdd = sc.parallelize([('a01',2),('A01',3),('a011',2),('a03',2),('a021',2),('a04',2)])
需求: 根据key进行排序操作,演示升序
代码: rdd.sortByKey().collect()
结果: [('A01', 3), ('a01', 2), ('a011', 2), ('a021', 2), ('a03', 2), ('a04', 2)]
总结: 对字符串类型的key进行排序的时候,按照ASCII码表进行排序。大写字母排在小写字母的前面;如果前缀一样,短的排在前面,长的排在后面。https://tool.ip138.com/ascii_code/
3.RDD的动作算子
collect() 算子:
作用:收集各个分区的数据,将数据汇总到一个大的列表返回
reduce()算子:
作用:根据用户传入的自定义函数,对数据进行聚合操作,该算子是Action动作算子;而reduceByKey是Transformation转换算子
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
需求: 统计所有元素之和是多少
代码:?
def mysum(agg,curr):
?? ?print(f"中间临时聚合结果{agg},当前遍历到的元素{curr}")
?? ?return agg+currrdd.reduce(mysum)
rdd.reduce(lambda agg,curr:agg+curr)
结果:?
中间临时聚合结果6,当前遍历到的元素7
中间临时聚合结果13,当前遍历到的元素8
中间临时聚合结果21,当前遍历到的元素9
中间临时聚合结果30,当前遍历到的元素10
中间临时聚合结果1,当前遍历到的元素2
中间临时聚合结果3,当前遍历到的元素3
中间临时聚合结果6,当前遍历到的元素4
中间临时聚合结果10,当前遍历到的元素5
中间临时聚合结果15,当前遍历到的元素40
55说明: 初始化的时候,agg,表示中间临时聚合结果,默认取列表中的第一个元素值,curr表示当前遍历到的元素,默认取列表中的第二个元素的值。
?first()算子:
作用:取RDD中的第一个元素,不会对RDD中的数据排序
输入: rdd = sc.parallelize([3,1,2,4,5,6,7,8,9,10])
需求: 获取第一个元素
代码: rdd.first()
结果: 3
take()算子
说明:取RDD中的前N元素,不会对RDD中的数据排序
?输入: rdd = sc.parallelize([3,1,2,4,5,6,7,8,9,10])
需求: 获取前3个元素
代码: rdd.take(3)
结果: [3, 1, 2]
说明: 返回结果是List列表。必须要传递参数N,而且不能是负数。
top()算子:
作用:对数据集进行倒序排序操作,如果kv键值对类型,针对key进行排序,获取前N个元素.
?
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
需求: 获取前3个元素
代码: rdd.top(3)
结果: [10, 9, 8]
输入: rdd = sc.parallelize([('c01',5),('c02',8),('c04',1),('c03',4)])
需求: 按照班级人数降序排序,取前2个
代码: rdd.top(2,key=lambda tup:tup[1])
结果: [('c02', 8), ('c01', 5)]
需求: 按照班级人数升序排序,取前2个
代码: rdd.top(2,key=lambda tup:-tup[1])
结果: [('c04', 1), ('c03', 4)]
count()算子:
作用:统计RDD一共有多少个元素
?输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
需求: 获取一共有多少个元素
代码: rdd.count()
结果: 10
foreach()算子:
作用:遍历RDD的元素,对元素根据传入的函数进行自定义的处理
?输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10])
需求: 对数据进行遍历打印
代码: rdd.foreach(lambda num:print(num))
结果:?
6
7
8
9
10
1
2
3
4
5
说明:?
?? ?1- foreach()算子对自定义函数不要求有返回值,另外该算子也没有返回值
?? ?2- 因为底层是多线程运行的,因此输出结果分区间可能是乱序
?? ?3- 该算子,一般用来对结果数据保存到数据库或者文件中
4.RDD的重要算子
4.1基本算子
?
?4.2分区算子
分区算子:针对整个分区数据进行处理的算子
mapPartition和foreachPartition
作用:map和foreach算子都有对应的分区算子,分区算子适用于有反复消耗资源的操作,例如:文件的打开和关闭,数据库的连接和关闭等,能够减少操作的次数
4.3 重分区算子
重分区算子:对RDD的分区重新进行分区操作的算子,也就是改变RDD分区数的算子.
repartition算子
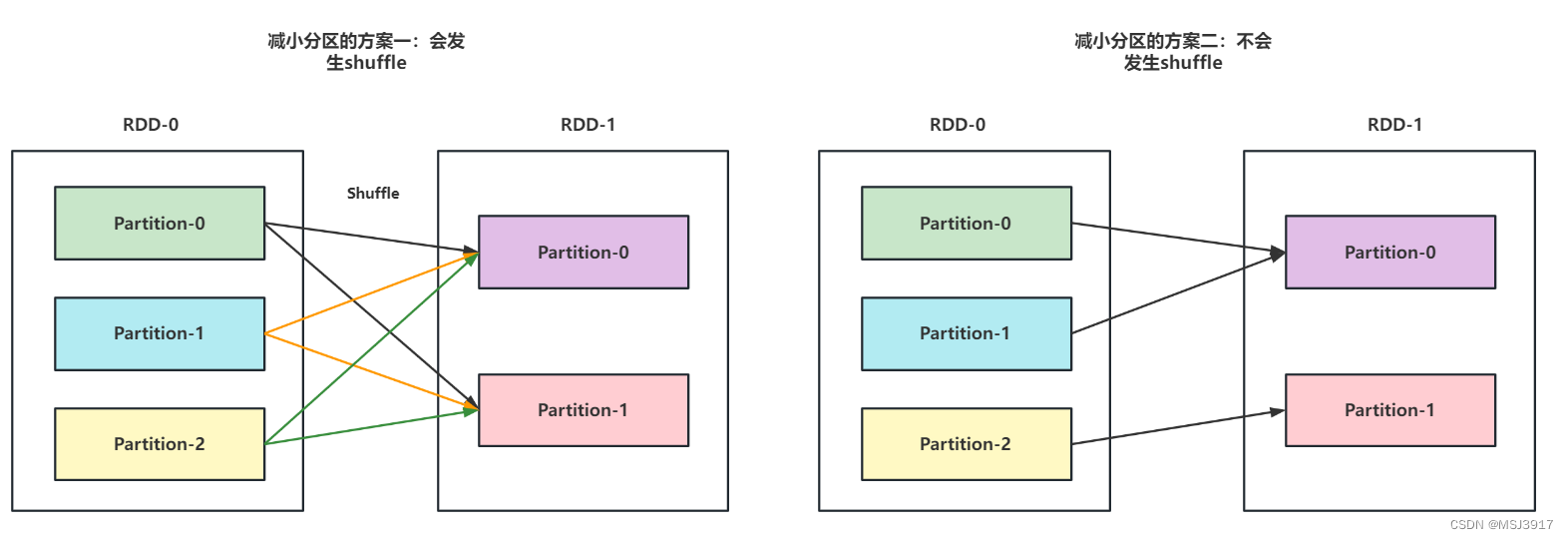
作用:改变RDD分区数,既能够增大RDD分区数,也能够减小RDD分区数,但是都会导致Shuffle过程.
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],3)
查看分区情况: rdd.glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]
增大分区: rdd.repartition(5).glom().collect()
结果: [[], [1, 2, 3], [7, 8, 9, 10], [4, 5, 6], []]
减少分区: rdd.repartition(2).glom().collect()
结果: [[1, 2, 3, 7, 8, 9, 10], [4, 5, 6]]
coalesce算子
格式:coalesce(num,shuffle=True|False)
作用:改变RDD分区数,但是,默认只能减小RDD分区数,不能增大,减小过程中不会发生Shuffle过程,如果想增大分区,需要将参数shuffle设置为True,但是会导致Shuffle过程.
?
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],3)
查看分区情况: rdd.glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]
减少分区: rdd.coalesce(2).glom().collect()
结果: [[1, 2, 3], [4, 5, 6, 7, 8, 9, 10]]? ??
增大分区: rdd.coalesce(5).glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]将参数2设置为True,再增大分区: rdd.coalesce(5,shuffle=True).glom().collect()
结果: [[], [1, 2, 3], [7, 8, 9, 10], [4, 5, 6], []]将参数2设置为True,再减小分区: rdd.coalesce(2,shuffle=True).glom().collect()
结果: [[1, 2, 3, 7, 8, 9, 10], [4, 5, 6]]
?
?
repartition 和 coalesce总结:
1- 这两个算子都是用来改变RDD的分区数
2- repartition 既能够增大RDD分区数,也能够减小RDD分区数。但是都会导致发生Shuffle过程。
3- coalesce默认只能减小RDD分区数,不能增大,减小过程中不会发生Shuffle过程。如果想增大分区,需要将参数shuffle设置为True,但是会导致Shuffle过程。
4- repartition 底层实际上是调用了coalesce算子,并且将shuffle参数设置为了True
partitionBy算子
作用:该算子主要是用来改变key-value键值对数据类型RDD的分区数的,num表示要设置的分区数,fn参数是可选,用来让用户自定义分区规则
注意:
默认情况下,根据key进行Hash取模分区。如果对默认分区规则不满意,可以传递参数fn来自定义分区规则。但是自定义分区规则函数需要满足两个条件,条件一:分区编号的数据类型需要是int类型;条件二:传递给自定义分区函数的参数是key
输入: rdd = sc.parallelize([(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(10,10)],5)
查看分区情况: rdd.glom().collect()
结果: [[(1, 1), (2, 2)], [(3, 3), (4, 4)], [(5, 5), (6, 6)], [(7, 7), (8, 8)], [(9, 9), (10, 10)]]
需求: 增大分区,尝试分为20个分区
代码: rdd.partitionBy(20).glom().collect()
结果: [[], [(1, 1)], [(2, 2)], [(3, 3)], [(4, 4)], [(5, 5)], [(6, 6)], [(7, 7)], [(8, 8)], [(9, 9)], [(10, 10)], [], [], [], [], [], [], [], [], []]需求: 减少分区,尝试分为2个分区
代码: rdd.partitionBy(2).glom().collect()
结果: [[(2, 2), (4, 4), (6, 6), (8, 8), (10, 10)], [(1, 1), (3, 3), (5, 5), (7, 7), (9, 9)]]
需求: 将 key>5 放置在一个分区,剩余放置到另一个分区
代码: rdd.partitionBy(2,partitionFunc=lambda key:0 if key>5 else 1).glom().collect()
结果: [[(6, 6), (7, 7), (8, 8), (9, 9), (10, 10)], [(1, 1), (2, 2), (3, 3), (4, 4), (5, 5)]]
注意: 分区编号的数据类型需要是int类型
4.4 聚合算子
单值类型的聚合算子
reduce(fn1):根据传入函数对数据进行聚合处理
fold(defaultAgg,fn1):根据传入函数对数据进行聚合处理,同时支持给agg设置初始值
aggregate(defaultAgg,fn1,fn2):?根据传入函数对数据进行聚合处理。defaultAgg设置agg的初始值,fn1对各个分区内的数据进行聚合计算,fn2 负责将各个分区的聚合结果进行汇总聚合
输入: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],3)
查看分区情况: rdd.glom().collect()
结果: [[1, 2, 3], [4, 5, 6], [7, 8, 9, 10]]
需求: 求和计算, 求所有数据之和================================reduce================================
代码:?
def my_sum(agg,curr):
?? ?return agg+curr
?? ?
rdd.reduce(my_sum)
结果: 55
================================fold================================
代码:?
def my_sum(agg,curr):
?? ?return agg+curr
?? ?
rdd.fold(5,my_sum)
结果: 75
================================aggregate================================
代码:?
def my_sum_1(agg,curr):
?? ?return agg+curr
?? ?
def my_sum_2(agg,curr):
?? ?return agg+curr
?? ?
rdd.aggregate(5,my_sum_1,my_sum_2)
结果: 75
?
总结:
reduce、fold、aggregate算子都能实现聚合操作。reduce的底层是fold,fold底层是aggregate。
在工作中,如果能够通过reduce实现的,就优先选择reduce;否则选择fold,实在不行就选择aggregate
KV类型的聚合函数:reduceByKey,foldByKey,aggregateByKey
以上三个与单值是一样的,只是在单值的基础上加了分组的操作而已,针对每个分组内的数据进行聚合而已,另外的groupByKey()仅分组,不聚合统计
问题:groupByKey()+聚合操作和reduceByKey()都可以完成分组聚合统计,谁的效率更高一些?
reduceByKey(),因为底层会进行局部的聚合操作,会减小后续处理的数据量.
reduceByKey:
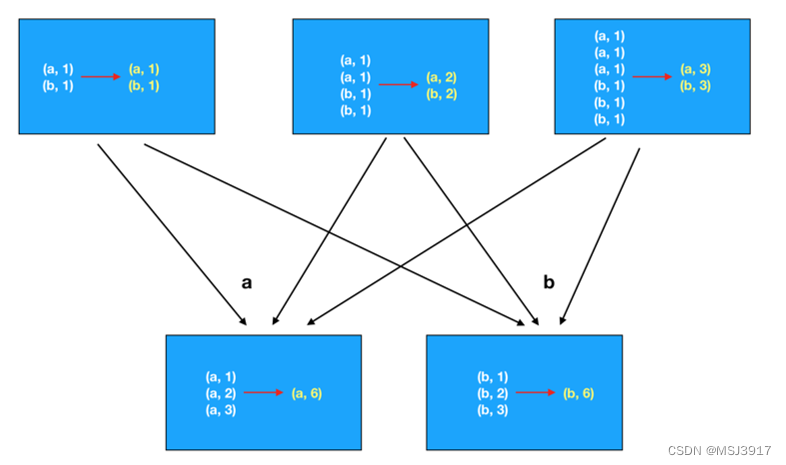
?groupByKey:

4.5关联算子
关联函数,主要是针对kv类型的数据,根据key进行关联操作
相关的算子:
join:实现两个RDD的join关联操作
leftOuterJoin:实现两个RDD的左关联操作
rightOuterJoin:实现两个RDD的右关联操作
fullOuterJoin:实现两个RDD的满外(全外)关联操作?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!