YOLOv2相比YOLOv1有哪些进步及改变?
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进。其中识别更多对象也就是扩展到能够检测9000种不同对象,称之为YOLO9000。 下面我们看下yoloV2的都做了哪些改进?
2.1 预测更准确(better)

2.1.1 batch normalization
批标准化有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果,从而能够获得更好的收敛速度和收敛效果。在yoloV2中卷积后全部加入Batch Normalization,网络会提升2%的mAP。
2.1.2 使用高分辨率图像微调分类模型
YOLO v1使用ImageNet的图像分类样本采用 224x224 作为输入,来训练CNN卷积层。然后在训练对象检测时,检测用的图像样本采用更高分辨率的 448x448 的图像作为输入。但这样切换对模型性能有一定影响。
YOLOV2在采用 224x224 图像进行分类模型预训练后,再采用 448x448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448x448 的分辨率。然后再使用 448x448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。

使用该技巧后网络的mAP提升了约4%。
2.1.3 采用Anchor Boxes
YOLO1并没有采用先验框,并且每个grid只预测两个bounding box,整个图像98个。YOLO2如果每个grid采用5个先验框,总共有13x13x5=845个先验框。通过引入anchor boxes,使得预测的box数量更多(13x13xn)。
2.2.4 聚类提取anchor尺度
Faster-rcnn选择的anchor比例都是手动指定的,但是不一定完全适合数据集。YOLO2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YOLO2的做法是对训练集中标注的边框进行聚类分析,以寻找尽可能匹配样本的边框尺寸。
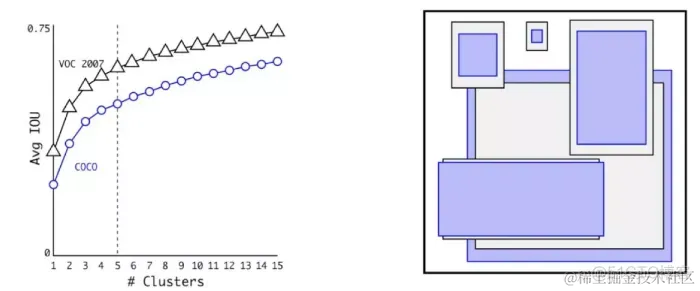
YoloV2选择了聚类的五种尺寸最为anchor box。
2.1.5 边框位置的预测
Yolov2中将边框的结果约束在特定的网格中:
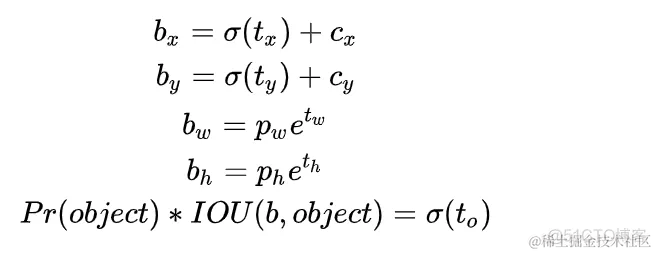
其中,
b_x,b_y,b_w,b_h是预测边框的中心和宽高。 Pr(object)?IOU(b,object)是预测边框的置信度,YOLO1是直接预测置信度的值,这里对预测参数t_o进行σ变换后作为置信度的值。 c_x,c_y是当前网格左上角到图像左上角的距离,要先将网格大小归一化,即令一个网格的宽=1,高=1。 p_w,p_h是先验框的宽和高。 σ是sigmoid函数。 t_x,t_y,t_w,t_h,t_o是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
如下图所示:
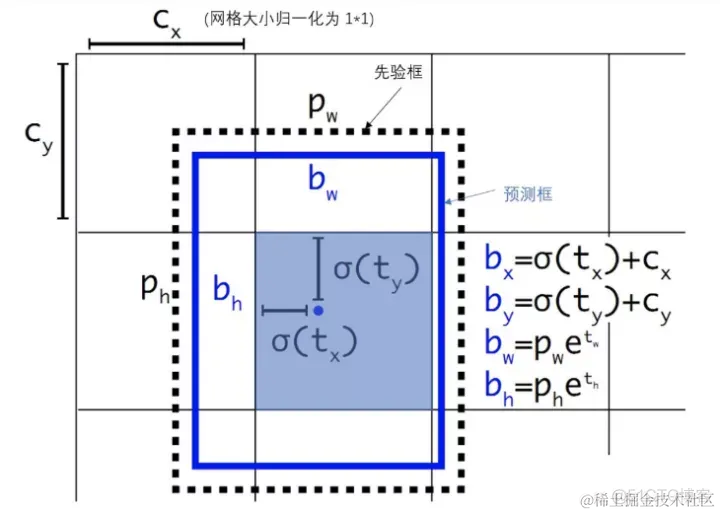
由于σ函数将 t_x,t_y约束在(0,1)范围内,预测边框的蓝色中心点被约束在蓝色背景的网格内。约束边框位置使得模型更容易学习,且预测更为稳定。
假设网络预测值为:
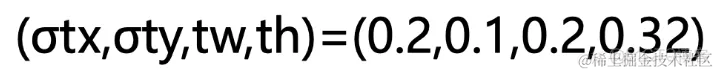
anchor框为:
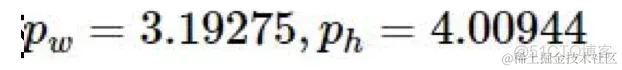
则目标在特征图中的位置:
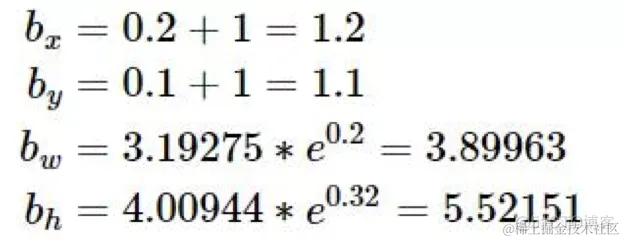
在原图像中的位置:
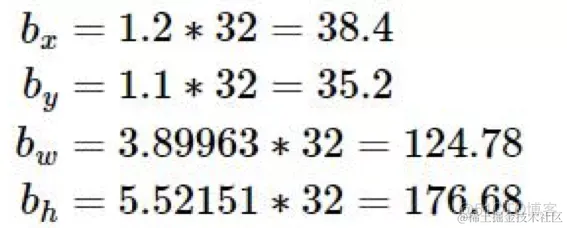
2.1.6 细粒度特征融合
图像中对象会有大有小,输入图像经过多层网络提取特征,最后输出的特征图中,较小的对象可能特征已经不明显甚至被忽略掉了。为了更好的检测出一些比较小的对象,最后输出的特征图需要保留一些更细节的信息。
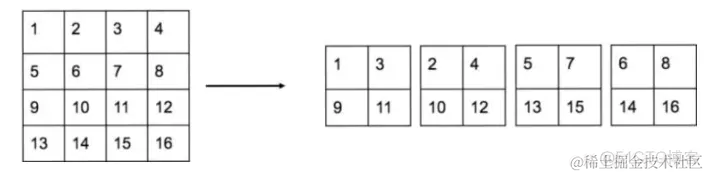
YOLO2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是26x26x512,将其1拆4,直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。
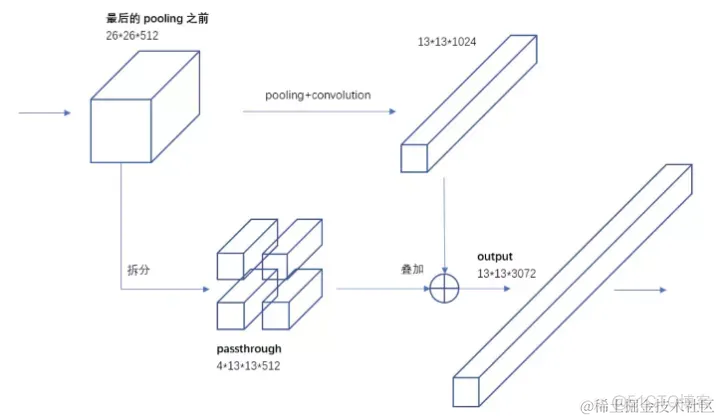
具体的拆分方法如下所示:
2.1.7 多尺度训练
YOLO2中没有全连接层,可以输入任何尺寸的图像。因为整个网络下采样倍数是32,采用了{320,352,…,608}等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是{10,11,…19}。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。

2.2 速度更快(Faster)
yoloV2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构作为特征提取网络。DarkNet-19比VGG-16小一些,精度不弱于VGG-16,但浮点运算量减少到约?,以保证更快的运算速度。
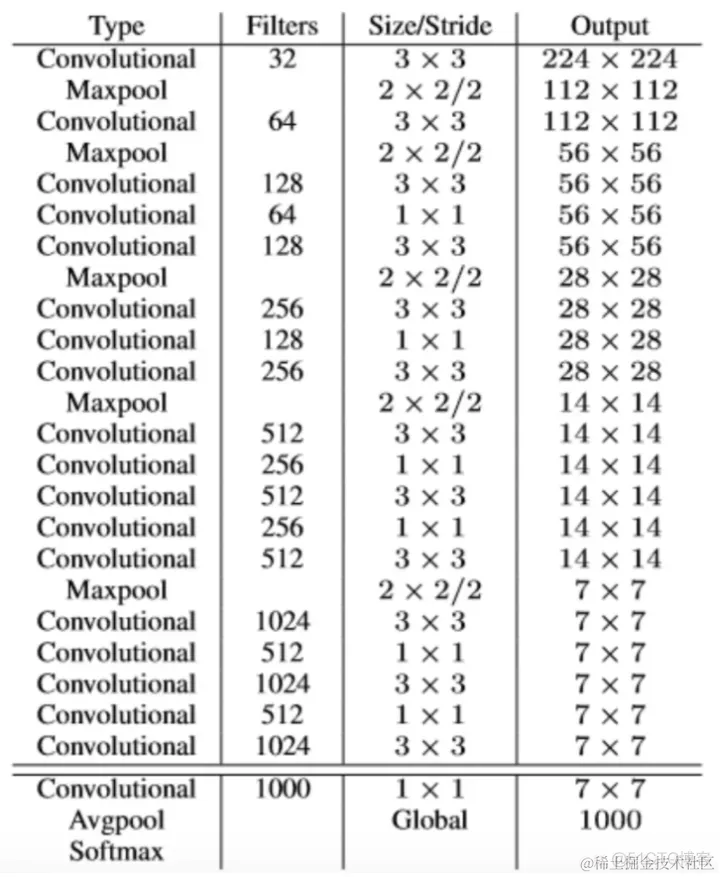
yoloV2的网络中只有卷积+pooling,从416x416x3 变换到 13x13x5x25。增加了batch normalization,增加了一个passthrough层,去掉了全连接层,以及采用了5个先验框,网络的输出如下图所示:

2.3 识别对象更多
VOC数据集可以检测20种对象,但实际上对象的种类非常多,只是缺少相应的用于对象检测的训练样本。YOLO2尝试利用ImageNet非常大量的分类样本,联合COCO的对象检测数据集一起训练,使得YOLO2即使没有学过很多对象的检测样本,也能检测出这些对象。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机组成原理核心内容整理
- gem5学习(8):创建一个简单的缓存对象--Creating a simple cache object
- Java根据二叉树的先序和后序得到二叉树
- linux MySQL数据库基本操作
- 论文阅读:PointCLIP V2: Prompting CLIP and GPT for Powerful3D Open-world Learning
- 25,verilog之generate生成块
- 【复现】金和OA协同管理平台 任意文件上传漏洞_20
- 移动零(双指针)
- 关于FormData添加数据后,打印数据为空的问题
- 【JS笔记】JavaScript语法 《基础+重点》 知识内容,快速上手(四)