【无标题】
在本博客中,我们将使用 UCF101 数据集深入探索动作识别的迷人世界。 动作识别是计算机视觉中的一项关键任务,其应用范围从监视到人机交互。 UCF101 数据集是我们进行此探索的游乐场。 我们的目标是建立一个结合卷积神经网络 (CNN) 和长短期记忆 (LSTM) 网络的动作识别模型,以取得令人印象深刻的结果。
NSDT工具推荐:?Three.js AI纹理开发包?-?YOLO合成数据生成器?-?GLTF/GLB在线编辑?-?3D模型格式在线转换?-?可编程3D场景编辑器?-?REVIT导出3D模型插件?-?3D模型语义搜索引擎?-?Three.js虚拟轴心开发包
1、了解 UCF101 数据集
UCF101 数据集是动作识别研究人员的金矿。 它由 101 个操作类别组成,适合广泛的应用。 每个动作都记录在不同的场景中,增加了数据集的复杂性。 在本节中,我们将深入研究数据集的细节,包括其大小、标签和视频格式。 我们还将讨论为什么 UCF101 数据集是动作识别实验的首选。

1.1 长短期记忆网络
长短期记忆 (LSTM) 网络已成为动作识别领域的关键组成部分,它们的采用已经改变了该领域。 引入这些专门的循环神经网络 (RNN) 是为了解决传统 RNN 在处理顺序数据时的局限性,使其成为对视频中固有的时间动态进行建模的理想选择。 在动作识别中,运动的背景和随时间的变化起着至关重要的作用。 与静态图像分类任务(CNN 通常就足够了)不同,识别动作需要深入了解视觉模式在视频序列中如何演变。
LSTM 凭借其独特的记忆单元,擅长捕获数据中的时间依赖性。 每个细胞都可以长时间存储信息,确保过去的观察对预测产生重大影响,甚至遥远的事件也可能影响识别过程。 这种时间建模能力与动作识别带来的挑战完美契合,其中动作的细微差别可能会逐渐演变,跨越多个帧。 例如,在区分“跑步”和“跳跃”时,腿部运动和身体姿势随时间的顺序至关重要,而 LSTM 擅长捕捉这些微妙之处。
此外,LSTM 在处理不同长度的序列方面提供了灵活性,这在动作识别数据集中很常见。 动作可以以不同的速度展开,LSTM 网络可以自然地适应这些动态。 这种适应性,加上它们处理远程依赖性的鲁棒性,导致它们在动作识别研究中得到广泛采用。 LSTM 层的输出可以封装整个视频序列的抽象表示,然后可用于进行准确的动作预测。 本质上,LSTM 充当模型的时间记忆,弥合了卷积神经网络 (CNN) 提取的空间特征与最终动作识别决策之间的差距。
LSTM 是动作识别机制中的重要齿轮,因为它们能够有效地对顺序数据进行建模。 它们将时间元素带入识别过程中,这使得它们对于时间动态很重要的任务来说是不可或缺的。 随着我们继续通过视频数据探索人类行为的细微差别,LSTM 很可能仍然是这个令人兴奋的领域的基石,帮助我们在监控、人机交互等应用中解锁新的可能性。
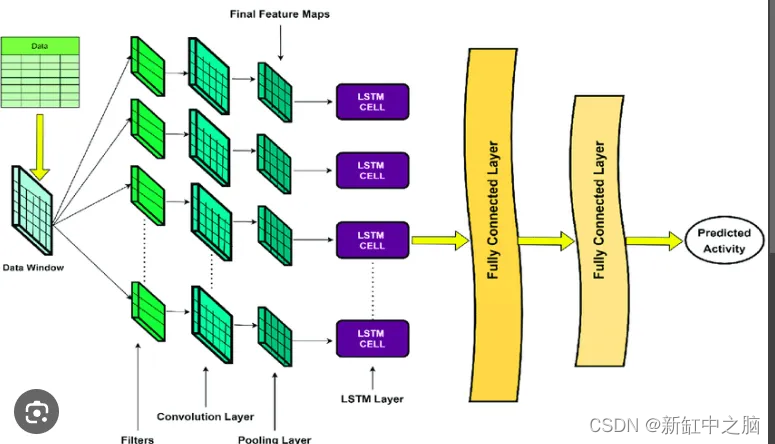
1.2 LSTM + CNN
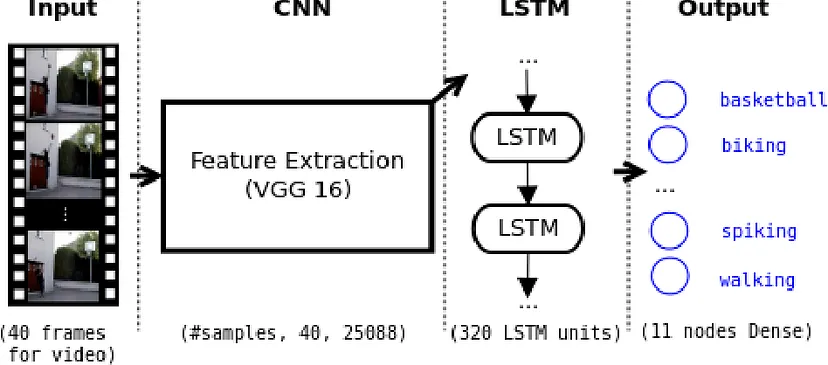
2、预处理和数据准备
在将 UCF101 数据集输入到我们的模型之前,我们需要对其进行适当的准备。 这涉及几个基本步骤。 我们将介绍数据预处理技术,例如调整大小、标准化和数据增强,以确保我们的模型有效学习。 我们还将演示如何将数据集分为训练集、验证集和测试集以进行稳健评估。
from google.colab import drive
drive.mount('/content/drive')
!pip install tensorflow
import os
import cv2
import math
import random
import numpy as np
import datetime as dt
import tensorflow as tf
from collections import deque
import matplotlib.pyplot as plt
from moviepy.editor import *
%matplotlib inline
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import *
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.utils import plot_model
!unrar x UCF50.rarimport random
plt.figure(figsize=(20, 20))
all_classes_names = os.listdir('UCF50')
for counter, selected_class_Name in enumerate(all_classes_names, 1):
video_files_names_list = os.listdir(f'UCF50/{selected_class_Name}')
# Check if there are video files in the folder
if video_files_names_list:
selected_video_file_name = random.choice(video_files_names_list)
video_reader = cv2.VideoCapture(f'UCF50/{selected_class_Name}/{selected_video_file_name}')
_, bgr_frame = video_reader.read()
video_reader.release()
rgb_frame = cv2.cvtColor(bgr_frame, cv2.COLOR_BGR2RGB)
cv2.putText(rgb_frame, selected_class_Name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
plt.subplot(5, 10, counter) # Adjust the number of rows and columns as needed
plt.imshow(rgb_frame)
plt.axis('off')
else:
print(f"No video files found in folder {selected_class_Name}")
plt.show()
IMAGE_HEIGHT,IMAGE_WIDTH = 64,64
SEQUENCE_LENGTH = 20
DATASET_DIR="UCF50"
CLASSES_LIST=["PlayingTabla","PommelHorse","JumpingJack","PushUps","PoleVault","HorseRace","HighJump","Drumming","HorseRiding","Diving","BreastStroke",
"Basketball","TrampolineJumping","YoYo","SalsaSpin","WalkingWithDog","VolleyballSpiking","ThrowDiscus","TennisSwing","TaiChi","Swing",
"SoccerJuggling","Skijet","Skiing","SkateBoarding","Rowing","RopeClimbing","RockClimbingIndoor","Punch","PullUps","PlayingViolin","PlayingPiano","PlayingGuitar",
"PizzaTossing","Nunchucks","Mixing","MilitaryParade","Lunges","Kayaking","JumpRope","JugglingBalls","JavelinThrow","HulaHoop","GolfSwing","Fencing",
"CleanAndJerk","Billiards","Biking","BenchPress","BaseballPitch"]3、用于特征提取的卷积神经网络 (CNN)
CNN 是我们动作识别模型的支柱。 在本节中,我们将探讨 CNN 在从视频帧中提取空间特征方面的作用。 我们将讨论流行的 CNN 架构,例如 VGG16 和 ResNet,它们可用作强大的特征提取器。 此外,我们将介绍为 UCF101 数据集量身定制的自定义 CNN 架构。 将提供用于构建和训练 CNN 模型的代码示例。
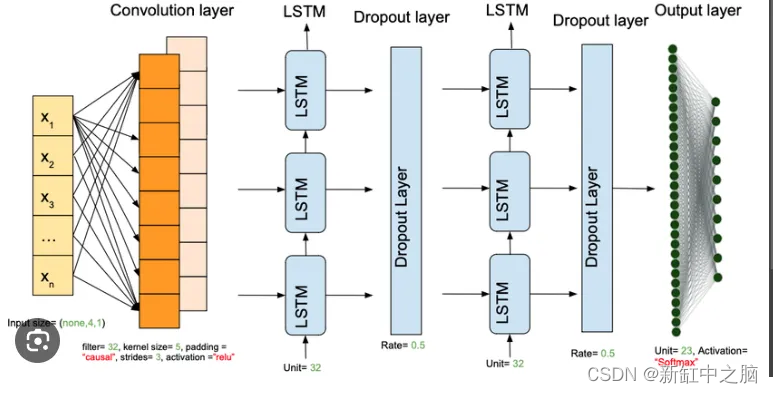
def frames_extraction(video_path):
frames_list=[]
video_reader = cv2.VideoCapture(video_path)
video_frames_count = int(video_reader.get(cv2.CAP_PROP_FRAME_COUNT))
skip_frames_window = max(int(video_frames_count/SEQUENCE_LENGTH),1)
for frame_counter in range(SEQUENCE_LENGTH):
video_reader.set(cv2.CAP_PROP_POS_FRAMES,frame_counter*skip_frames_window)
success,frame = video_reader.read()
if not success:
break
resized_frame = cv2.resize(frame,(IMAGE_HEIGHT,IMAGE_WIDTH))
normalized_frame = resized_frame / 255
frames_list.append(normalized_frame)
video_reader.release()
return frames_list
def create_dataset():
features = []
labels = []
video_files_paths = []
for class_index,class_name in enumerate(CLASSES_LIST[:40]):
print(f'Extracting Data of CLass: {class_name}')
files_list = os.listdir(os.path.join(DATASET_DIR,class_name))
for file_name in files_list:
video_file_path = os.path.join(DATASET_DIR,class_name,file_name)
frames = frames_extraction(video_file_path)
if len(frames) == SEQUENCE_LENGTH:
features.append(frames)
labels.append(class_index)
video_files_paths.append(video_file_path)
features = np.asarray(features)
labels = np.array(labels)
return features,labels,video_files_paths
features,labels,video_files_paths = create_dataset()
one_hot_encoded_labels = to_categorical(labels)seed_constant = 27
np.random.seed(seed_constant)
random.seed(seed_constant)
tf.random.set_seed(seed_constant)
features_train,features_test,labels_train,lables_test = train_test_split(features,one_hot_encoded_labels,
test_size = 0.25,shuffle = True,
random_state = seed_constant)
4、用于时间建模的长短期记忆 (LSTM) 网络
动作识别不仅仅涉及空间特征;还涉及空间特征。 它还与时间依赖性有关。 LSTM 网络可以帮助捕捉这些时间关系。 我们将深入研究 LSTM 背后的理论及其有效建模序列的独特能力。 你将深入了解我们为 UCF101 设计的基于 LSTM 的模型的架构。 我们将解决处理视频序列作为输入数据的挑战。
def create_LRCN_model():
model = Sequential()
#Model Architecture.
#---------------------------------------------------------------------------------------------------------------------------------------------------#
model.add(TimeDistributed(Conv2D(16, (3, 3), padding='same',activation = 'relu'),
input_shape = (SEQUENCE_LENGTH, IMAGE_HEIGHT, IMAGE_WIDTH, 3)))
model.add(TimeDistributed(MaxPooling2D((4, 4))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(32, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((4, 4))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(64, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((2, 2))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(64, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((2, 2))))
#model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Flatten()))
#K-LAYERED LSTM K=1
model.add(LSTM(32))
model.add(Dense(len(CLASSES_LIST[:10]), activation = 'softmax'))
#------------------------------------------------------------------------------------------------------------------------------------------------#
model.summary()
return model
LRCN_model = create_LRCN_model()
print("Model Created Successfully!")- 层数:TimeDistributed 层中卷积层和池化层数量的选择基于从视频帧中提取空间特征的通用架构模式,逐渐增加深度(滤波器数量),同时减少空间维度以捕获分层特征 。
- 激活函数:卷积层选择 ReLU(修正线性单元)激活函数,因为它们向模型引入了非线性,使其能够有效地学习数据中的复杂模式。
- Dropout:在每个 MaxPooling2D 层之后添加了 dropout 率为 0.25 的 Dropout 层,以通过在训练期间随机停用一部分神经元来防止过度拟合。
- LSTM 层:选择具有 32 个单元的单个 LSTM 层来有效捕获视频序列中的时间依赖性。
- 输出层激活:输出层使用softmax激活函数,将模型的logits转换为类概率,适用于多类分类任务。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
time_distributed (TimeDist (None, 20, 64, 64, 16) 448
ributed)
time_distributed_1 (TimeDi (None, 20, 16, 16, 16) 0
stributed)
time_distributed_2 (TimeDi (None, 20, 16, 16, 16) 0
stributed)
time_distributed_3 (TimeDi (None, 20, 16, 16, 32) 4640
stributed)
time_distributed_4 (TimeDi (None, 20, 4, 4, 32) 0
stributed)
time_distributed_5 (TimeDi (None, 20, 4, 4, 32) 0
stributed)
time_distributed_6 (TimeDi (None, 20, 4, 4, 64) 18496
stributed)
time_distributed_7 (TimeDi (None, 20, 2, 2, 64) 0
stributed)
time_distributed_8 (TimeDi (None, 20, 2, 2, 64) 0
stributed)
time_distributed_9 (TimeDi (None, 20, 2, 2, 64) 36928
stributed)
time_distributed_10 (TimeD (None, 20, 1, 1, 64) 0
istributed)
time_distributed_11 (TimeD (None, 20, 64) 0
istributed)
lstm (LSTM) (None, 32) 12416
dense (Dense) (None, 10) 330
=================================================================
Total params: 73258 (286.16 KB)
Trainable params: 73258 (286.16 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Model Created Successfully!def plot_metric(model_training_history,metric_name1,metric_name2,plot_name):
metric_value1 = model_training_history.history[metric_name1]
metric_value2 = model_training_history.history[metric_name2]
epochs = range(len(metric_value1))
plt.plot(epochs,metric_value1,'blue',label=metric_name1)
plt.plot(epochs,metric_value2,'red',label=metric_name2)
plt.title(str(plot_name))
plt.legend()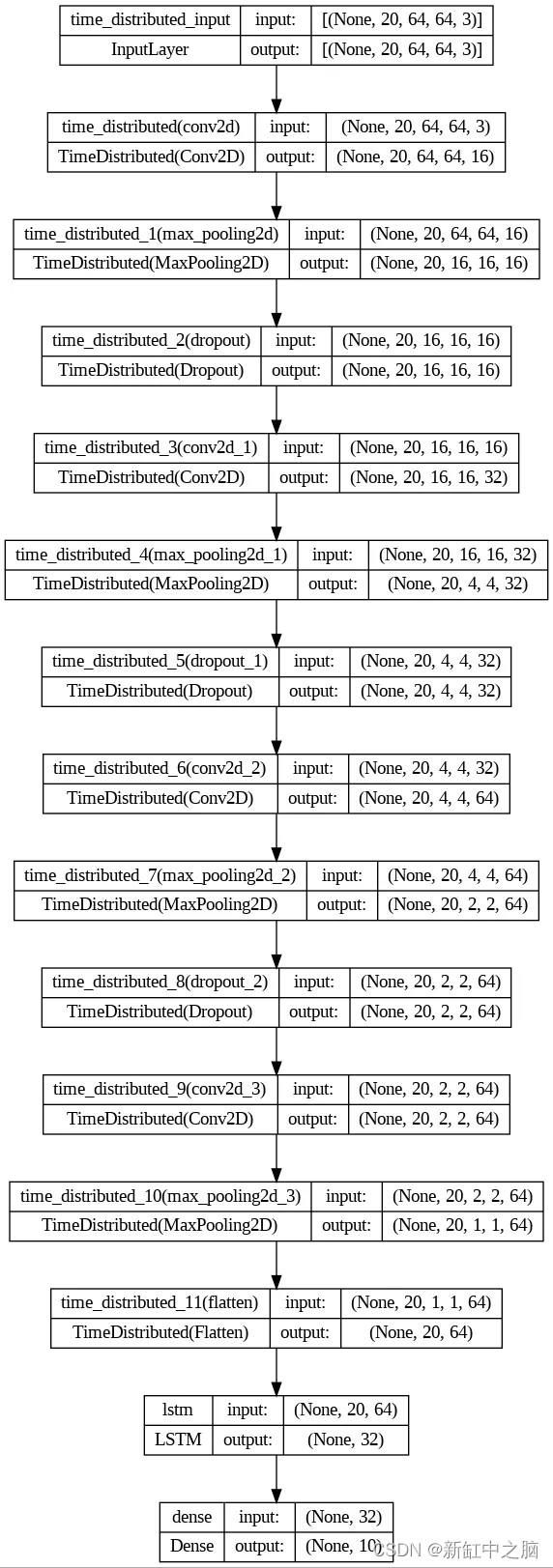 ?
?
Learning Rate: The choice of the learning rate (lr) was based on experimentation to find a value that allowed the model to converge effectively without causing divergence, and a value of 0.001 (default for Adam optimizer) was found to work well.
Optimizer: The Adam optimizer was chosen because it combines the benefits of both AdaGrad and RMSProp, providing effective optimization for training deep neural networks.
Epochs: The number of epochs (100) was selected based on early stopping to prevent overfitting while allowing the model to train until convergence.
Batch Size: A batch size of 4 was chosen to strike a balance between computation efficiency and model stability during training.
Loss Function: Categorical Crossentropy was chosen as the loss function because it is suitable for multi-class classification tasks and encourages the model to minimize the difference between predicted and actual class probabilities.import time
# before training
start_time = time.time()
early_stopping_callback = EarlyStopping(monitor='accuracy', patience=10, mode='max', restore_best_weights=True)
LRCN_model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=["accuracy"])
# Start training
LRCN_model_training_history = LRCN_model.fit(x=features_train, y=labels_train, epochs=100, batch_size=4,
shuffle=True, validation_split=0.2, callbacks=[early_stopping_callback])
# end time after training
end_time = time.time()
# total training time
total_training_time = end_time - start_time
print(f"Total training time: {total_training_time:.2f} seconds")
model_evaluation_history = LRCN_model.evaluate(features_test,lables_test)5、模型集成:CNN + LSTM
当我们将 CNN 和 LSTM 层结合起来形成我们的动作识别模型时,奇迹就发生了。 我们将探索 3D 卷积的概念,它无缝地融合了空间和时间特征。 我们将展示集成 CNN-LSTM 模型的架构,包括输入形状和层连接。 为了获得实践经验,我们将提供用于构建这个强大模型的代码示例。

6、训练与评估
训练我们的模型是关键的一步,它涉及选择适当的损失函数和优化器。 我们将解释超参数调整以实现最佳性能的重要性。 将详细讨论评估指标,例如准确性、混淆矩阵和 F1 分数。 准备好深入分析我们的模型在 UCF101 测试集上的结果。
import os
from moviepy.editor import VideoFileClip
test_videos_directory='test_videos'
os.makedirs(test_videos_directory,exist_ok=True)
input_video_file_path = '/content/drive/MyDrive/Cognitica/Test_dir/v_Diving_g25_c02.avi'
video_title = os.path.splitext(os.path.basename(input_video_file_path))[0]
print(f"Video Name: {video_title}")def predict_on_video(video_file_path, output_file_path, SEQUENCE_LENGTH):
video_reader = cv2.VideoCapture(video_file_path)
original_video_width = int(video_reader.get(cv2.CAP_PROP_FRAME_WIDTH))
original_video_height = int(video_reader.get(cv2.CAP_PROP_FRAME_HEIGHT))
video_writer = cv2.VideoWriter(output_file_path, cv2.VideoWriter_fourcc('M', 'P', '4', 'V'),
video_reader.get(cv2.CAP_PROP_FPS), (original_video_width, original_video_height))
frames_queue = deque(maxlen=SEQUENCE_LENGTH)
predicted_class_name = ''
while video_reader.isOpened():
ok, frame = video_reader.read()
if not ok:
break # Exit the loop when there are no more frames
# Check if the frame is empty before resizing
if not frame.size:
continue
resized_frame = cv2.resize(frame, (IMAGE_HEIGHT, IMAGE_WIDTH))
normalized_frame = resized_frame / 255
frames_queue.append(normalized_frame)
if len(frames_queue) == SEQUENCE_LENGTH:
predicted_labels_probabilities = LRCN_model.predict(np.expand_dims(frames_queue, axis=0))[0]
predicted_label = np.argmax(predicted_labels_probabilities)
predicted_class_name = CLASSES_LIST[predicted_label]
cv2.putText(frame, predicted_class_name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
video_writer.write(frame)
video_reader.release()
video_writer.release()%%capture
output_dir = "/content/drive/MyDrive/Cognitica/Output"
output_video_file_path = f'{output_dir}/{video_title}-Output-SeqLen{SEQUENCE_LENGTH}.mp4'
predict_on_video(input_video_file_path, output_video_file_path, SEQUENCE_LENGTH)
processed_video = VideoFileClip(output_video_file_path, audio=False, target_resolution=(300, None))
processed_video.ipython_display()分类报告:
%%capture
true_labels = [] # true labels for each frame
predicted_labels = [] # predicted labels for each frame
#predict labels for a video
def predict_on_video(video_file_path, true_label):
video_reader = cv2.VideoCapture(video_file_path)
frames_queue = deque(maxlen=SEQUENCE_LENGTH)
while video_reader.isOpened():
ok, frame = video_reader.read()
if not ok:
break
if not frame.size:
continue
resized_frame = cv2.resize(frame, (IMAGE_HEIGHT, IMAGE_WIDTH))
normalized_frame = resized_frame / 255
frames_queue.append(normalized_frame)
if len(frames_queue) == SEQUENCE_LENGTH:
predicted_labels_probabilities = LRCN_model.predict(np.expand_dims(frames_queue, axis=0))[0]
predicted_label = np.argmax(predicted_labels_probabilities)
predicted_class_name = CLASSES_LIST[predicted_label]
true_labels.append(true_label)
predicted_labels.append(predicted_class_name)
video_reader.release()
return true_labels, predicted_labels
#test vids
class_name_mapping = {
'v_Diving_g25_c02': 'Diving',
'v_Drumming_g25_c07': 'Drumming',
'v_HighJump_g25_c04': 'HighJump',
'v_HorseRace_g25_c04': 'HorseRace',
'v_HorseRiding_g25_c21': 'HorseRiding',
'v_JumpingJack_g25_c07': 'JumpingJack',
'v_PlayingTabla_g22_c04': 'PlayingTabla',
'v_PoleVault_g17_c09': 'PoleVault',
'v_PommelHorse_g05_c04': 'PommelHorse',
'v_PushUps_g26_c04': 'PushUps',
}
all_true_labels = []
all_predicted_labels = []
test_videos_directory = '/content/drive/MyDrive/Cognitica/Test_dir'
for video_file in os.listdir(test_videos_directory):
if video_file.endswith(".avi"):
video_file_path = os.path.join(test_videos_directory, video_file)
video_title = os.path.splitext(os.path.basename(video_file_path))[0]
# Map video_title
class_name = class_name_mapping.get(video_title, 'Unknown')
true_labels_video, predicted_labels_video = predict_on_video(video_file_path, true_label=class_name)
all_true_labels.extend(true_labels_video)
all_predicted_labels.extend(predicted_labels_video)
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=UndefinedMetricWarning)
report = classification_report(all_true_labels, all_predicted_labels)
print(report)
 ?
?
混淆矩阵:
confusion = confusion_matrix(all_true_labels, all_predicted_labels)
print("Confusion Matrix:")
print(confusion)
7、实际应用
LSTM+CNN(长短期记忆+卷积神经网络)架构由于能够捕获空间和时间特征,因此在各个领域都有应用。 以下是一些值得注意的应用:
- 视频中的动作识别:LSTM+CNN模型广泛用于识别视频序列中的人类动作。 他们可以使用 CNN 捕获空间细节,并使用 LSTM 对跨帧的时间依赖性进行建模,从而有效区分复杂的动作。
- 手势识别:手语或人机交互场景中的手势识别受益于LSTM+CNN架构。 他们可以解释手势的静态手部位置(空间特征)和随时间的动态变化(时间特征)。
- 视频监控:对监控录像中的活动进行检测和分类对于安全至关重要。 LSTM+CNN 模型擅长通过分析视频流中的空间和时间模式来识别可疑行为。
- 自动驾驶:自动驾驶汽车采用 LSTM 与 CNN 相结合来解释交通场景。 他们可以识别物体,预测它们的运动,并根据时间背景做出决策,从而为更安全的自动驾驶汽车做出贡献。
- 人体姿势估计:从图像或视频估计人体姿势通常需要捕获身体部位的空间关系及其时间演变。 LSTM+CNN 可以有效地处理这个任务。
- 语音识别:虽然不是直接视觉化的,但 LSTM+CNN 架构可用于自动语音识别系统。 它们处理音频频谱图(空间特征)并对语音信号的顺序性质(时间特征)进行建模。
- 医学图像分析:在医学成像中,识别异常情况或跟踪患者扫描随时间的变化至关重要。 LSTM+CNN 模型有助于有效分析 3D 或时间序列医学图像。
- 自然语言处理:LSTM+CNN 主要用于图像和视频,但也适用于处理自然语言处理任务中的时空数据。 它们可以处理词嵌入序列并捕获文本数据中的上下文。
- 金融时间序列预测:预测股票价格或金融市场趋势涉及分析具有时间依赖性的历史数据。 LSTM+CNN 模型可以捕获金融时间序列数据中的复杂模式。
- 手势控制设备:手势控制电视或智能家电等设备使用 LSTM+CNN 模型来解释手部动作和手势,从而实现直观的用户交互。
- 机器人技术:配备摄像头和传感器的机器人可以受益于 LSTM+CNN 架构,以导航复杂的环境、识别物体并根据视觉和时间线索做出决策。
- 情绪识别:从视频中的面部表情中理解人类情绪需要分析面部的空间细节和表情的时间演变,这使得 LSTM+CNN 在这种情况下很有价值。
这些应用展示了 LSTM+CNN 架构在处理涉及时空数据的各种任务方面的多功能性。 它们结合空间和时间信息的能力使它们成为上下文和时间至关重要的任务的有力选择。

8、结束语
当我们结束对 UCF101 数据集的动作识别的探索时,让我们总结一下关键要点。 我们见证了该数据集的重要性、CNN 和 LSTM 的强大功能以及它们组合的协同作用。 我们鼓励你踏上动作识别之旅,尝试 CNN-LSTM 模型,并利用 UCF101 数据集来突破人工智能的界限。如果你喜欢亲手实践,本文的代码可以从这里获取。
这些应用展示了 LSTM+CNN 架构在处理涉及时空数据的各种任务方面的多功能性。 它们结合空间和时间信息的能力使它们成为上下文和时间至关重要的任务的有力选择。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《低功耗方法学》翻译——第二章:标准低功耗方法
- matlab simulink风力发电机变桨距PI控制仿真
- 【Python学习】Python学习6-循环语句
- 【卡梅德生物】单B细胞技术:如何制备兔单抗?
- EMQX安装和Java订阅、发布mqtt消息
- Windows系统清理优化方法总结
- 谷歌手机安装证书到根目录
- 网络安全(黑客)—自学
- 关于“Python”的核心知识点整理大全53
- 【论文阅读】Augmented Transformer network for MRI brain tumor segmentation