python-爬取网易云音乐(歌名-歌手-链接)
发布时间:2024年01月11日
绕过请求头方法一、?
绕过请求头检查:
import requests
import re
from fake_useragent import UserAgent?
url='https://music.163.com/'
headers={
'user-agent':UserAgent().random
}?
print(headers)
req=requests.get(url=url,headers=headers)
code=req.status_code
print(code)
绕过请求头?方法二、
import requests
import re
import fake_useragent
ua=fake_useragent.UserAgent()
url='https://music.163.com/'
headers={
'user-agent':ua.random
}
print(headers)
req=requests.get(url=url,headers=headers)
code=req.status_code
print(code)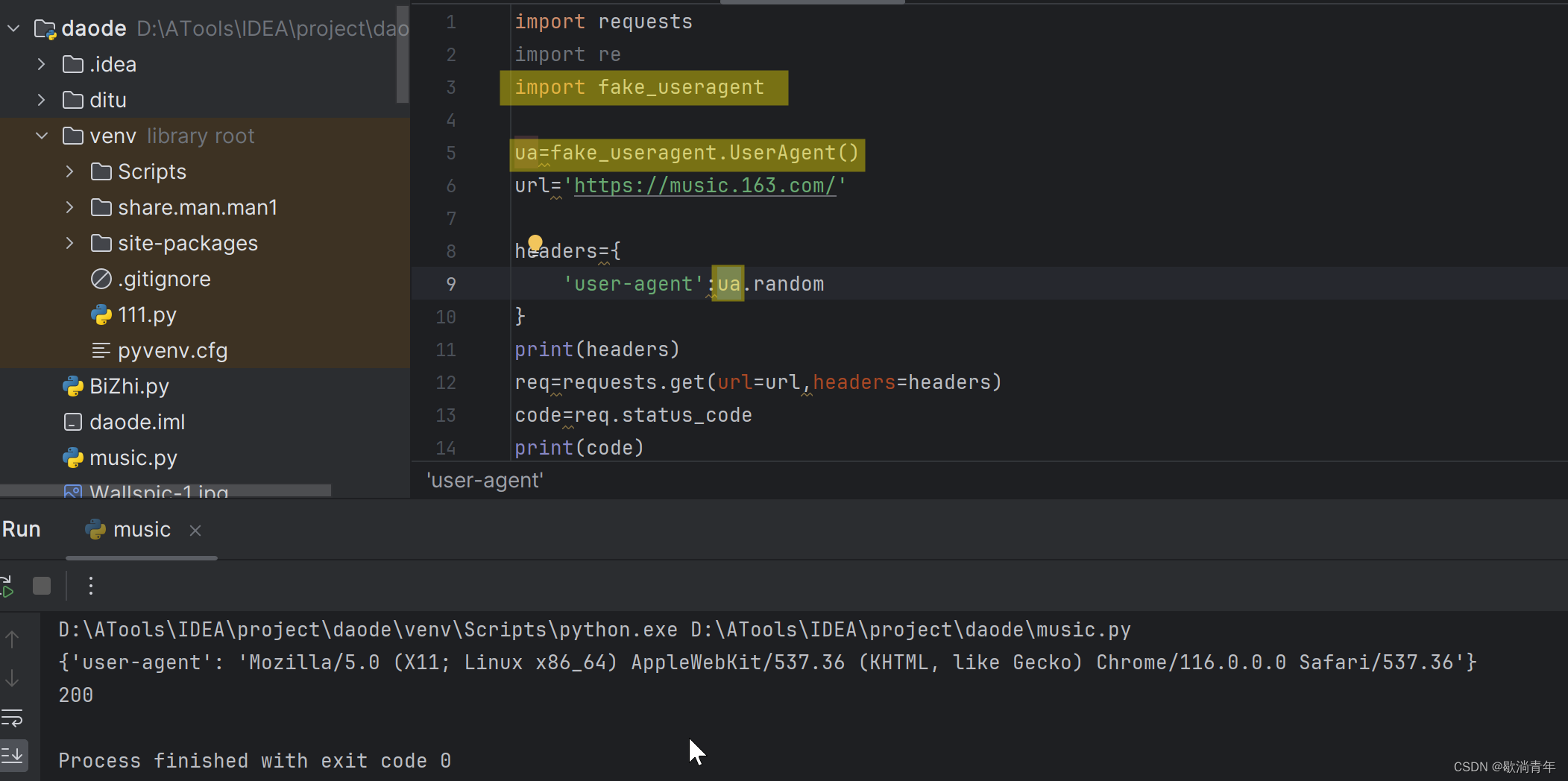
import requests
import fake_useragent
import re
"""
1.确定网址
2.搭建关系 发送请求 接受响应
3.筛选数据
4.保存本地
"""
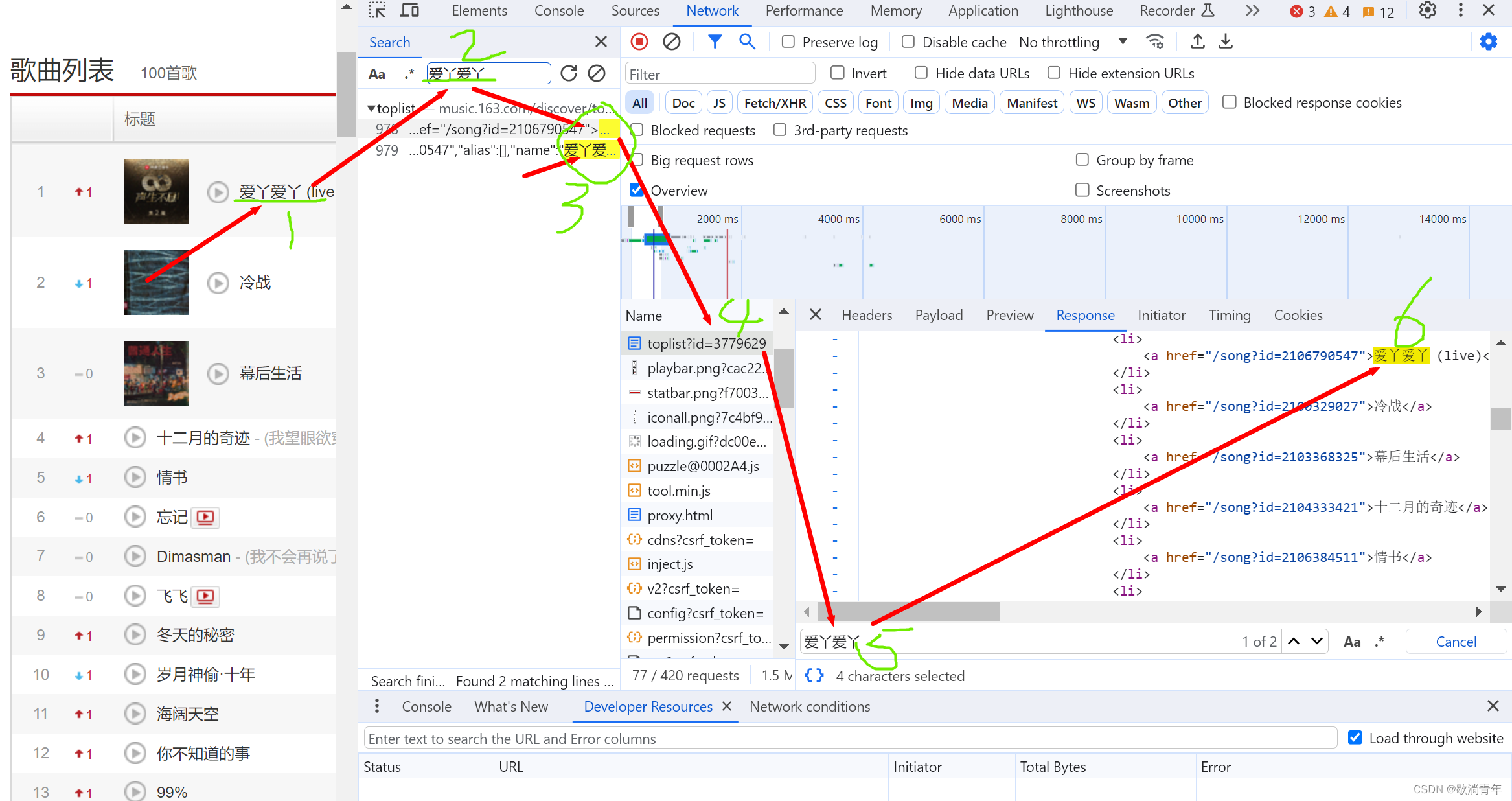
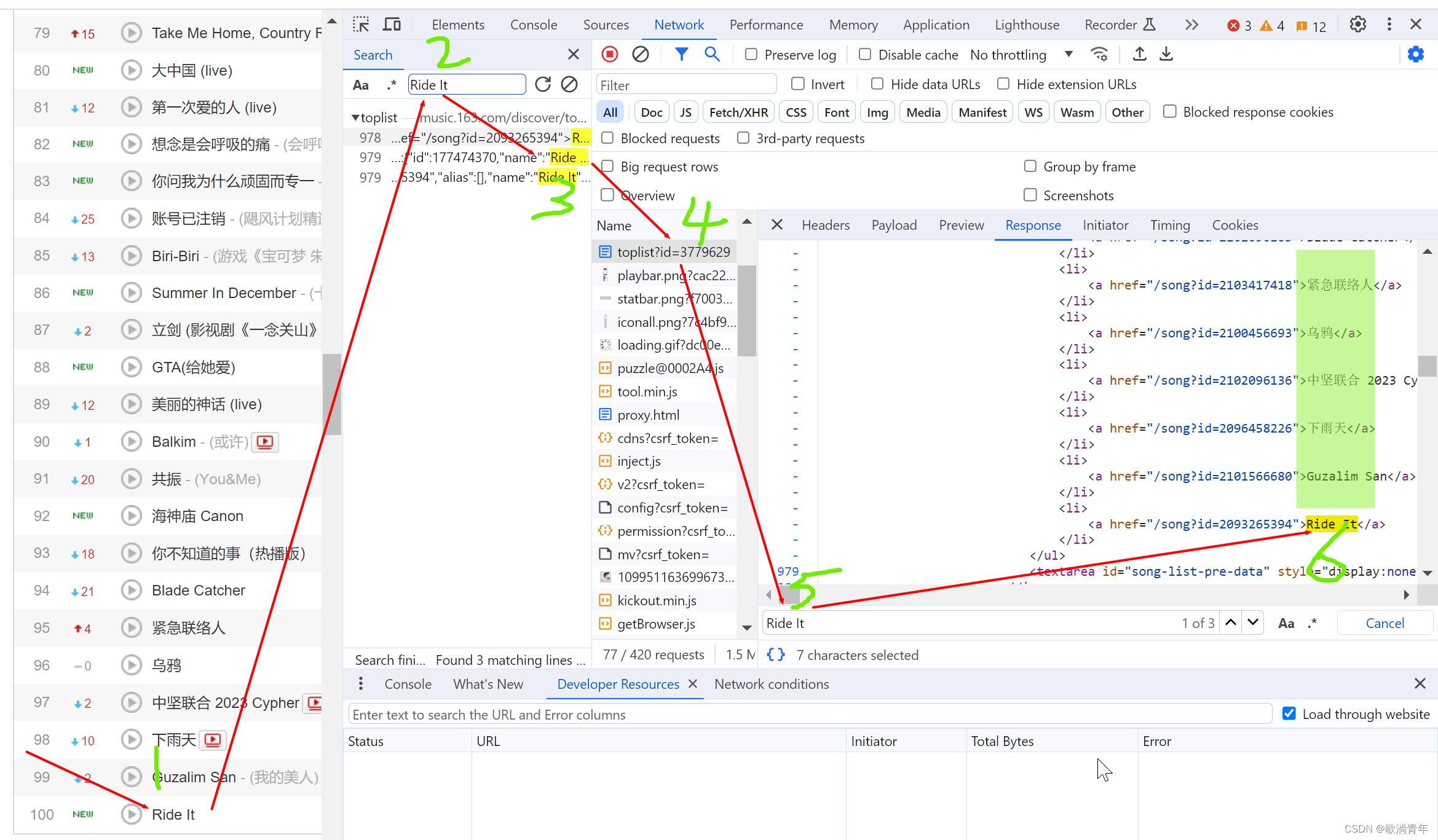
url = "https://music.163.com/discover/toplist?id=3778678"
ua = fake_useragent.UserAgent()
header = {
'user-agent': ua.random
}
response = requests.get(url=url, headers=header)
r = response.text
# print(r)
response.close()
# 包含歌曲和歌曲链接的一段字符串
all = ''.join(re.findall('<ul class="f-hide">(.*?)</ul>', r))
# 从 all 里提取歌名
name = re.findall('<a href=".*?">(.*?)</a>', all)
# 从 all 里提取歌曲地址
song_url = re.findall('<a href="(.*?)">.*?</a>', all)
# 从页面全部源代码中提取歌手的信息
singer = re.findall(r'"artists":\[{"id":.*?,"name":"(.*?)",', r)
# 打印
for i in range(len(name)):
print(name[i], '\t', singer[i], '\t','https://music.163.com/#/'+song_url[i])需要添加放到 excle中,放到docs中打印输出?
文章来源:https://blog.csdn.net/ssss39/article/details/134954896
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- springboot/java/php/node/python便利店系统【计算机毕设】
- 【leetcode100-036】【链表】二叉树中序遍历(四解)
- element-plus里el-date-picker日期选择器,默认值不显示的问题
- 配置环境变量
- mockjs使用(2)
- Linux中标准I/O的例题
- REVIT二次开发删除轴线
- 什么是边缘计算:最全指南
- NXP应用随记(五):eMios功能点阅读随记
- 欧拉操作系统(openEuler)简介