利用 OpenAI API 进行文本聚类和标记

每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
欢迎关注公众号

原文标题:Text Clustering and Labeling Utilizing OpenAI API
原文地址:https://medium.com/@kbdhunga/text-clustering-and-labeling-utilizing-openai-api-677271e0763c
Github:https://github.com/DhunganaKB/OpenAI-App/blob/main/Notebooks/clustering_labelling_amazon_reviews.ipynb
由于大型语言模型(LLM)的出现,对开放式文本进行聚类变得异常简单。LLM 在聚类方面的主要优势在于文本嵌入,其产生的高维向量能有效捕捉语义相似性,从而使其有别于传统方法。在各种自然语言处理(NLP)任务中,这些向量嵌入具有重要意义,可作为模型的关键输入,并对其结果产生重大影响。Prompt 工程与 LLMs 和 LangChain 框架相结合,进一步简化了这一过程,在完成聚类阶段后即可轻松实现聚类标记。
本文将引导您了解使用 OpenAI API 和 LangChain 框架完成聚类和标记所需的三个不同步骤。
- 利用 OpenAI 驱动的 LLM 进行文本嵌入
- 内嵌向量的聚类
- 通过 LLM 和 LangChain 框架进行集群标注
1. 数据集
我们从 Kaggle 获取了数据集。您可以从这个链接获取数据集,因为它是公开的。该数据集包含亚马逊上关于美食的评论。请看下面的示例数据片段。我们将主要关注 "Text"列,该列代表客户评论。

第一步是创建 OpenAI API 密钥,允许访问所有基于 OpenAI 的 LLM。如果您不熟悉如何生成 API 密钥,请查看此参考资料。许多文章都阐述了如何使用基于 OpenAI 的 LLM;如果你是新手,你可能会发现这篇文章很有帮助。生成 API 密钥后,必须将其安全地纳入我们的代码中。下面的代码片段提供了一种在我们的应用程序中嵌入 API 密钥的方法。在执行这段代码之前,请记住在运行代码的位置建立一个 .env 文件,并将 Open API 密钥定义为 OPENAI_API_KEY = ‘xxxxxxxxxxxxxxxxxx’。
import openai
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv(), override=True)
我们手头有大约 500,000 条评论,将这些评论全部纳入我们的分析中不仅耗时,而且由于 OpenAI 的付费 API 密钥相关的使用成本而产生费用。为了简化当前的分析,我们将只集中分析该数据集中的最初 2000 条评论。对于那些有兴趣将此分析扩展到更大数据集的人,本文概述的程序将保持一致。下面的代码节选旨在读取下载的 .csv 文件(确保提供相对或绝对文件路径),并选择前 2000 行进行详细分析。
import numpy as np
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import time
import os
from sklearn.cluster import KMeans
from tqdm.notebook import tqdm
from sklearn.metrics import silhouette_score
from langchain import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
openai.api_key=os.getenv('OPENAI_API_KEY')
df =pd.read_csv('Reviews.csv')
df=df[['Id', 'Score', 'Summary', 'Text']]
df = df.head(2000)
2. 文本嵌入
文本嵌入是对各种自然语言处理(NLP)任务至关重要的基本流程。它将文本(无论是单词、短语还是较长的句子)转化为一个紧凑的数字向量。该向量囊括了文本意义的精髓,可实现高效分析。OpenAI 通过不同的模型提供直接的文本嵌入,其中 "text-embedding-ada-002 "尤其受到青睐。需要注意的是,使用 OpenAI 模型进行嵌入需要一定的成本。为方便文本嵌入,我们提供了相应的代码片段;建议保存结果以备将来使用。
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
df['ada_embedding'] = df.Text.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
df=pd.read_csv('Reviews_with_embedding.csv')
所提供的示例展示了一个向量维度为 1536 的嵌入式列。

3. K-mean聚类
完成文本嵌入后,下一阶段将利用 K 均值聚类原理来确定数据集中的聚类数量。聚类的第一步是利用嵌入向量创建一个矩阵。然后,我们将重点转移到确定最合适的聚类数量上。这可以通过比较Silhouette Score来实现,Silhouette Score是一个评估聚类效果的指标。Silhouette Score的范围为-1 到 1:得分 1 表示聚类之间的距离较远且特征明显,0 表示聚类特征相似,-1 表示聚类分配不当。这一过程有助于确定聚类的最佳配置。
## Reading the previously saved file which contains emedded vector for each review:
df=pd.read_csv('Reviews_with_embedding.csv')
df['ada_embedding'] = df.ada_embedding.apply(eval).apply(np.array) # this will convert this column from string to np.array
matrix = np.vstack(df.ada_embedding.values)
## Running K-mean clustering and
def calculate_silhouette_scores(data_matrix, min_clusters=3, max_clusters=40):
cluster_results_km = pd.DataFrame(columns=['k', 'score'])
for k in tqdm(range(min_clusters, max_clusters + 1)):
km_model = KMeans(n_clusters=k, init='k-means++', random_state=42)
y = km_model.fit_predict(data_matrix)
silhouette = silhouette_score(data_matrix, y)
dic={'k': [k], 'score': [silhouette]}
cluster_results_km=pd.concat([cluster_results_km, pd.DataFrame(dic)])
return cluster_results_km
def find_optimal_cluster(cluster_results):
cluster_results = cluster_results.reset_index(drop=True)
optimal_cluster = cluster_results['score'].idxmax()
optimal_cluster = cluster_results['k'].iloc[optimal_cluster]
return optimal_cluster
matrix = matrix
cluster_results_km = calculate_silhouette_scores(matrix)
num_cluster = find_optimal_cluster(cluster_results_km)
print("Optimal number of clusters:", num_cluster)
print(cluster_results_km.loc[cluster_results_km['k'] == num_cluster])
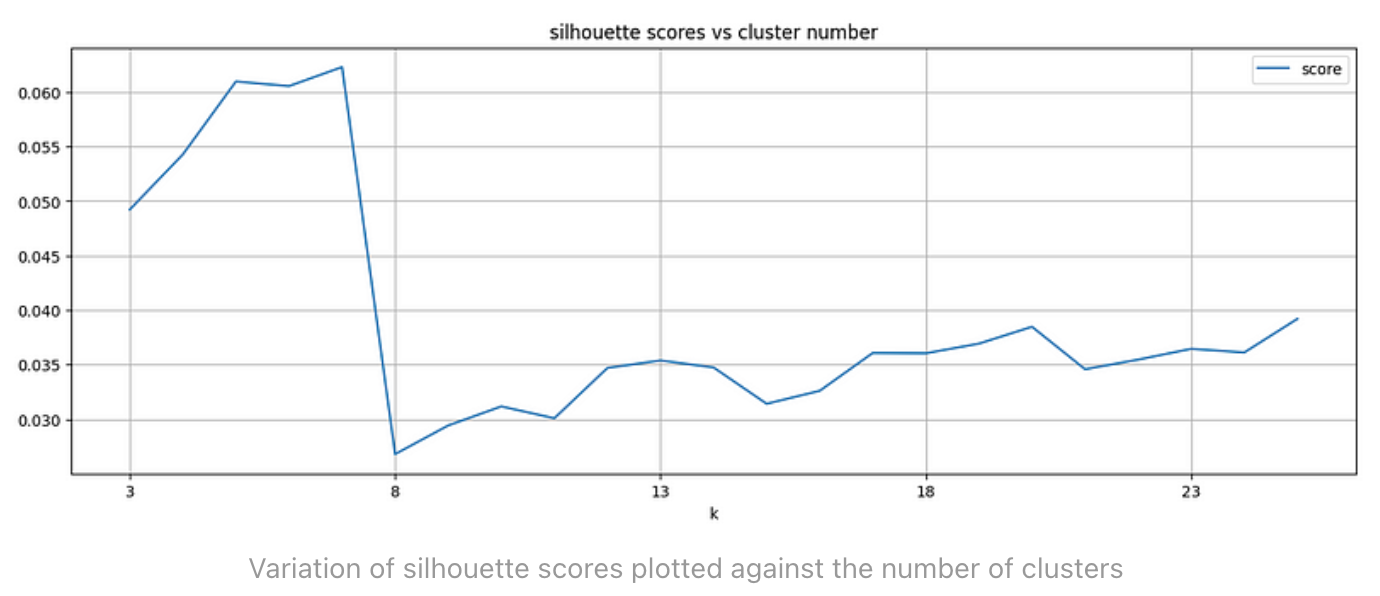
上图清楚地表明:在 k=7 时,Silhouette Score最高。因此,我们的数据集的理想聚类数是 7。不过,这个最佳聚类数的Silhouette Score幅度并不大,这表明有些聚类具有相似性。最后,我们将以 k=7 重新执行 k-means 聚类,获取聚类标签,并将这些值归入数据中。
# final k-mean clustering
km_model = KMeans(n_clusters = num_cluster, init ='k-means++', random_state = 42)
y = km_model.fit_predict(matrix)
df['Cluster']=y
4. 使用 t-SNE 进行嵌入和可视化
t-SNE 是一种非线性降维方法,广泛应用于低维空间中嵌入向量的可视化。许多媒体文章都对这种方法进行了深入探讨。我建议参考这篇文章,以了解简要概况。随后的代码片段可以在二维空间中实现内嵌向量的可视化,并配有聚类中心点。
plt.rcParams['figure.figsize'] = (15, 8)
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims2 = tsne.fit_transform(matrix)
x = [x for x,y in vis_dims2]
y = [y for x,y in vis_dims2]
#palette = sns.color_palette("inferno", num_cluster).as_hex()
palette = sns.color_palette("husl", num_cluster).as_hex()
for category, color in enumerate(palette):
xs = np.array(x)[df.Cluster==category]
ys = np.array(y)[df.Cluster==category]
plt.scatter(xs, ys, color=color, alpha=0.3, s=50)
avg_x = xs.mean()
avg_y = ys.mean()
plt.scatter(avg_x, avg_y, marker='*', color='black', s=300)
plt.title("Reduced Dimension: Embeddings visualized using t-SNE", size=17, fontweight="bold")
plt.xlabel('Axis 1',size=13, fontweight="bold")
plt.ylabel('Axis 2',size=13, fontweight="bold")

5. 聚类标签
根据我们目前的了解,我们的数据集中存在七个不同的聚类。我们接下来的任务是理解每个集群的独特特征,并为它们分配适当的标签(类别)。为了促进这一过程,我们计划利用 LLM 和 LangChain 框架的功能。
为了确定合适的群组标题(或类别),我们将汇总每个群组内的评论,并请 LLM 协助确定合适的标题。值得注意的是,LLM 模型的标记处理能力是有限的。因此,如果评论相对较短,且每个群组的评论量仍在可控范围内,我们就可以直接向模型提供评论。不过,我们必须承认,这种情况与现实世界中经常遇到的复杂情况有很大不同。
因此,我们最初的方法是通过摘要浓缩每篇评论,确保保留内容的精髓,同时使其更加简洁。随后的代码片段将系统地逐行总结每篇评论,从而在实现这一目标的过程中发挥关键作用。
def call_openai_api(messages):
return openai.ChatCompletion.create(
model='gpt-3.5-turbo-16k',
messages=messages,
max_tokens=4096,
temperature=1
)
def summarize_text(transcript):
system_prompt = "I would like for you to assume the role of a Life Coach"
user_prompt = f"""Generate ten words summary of the text below.
Text: {transcript}
"""
messages = [
{'role': 'system', 'content': system_prompt},
{'role': 'user', 'content': user_prompt}
]
response = call_openai_api(messages)
summary = response['choices'][0]['message']['content']
return summary
摘要的有效性在很大程度上取决于我们如何撰写提示语。在这种情况下,我的目标是用简洁的摘要抓住评论的主要内容。在执行这些功能时,必须注意所使用模型的速度限制。每个模型都有在一分钟内处理令牌的特定阈值。如下所示,超过此标记限制将持续导致错误。
# RateLimitError: Rate limit reached for default-gpt-3.5-turbo-16k in organization org-7d1yAjMgmG3lnmgY87cMEAVy on tokens per min. Limit: 180000 / min. Current: 177927 / min. Contact us through our help center at help.openai.com if you continue to have issues.
为了防止出现此类错误,我在 for 循环中执行了上述函数。我们的数据集仅包含 2000 行,这是直接嵌入到脚本中的值。如果您的数据集超过 2000 行,请记得相应修改以下代码。
import time
df1=pd.DataFrame()
for i in range(20): # since we have only 2000 rows in our data set
init = i*100
final = (i+1)*100
dk = df.iloc[init:final]
print(i, init, final)
dk['summary_openai'] = dk['Text'].map(lambda x: summarize_text(x))
df1 = pd.concat([df1, dk])
time.sleep(60)
接下来,我们将创建一个函数,旨在帮助我们识别每个集群的主题。为此,我将结合 ChatOpenAI 模型使用 LangChain 框架。鉴于这项任务需要大量的标记,我选择了 "gpt-3.5-turbo-16k "模型。
def get_prompt():
system_template = "You are a market analyst and know all reviews from Amazon. You're helping me write a concise topic from many reviews."
human_template = "Using the following reviews, write a topic title that summarizes them.\n\nREVIEWS:{reviews}\n\nTOPIC TITLE:"
return ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(system_template),
HumanMessagePromptTemplate.from_template(human_template),
],
input_variables=["reviews"],
)
for c in df1.Cluster.unique():
chain = LLMChain(
llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-16k"), prompt=get_prompt(), verbose=False
)
review_str = "\n".join(
[
f"{review['summary_openai']}\n"
for review in df1.query(f"Cluster == {c}").to_dict(orient="records")
]
)
result = chain.run(
{
"reviews": review_str,
}
)
df1.loc[df1.Cluster == c, "review_topic"] = result
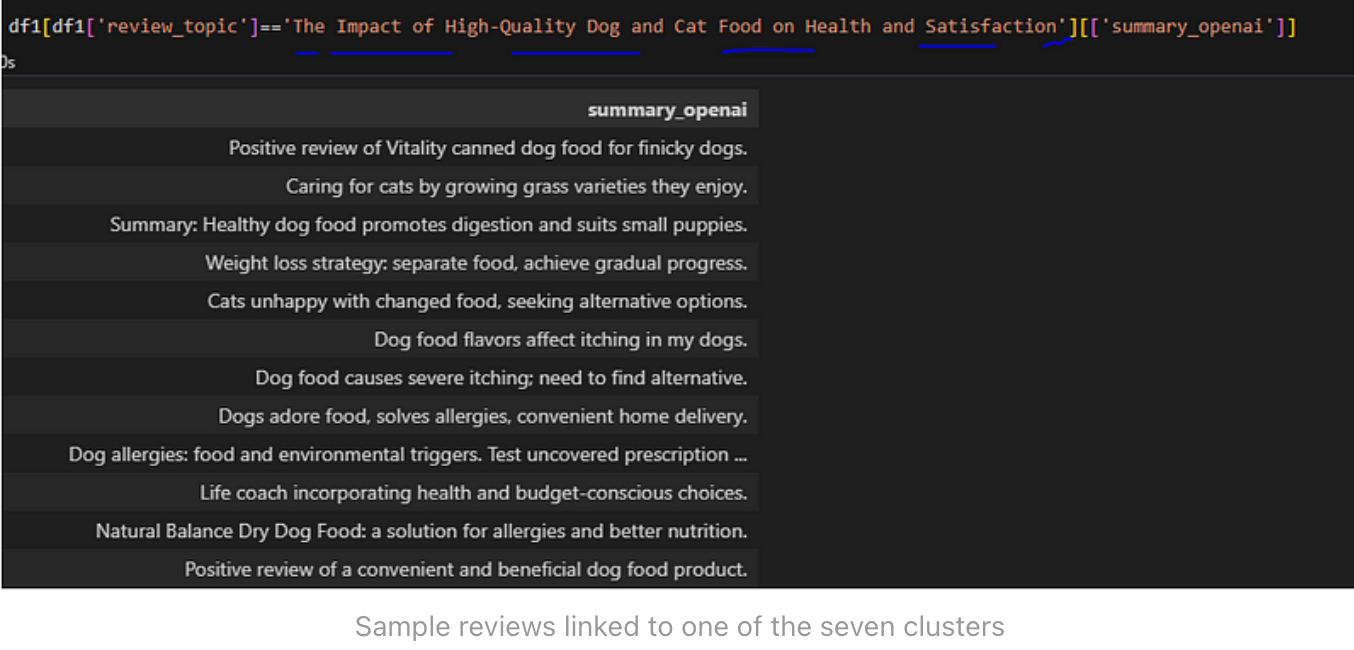
这是最终完成的数据帧的外观:

这里共有七个群组,每个群组对应一个不同的主题。以下是当前的主题表示法:

我选择了 "The Impact of High-Quality Dog and Cat Food on Health and Satisfaction"作为例子,来研究与特定群组相关的评论。很明显,这个群组中的大多数评论都关注与猫狗食品有关的问题,尤其是它们对健康和幸福的影响。因此,法律硕士建议的主题似乎是合乎逻辑的,也是非常吻合的。
K 均值聚类可能并不总是聚类的最佳选择。我们建议探索更适合我们数据集的各种聚类技术。基于密度的聚类方法经常会产生更有利的聚类结果。对于有兴趣尝试 HDBSCAN 方法的人,我建议参考这篇文章以获得指导。在为数据集尝试各种聚类方法时,重要的是要注意,无论采用哪种方法,初始步骤(嵌入)和最终步骤(聚类标记)都将保持一致。
6. 总结
这里再仔细总结一下这篇文章:
- 文本嵌入
openai的text-embedding-ada-002模型
- K-mean聚类
sklern.cluster.KMeans
Silhouette Score指标
- t-SNE可视化
sklearn.manifold.TSNE
- 聚类主题标签
openai结合langchain
评论总结Prompt:
system_prompt = "I would like for you to assume the role of a Life Coach"
user_prompt = f"""Generate ten words summary of the text below. Text: {transcript} """
主题总结Prompt:
system_template = "You are a market analyst and know all reviews from Amazon. You're helping me write a concise topic from many reviews."
human_template = "Using the following reviews, write a topic title that summarizes them.\n\nREVIEWS:{reviews}\n\nTOPIC TITLE:"
- 查看主题是否可行
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 微积分-第二章三角函数(合集)
- 计算机毕业设计----SSH在线水果商城平台含管理系统
- 汉诺塔问题
- 王道短期班c++ day05
- 食品饮料加工厂需要哪些污水处理设备和工艺
- HLS + ffmpeg 实现动态码流视频服务
- 政府、医疗数据安全「专精」厂商,美创再登《2023中国网络安全产业势能榜》
- 2024.1.2 Redis 数据类型 Stream、Geospatial、HyperLogLog、Bitmaps、Bitfields 简介
- 【Linux】理解文件系统
- 【C/C++】开源串口库 CSerialPort 应用