基于yolov5的PCB板缺陷检测(附有详细步骤通俗易懂版)
PCB板缺陷检测
模型训练
在初学的时候,可能不太了解到底模型训练是个什么流程,到底是什么意思。其实也很简单,就是我们用一个框架(如pytorch,tensorflow等)通过一定的算法如yolov5,对一定的数据集进行训练后等形成一个可以直接调用模型(例如用pytorch训练的模型通常是.pt或.pth文件,当然也有一些其他的,这就是看具体的需要了),通过一定的方法调用模型后(通常是简单的.load()语句),直接输入数据就可以按照一定的格式输出训练后的数据。
选择数据集
PCB缺陷检测我查到的有两种数据集,一种是deepPCB,另一种是北京大学智能机器人开放实验室数据,因为北京大学的数据已经处理好了,不用我们再处理了,所以我们在本次实验采用的是北京大学的数据,数据内容如下:

我们可以打开Annotations文件夹,然后再随便打开一个缺陷类型的文件,我们发现都是一些xml的文件,如下图所示:
这就是已经标注好的文件,用xml文件的形式保存,这个文件是在软件上手动标注后导出的文件,我们需要通过一定的处理,将标注信息提取出来。而这一步北京大学的数据集也替我们做了,连处理都不用了,我们可以看一下labels文件夹,内容如下:

这一个一个的txt文件就是我们训练需要的标签文件,我们可以随便打开一个,内容如下:

一共是三行五列数据,开头的0表示缺陷的类型(这里的0~5表示5种缺陷类型),后面的四列表示的是图像的一些其他的信息。三行表示这张图片总共有三个缺陷的地方。
划分训练集
上一步中,我们已经有了初步的数据集,下一步我们要将数据集处理成yolo可以处理的形式,什么意思呢,就是只要我们将yolo模型中的数据集位置改成自己的,就可以直接训练。yolo的数据集如下图所示:

先建立一个主文件夹datasets

然后在里面建立两个文件夹,一个labels,一个images

images里面建立两个文件夹 train和val

labels里面也建立两个文件夹train,val
然后,两个文件夹里的train和val放置对应的文件就行,images里面放图片,labels里面放txt文件,其他就不用管了,因为这个数据集的iamge和txt的文件名称已经对应起来了。另外要注意的是images和labels里面的文件要对应起来,一定是images的train里面放什么图片,labels的train里面就放什么txt文件,val也是如此。train和val的比例这个可以根据需求设置,我这里是设置的8:2。这样数据集就算完成了。
环境配置
首先需要下载yolo模型:yolo下载
下载并解压完成后,我们需要配置文件,打开yolo的那个文件,找到一个requirements文件,如下图:

这个里面就是运行yolo所需要的配置,我们在我们的python的那个终端界面中或者是anaconda的终端窗口中找到自己准备运行的环境,运行下面的语句:
pip install -r requirements.txt
这样我们就下载了所有的依赖包
模型训练
我们需要改变这个模型的几个地方
在/yolov5-master/data下面新建一个pcb.yaml,如下图:
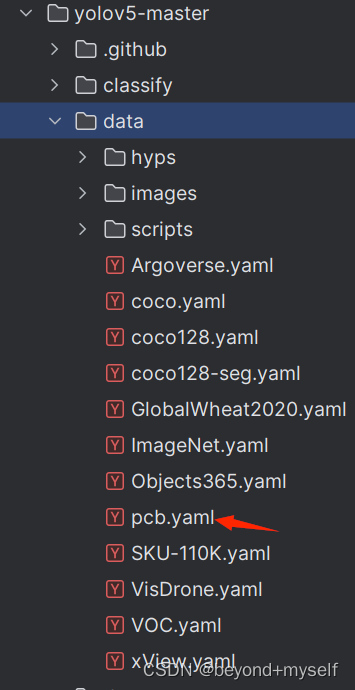
内容如下:
# PCB data
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: D:/AI_PCB_test/datasets #改为自己的数据集的位置
train: images/train # train是txt文件
val: images/val # labels是目录文件
nc: 6 # number of classes
names: ['missing_hole', 'mouse_bite', 'open_circuit', 'short', 'spur', 'spurious_copper']
我们可以从上面看到,这里的train和val都是images的,但是,训练的代码的内部应该是会调用到labels里面的,所以,我们还是要严格的按照上面数据集划分那样来分。
再一个就是修改/yolov5-master/models/yolov5s.yaml(这里取决于自己,我们在这里选择的是small的模型)中修改一个内容,如下:
将这个nc改为6,表示有6种分类
最后就是对train.py的修改
首先找到下面的一个函数:
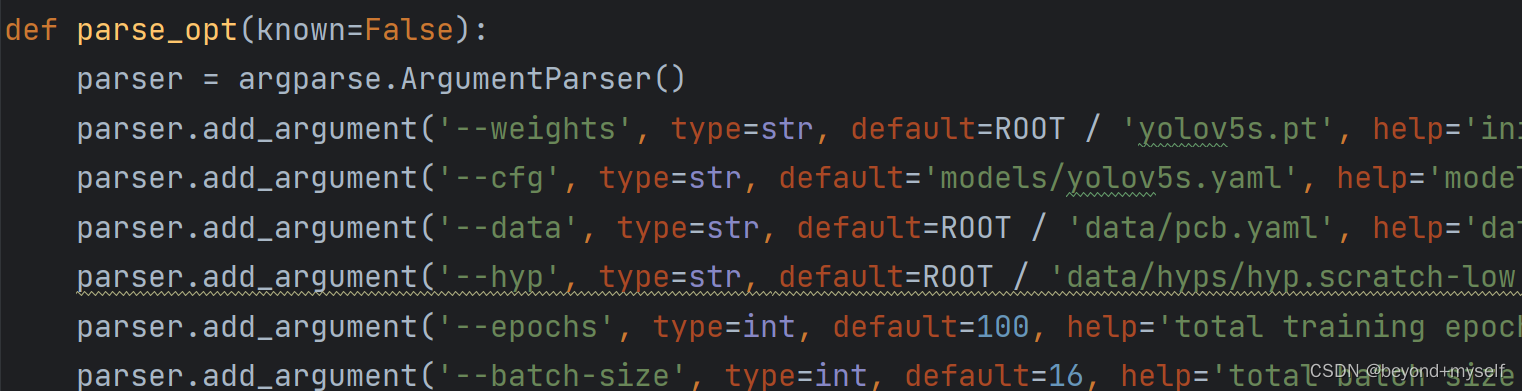
然后将下面三个对应的参数修改即可:
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/pcb.yaml', help='dataset.yaml path')
#注意,第三行中的pcb.yaml如果修改的不是这个名字,换成自己的名字就行
完成了上面的操作,所有的预备条件就完成了,如果用自己的电脑训练的话,直接运行train.py文件就可以了,因为我的电脑配置相对来说不是很好,所以我直接租用服务器来训练,这里的我也建议租用服务器来训练,这里是一个服务器的地址:AutoDL,一方面是服务器的训练速度很快,另一方面训练这样的大模型可能会在电脑上加点东西,还不知道在哪删除,所以建议在服务器上训练。当然自己电脑性能很好的话在自己电脑上训练也完全没有问题。如果不知道AutoDL如何使用的话去看一下上面的说明,很简单的,类似于anaconda的使用。(如果实在不会使用的话,可以私聊我)。
如果上面的操作完成后,只需要在服务器上配置环境(同样是刚才那个pip语句),然后直接训练即可。
调用模型
训练完成后,我们在\yolov5-master1\yolov5-master\runs\train\exp\weights中好到best.pt这个文件,这就是我们训练好的模型,当然有可能有很多的exp文件,我们找一下,一定会有一个exp文件中有这个模型
这些图片都是对模型的评估,可以根据自己的需要对图片进行分析。
如果是在服务器上训练的,建议将整个yolo文件下载下来,因为这个模型的位置并不是随便的,在yolo的代码中可能是已经定义好的,否则直接调用会出现奇怪的bug。下面是调用的一个模板,建议直接粘贴复制:
import os
import torch
import torchvision
import torchvision.models as models
from torchvision import transforms
from PIL import Image
import sys
sys.path.insert(0, './yolov5-master')#这句话一定要加,因为不加会奇怪的错误
#载入本地模型
model = torch.hub.load('D:\yolov5-master', 'custom', 'D:\AI_PCB_test\yolov5-master\\runs\\train\\exp9\\weights\\best.pt', source='local')
#载入图片并显示
img = 'D:\\AI_PCB_test\\PCB_DATASET\\images\\Open_circuit\\12_open_circuit_10.jpg'
result = model(img)
result.show()
我是将yolov5-master放到AI_PCB_test下,然后运行了上面代码既可调用模型,模型调用结果如下图所示:

为什么这么强调文件的位置,因为我在运行的过程中出现了很多的错误,可以多试一下,毕竟这是最后一步,还是这一步完成了就大功告成了。
最后还要注意的是,模型预测的图片应该会最终存入runs/dectect下面,自己不需要创建,如果没有的话,他会自动创建,在调用图片的时候需要注意
图形化界面
用pyqt5或其他的都行,这一步就比较简单了,网上搜一下教程即可。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AI:119-DySnakeConv技术在图像分割中的优化应用:以分割检测头为例
- 【期末复习向】文本理解与数据挖掘-名词解释
- 单聊和群聊
- Android自动化巡检环境搭建
- ADA-YOLO:YOLOv8+注意力+Adaptive Head,mAP提升3%
- nvm安装pnpm,pnpm不是内部或者外部指令问题解决
- D35XB100-ASEMI配电箱整流桥D35XB100
- 【2023 CCF 大数据与计算智能大赛】基于TPU平台实现超分辨率重建模型部署 基于FSRCNN的TPU平台超分辨率模型部署方案
- 华为OD机试真题-用连续自然数之和来表达整数-Java-OD统一考试(C卷)
- java环境配置