写给不耐烦程序员的 JavaScript 指南(二)
第四部分:原始值
原文:
exploringjs.com/impatient-js/pt_primitive-values.html译者:飞龙
下一步:14 非值 undefined 和 null
十四、非值的 undefined 和 null
原文:
exploringjs.com/impatient-js/ch_undefined-null.html译者:飞龙
-
14.1?
undefinedvs.null -
14.2?Occurrences of
undefinedandnull-
14.2.1?Occurrences of
undefined -
14.2.2?Occurrences of
null
-
-
14.3?Checking for
undefinedornull -
14.4?The nullish coalescing operator (
??) for default values [ES2020]-
14.4.1?Example: counting matches
-
14.4.2?Example: specifying a default value for a property
-
14.4.3?Using destructuring for default values
-
14.4.4?Legacy approach: using logical Or (
||) for default values -
14.4.5?空值合并赋值运算符 (
??=) [ES2021]
-
-
14.5?
undefinedandnulldon’t have properties -
14.6?The history of
undefinedandnull
许多编程语言都有一个叫做 null 的“非值”。它表示变量当前没有指向对象 - 例如,当它尚未初始化时。
相反,JavaScript 有两个:undefined 和 null。
14.1?undefined vs. null
这两个值非常相似,经常可以互换使用。它们的区别因此很微妙。语言本身做出以下区分:
-
undefined意味着“未初始化”(例如变量)或“不存在”(例如对象的属性)。 -
null意味着“有意的缺少任何对象值”(引用自语言规范)。
程序员可能会做出以下区分:
-
undefined是语言使用的非值(当某些东西未初始化时等)。 -
null意味着“明确关闭”。也就是说,它有助于实现一个包括有意义值和代表“没有有意义值”的元值的类型。这种类型在函数式编程中称为option type 或 maybe type。
14.2?Occurrences of undefined and null
下面的小节描述了语言中 undefined 和 null 出现的地方。我们将遇到几种稍后在本书中更详细解释的机制。
14.2.1?Occurrences of undefined
未初始化的变量 myVar:
let myVar;
assert.equal(myVar, undefined);
参数 x 未提供:
function func(x) {
return x;
}
assert.equal(func(), undefined);
属性 .unknownProp 丢失:
const obj = {};
assert.equal(obj.unknownProp, undefined);
如果我们没有通过 return 语句明确指定函数的结果,JavaScript 会为我们返回 undefined:
function func() {}
assert.equal(func(), undefined);
14.2.2?Occurrences of null
对象的原型要么是对象,要么在原型链的末端是 null。Object.prototype 没有原型:
> Object.getPrototypeOf(Object.prototype)
null
如果我们对字符串(例如 'x')进行正则表达式匹配(例如 /a/),我们要么得到一个具有匹配数据的对象(如果匹配成功),要么得到 null(如果匹配失败):
> /a/.exec('x')
null
JSON 数据格式 不支持 undefined,只支持 null:
> JSON.stringify({a: undefined, b: null})
'{"b":null}'
14.3?Checking for undefined or null
检查任何一个:
if (x === null) ···
if (x === undefined) ···
x 有值吗?
if (x !== undefined && x !== null) {
// ···
}
if (x) { // truthy?
// x is neither: undefined, null, false, 0, NaN, ''
}
x 是 undefined 还是 null?
if (x === undefined || x === null) {
// ···
}
if (!x) { // falsy?
// x is: undefined, null, false, 0, NaN, ''
}
Truthy 意味着“如果强制转换为布尔值,则为 true”。Falsy 意味着“如果强制转换为布尔值,则为 false”。这两个概念在§15.2 “Falsy and truthy values”中得到了适当的解释。
14.4?The nullish coalescing operator (??) for default values [ES2020]
有时我们会收到一个值,只想在它既不是null也不是undefined时使用它。否则,我们希望使用一个默认值作为后备。我们可以通过空值合并运算符(??)来实现这一点:
const valueToUse = receivedValue ?? defaultValue;
以下两个表达式是等价的:
a ?? b
a !== undefined && a !== null ? a : b
14.4.1 示例:计算匹配项
以下代码显示了一个现实世界的例子:
function countMatches(regex, str) {
const matchResult = str.match(regex); // null or Array
return (matchResult ?? []).length;
}
assert.equal(
countMatches(/a/g, 'ababa'), 3);
assert.equal(
countMatches(/b/g, 'ababa'), 2);
assert.equal(
countMatches(/x/g, 'ababa'), 0);
如果str中存在一个或多个regex的匹配项,则.match()返回一个数组。如果没有匹配项,它不幸地返回null(而不是空数组)。我们通过??运算符来修复这个问题。
我们也可以使用可选链:
return matchResult?.length ?? 0;
14.4.2 示例:为属性指定默认值
function getTitle(fileDesc) {
return fileDesc.title ?? '(Untitled)';
}
const files = [
{path: 'index.html', title: 'Home'},
{path: 'tmp.html'},
];
assert.deepEqual(
files.map(f => getTitle(f)),
['Home', '(Untitled)']);
14.4.3 使用解构来设置默认值
在某些情况下,解构也可以用于默认值 - 例如:
function getTitle(fileDesc) {
const {title = '(Untitled)'} = fileDesc;
return title;
}
14.4.4 传统方法:使用逻辑或(||)来设置默认值
在 ECMAScript 2020 之前和空值合并运算符之前,逻辑或被用于默认值。这有一个缺点。
||对undefined和null的工作方式与预期相同:
> undefined || 'default'
'default'
> null || 'default'
'default'
但它还返回所有其他假值的默认值 - 例如:
> false || 'default'
'default'
> 0 || 'default'
'default'
> 0n || 'default'
'default'
> '' || 'default'
'default'
将其与??的工作方式进行比较:
> undefined ?? 'default'
'default'
> null ?? 'default'
'default'
> false ?? 'default'
false
> 0 ?? 'default'
0
> 0n ?? 'default'
0n
> '' ?? 'default'
''
14.4.5 空值合并赋值运算符(??=) [ES2021]
??=是一个逻辑赋值运算符。以下两个表达式大致等价:
a ??= b
a ?? (a = b)
这意味着??=是短路的:只有在a是undefined或null时才进行赋值。
14.4.5.1 示例:使用??=添加丢失的属性
const books = [
{
isbn: '123',
},
{
title: 'ECMAScript Language Specification',
isbn: '456',
},
];
// Add property .title where it’s missing
for (const book of books) {
book.title ??= '(Untitled)';
}
assert.deepEqual(
books,
[
{
isbn: '123',
title: '(Untitled)',
},
{
title: 'ECMAScript Language Specification',
isbn: '456',
},
]);
14.5 undefined和null没有属性
undefined和null是 JavaScript 中唯一两个值,如果我们尝试读取属性,会得到异常。为了探索这一现象,让我们使用以下函数,该函数读取(“获取”)属性.foo并返回结果。
function getFoo(x) {
return x.foo;
}
如果我们将getFoo()应用于各种值,我们可以看到它仅对undefined和null失败:
> getFoo(undefined)
TypeError: Cannot read properties of undefined (reading 'foo')
> getFoo(null)
TypeError: Cannot read properties of null (reading 'foo')
> getFoo(true)
undefined
> getFoo({})
undefined
14.6 未定义和 null 的历史
在 Java 中(它启发了 JavaScript 的许多方面),初始化值取决于变量的静态类型:
-
具有对象类型的变量被初始化为
null。 -
每种原始类型都有自己的初始化值。例如,
int变量的初始化值为0。
在 JavaScript 中,每个变量既可以保存对象值,也可以保存原始值。因此,如果null表示“不是对象”,JavaScript 还需要一个初始化值,表示“既不是对象也不是原始值”。该初始化值是undefined。
 测验
测验
请参阅测验应用程序。
十五、布尔值
原文:
exploringjs.com/impatient-js/ch_booleans.html译者:飞龙
-
15.1?转换为布尔值
-
15.2?假值和真值
- 15.2.1?检查真值或假值
-
15.3?基于真值的存在性检查
-
15.3.1?陷阱:基于真值的存在性检查不精确
-
15.3.2?用例:是否提供了参数?
-
15.3.3?用例:属性是否存在?
-
-
15.4?条件运算符(
? :) -
15.5?二进制逻辑运算符:And(
x && y),Or(x || y)-
15.5.1?值保留
-
15.5.2?短路
-
15.5.3?逻辑与(
x && y) -
15.5.4?逻辑或(
||)
-
-
15.6?逻辑非(
!)
原始类型boolean包括两个值 - false 和 true:
> typeof false
'boolean'
> typeof true
'boolean'
15.1?转换为布尔值
 “转换为[type]” 的含义
“转换为[type]” 的含义
“转换为[type]”是“将任意值转换为[type]类型的值”的简称。
有三种方法可以将任意值x转换为布尔值。
-
Boolean(x)最具描述性;推荐使用。
-
x ? true : false使用条件运算符(在本章后面解释)。
-
!!x使用逻辑非运算符(
!)。此运算符将其操作数强制转换为布尔值。然后再次应用它以获得非否定的结果。
Tbl. 4 描述了各种值如何转换为布尔值。
表 4:将值转换为布尔值。
x | Boolean(x) |
|---|---|
undefined | false |
null | false |
| boolean | x (no change) |
| number | 0 → false, NaN → false |
其他数字 → true | |
| bigint | 0 → false |
其他数字 → true | |
| string | '' → false |
其他字符串 → true | |
| symbol | true |
| object | 始终为 true |
15.2?假值和真值
在检查if语句、while循环或do-while循环的条件时,JavaScript 的工作方式与您可能期望的不同。例如,考虑以下条件:
if (value) {}
在许多编程语言中,此条件等同于:
if (value === true) {}
然而,在 JavaScript 中,它等同于:
if (Boolean(value) === true) {}
也就是说,JavaScript 检查将value转换为布尔值时是否为true。这种检查非常常见,因此引入了以下名称:
-
如果将值转换为布尔值时为
true,则称该值为真值。 -
如果将值转换为布尔值时为
false,则称该值为假值。
每个值都是真值或假值。通过查阅表 4,我们可以列出所有假值的详尽列表:
-
undefined -
null -
布尔值:
false -
数字:
0,NaN -
Bigint:
0n -
字符串:
''
所有其他值(包括所有对象)都是真值:
> Boolean('abc')
true
> Boolean([])
true
> Boolean({})
true
15.2.1?检查真值或假值
if (x) {
// x is truthy
}
if (!x) {
// x is falsy
}
if (x) {
// x is truthy
} else {
// x is falsy
}
const result = x ? 'truthy' : 'falsy';
在最后一行使用的条件运算符在本章后面有解释。
 练习:真值
练习:真值
exercises/booleans/truthiness_exrc.mjs
15.3?基于真值的存在性检查
在 JavaScript 中,如果你读取一个不存在的东西(例如,一个缺失的参数或一个缺失的属性),通常会得到undefined作为结果。在这些情况下,存在性检查等同于将一个值与undefined进行比较。例如,以下代码检查对象obj是否具有属性.prop:
if (obj.prop !== undefined) {
// obj has property .prop
}
由于undefined是假值,我们可以将这个检查缩短为:
if (obj.prop) {
// obj has property .prop
}
15.3.1 陷阱:基于真实性的存在性检查不够精确
基于真实性的存在性检查有一个陷阱:它们不是很精确。考虑这个之前的例子:
if (obj.prop) {
// obj has property .prop
}
如果:
obj.prop是丢失的(在这种情况下,JavaScript 返回undefined)。
然而,如果:
-
obj.prop是undefined。 -
obj.prop是任何其他假值(null,0,'',等等)。
实际上,这很少会引起问题,但你必须意识到这个陷阱。
15.3.2 用例:是否提供了参数?
真实性检查经常用于确定函数的调用者是否提供了参数:
function func(x) {
if (!x) {
throw new Error('Missing parameter x');
}
// ···
}
好的一面是,这种模式已经被建立并且很简短。它可以正确地抛出undefined和null的错误。
不好的一面是,之前提到的陷阱:代码也会对所有其他假值抛出错误。
另一种方法是检查undefined:
if (x === undefined) {
throw new Error('Missing parameter x');
}
15.3.3 用例:属性是否存在?
真实性检查也经常用于确定属性是否存在:
function readFile(fileDesc) {
if (!fileDesc.path) {
throw new Error('Missing property: .path');
}
// ···
}
readFile({ path: 'foo.txt' }); // no error
这种模式也已经建立,并且有一个通常的警告:它不仅在属性丢失时抛出错误,而且在属性存在并且具有任何假值时也会抛出错误。
如果你真的想检查属性是否存在,你必须使用 in 运算符:
if (! ('path' in fileDesc)) {
throw new Error('Missing property: .path');
}
15.4 条件运算符(? :)
条件运算符是if语句的表达式版本。它的语法是:
?condition? ? ?thenExpression? : ?elseExpression?
它的评估如下:
-
如果
condition为真值,则评估并返回thenExpression。 -
否则,评估并返回
elseExpression。
条件运算符也被称为三元运算符,因为它有三个操作数。
例子:
> true ? 'yes' : 'no'
'yes'
> false ? 'yes' : 'no'
'no'
> '' ? 'yes' : 'no'
'no'
以下代码演示了通过条件选择的两个分支“then”和“else”,只有一个分支被评估。另一个分支不会被评估。
const x = (true ? console.log('then') : console.log('else'));
// Output:
// 'then'
15.5 二进制逻辑运算符:与(x && y),或(x || y)
二进制逻辑运算符&&和||是值保留和短路的。
15.5.1 值保留
值保留意味着操作数被解释为布尔值,但返回不变:
> 12 || 'hello'
12
> 0 || 'hello'
'hello'
15.5.2 短路
短路意味着如果第一个操作数已经确定了结果,那么第二个操作数就不会被评估。唯一延迟评估其操作数的其他运算符是条件运算符。通常,在执行操作之前会评估所有操作数。
例如,逻辑与(&&)如果第一个操作数为假,则不评估第二个操作数:
const x = false && console.log('hello');
// No output
如果第一个操作数为真值,则执行console.log():
const x = true && console.log('hello');
// Output:
// 'hello'
15.5.3 逻辑与(x && y)
表达式a && b(“a和b”)的评估如下:
-
评估
a。 -
结果是否为假?返回它。
-
否则,评估
b并返回结果。
换句话说,以下两个表达式大致等价:
a && b
!a ? a : b
例子:
> false && true
false
> false && 'abc'
false
> true && false
false
> true && 'abc'
'abc'
> '' && 'abc'
''
15.5.4 逻辑或(||)
表达式a || b(“a或b”)的评估如下:
-
评估
a。 -
结果是否为真值?返回它。
-
否则,评估
b并返回结果。
换句话说,以下两个表达式大致等价:
a || b
a ? a : b
例子:
> true || false
true
> true || 'abc'
true
> false || true
true
> false || 'abc'
'abc'
> 'abc' || 'def'
'abc'
15.5.4.1 逻辑或(||)的传统用例:提供默认值
ECMAScript 2020 引入了空值合并运算符(??)用于默认值。在此之前,逻辑或被用于此目的:
const valueToUse = receivedValue || defaultValue;
有关??和在这种情况下||的缺点的更多信息,请参见§14.4“空值合并运算符(??)用于默认值[ES2020]”。
 传统练习:通过或运算符(
传统练习:通过或运算符(||)提供默认值
exercises/booleans/default_via_or_exrc.mjs
15.6 逻辑非 (!)
表达式!x(“非x”)的求值如下:
-
求值
x。 -
它是真值吗?返回
false。 -
否则,返回
true。
例子:
> !false
true
> !true
false
> !0
true
> !123
false
> !''
true
> !'abc'
false
 Quiz
Quiz
参见 quiz app。
十六、数字
原文:
exploringjs.com/impatient-js/ch_numbers.html译者:飞龙
-
16.1?数字既用于浮点数也用于整数
-
16.2?数字文字
-
16.2.1?整数文字
-
16.2.2?浮点数文字
-
16.2.3?语法陷阱:整数字面值的属性
-
16.2.4?数字文字中的下划线 (
_) 作为分隔符 [ES2021]
-
-
16.3?算术运算符
-
16.3.1?二进制算术运算符
-
16.3.2?一元加号 (
+) 和否定 (-) -
16.3.3?递增 (
++) 和递减 (--)
-
-
16.4?转换为数字
-
16.5?错误值
-
16.5.1?错误值:
NaN -
16.5.2?错误值:
Infinity
-
-
16.6?数字的精度:小心处理小数部分
-
16.7?(高级)
-
16.8?背景:浮点数精度
- 16.8.1?浮点数的简化表示
-
16.9?JavaScript 中的整数
-
16.9.1?转换为整数
-
16.9.2?JavaScript 中整数的范围
-
16.9.3?安全整数
-
-
16.10?位运算符
-
16.10.1?在内部,按位运算符使用 32 位整数
-
16.10.2?按位取反
-
16.10.3?二进制位运算符
-
16.10.4?位移运算符
-
16.10.5?
b32(): 以二进制表示无符号 32 位整数
-
-
16.11?快速参考:数字
-
16.11.1?数字的全局函数
-
16.11.2?
Number的静态属性 -
16.11.3?
Number的静态方法 -
16.11.4?
Number.prototype的方法 -
16.11.5?来源
-
JavaScript 有两种数值类型:
-
Numbers 是 64 位浮点数,也用于较小的整数(范围在正负 53 位之内)。
-
Bigints 代表具有任意精度的整数。
本章涵盖了数字。大整数将在本书的后面进行介绍。
16.1?数字既用于浮点数也用于整数
在 JavaScript 中,类型 number 用于整数和浮点数:
98
123.45
然而,所有数字都是双精度,64 位浮点数,根据IEEE 浮点算术标准(IEEE 754)实现。
整数就是没有小数部分的浮点数:
> 98 === 98.0
true
请注意,在底层,大多数 JavaScript 引擎通常能够使用真正的整数,带有所有相关的性能和存储大小优势。
16.2?数字文字
让我们来看看数字的文字。
16.2.1?整数字面值
几个整数字面值让我们可以用不同的基数表示整数:
// Binary (base 2)
assert.equal(0b11, 3); // ES6
// Octal (base 8)
assert.equal(0o10, 8); // ES6
// Decimal (base 10)
assert.equal(35, 35);
// Hexadecimal (base 16)
assert.equal(0xE7, 231);
16.2.2?浮点数文字
浮点数只能用十进制表示。
分数:
> 35.0
35
指数:eN 表示 ×10^N
> 3e2
300
> 3e-2
0.03
> 0.3e2
30
16.2.3?语法陷阱:整数字面值的属性
访问整数字面值的属性会导致一个陷阱:如果整数字面值紧接着一个点,那么该点会被解释为十进制点:
7.toString(); // syntax error
有四种方法可以避开这个陷阱:
7.0.toString()
(7).toString()
7..toString()
7 .toString() // space before dot
16.2.4?下划线 (_) 作为数字字面值中的分隔符 [ES2021]
将数字分组以使长数字更易读具有悠久的传统。例如:
-
1825 年,伦敦有 1,335,000 名居民。
-
地球和太阳之间的距离是 149,600,000 公里。
自 ES2021 以来,我们可以在数字字面值中使用下划线作为分隔符:
const inhabitantsOfLondon = 1_335_000;
const distanceEarthSunInKm = 149_600_000;
对于其他进制,分组也很重要:
const fileSystemPermission = 0b111_111_000;
const bytes = 0b1111_10101011_11110000_00001101;
const words = 0xFAB_F00D;
我们还可以在分数和指数中使用分隔符:
const massOfElectronInKg = 9.109_383_56e-31;
const trillionInShortScale = 1e1_2;
16.2.4.1?我们可以在哪里放置分隔符?
分隔符的位置受到两种限制:
-
我们只能在两个数字之间放下划线。因此,以下所有数字字面值都是非法的:
3_.141 3._141 1_e12 1e_12 _1464301 // valid variable name! 1464301_ 0_b111111000 0b_111111000 -
我们不能连续使用多个下划线:
123__456 // two underscores – not allowed
这些限制背后的动机是保持解析简单,避免奇怪的边缘情况。
16.2.4.2?使用分隔符解析数字
以下用于解析数字的函数不支持分隔符:
-
Number() -
Number.parseInt() -
Number.parseFloat()
例如:
> Number('123_456')
NaN
> Number.parseInt('123_456')
123
其理念是数字分隔符是为了代码。其他类型的输入应该以不同的方式处理。
16.3?算术运算符
16.3.1?二进制算术运算符
Tbl. 5 列出了 JavaScript 的二进制算术运算符。
表 5:二进制算术运算符。
| 运算符 | 名称 | 例子 | |
|---|---|---|---|
n + m | 加法 | ES1 | 3 + 4 → 7 |
n - m | 减法 | ES1 | 9 - 1 → 8 |
n * m | 乘法 | ES1 | 3 * 2.25 → 6.75 |
n / m | 除法 | ES1 | 5.625 / 5 → 1.125 |
n % m | 余数 | ES1 | 8 % 5 → 3 |
-8 % 5 → -3 | |||
n ** m | 指数 | ES2016 | 4 ** 2 → 16 |
16.3.1.1?% 是余数运算符
% 是一个余数运算符,而不是模运算符。其结果具有第一个操作数的符号:
> 5 % 3
2
> -5 % 3
-2
有关余数和模运算之间的区别的更多信息,请参阅博文“余数运算符 vs. 模运算符(带有 JavaScript 代码)” 在 2ality 上。
16.3.2?一元加 (+) 和否定 (-)
Tbl. 6 总结了两个运算符 一元加 (+) 和 否定 (-)。
表 6:一元加 (+) 和否定 (-) 运算符。
| 运算符 | 名称 | 例子 | |
|---|---|---|---|
+n | 一元加 | ES1 | +(-7) → -7 |
-n | 一元否定 | ES1 | -(-7) → 7 |
这两个运算符都会将它们的操作数强制转换为数字:
> +'5'
5
> +'-12'
-12
> -'9'
-9
因此,一元加让我们将任意值转换为数字。
16.3.3?递增 (++) 和递减 (--)
递增运算符 ++ 存在前缀版本和后缀版本。在两个版本中,它都会破坏性地将其操作数加一。因此,它的操作数必须是可以更改的存储位置。
递减运算符 -- 的工作方式相同,但是从其操作数中减去一个。下面的两个例子解释了前缀和后缀版本之间的区别。
Tbl. 7 总结了递增和递减运算符。
表 7:递增运算符和递减运算符。
| 运算符 | 名称 | 例子 | |
|---|---|---|---|
v++ | 递增 | ES1 | let v=0; [v++, v] → [0, 1] |
++v | 递增 | ES1 | let v=0; [++v, v] → [1, 1] |
v-- | 递减 | ES1 | let v=1; [v--, v] → [1, 0] |
--v | 递减 | ES1 | let v=1; [--v, v] → [0, 0] |
接下来,我们将看一些使用这些运算符的例子。
前缀 ++ 和前缀 -- 改变它们的操作数,然后返回它们。
let foo = 3;
assert.equal(++foo, 4);
assert.equal(foo, 4);
let bar = 3;
assert.equal(--bar, 2);
assert.equal(bar, 2);
后缀 ++ 和后缀 -- 返回它们的操作数,然后改变它们。
let foo = 3;
assert.equal(foo++, 3);
assert.equal(foo, 4);
let bar = 3;
assert.equal(bar--, 3);
assert.equal(bar, 2);
16.3.3.1?操作数:不仅仅是变量
我们还可以将这些运算符应用于属性值:
const obj = { a: 1 };
++obj.a;
assert.equal(obj.a, 2);
以及数组元素:
const arr = [ 4 ];
arr[0]++;
assert.deepEqual(arr, [5]);
 练习:数字运算符
练习:数字运算符
exercises/numbers-math/is_odd_test.mjs
16.4?转换为数字
这些是将值转换为数字的三种方法:
-
Number(value) -
+value -
parseFloat(value)(避免;与其他两种方法不同!)
建议:使用描述性的Number()。Tbl. 8 总结了它的工作原理。
表 8:将值转换为数字。
x | Number(x) |
|---|---|
未定义 | NaN |
null | 0 |
| 布尔值 | false → 0,true → 1 |
| 数字 | x(无变化) |
| 大整数 | -1n → -1,1n → 1,等等。 |
| 字符串 | '' → 0 |
其他→解析的数字,忽略前导/尾随空格 | |
| 符号 | 抛出TypeError |
| 对象 | 可配置的(例如通过.valueOf()) |
例子:
assert.equal(Number(123.45), 123.45);
assert.equal(Number(''), 0);
assert.equal(Number('\n 123.45 \t'), 123.45);
assert.equal(Number('xyz'), NaN);
assert.equal(Number(-123n), -123);
对象如何转换为数字可以进行配置-例如,通过覆盖.valueOf():
> Number({ valueOf() { return 123 } })
123
 练习:转换为数字
练习:转换为数字
exercises/numbers-math/parse_number_test.mjs
16.5?错误值
当发生错误时,会返回两个数字值:
-
NaN -
Infinity
16.5.1?错误值:NaN
NaN是“不是一个数字”的缩写。讽刺的是,JavaScript 认为它是一个数字:
> typeof NaN
'number'
何时返回NaN?
如果无法解析数字,则返回NaN:
> Number('$$$')
NaN
> Number(undefined)
NaN
如果无法执行操作,则返回NaN:
> Math.log(-1)
NaN
> Math.sqrt(-1)
NaN
如果操作数或参数是NaN,则返回NaN(以传播错误):
> NaN - 3
NaN
> 7 ** NaN
NaN
16.5.1.1?检查NaN
NaN是唯一一个不严格等于自身的 JavaScript 值:
const n = NaN;
assert.equal(n === n, false);
这是检查值x是否为NaN的几种方法:
const x = NaN;
assert.equal(Number.isNaN(x), true); // preferred
assert.equal(Object.is(x, NaN), true);
assert.equal(x !== x, true);
在最后一行,我们使用比较技巧来检测NaN。
16.5.1.2?在数组中查找NaN
一些数组方法无法找到NaN:
> [NaN].indexOf(NaN)
-1
其他可以:
> [NaN].includes(NaN)
true
> [NaN].findIndex(x => Number.isNaN(x))
0
> [NaN].find(x => Number.isNaN(x))
NaN
遗憾的是,没有简单的经验法则。我们必须检查每种方法如何处理NaN。
16.5.2?错误值:Infinity
何时返回错误值Infinity?
如果数字太大,则返回无穷大:
> Math.pow(2, 1023)
8.98846567431158e+307
> Math.pow(2, 1024)
Infinity
如果除以零,则返回无穷大:
> 5 / 0
Infinity
> -5 / 0
-Infinity
16.5.2.1?Infinity作为默认值
Infinity大于所有其他数字(除了NaN),使其成为一个很好的默认值:
function findMinimum(numbers) {
let min = Infinity;
for (const n of numbers) {
if (n < min) min = n;
}
return min;
}
assert.equal(findMinimum([5, -1, 2]), -1);
assert.equal(findMinimum([]), Infinity);
16.5.2.2?检查Infinity
这是检查值x是否为Infinity的两种常见方法:
const x = Infinity;
assert.equal(x === Infinity, true);
assert.equal(Number.isFinite(x), false);
 练习:比较数字
练习:比较数字
exercises/numbers-math/find_max_test.mjs
16.6?数字的精度:小心处理小数
在内部,JavaScript 浮点数使用基数 2 来表示(根据 IEEE 754 标准)。这意味着十进制小数(基数 10)不能总是精确表示:
> 0.1 + 0.2
0.30000000000000004
> 1.3 * 3
3.9000000000000004
> 1.4 * 100000000000000
139999999999999.98
因此,在 JavaScript 中进行算术运算时,我们需要考虑舍入误差。
继续阅读对这一现象的解释。
 测验:基础
测验:基础
请参阅测验应用程序的解释。
16.7?(高级)
本章的所有其余部分都是高级的。
16.8?背景:浮点精度
在 JavaScript 中,使用数字进行计算并不总是产生正确的结果-例如:
> 0.1 + 0.2
0.30000000000000004
要理解为什么,我们需要探索 JavaScript 如何在内部表示浮点数。它使用三个整数来表示,总共占用 64 位存储空间(双精度):
| 组件 | 大小 | 整数范围 |
|---|---|---|
| 符号 | 1 位 | [0, 1] |
| 分数 | 52 位 | [0, 2?2?1] |
| 指数 | 11 位 | [?1023, 1024] |
由这些整数表示的浮点数计算如下:
(-1)^(符号)× 0b1.fraction × 2^(exponent)
这种表示无法编码零,因为它的第二个组件(涉及分数)总是有一个前导 1。因此,零通过特殊指数-1023 和分数 0 来编码。
16.8.1?浮点数的简化表示
为了使进一步讨论更容易,我们简化了先前的表示:
-
我们使用基数 10(十进制)而不是基数 2(二进制),因为大多数人更熟悉十进制。
-
分数是一个被解释为分数的自然数(小数点后的数字)。我们切换到尾数,一个被解释为自身的整数。因此,指数的使用方式不同,但其基本作用并未改变。
-
由于尾数是一个整数(带有自己的符号),我们不再需要单独的符号。
新的表示方法如下:
尾数 × 10^(指数)
让我们尝试一下这种表示方法来表示一些浮点数。
-
对于整数?123,我们主要需要尾数:
> -123 * (10 ** 0) -123 -
对于数字 1.5,我们想象尾数后有一个点。我们使用负指数将该点向左移动一位:
> 15 * (10 ** -1) 1.5 -
对于数字 0.25,我们将小数点向左移动两位:
> 25 * (10 ** -2) 0.25
具有负指数的表示也可以写成分母中具有正指数的分数:
> 15 * (10 ** -1) === 15 / (10 ** 1)
true
> 25 * (10 ** -2) === 25 / (10 ** 2)
true
这些分数有助于理解为什么有些数字我们的编码无法表示:
-
1/10可以表示。它已经具有所需的格式:分母中的 10 的幂。 -
1/2可以表示为5/10。我们通过将分子和分母乘以 5,将分母中的 2 转换为 10 的幂。 -
1/4可以表示为25/100。我们通过将分子和分母乘以 25,将分母中的 4 转换为 10 的幂。 -
1/3无法表示。没有办法将分母转换为 10 的幂。(10 的质因数是 2 和 5。因此,任何只有这些质因数的分母都可以通过乘以足够多的 2 和 5 来转换为 10 的幂。如果分母有其他质因数,那么我们就无能为力了。)
为了结束我们的探讨,我们再次切换到基数 2:
-
0.5 = 1/2可以用基数 2 表示,因为分母已经是 2 的幂。 -
0.25 = 1/4可以用基数 2 表示,因为分母已经是 2 的幂。 -
0.1 = 1/10无法表示,因为分母无法转换为 2 的幂。 -
0.2 = 2/10无法表示,因为分母无法转换为 2 的幂。
现在我们可以看到为什么0.1 + 0.2不能产生正确的结果:在内部,这两个操作数都无法精确表示。
精确计算小数部分的唯一方法是在内部切换到基数 10。对于许多编程语言,基数 2 是默认值,基数 10 是一个选项。例如,Java 有类BigDecimal,Python 有模块decimal。有计划向 JavaScript 添加类似的功能:ECMAScript 提案“Decimal”。
16.9 JavaScript 中的整数
整数是没有小数部分的正常(浮点)数:
> 1 === 1.0
true
> Number.isInteger(1.0)
true
在本节中,我们将看一些处理这些伪整数的工具。JavaScript 还支持bigints,这些是真正的整数。
16.9.1 转换为整数
将数字转换为整数的推荐方法是使用Math对象的其中一种四舍五入方法:
-
Math.floor(n): 返回最大的整数i≤n> Math.floor(2.1) 2 > Math.floor(2.9) 2 -
Math.ceil(n): 返回最小的整数i≥n> Math.ceil(2.1) 3 > Math.ceil(2.9) 3 -
Math.round(n): 返回与n“最接近”的整数,其中__.5四舍五入为上述整数,例如:> Math.round(2.4) 2 > Math.round(2.5) 3 -
Math.trunc(n): 移除n的任何小数部分(小数点后),因此将其转换为整数。> Math.trunc(2.1) 2 > Math.trunc(2.9) 2
有关四舍五入的更多信息,请参阅§17.3 “Rounding”。
16.9.2 JavaScript 中整数的范围
这些是 JavaScript 中整数的重要范围:
-
**安全整数:**可以被 JavaScript“安全”表示(在下一小节中会详细介绍)
-
精度:53 位加符号
-
范围:(?2?3, 2?3)
-
-
数组索引
-
精度:32 位,无符号
-
范围:[0, 232?1)(不包括最大长度)
-
类型化数组具有 53 位的更大范围(安全且无符号)
-
-
按位运算符(按位或等)
-
精度:32 位
-
无符号右移(
>>>)的范围:无符号,[0, 232) -
所有其他按位运算符的范围:有符号,[?231, 231)
-
16.9.3 安全整数
这是 JavaScript 中安全的整数范围(53 位加上符号):
[–(2?3)+1, 2?3–1]
如果一个整数由一个 JavaScript 数字精确表示,则该整数是安全的。鉴于 JavaScript 数字被编码为乘以 2 的指数幂的分数,更高的整数也可以表示,但它们之间存在间隙。
例如(18014398509481984 是 2??):
> 18014398509481984
18014398509481984
> 18014398509481985
18014398509481984
> 18014398509481986
18014398509481984
> 18014398509481987
18014398509481988
Number的以下属性有助于确定整数是否安全:
assert.equal(Number.MAX_SAFE_INTEGER, (2 ** 53) - 1);
assert.equal(Number.MIN_SAFE_INTEGER, -Number.MAX_SAFE_INTEGER);
assert.equal(Number.isSafeInteger(5), true);
assert.equal(Number.isSafeInteger('5'), false);
assert.equal(Number.isSafeInteger(5.1), false);
assert.equal(Number.isSafeInteger(Number.MAX_SAFE_INTEGER), true);
assert.equal(Number.isSafeInteger(Number.MAX_SAFE_INTEGER+1), false);
 练习:检测安全整数
练习:检测安全整数
exercises/numbers-math/is_safe_integer_test.mjs
16.9.3.1 安全计算
让我们来看看涉及不安全整数的计算。
以下结果是不正确和不安全的,即使它的操作数都是安全的:
> 9007199254740990 + 3
9007199254740992
以下结果是安全的,但不正确。第一个操作数是不安全的;第二个操作数是安全的:
> 9007199254740995 - 10
9007199254740986
因此,表达式a op b的结果是正确的当且仅当:
isSafeInteger(a) && isSafeInteger(b) && isSafeInteger(a op b)
也就是说,操作数和结果都必须是安全的。
16.10?按位运算符
16.10.1 按位运算符在内部使用 32 位整数
在内部,JavaScript 的按位运算符使用 32 位整数。它们通过以下步骤产生结果:
-
输入(JavaScript 数字):首先将 1-2 个操作数转换为 JavaScript 数字(64 位浮点数),然后转换为 32 位整数。
-
计算(32 位整数):实际操作处理 32 位整数并产生 32 位整数。
-
输出(JavaScript 数字):在返回结果之前,它被转换回 JavaScript 数字。
16.10.1.1 操作数和结果的类型
对于每个按位运算符,本书提到了它的操作数和结果的类型。每种类型总是以下两种之一:
| 类型 | 描述 | 大小 | 范围 |
|---|---|---|---|
| Int32 | 有符号 32 位整数 | 32 位包括符号 | ?231, 231) |
| Uint32 | 无符号 32 位整数 | 32 位 | [0, 232) |
考虑到前面提到的步骤,我建议假装按位运算符在内部使用无符号 32 位整数(步骤“计算”),而 Int32 和 Uint32 只影响 JavaScript 数字如何转换为整数和从整数转换为(步骤“输入”和“输出”)。
16.10.1.2 将 JavaScript 数字显示为无符号 32 位整数
在探索按位运算符时,有时将 JavaScript 数字显示为二进制表示的无符号 32 位整数会有所帮助。这就是b32()的作用(其实现稍后会显示):
assert.equal(
b32(-1),
'11111111111111111111111111111111');
assert.equal(
b32(1),
'00000000000000000000000000000001');
assert.equal(
b32(2 ** 31),
'10000000000000000000000000000000');
16.10.2 按位非
表 9:按位非运算符。
| 操作 | 名称 | 类型签名 | |
|---|---|---|---|
~num | 按位非,补码 | Int32 → Int32 | ES1 |
按位非运算符(tbl. [9)反转其操作数的每个二进制位:
> b32(~0b100)
'11111111111111111111111111111011'
所谓的补码对于某些算术运算类似于负数。例如,将整数加上它的补码总是-1:
> 4 + ~4
-1
> -11 + ~-11
-1
16.10.3 二进制按位运算符
表 10:二进制按位运算符。
| 操作 | 名称 | 类型签名 | |
|---|---|---|---|
num1 & num2 | 按位与 | Int32 × Int32 → Int32 | ES1 |
num1 | num2 | 按位或 | Int32 × Int32 → Int32 | ES1 |
num1 ^ num2 | 按位异或 | Int32 × Int32 → Int32 | ES1 |
二进制按位运算符(tbl. 10)将它们的操作数的位组合起来产生它们的结果:
> (0b1010 & 0b0011).toString(2).padStart(4, '0')
'0010'
> (0b1010 | 0b0011).toString(2).padStart(4, '0')
'1011'
> (0b1010 ^ 0b0011).toString(2).padStart(4, '0')
'1001'
16.10.4 按位移动运算符
表 11:位移运算符。
| 操作 | 名称 | 类型签名 | |
|---|---|---|---|
num << count | 左移 | Int32 × Uint32 → Int32 | ES1 |
num >> count | 有符号右移 | Int32 × Uint32 → Int32 | ES1 |
num >>> count | 无符号右移 | Uint32 × Uint32 → Uint32 | ES1 |
位移运算符(见表 11)将二进制数字向左或向右移动:
> (0b10 << 1).toString(2)
'100'
>>保留最高位,>>>不保留:
> b32(0b10000000000000000000000000000010 >> 1)
'11000000000000000000000000000001'
> b32(0b10000000000000000000000000000010 >>> 1)
'01000000000000000000000000000001'
16.10.5?b32(): 以二进制表示无符号 32 位整数
我们现在已经使用了b32()几次。以下代码是它的一个实现:
/**
* Return a string representing n as a 32-bit unsigned integer,
* in binary notation.
*/
function b32(n) {
// >>> ensures highest bit isn’t interpreted as a sign
return (n >>> 0).toString(2).padStart(32, '0');
}
assert.equal(
b32(6),
'00000000000000000000000000000110');
n >>> 0表示我们将n向右移动零位。因此,原则上,>>>运算符什么也不做,但它仍然将n强制转换为无符号 32 位整数:
> 12 >>> 0
12
> -12 >>> 0
4294967284
> (2**32 + 1) >>> 0
1
16.11?快速参考:数字
16.11.1?用于数字的全局函数
JavaScript 有以下四个用于数字的全局函数:
-
isFinite() -
isNaN() -
parseFloat() -
parseInt()
然而,最好使用Number的相应方法(Number.isFinite()等),它们有更少的陷阱。它们是在 ES6 中引入的,并在下面讨论。
16.11.2?Number的静态属性
-
.EPSILON: number^([ES6])1 和下一个可表示的浮点数之间的差异。一般来说,机器 epsilon提供了浮点运算中舍入误差的上限。
- 大约为:2.2204460492503130808472633361816 × 10^(-16)
-
.MAX_SAFE_INTEGER: number^([ES6])JavaScript 可以明确表示的最大整数(2?3?1)。
-
.MAX_VALUE: number^([ES1])最大的正有限 JavaScript 数字。
- 大约为:1.7976931348623157 × 103??
-
.MIN_SAFE_INTEGER: number^([ES6])JavaScript 可以明确表示的最小整数(?2?3+1)。
-
.MIN_VALUE: number^([ES1])最小的正 JavaScript 数字。大约为 5 × 10^(?324)。
-
.NaN: number^([ES1])与全局变量
NaN相同。 -
.NEGATIVE_INFINITY: number^([ES1])与
-Number.POSITIVE_INFINITY相同。 -
.POSITIVE_INFINITY: number^([ES1])与全局变量
Infinity相同。
16.11.3?Number的静态方法
-
.isFinite(num: number): boolean^([ES6])如果
num是一个实际数字(既不是Infinity也不是-Infinity也不是NaN),则返回true。> Number.isFinite(Infinity) false > Number.isFinite(-Infinity) false > Number.isFinite(NaN) false > Number.isFinite(123) true -
.isInteger(num: number): boolean^([ES6])如果
num是一个数字并且没有小数部分,则返回true。> Number.isInteger(-17) true > Number.isInteger(33) true > Number.isInteger(33.1) false > Number.isInteger('33') false > Number.isInteger(NaN) false > Number.isInteger(Infinity) false -
.isNaN(num: number): boolean^([ES6])如果
num是值NaN,则返回true:> Number.isNaN(NaN) true > Number.isNaN(123) false > Number.isNaN('abc') false -
.isSafeInteger(num: number): boolean^([ES6])如果
num是一个数字并且明确表示一个整数,则返回true。 -
.parseFloat(str: string): number^([ES6])将其参数强制转换为字符串并将其解析为浮点数。对于将字符串转换为数字,通常使用
Number()(它忽略前导和尾随空格)比使用Number.parseFloat()(它忽略前导空格和非法的尾随字符,并且可能隐藏问题)更好。> Number.parseFloat(' 123.4#') 123.4 > Number(' 123.4#') NaN -
.parseInt(str: string, radix=10): number^([ES6])将其参数强制转换为字符串并将其解析为整数,忽略前导空格和非法的尾随字符:
> Number.parseInt(' 123#') 123参数
radix指定要解析的数字的基数:> Number.parseInt('101', 2) 5 > Number.parseInt('FF', 16) 255不要使用此方法将数字转换为整数:强制转换为字符串是低效的。在第一个非数字之前停止不是去除数字的小数部分的好算法。这里有一个它出错的例子:
> Number.parseInt(1e21, 10) // wrong 1最好使用
Math的一个舍入函数将数字转换为整数:> Math.trunc(1e21) // correct 1e+21
16.11.4?Number.prototype的方法
(Number.prototype是存储数字方法的地方。)
-
.toExponential(fractionDigits?: number): string^([ES3])返回表示数字的指数表示的字符串。使用
fractionDigits,我们可以指定应显示与指数相乘的数字的位数(默认情况下,显示所需的位数)。示例:数字太小,无法通过
.toString()获得正指数。> 1234..toString() '1234' > 1234..toExponential() // 3 fraction digits '1.234e+3' > 1234..toExponential(5) '1.23400e+3' > 1234..toExponential(1) '1.2e+3'示例:小数部分不够小,无法通过
.toString()获得负指数。> 0.003.toString() '0.003' > 0.003.toExponential() '3e-3' -
.toFixed(fractionDigits=0): string^([ES3])返回不带指数的数字表示,四舍五入到
fractionDigits位数。> 0.00000012.toString() // with exponent '1.2e-7' > 0.00000012.toFixed(10) // no exponent '0.0000001200' > 0.00000012.toFixed() '0'如果数字大于或等于 1021,甚至
.toFixed()也会使用指数:> (10 ** 21).toFixed() '1e+21' -
.toPrecision(precision?: number): string^([ES3])类似于
.toString(),但precision指定应显示多少位数字。如果缺少precision,则使用.toString()。> 1234..toPrecision(3) // requires exponential notation '1.23e+3' > 1234..toPrecision(4) '1234' > 1234..toPrecision(5) '1234.0' > 1.234.toPrecision(3) '1.23' -
.toString(radix=10): string^([ES1])返回数字的字符串表示。
默认情况下,我们得到一个以 10 为底的数字作为结果:
> 123.456.toString() '123.456'如果我们希望数字以不同的基数表示,可以通过
radix指定:> 4..toString(2) // binary (base 2) '100' > 4.5.toString(2) '100.1' > 255..toString(16) // hexadecimal (base 16) 'ff' > 255.66796875.toString(16) 'ff.ab' > 1234567890..toString(36) 'kf12oi'Number.parseInt()提供了反向操作:它将包含给定基数的整数(无小数部分!)数字的字符串转换为数字。> Number.parseInt('kf12oi', 36) 1234567890
16.11.5?来源
 测验:高级
测验:高级
请参阅测验应用程序。
十七、数学
原文:
exploringjs.com/impatient-js/ch_math.html译者:飞龙
-
17.1?数据属性
-
17.2?指数、根、对数
-
17.3?舍入
-
17.4?三角函数
-
17.5?其他各种函数
-
17.6?来源
Math是一个具有数据属性和用于处理数字的方法的对象。您可以将其视为一个简陋的模块:它是在 JavaScript 拥有模块之前创建的。
17.1?数据属性
-
Math.E: number^([ES1])欧拉数,自然对数的底数,约为 2.7182818284590452354。
-
Math.LN10: number^([ES1])10 的自然对数,约为 2.302585092994046。
-
Math.LN2: number^([ES1])2 的自然对数,约为 0.6931471805599453。
-
Math.LOG10E: number^([ES1])以 10 为底的e的对数,约为 0.4342944819032518。
-
Math.LOG2E: number^([ES1])e的以 2 为底的对数,约为 1.4426950408889634。
-
Math.PI: number^([ES1])数学常数π,圆的周长与直径的比值,约为 3.1415926535897932。
-
Math.SQRT1_2: number^([ES1])1/2 的平方根,约为 0.7071067811865476。
-
Math.SQRT2: number^([ES1])2 的平方根,约为 1.4142135623730951。
17.2?指数、根、对数
-
Math.cbrt(x: number): number^([ES6])返回
x的立方根。> Math.cbrt(8) 2 -
Math.exp(x: number): number^([ES1])返回e^(
x)(e为欧拉数)。是Math.log()的反函数。> Math.exp(0) 1 > Math.exp(1) === Math.E true -
Math.expm1(x: number): number^([ES6])返回
Math.exp(x)-1。是Math.log1p()的反函数。非常小的数字(接近 0 的分数)以更高的精度表示。因此,当.exp()返回接近 1 的值时,此函数返回更精确的值。 -
Math.log(x: number): number^([ES1])返回
x的自然对数(以e为底,即欧拉数)。是Math.exp()的反函数。> Math.log(1) 0 > Math.log(Math.E) 1 > Math.log(Math.E ** 2) 2 -
Math.log1p(x: number): number^([ES6])返回
Math.log(1 + x)。是Math.expm1()的反函数。非常小的数字(接近 0 的分数)以更高的精度表示。因此,当.log()的参数接近 1 时,您可以提供此函数更精确的参数。 -
Math.log10(x: number): number^([ES6])返回
x的以 10 为底的对数。是10 ** x的反函数。> Math.log10(1) 0 > Math.log10(10) 1 > Math.log10(100) 2 -
Math.log2(x: number): number^([ES6])返回
x的以 2 为底的对数。是2 ** x的反函数。> Math.log2(1) 0 > Math.log2(2) 1 > Math.log2(4) 2 -
Math.pow(x: number, y: number): number^([ES1])返回
x^(y),x的y次方。与x ** y相同。> Math.pow(2, 3) 8 > Math.pow(25, 0.5) 5 -
Math.sqrt(x: number): number^([ES1])返回
x的平方根。是x ** 2的反函数。> Math.sqrt(9) 3
17.3?舍入
舍入意味着将任意数字转换为整数(没有小数部分的数字)。以下函数实现了不同的舍入方法。
-
Math.ceil(x: number): number^([ES1])返回最小的(最接近-∞)整数
i,使得x≤i。> Math.ceil(2.1) 3 > Math.ceil(2.9) 3 -
Math.floor(x: number): number^([ES1])返回最大的(最接近+∞)整数
i,使得i≤x。> Math.floor(2.1) 2 > Math.floor(2.9) 2 -
Math.round(x: number): number^([ES1])返回最接近
x的整数。如果x的小数部分是.5,则.round()会向上舍入(到更接近正无穷大的整数):> Math.round(2.4) 2 > Math.round(2.5) 3 -
Math.trunc(x: number): number^([ES6])去除
x的小数部分并返回结果整数。> Math.trunc(2.1) 2 > Math.trunc(2.9) 2
Tbl. 12 显示了几个代表性输入的舍入函数的结果。
表 12:Math的舍入函数。请注意,由于“更大”始终意味着“更接近正无穷大”,因此负数会导致结果发生变化。
-2.9 | -2.5 | -2.1 | 2.1 | 2.5 | 2.9 | |
|---|---|---|---|---|---|---|
Math.floor | -3 | -3 | -3 | 2 | 2 | 2 |
Math.ceil | -2 | -2 | -2 | 3 | 3 | 3 |
Math.round | -3 | -2 | -2 | 2 | 3 | 3 |
Math.trunc | -2 | -2 | -2 | 2 | 2 | 2 |
17.4?三角函数
所有角度均以弧度指定。使用以下两个函数在度和弧度之间进行转换。
function degreesToRadians(degrees) {
return degrees / 180 * Math.PI;
}
assert.equal(degreesToRadians(90), Math.PI/2);
function radiansToDegrees(radians) {
return radians / Math.PI * 180;
}
assert.equal(radiansToDegrees(Math.PI), 180);
-
Math.acos(x: number): number^([ES1])返回
x的反余弦(反余弦)。> Math.acos(0) 1.5707963267948966 > Math.acos(1) 0 -
Math.acosh(x: number): number^([ES6])返回
x的反双曲余弦。 -
Math.asin(x: number): number^([ES1])返回
x的反正弦(反正弦)。> Math.asin(0) 0 > Math.asin(1) 1.5707963267948966 -
Math.asinh(x: number): number^([ES6])返回
x的反双曲正弦。 -
Math.atan(x: number): number^([ES1])返回
x的反正切(反正切)。 -
Math.atanh(x: number): number^([ES6])返回
x的反双曲正切。 -
Math.atan2(y: number, x: number): number^([ES1])返回商 y/x 的反正切。
-
Math.cos(x: number): number^([ES1])返回
x的余弦。> Math.cos(0) 1 > Math.cos(Math.PI) -1 -
Math.cosh(x: number): number^([ES6])返回
x的双曲余弦。 -
Math.hypot(...values: number[]): number^([ES6])返回
values的平方和的平方根(毕达哥拉斯定理):> Math.hypot(3, 4) 5 -
Math.sin(x: number): number^([ES1])返回
x的正弦。> Math.sin(0) 0 > Math.sin(Math.PI / 2) 1 -
Math.sinh(x: number): number^([ES6])返回
x的双曲正弦。 -
Math.tan(x: number): number^([ES1])返回
x的正切。> Math.tan(0) 0 > Math.tan(1) 1.5574077246549023 -
Math.tanh(x: number): number;^([ES6])返回
x的双曲正切。
17.5?其他各种功能
-
Math.abs(x: number): number^([ES1])返回
x的绝对值。> Math.abs(3) 3 > Math.abs(-3) 3 > Math.abs(0) 0 -
Math.clz32(x: number): number^([ES6])计算 32 位整数
x中前导零位的数量。用于 DSP 算法。> Math.clz32(0b01000000000000000000000000000000) 1 > Math.clz32(0b00100000000000000000000000000000) 2 > Math.clz32(2) 30 > Math.clz32(1) 31 -
Math.max(...values: number[]): number^([ES1])将
values转换为数字并返回最大值。> Math.max(3, -5, 24) 24 -
Math.min(...values: number[]): number^([ES1])将
values转换为数字并返回最小值。> Math.min(3, -5, 24) -5 -
Math.random(): number^([ES1])返回一个伪随机数
n,其中 0 ≤n< 1。/** Returns a random integer i with 0 <= i < max */ function getRandomInteger(max) { return Math.floor(Math.random() * max); } -
Math.sign(x: number): number^([ES6])返回一个数字的符号:
> Math.sign(-8) -1 > Math.sign(0) 0 > Math.sign(3) 1
17.6?来源
十八、大整数 - 任意精度整数 [ES2020](高级)
原文:
exploringjs.com/impatient-js/ch_bigints.html译者:飞龙
-
18.1 为什么 bigints?
-
18.2 Bigints
-
18.2.1 超越 53 位整数
-
18.2.2 示例:使用 bigints
-
-
18.3 大整数文字
- 18.3.1 大整数文字中的下划线(
_)作为分隔符[ES2021]
- 18.3.1 大整数文字中的下划线(
-
18.4 重用 bigints 的数字运算符(重载)
-
18.4.1 算术运算符
-
18.4.2 排序运算符
-
18.4.3 位运算符
-
18.4.4 松散相等(
==)和不等(!=) -
18.4.5 严格相等(
===)和不等(!==)
-
-
18.5 包装构造函数
BigInt-
18.5.1
BigInt作为构造函数和作为函数 -
18.5.2
BigInt.prototype.*方法 -
18.5.3
BigInt.*方法 -
18.5.4 强制转换和 64 位整数
-
-
18.6 将 bigints 强制转换为其他原始类型
-
18.7 64 位值的 TypedArrays 和 DataView 操作
-
18.8 Bigints 和 JSON
-
18.8.1 将 bigints 转换为字符串
-
18.8.2 解析大整数
-
-
18.9 常见问题:Bigints
-
18.9.1 我如何决定何时使用数字,何时使用 bigints?
-
18.9.2 为什么不像 bigints 一样增加数字的精度?
-
在本章中,我们将看一下bigints,JavaScript 的整数,其存储空间会根据需要增长和缩小。
18.1 为什么 bigints?
在 ECMAScript 2020 之前,JavaScript 处理整数如下:
-
浮点数和整数只有一个类型:64 位浮点数(IEEE 754 双精度)。
-
在幕后,大多数 JavaScript 引擎透明地支持整数:如果一个数字没有小数位并且在某个范围内,它可以在内部存储为真正的整数。这种表示称为小整数,通常适合 32 位。例如,在 V8 引擎的 64 位版本上,小整数的范围是从-231到 231-1(来源)。
-
JavaScript 数字也可以表示超出小整数范围的整数,作为浮点数。在这里,安全范围是加/减 53 位。有关此主题的更多信息,请参见§16.9.3“安全整数”。
有时,我们需要超过有符号的 53 位 - 例如:
-
Twitter 使用 64 位整数作为推文的 ID(来源)。在 JavaScript 中,这些 ID 必须存储为字符串。
-
金融技术使用所谓的大整数(具有任意精度的整数)来表示货币金额。在内部,金额被乘以一个数,以便十进制数消失。例如,美元金额被乘以 100,以便消失掉美分。
18.2 Bigints
Bigint是一个新的整数原始数据类型。大整数的存储大小没有固定的位数;它们的大小会根据它们所表示的整数而调整:
-
小整数的位数比大整数少。
-
可以表示的整数没有负的下限或正的上限。
大整数文字是一个由一个或多个数字组成的序列,后面跟着一个 n - 例如:
123n
诸如 - 和 * 这样的运算符被重载并且可以与大整数一起使用:
> 123n * 456n
56088n
大整数是原始值。typeof 为它们返回一个新的结果:
> typeof 123n
'bigint'
18.2.1?超过 53 位的整数
JavaScript 数字在内部表示为一个乘以指数的分数(有关详细信息,请参见§16.8“背景:浮点精度”)。因此,如果我们超过了最高的安全整数 2?3?1,仍然有一些整数可以表示,但它们之间存在间隙:
> 2**53 - 2 // safe
9007199254740990
> 2**53 - 1 // safe
9007199254740991
> 2**53 // unsafe, same as next integer
9007199254740992
> 2**53 + 1
9007199254740992
> 2**53 + 2
9007199254740994
> 2**53 + 3
9007199254740996
> 2**53 + 4
9007199254740996
> 2**53 + 5
9007199254740996
大整数使我们能够超过 53 位:
> 2n**53n
9007199254740992n
> 2n**53n + 1n
9007199254740993n
> 2n**53n + 2n
9007199254740994n
18.2.2?示例:使用大整数
这就是使用大整数的样子(基于提案中的一个例子):
/**
* Takes a bigint as an argument and returns a bigint
*/
function nthPrime(nth) {
if (typeof nth !== 'bigint') {
throw new TypeError();
}
function isPrime(p) {
for (let i = 2n; i < p; i++) {
if (p % i === 0n) return false;
}
return true;
}
for (let i = 2n; ; i++) {
if (isPrime(i)) {
if (--nth === 0n) return i;
}
}
}
assert.deepEqual(
[1n, 2n, 3n, 4n, 5n].map(nth => nthPrime(nth)),
[2n, 3n, 5n, 7n, 11n]
);
18.3?大整数文字
与数字文字一样,大整数文字支持几种基数:
-
十进制:
123n -
十六进制:
0xFFn -
二进制:
0b1101n -
八进制:
0o777n
负大整数是通过在数字前加上一元减号操作符来产生的:-0123n
18.3.1?大整数文字中的下划线(_)作为分隔符 [ES2021]
就像在数字文字中一样,我们可以在大整数文字中使用下划线(_)作为分隔符:
const massOfEarthInKg = 6_000_000_000_000_000_000_000_000n;
大整数经常用于在金融技术领域表示货币。分隔符在这里也有帮助:
const priceInCents = 123_000_00n; // 123 thousand dollars
与数字文字一样,有两个限制:
-
我们只能在两个数字之间放一个下划线。
-
我们最多可以连续使用一个下划线。
18.4?重用大整数的数字运算符(重载)
对于大多数运算符,我们不允许混合使用大整数和数字。如果这样做,就会抛出异常:
> 2n + 1
TypeError: Cannot mix BigInt and other types, use explicit conversions
这个规则的原因是没有一般的方法来强制一个数字和一个大整数转换为一个公共类型:数字无法表示超过 53 位的大整数,大整数无法表示分数。因此,这些异常警告我们可能导致意外结果的拼写错误。
例如,以下表达式的结果应该是 9007199254740993n 还是 9007199254740992?
2**53 + 1n
以下表达式的结果也不清楚:
2n**53n * 3.3
18.4.1?算术运算符
二进制 +,二进制 -,*,** 的工作方式与预期相同:
> 7n * 3n
21n
混合使用大整数和字符串是可以的:
> 6n + ' apples'
'6 apples'
/,% 向零舍入(就像 Math.trunc()):
> 1n / 2n
0n
一元 - 的工作方式与预期相同:
> -(-64n)
64n
大整数不支持一元 +,因为很多代码依赖于它将其操作数强制转换为数字:
> +23n
TypeError: Cannot convert a BigInt value to a number
18.4.2?排序运算符
排序运算符 <,>,>=,<= 的工作方式与预期相同:
> 17n <= 17n
true
> 3n > -1n
true
比较大整数和数字不会带来任何风险。因此,我们可以混合使用大整数和数字:
> 3n > -1
true
18.4.3?按位运算符
18.4.3.1?数字的按位运算符
按位运算符将数字解释为 32 位整数。这些整数可以是无符号的,也可以是有符号的。如果它们是有符号的,那么一个整数的负数是它的二进制补码(将一个整数加上它的二进制补码 - 忽略溢出 - 会得到零):
> 2**32-1 >> 0
-1
由于这些整数具有固定的大小,它们的最高位表示它们的符号:
> 2**31 >> 0 // highest bit is 1
-2147483648
> 2**31 - 1 >> 0 // highest bit is 0
2147483647
18.4.3.2?大整数的按位运算符
对于大整数,按位运算符将负号解释为无限的二进制补码 - 例如:
-
-1是···111111(1 无限扩展到左边) -
-2是···111110 -
-3是···111101 -
-4是···111100
也就是说,负号更像是一个外部标志,而不是实际表示为一个位。
18.4.3.3?按位取反(~)
按位取反(~)反转所有位:
> ~0b10n
-3n
> ~0n
-1n
> ~-2n
1n
18.4.3.4?二进制按位运算符(&,|,^)
将二进制按位运算符应用于大整数的工作方式类似于将它们应用于数字:
> (0b1010n | 0b0111n).toString(2)
'1111'
> (0b1010n & 0b0111n).toString(2)
'10'
> (0b1010n | -1n).toString(2)
'-1'
> (0b1010n & -1n).toString(2)
'1010'
18.4.3.5?按位有符号移位运算符(<< 和 >>)
bigint 的有符号移位运算符保留数字的符号:
> 2n << 1n
4n
> -2n << 1n
-4n
> 2n >> 1n
1n
> -2n >> 1n
-1n
回想一下,-1n 是一个向左无限延伸的一系列数字。这就是为什么将其向左移动不会改变它的原因:
> -1n >> 20n
-1n
18.4.3.6?位无符号右移运算符 (>>>)
bigint 没有无符号右移运算符:
> 2n >>> 1n
TypeError: BigInts have no unsigned right shift, use >> instead
为什么?无符号右移的想法是从“左边”移入一个零。换句话说,假设是有限数量的二进制数字。
然而,对于 bigint,没有“左”,它们的二进制数字无限延伸。这在处理负数时尤为重要。
有符号右移即使在有无限位数的情况下也可以工作,因为最高位数字被保留。因此,它可以适应 bigint。
18.4.4?宽松相等 (==) 和不等 (!=)
宽松相等 (==) 和不等 (!=) 强制转换值:
> 0n == false
true
> 1n == true
true
> 123n == 123
true
> 123n == '123'
true
18.4.5?严格相等 (===) 和不等 (!==)
严格相等 (===) 和不等 (!==) 只有在它们具有相同类型时才被认为是相等的:
> 123n === 123
false
> 123n === 123n
true
18.5?包装构造函数 BigInt
类似于数字,bigint 有关联的包装构造函数 BigInt。
18.5.1?BigInt 作为构造函数和作为函数
-
new BigInt(): 抛出TypeError。 -
BigInt(x)将任意值x转换为 bigint。这类似于Number(),但有几个不同之处,这些不同之处在 tbl. 13 中总结,并在以下小节中详细解释。
表 13:将值转换为 bigint。
x | BigInt(x) |
|---|---|
undefined | 抛出 TypeError |
null | 抛出 TypeError |
| 布尔值 | false → 0n, true → 1n |
| 数字 | 例子:123 → 123n |
非整数 → 抛出 RangeError | |
| bigint | x (不变) |
| 字符串 | 例子:'123' → 123n |
无法解析的 → 抛出 SyntaxError | |
| 符号 | 抛出 TypeError |
| 对象 | 可配置的(例如通过 .valueOf()) |
18.5.1.1?转换 undefined 和 null
如果 x 是 undefined 或 null,则抛出 TypeError:
> BigInt(undefined)
TypeError: Cannot convert undefined to a BigInt
> BigInt(null)
TypeError: Cannot convert null to a BigInt
18.5.1.2?转换字符串
如果一个字符串不表示整数,BigInt() 抛出 SyntaxError(而 Number() 返回错误值 NaN):
> BigInt('abc')
SyntaxError: Cannot convert abc to a BigInt
后缀 'n' 是不允许的:
> BigInt('123n')
SyntaxError: Cannot convert 123n to a BigInt
bigint 文字的所有基数都是允许的:
> BigInt('123')
123n
> BigInt('0xFF')
255n
> BigInt('0b1101')
13n
> BigInt('0o777')
511n
18.5.1.3?非整数数字会产生异常
> BigInt(123.45)
RangeError: The number 123.45 cannot be converted to a BigInt because
it is not an integer
> BigInt(123)
123n
18.5.1.4?转换对象
如何将对象转换为 bigint 可以进行配置 - 例如,通过覆盖 .valueOf():
> BigInt({valueOf() {return 123n}})
123n
18.5.2?BigInt.prototype.* 方法
BigInt.prototype 包含了原始 bigint “继承”的方法:
-
BigInt.prototype.toLocaleString(locales?, options?) -
BigInt.prototype.toString(radix?) -
BigInt.prototype.valueOf()
18.5.3?BigInt.* 方法
-
BigInt.asIntN(width, theInt)将
theInt转换为width位(有符号)。这会影响值在内部的表示方式。 -
BigInt.asUintN(width, theInt)将
theInt转换为width位(无符号)。
18.5.4?强制转换和 64 位整数
强制转换允许我们创建具有特定位数的整数值。如果我们想要限制自己只使用 64 位整数,我们必须始终进行强制转换:
const uint64a = BigInt.asUintN(64, 12345n);
const uint64b = BigInt.asUintN(64, 67890n);
const result = BigInt.asUintN(64, uint64a * uint64b);
18.6?将 bigint 强制转换为其他原始类型
这个表格展示了如果我们将 bigint 转换为其他原始类型会发生什么:
| 转换为 | 显式转换 | 强制转换(隐式转换) |
|---|---|---|
| 布尔值 | Boolean(0n) → false | !0n → true |
Boolean(int) → true | !int → false | |
| 数字 | Number(7n) → 7 (例子) | +int → TypeError (1) |
| 字符串 | String(7n) → '7' (例子) | ''+7n → '7' (例子) |
注释:
- (1) 由于很多代码依赖于它将其操作数强制转换为数字,因此 bigint 不支持一元
+。
18.7?64 位值的 TypedArrays 和 DataView 操作
由于 bigint,Typed Arrays 和 DataViews 可以支持 64 位值。
-
类型化数组构造函数:
-
BigInt64Array -
BigUint64Array
-
-
DataView 方法:
-
DataView.prototype.getBigInt64() -
DataView.prototype.setBigInt64() -
DataView.prototype.getBigUint64() -
DataView.prototype.setBigUint64()
-
18.8 Bigints 和 JSON
JSON 标准是固定的,不会改变。好处是旧的 JSON 解析代码永远不会过时。坏处是 JSON 无法扩展以包含 bigint。
序列化 bigint 会抛出异常:
> JSON.stringify(123n)
TypeError: Do not know how to serialize a BigInt
> JSON.stringify([123n])
TypeError: Do not know how to serialize a BigInt
18.8.1 序列化 bigint
因此,我们最好的选择是将 bigint 存储为字符串:
const bigintPrefix = '[[bigint]]';
function bigintReplacer(_key, value) {
if (typeof value === 'bigint') {
return bigintPrefix + value;
}
return value;
}
const data = { value: 9007199254740993n };
assert.equal(
JSON.stringify(data, bigintReplacer),
'{"value":"[[bigint]]9007199254740993"}'
);
18.8.2 解析 bigint
以下代码显示了如何解析诸如我们在前面示例中生成的字符串。
function bigintReviver(_key, value) {
if (typeof value === 'string' && value.startsWith(bigintPrefix)) {
return BigInt(value.slice(bigintPrefix.length));
}
return value;
}
const str = '{"value":"[[bigint]]9007199254740993"}';
assert.deepEqual(
JSON.parse(str, bigintReviver),
{ value: 9007199254740993n }
);
18.9 常见问题:Bigints
18.9.1 我如何决定何时使用数字,何时使用 bigint?
我的建议:
-
对于最多 53 位和数组索引,请使用数字。原因是:它们已经随处可见,并且大多数引擎都可以高效处理它们(特别是如果它们适合 31 位)。出现的情况包括:
-
Array.prototype.forEach() -
Array.prototype.entries()
-
-
对于大数值,请使用 bigint:如果您的无小数数值不适合 53 位,那么您别无选择,只能转为 bigint。
所有现有的 web API 只返回和接受数字,并且只会在特定情况下升级为 bigint。
18.9.2 为什么不像 bigint 一样增加数字的精度?
可以想象将number分成integer和double,但这将给语言增加许多新的复杂性(几个仅限整数的运算符等)。我在a Gist中勾勒了后果。
致谢:
-
感谢 Daniel Ehrenberg 对此内容的早期版本进行审查。
-
感谢 Dan Callahan 对此内容的早期版本进行审查。
十九、Unicode-简介(高级)
原文:
exploringjs.com/impatient-js/ch_unicode.html译者:飞龙
-
19.1?码点与码元
-
19.1.1?码点
-
19.1.2?编码 Unicode 码点:UTF-32,UTF-16,UTF-8
-
-
19.2?Web 开发中使用的编码:UTF-16 和 UTF-8
-
19.2.1?内部源代码:UTF-16
-
19.2.2?字符串:UTF-16
-
19.2.3?文件中的源代码:UTF-8
-
-
19.3?字形簇-真正的字符
- 19.3.1?字形簇与字形
Unicode 是表示和管理世界上大多数书写系统的文本的标准。几乎所有处理文本的现代软件都支持 Unicode。该标准由 Unicode 联盟维护。每年都会发布标准的新版本(带有新的表情符号等)。Unicode 版本 1.0.0 于 1991 年 10 月发布。
19.1?码点与码元
了解 Unicode 的两个概念至关重要:
-
码点是表示 Unicode 文本的原子部分的数字。它们大多表示可见符号,但也可以具有其他含义,例如指定符号的某个方面(字母的重音,表情符号的肤色等)。
-
码元是编码码点的数字,用于存储或传输 Unicode 文本。一个或多个码元编码一个单个码点。每个码元的大小相同,取决于所使用的编码格式。最流行的格式 UTF-8 具有 8 位码元。
19.1.1?码点
Unicode 的第一个版本具有 16 位码点。从那时起,字符数量大大增加,码点的大小扩展到 21 位。这 21 位被分成 17 个平面,每个平面有 16 位:
-
平面 0:基本多语言平面(BMP),0x0000–0xFFFF
- 包含几乎所有现代语言的字符(拉丁字符,亚洲字符等)和许多符号。
-
平面 1:补充多语言平面(SMP),0x10000–0x1FFFF
-
支持历史书写系统(例如埃及象形文字和楔形文字)和其他现代书写系统。
-
支持表情符号和许多其他符号。
-
-
平面 2:补充表意文字平面(SIP),0x20000–0x2FFFF
- 包含额外的 CJK(中文,日文,韩文)表意文字。
-
平面 3-13:未分配
-
平面 14:补充特殊用途平面(SSP),0xE0000–0xEFFFF
- 包含标记字符和字形变体选择器等非图形字符。
-
平面 15-16:补充专用区域(S PUA A/B),0x0F0000–0x10FFFF
- 可供 ISO 和 Unicode 联盟之外的各方分配字符。未标准化。
飞机 1-16 被称为补充平面或星界平面。
让我们检查一些字符的码点:
> 'A'.codePointAt(0).toString(16)
'41'
> 'ü'.codePointAt(0).toString(16)
'fc'
> 'π'.codePointAt(0).toString(16)
'3c0'
> '🙂'.codePointAt(0).toString(16)
'1f642'
码点的十六进制数字告诉我们,前三个字符位于平面 0(在 16 位内),而表情符号位于平面 1。
19.1.2?编码 Unicode 码点:UTF-32,UTF-16,UTF-8
编码码点的主要方式有三种Unicode 转换格式(UTFs):UTF-32,UTF-16,UTF-8。每种格式的末尾数字表示其码元的大小(以位为单位)。
19.1.2.1?UTF-32(Unicode 转换格式 32)
UTF-32 使用 32 位来存储码元,从而每个码点对应一个码元。这种格式是唯一具有固定长度编码的格式;其他所有格式都使用不同数量的码元来编码单个码点。
19.1.2.2?UTF-16(Unicode 转换格式 16)
UTF-16 使用 16 位码元进行编码。它将码点编码如下:
-
BMP(Unicode 的前 16 位)存储在单个代码单元中。
-
星际平面:BMP 包括 0x10_000 个代码点。鉴于 Unicode 总共有 0x110_000 个代码点,我们仍然需要编码剩余的 0x100_000 个代码点(20 位)。BMP 有两个未分配代码点的范围,提供了必要的存储空间:
-
最重要的 10 位(领导代理):0xD800-0xDBFF
-
最不重要的 10 位(尾随代理):0xDC00-0xDFFF
-
换句话说,末尾的两个十六进制数字贡献了 8 位。但是,只有当 BMP 以以下两位数字对之一开头时,我们才能使用这 8 位:
-
D8, D9, DA, DB
-
DC, DD, DE, DF
每个代理都有 4 对可选,这就是剩下的 2 位来自的地方。
因此,每个 UTF-16 代码单元始终是一个领导代理、一个尾随代理或者编码 BMP 代码点。
这是 UTF-16 编码的两个示例代码点:
-
代码点 0x03C0(π)在 BMP 中,因此可以由单个 UTF-16 代码单元 0x03C0 表示。
-
代码点 0x1F642(
🙂)在星际平面中,由两个代码单元表示:0xD83D 和 0xDE42。
19.1.2.3?UTF-8(Unicode 转换格式 8)
UTF-8 具有 8 位代码单元。它使用 1-4 个代码单元来编码一个代码点:
| 代码点 | 代码单元 |
|---|---|
| 0000–007F | 0bbbbbbb (7 位) |
| 0080–07FF | 110bbbbb, 10bbbbbb (5+6 位) |
| 0800–FFFF | 1110bbbb, 10bbbbbb, 10bbbbbb (4+6+6 位) |
| 10000–1FFFFF | 11110bbb, 10bbbbbb, 10bbbbbb, 10bbbbbb (3+6+6+6 位) |
注:
-
每个代码单元的位前缀告诉我们:
-
它是一系列代码单元中的第一个吗?如果是,后面会跟随多少个代码单元?
-
它是一系列代码单元中的第二个或更后面的吗?
-
-
0000–007F 范围内的字符映射与 ASCII 相同,这导致与旧软件的一定程度的向后兼容。
三个例子:
| 字符 | 代码点 | 代码单元 |
|---|---|---|
| A | 0x0041 | 01000001 |
| π | 0x03C0 | 11001111, 10000000 |
🙂 | 0x1F642 | 11110000, 10011111, 10011001, 10000010 |
19.2?Web 开发中使用的编码:UTF-16 和 UTF-8
在 Web 开发中使用的 Unicode 编码格式有:UTF-16 和 UTF-8。
19.2.1?源代码内部:UTF-16
ECMAScript 规范在内部将源代码表示为 UTF-16。
19.2.2?字符串:UTF-16
JavaScript 字符串中的字符基于 UTF-16 代码单元:
> const smiley = '🙂';
> smiley.length
2
> smiley === '\uD83D\uDE42' // code units
true
有关 Unicode 和字符串的更多信息,请参阅§20.7“文本的原子:代码点、JavaScript 字符、图形簇”。
19.2.3?文件中的源代码:UTF-8
HTML 和 JavaScript 这些天几乎总是以 UTF-8 编码。
例如,这就是 HTML 文件通常现在的开头方式:
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
···
对于在 Web 浏览器中加载的 HTML 模块,标准编码也是 UTF-8。
19.3?图形簇 - 真正的字符
字符的概念一旦考虑到世界上各种不同的书写系统,就变得非常复杂。这就是为什么有几个不同的 Unicode 术语在某种程度上都意味着“字符”:代码点、图形簇、字形等。
在 Unicode 中,代码点是文本的一个原子部分。
然而,图形簇最接近于屏幕或纸张上显示的符号。它被定义为“文本的水平可分割单元”。因此,官方 Unicode 文件也称其为用户感知字符。需要一个或多个代码点来编码一个图形簇。
例如,德瓦纳加里语kshi由 4 个代码点编码。我们使用Array.from()将字符串拆分为具有代码点的数组(有关详细信息,请参阅§20.7.1“使用代码点”):
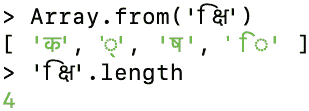
旗帜表情符号也是字形簇,由两个代码点组成 - 例如,日本的国旗:

19.3.1?字形簇 vs. 字形
符号是一个抽象概念,是书面语言的一部分:
-
它在计算机内存中由字形簇表示 - 一个或多个数字(代码点)的序列。
-
它通过字形在屏幕上绘制。字形是一种图像,通常存储在字体中。可以使用多个字形来绘制单个符号 - 例如,符号“é”可以通过组合字形“e”和字形“′”来绘制。
概念与其表示之间的区别是微妙的,在谈论 Unicode 时可能会变得模糊。
有关字形簇的更多信息
有关更多信息,请参阅 Manish Goregaokar 的“让我们停止将含义归因于代码点”。
测验
请参阅测验应用程序。
二十、字符串
原文:
exploringjs.com/impatient-js/ch_strings.html译者:飞龙
-
20.1?字符串速查表
-
20.1.1?处理字符串
-
20.1.2?JavaScript 字符 vs. 代码点 vs. 图形簇
-
20.1.3?字符串方法
-
-
20.2?普通字符串字面量
- 20.2.1?转义
-
20.3?访问 JavaScript 字符
-
20.4?通过
+进行字符串连接 -
20.5?转换为字符串
-
20.5.1?对象的字符串化
-
20.5.2?自定义对象的字符串化
-
20.5.3?值的另一种字符串化方式
-
-
20.6?比较字符串
-
20.7?文本的原子:代码点、JavaScript 字符、图形簇
-
20.7.1?使用代码点
-
20.7.2?使用代码单元(字符代码)
-
20.7.3?ASCII 转义
-
20.7.4?注意事项:图形簇
-
-
20.8?字符串快速参考
-
20.8.1?转换为字符串
-
20.8.2?文本原子的数值
-
20.8.3?
String.prototype: 查找和匹配 -
20.8.4?
String.prototype: 提取 -
20.8.5?
String.prototype: 组合 -
20.8.6?
String.prototype: 转换 -
20.8.7?来源
-
20.1?字符串速查表
字符串是 JavaScript 中的原始值,是不可变的。也就是说,与字符串相关的操作总是产生新的字符串,而不会改变现有的字符串。
20.1.1?处理字符串
字符串字面量:
const str1 = 'Don\'t say "goodbye"'; // string literal
const str2 = "Don't say \"goodbye\""; // string literals
assert.equal(
`As easy as ${123}!`, // template literal
'As easy as 123!',
);
反斜杠用于:
-
转义文字定界符(前一个示例的前两行)
-
表示特殊字符:
-
\\表示反斜杠 -
\n表示换行 -
\r表示回车 -
\t表示制表符
-
在 String.raw 标记模板中(A 行),反斜杠被视为普通字符:
assert.equal(
String.raw`\ \n\t`, // (A)
'\\ \\n\\t',
);
将值转换为字符串:
> String(undefined)
'undefined'
> String(null)
'null'
> String(123.45)
'123.45'
> String(true)
'true'
复制字符串的部分
// There is no type for characters;
// reading characters produces strings:
const str3 = 'abc';
assert.equal(
str3[2], 'c' // no negative indices allowed
);
assert.equal(
str3.at(-1), 'c' // negative indices allowed
);
// Copying more than one character:
assert.equal(
'abc'.slice(0, 2), 'ab'
);
连接字符串:
assert.equal(
'I bought ' + 3 + ' apples',
'I bought 3 apples',
);
let str = '';
str += 'I bought ';
str += 3;
str += ' apples';
assert.equal(
str, 'I bought 3 apples',
);
20.1.2?JavaScript 字符 vs. 代码点 vs. 图形簇
JavaScript 字符 大小为 16 位。它们是字符串中的索引和 .length 计数的内容。
代码点 是 Unicode 文本的原子部分。大多数代码点适合一个 JavaScript 字符,其中一些占据两个(特别是表情符号):
assert.equal(
'A'.length, 1
);
assert.equal(
'🙂'.length, 2
);
图形簇(用户感知的字符)代表书面符号。每个图形簇由一个或多个代码点组成。
因此,我们不应该将文本拆分为 JavaScript 字符,而应该将其拆分为图形簇。有关如何处理文本的更多信息,请参见§20.7 “文本的原子:代码点、JavaScript 字符、图形簇”。
20.1.3?字符串方法
本小节简要概述了字符串 API。本章末尾有更全面的快速参考。
查找子字符串:
> 'abca'.includes('a')
true
> 'abca'.startsWith('ab')
true
> 'abca'.endsWith('ca')
true
> 'abca'.indexOf('a')
0
> 'abca'.lastIndexOf('a')
3
拆分和连接:
assert.deepEqual(
'a, b,c'.split(/, ?/),
['a', 'b', 'c']
);
assert.equal(
['a', 'b', 'c'].join(', '),
'a, b, c'
);
填充和修剪:
> '7'.padStart(3, '0')
'007'
> 'yes'.padEnd(6, '!')
'yes!!!'
> '\t abc\n '.trim()
'abc'
> '\t abc\n '.trimStart()
'abc\n '
> '\t abc\n '.trimEnd()
'\t abc'
重复和更改大小写:
> '*'.repeat(5)
'*****'
> '= b2b ='.toUpperCase()
'= B2B ='
> 'ΑΒΓ'.toLowerCase()
'αβγ'
20.2?普通字符串字面量
普通字符串字面量由单引号或双引号括起来:
const str1 = 'abc';
const str2 = "abc";
assert.equal(str1, str2);
单引号更常用,因为它更容易提及 HTML,而 HTML 更喜欢双引号。
下一章涵盖了模板文字,它给我们提供了:
-
字符串插值
-
多行
-
原始字符串文字(反斜杠没有特殊含义)
20.2.1?转义
反斜杠让我们创建特殊字符:
-
Unix 换行符:
'\n' -
Windows 换行符:
'\r\n' -
制表符:
'\t' -
反斜杠:
'\\'
反斜杠还允许我们在字符串文字内部使用字符串文字的分隔符:
assert.equal(
'She said: "Let\'s go!"',
"She said: \"Let's go!\"");
20.3?访问 JavaScript 字符
JavaScript 没有额外的字符数据类型-字符始终表示为字符串。
const str = 'abc';
// Reading a JavaScript character at a given index
assert.equal(str[1], 'b');
// Counting the JavaScript characters in a string:
assert.equal(str.length, 3);
我们在屏幕上看到的字符称为图形簇。它们中的大多数由单个 JavaScript 字符表示。但是,还有一些图形簇(特别是表情符号)由多个 JavaScript 字符表示:
> '🙂'.length
2
这是在§20.7 “文本的原子:代码点、JavaScript 字符、图形簇”中解释的。
20.4?通过+进行字符串连接
如果至少有一个操作数是字符串,则加号运算符(+)将任何非字符串转换为字符串并连接结果:
assert.equal(3 + ' times ' + 4, '3 times 4');
赋值运算符+=在我们想要逐步组装字符串时非常有用:
let str = ''; // must be `let`!
str += 'Say it';
str += ' one more';
str += ' time';
assert.equal(str, 'Say it one more time');
 通过
通过+进行连接是有效的
使用+来组装字符串非常有效,因为大多数 JavaScript 引擎在内部对其进行了优化。
 练习:连接字符串
练习:连接字符串
exercises/strings/concat_string_array_test.mjs
20.5?转换为字符串
这是将值x转换为字符串的三种方法:
-
String(x) -
''+x -
x.toString()(对于undefined和null无效)
建议:使用描述性和安全的String()。
示例:
assert.equal(String(undefined), 'undefined');
assert.equal(String(null), 'null');
assert.equal(String(false), 'false');
assert.equal(String(true), 'true');
assert.equal(String(123.45), '123.45');
布尔值的陷阱:如果我们通过String()将布尔值转换为字符串,通常无法通过Boolean()将其转换回来:
> String(false)
'false'
> Boolean('false')
true
唯一返回false的字符串是空字符串。
20.5.1?字符串化对象
普通对象具有默认的字符串表示,这并不是非常有用:
> String({a: 1})
'[object Object]'
数组具有更好的字符串表示,但仍然隐藏了许多信息:
> String(['a', 'b'])
'a,b'
> String(['a', ['b']])
'a,b'
> String([1, 2])
'1,2'
> String(['1', '2'])
'1,2'
> String([true])
'true'
> String(['true'])
'true'
> String(true)
'true'
字符串化函数,返回它们的源代码:
> String(function f() {return 4})
'function f() {return 4}'
20.5.2?自定义对象的字符串化
我们可以通过实现toString()方法来覆盖对象的内置字符串化方式:
const obj = {
toString() {
return 'hello';
}
};
assert.equal(String(obj), 'hello');
20.5.3?字符串化值的另一种方法
JSON 数据格式是 JavaScript 值的文本表示。因此,JSON.stringify()也可以用于将值转换为字符串:
> JSON.stringify({a: 1})
'{"a":1}'
> JSON.stringify(['a', ['b']])
'["a",["b"]]'
警告是 JSON 仅支持null、布尔值、数字、字符串、数组和对象(它总是将其视为通过对象文字创建的)。
提示:第三个参数让我们可以切换到多行输出并指定缩进的数量-例如:
console.log(JSON.stringify({first: 'Jane', last: 'Doe'}, null, 2));
此语句产生以下输出:
{
"first": "Jane",
"last": "Doe"
}
20.6?比较字符串
字符串可以通过以下运算符进行比较:
< <= > >=
有一个重要的警告需要考虑:这些运算符基于 JavaScript 字符的数值进行比较。这意味着 JavaScript 用于字符串的顺序与字典和电话簿中使用的顺序不同:
> 'A' < 'B' // ok
true
> 'a' < 'B' // not ok
false
> '?' < 'b' // not ok
false
正确比较文本超出了本书的范围。它通过ECMAScript 国际化 API(Intl)支持。
20.7?文本的原子:代码点、JavaScript 字符、图形簇
§19 “Unicode – a brief introduction”的快速回顾:
-
代码点是 Unicode 文本的原子部分。每个代码点的大小为 21 位。
-
JavaScript 字符串通过 UTF-16 编码格式实现 Unicode。它使用一个或两个 16 位代码单元来编码单个代码点。
- 每个 JavaScript 字符(在字符串中索引)都是一个代码单元。在 JavaScript 标准库中,代码单元也被称为char codes。
-
字形簇(用户感知字符)表示屏幕或纸张上显示的书写符号。需要一个或多个代码点来编码单个字形簇。
以下代码演示了一个代码点包含一个或两个 JavaScript 字符。我们通过.length来计算后者:
// 3 code points, 3 JavaScript characters:
assert.equal('abc'.length, 3);
// 1 code point, 2 JavaScript characters:
assert.equal('🙂'.length, 2);
以下表格总结了我们刚刚探讨的概念:
| 实体 | 大小 | 通过编码 |
|---|---|---|
| JavaScript 字符(UTF-16 代码单元) | 16 位 | - |
| Unicode 代码点 | 21 位 | 1-2 个代码单元 |
| Unicode 字形簇 | 1 个或多个代码点 |
20.7.1 处理代码点
让我们探索一下 JavaScript 处理代码点的工具。
Unicode 代码点转义允许我们以十六进制(1-5 位数字)指定代码点。它产生一个或两个 JavaScript 字符。
> '\u{1F642}'
'🙂'
 Unicode 转义序列
Unicode 转义序列
在 ECMAScript 语言规范中,Unicode 代码点转义和Unicode 代码单元转义(我们稍后会遇到)被称为Unicode 转义序列。
String.fromCodePoint()将一个代码点转换为 1-2 个 JavaScript 字符:
> String.fromCodePoint(0x1F642)
'🙂'
.codePointAt()将 1-2 个 JavaScript 字符转换为一个代码点:
> '🙂'.codePointAt(0).toString(16)
'1f642'
我们可以迭代字符串,这将访问代码点(而不是 JavaScript 字符)。迭代在本书的后面有描述。一种迭代的方式是通过for-of循环:
const str = '🙂a';
assert.equal(str.length, 3);
for (const codePointChar of str) {
console.log(codePointChar);
}
// Output:
// '🙂'
// 'a'
Array.from()也是基于迭代和访问代码点的:
> Array.from('🙂a')
[ '🙂', 'a' ]
这使得它成为一个很好的计算代码点的工具:
> Array.from('🙂a').length
2
> '🙂a'.length
3
20.7.2 处理代码单元(char codes)
字符串的索引和长度是基于 JavaScript 字符的(由 UTF-16 代码单元表示)。
要以十六进制指定代码单元,我们可以使用一个Unicode 代码单元转义,其中恰好有四个十六进制数字:
> '\uD83D\uDE42'
'🙂'
我们可以使用String.fromCharCode()。Char code是标准库对代码单元的名称:
> String.fromCharCode(0xD83D) + String.fromCharCode(0xDE42)
'🙂'
要获取字符的 char code,请使用.charCodeAt():
> '🙂'.charCodeAt(0).toString(16)
'd83d'
20.7.3 ASCII 转义
如果一个字符的代码点低于 256,我们可以通过ASCII 转义来引用它,其中恰好有两个十六进制数字:
> 'He\x6C\x6Co'
'Hello'
(ASCII 转义的官方名称是十六进制转义序列 - 这是第一个使用十六进制数字的转义。)
20.7.4 注意事项:字形簇
在处理可能用任何人类语言书写的文本时,最好在字形簇的边界处拆分,而不是在代码点的边界处。
TC39 正在研究Intl.Segmenter,这是 ECMAScript 国际化 API 的一个提案,支持 Unicode 分段(沿着字形簇边界,单词边界,句子边界等)。
在该提案成为标准之前,我们可以使用几个可用的库之一(在网上搜索“JavaScript grapheme”)。
20.8 快速参考:字符串
20.8.1 转换为字符串
Tbl. 14 描述了各种值如何转换为字符串。
表 14:将值转换为字符串。
x | String(x) |
|---|---|
undefined | 'undefined' |
null | 'null' |
| boolean | false → 'false', true → 'true' |
| number | 例子:123 → '123' |
| bigint | 例子:123n → '123' |
| string | x(输入,不变) |
| symbol | 例子:Symbol('abc') → 'Symbol(abc)' |
| object | 可以通过,例如,toString() 进行配置 |
20.8.2 文本原子的数值
-
Char code:表示 JavaScript 字符的数字。JavaScript 对Unicode 代码单元的名称。
-
大小:16 位,无符号
-
将数字转换为字符串:
String.fromCharCode()^([ES1]) -
将字符串转换为数字:字符串方法
.charCodeAt()^([ES1])
-
-
代码点:表示 Unicode 文本的一个原子部分的数字。
-
大小:21 位,无符号(17 个平面,每个 16 位)
-
将数字转换为字符串:
String.fromCodePoint()^([ES6]) -
将字符串转换为数字:字符串方法
.codePointAt()^([ES6])
-
20.8.3?String.prototype: 查找和匹配
(String.prototype是存储字符串方法的地方。)
-
.endsWith(searchString: string, endPos=this.length): boolean^([ES6])如果字符串的长度为
endPos,则返回true,如果不是则返回false。> 'foo.txt'.endsWith('.txt') true > 'abcde'.endsWith('cd', 4) true -
.includes(searchString: string, startPos=0): boolean^([ES6])如果字符串包含
searchString则返回true,否则返回false。搜索从startPos开始。> 'abc'.includes('b') true > 'abc'.includes('b', 2) false -
.indexOf(searchString: string, minIndex=0): number^([ES1])返回字符串中
searchString出现的最低索引,否则返回-1。任何返回的索引都将是minIndex或更高。> 'abab'.indexOf('a') 0 > 'abab'.indexOf('a', 1) 2 > 'abab'.indexOf('c') -1 -
.lastIndexOf(searchString: string, maxIndex=Infinity): number^([ES1])返回字符串中
searchString出现的最高索引,否则返回-1。任何返回的索引都将是maxIndex或更低。> 'abab'.lastIndexOf('ab', 2) 2 > 'abab'.lastIndexOf('ab', 1) 0 > 'abab'.lastIndexOf('ab') 2 -
[1 of 2]
.match(regExp: string | RegExp): RegExpMatchArray | null^([ES3])如果
regExp是一个带有标志/g的正则表达式,则.match()返回字符串中regExp的第一个匹配项。如果没有匹配项则返回null。如果regExp是一个字符串,则在执行先前提到的步骤之前,用它创建一个正则表达式(类似于new RegExp()的参数)。结果具有以下类型:
interface RegExpMatchArray extends Array<string> { index: number; input: string; groups: undefined | { [key: string]: string }; }编号的捕获组成为数组索引(这就是为什么这种类型扩展了
Array)。命名捕获组(ES2018)成为.groups的属性。在此模式下,.match()的工作方式类似于RegExp.prototype.exec()。例子:
> 'ababb'.match(/a(b+)/) { 0: 'ab', 1: 'b', index: 0, input: 'ababb', groups: undefined } > 'ababb'.match(/a(?<foo>b+)/) { 0: 'ab', 1: 'b', index: 0, input: 'ababb', groups: { foo: 'b' } } > 'abab'.match(/x/) null -
[2 of 2]
.match(regExp: RegExp): string[] | null^([ES3])如果
regExp的标志/g被设置,.match()返回所有匹配项的数组,如果没有匹配项则返回null。> 'ababb'.match(/a(b+)/g) [ 'ab', 'abb' ] > 'ababb'.match(/a(?<foo>b+)/g) [ 'ab', 'abb' ] > 'abab'.match(/x/g) null -
.search(regExp: string | RegExp): number^([ES3])返回
regExp在字符串中出现的索引。如果regExp是一个字符串,则用它创建一个正则表达式(类似于new RegExp()的参数)。> 'a2b'.search(/[0-9]/) 1 > 'a2b'.search('[0-9]') 1 -
.startsWith(searchString: string, startPos=0): boolean^([ES6])如果
searchString在索引startPos处出现,则返回true。否则返回false。> '.gitignore'.startsWith('.') true > 'abcde'.startsWith('bc', 1) true
20.8.4?String.prototype: 提取
-
.slice(start=0, end=this.length): string^([ES3])返回字符串的子字符串,从索引
start(包括)开始,到索引end(不包括)结束。如果索引为负数,则在使用之前将其添加到.length(-1变为this.length-1等)。> 'abc'.slice(1, 3) 'bc' > 'abc'.slice(1) 'bc' > 'abc'.slice(-2) 'bc' -
.at(index: number): string | undefined^([ES2022])返回索引处的 JavaScript 字符作为字符串。如果
index为负数,则在使用之前将其添加到.length(-1变为this.length-1等)。> 'abc'.at(0) 'a' > 'abc'.at(-1) 'c' -
.split(separator: string | RegExp, limit?: number): string[]^([ES3])将字符串拆分为子字符串数组 - 出现在分隔符之间的字符串。分隔符可以是一个字符串:
> 'a | b | c'.split('|') [ 'a ', ' b ', ' c' ]它也可以是正则表达式:
> 'a : b : c'.split(/ *: */) [ 'a', 'b', 'c' ] > 'a : b : c'.split(/( *):( *)/) [ 'a', ' ', ' ', 'b', ' ', ' ', 'c' ]最后一个调用演示了正则表达式中的组捕获成为返回的数组的元素。
**警告:
.split('')将字符串拆分为 JavaScript 字符。**在处理星号代码点(编码为两个 JavaScript 字符)时效果不佳。例如,表情符号是星号的:> '🙂X🙂'.split('') [ '\uD83D', '\uDE42', 'X', '\uD83D', '\uDE42' ]相反,最好使用
Array.from()(或扩展):> Array.from('🙂X🙂') [ '🙂', 'X', '🙂' ] -
.substring(start: number, end=this.length): string^([ES1])使用
.slice()代替这个方法。.substring()在旧引擎中实现不一致,并且不支持负索引。
20.8.5?String.prototype: 组合
-
.concat(...strings: string[]): string^([ES3])返回字符串和
strings的连接。'a'.concat('b')等同于'a'+'b'。后者更受欢迎。> 'ab'.concat('cd', 'ef', 'gh') 'abcdefgh' -
.padEnd(len: number, fillString=' '): string^([ES2017])将(片段)
fillString附加到字符串,直到达到所需的长度len。如果它已经达到或超过len,则返回时不会有任何更改。> '#'.padEnd(2) '# ' > 'abc'.padEnd(2) 'abc' > '#'.padEnd(5, 'abc') '#abca' -
.padStart(len: number, fillString=' '): string^([ES2017])将(片段)
fillString前置到字符串,直到达到所需的长度len。如果它已经达到或超过len,则返回时不会有任何更改。> '#'.padStart(2) ' #' > 'abc'.padStart(2) 'abc' > '#'.padStart(5, 'abc') 'abca#' -
.repeat(count=0): string^([ES6])返回字符串,连接
count次。> '*'.repeat() '' > '*'.repeat(3) '***'
20.8.6?String.prototype: 转换
-
.normalize(form: 'NFC'|'NFD'|'NFKC'|'NFKD' = 'NFC'): string^([ES6])根据Unicode 规范化形式对字符串进行规范化。
-
[1 of 2]
.replaceAll(searchValue: string | RegExp, replaceValue: string): string^([ES2021]) 如果无法使用
如果无法使用.replaceAll()该怎么办如果在目标平台上不支持
.replaceAll(),则可以使用.replace()。如何使用在§43.6.8.1 “str.replace(searchValue, replacementValue)^([ES3])”中有解释。用
replaceValue替换所有匹配的searchValue。如果searchValue是一个没有标志/g的正则表达式,则会抛出TypeError。> 'x.x.'.replaceAll('.', '#') 'x#x#' > 'x.x.'.replaceAll(/./g, '#') '####' > 'x.x.'.replaceAll(/./, '#') TypeError: String.prototype.replaceAll called with a non-global RegExp argumentreplaceValue中的特殊字符是:-
$$: 变成$ -
$n: 变成编号为n的捕获组(遗憾的是,$0代表字符串'$0',它不是指完全匹配) -
$&: 变成完全匹配 -
`$``: 变成匹配前的所有内容
-
$': 变成匹配后的所有内容
示例:
> 'a 1995-12 b'.replaceAll(/([0-9]{4})-([0-9]{2})/g, '|$2|') 'a |12| b' > 'a 1995-12 b'.replaceAll(/([0-9]{4})-([0-9]{2})/g, '|$&|') 'a |1995-12| b' > 'a 1995-12 b'.replaceAll(/([0-9]{4})-([0-9]{2})/g, '|$`|') 'a |a | b'命名捕获组(ES2018)也受支持:
$<name>变成命名组name的捕获
示例:
assert.equal( 'a 1995-12 b'.replaceAll( /(?<year>[0-9]{4})-(?<month>[0-9]{2})/g, '|$<month>|'), 'a |12| b'); -
-
[2 of 2]
.replaceAll(searchValue: string | RegExp, replacer: (...args: any[]) => string): string^([ES2021])如果第二个参数是一个函数,则出现的地方将被它返回的字符串替换。它的参数
args是:-
matched: string。完全匹配 -
g1: string|undefined。编号为 1 的捕获组 -
g2: string|undefined。编号为 2 的捕获组 -
(等等)
-
offset: number。匹配在输入字符串中的位置? -
input: string。整个输入字符串
const regexp = /([0-9]{4})-([0-9]{2})/g; const replacer = (all, year, month) => '|' + all + '|'; assert.equal( 'a 1995-12 b'.replaceAll(regexp, replacer), 'a |1995-12| b');命名捕获组(ES2018)也受支持。如果有任何,最后会添加一个带有包含捕获的属性的对象的参数:
const regexp = /(?<year>[0-9]{4})-(?<month>[0-9]{2})/g; const replacer = (...args) => { const groups=args.pop(); return '|' + groups.month + '|'; }; assert.equal( 'a 1995-12 b'.replaceAll(regexp, replacer), 'a |12| b'); -
-
.replace(searchValue: string | RegExp, replaceValue: string): string^([ES3]) -
.replace(searchValue: string | RegExp, replacer: (...args: any[]) => string): string^([ES3]).replace()的工作方式类似于.replaceAll(),但如果searchValue是字符串或没有/g的正则表达式,则只替换第一次出现:> 'x.x.'.replace('.', '#') 'x#x.' > 'x.x.'.replace(/./, '#') '#.x.'有关此方法的更多信息,请参见§43.6.8.1 “
str.replace(searchValue, replacementValue)^([ES3])”。 -
.toUpperCase(): string^([ES1])返回字符串的副本,其中所有小写字母都转换为大写。这对各种字母表的工作效果取决于 JavaScript 引擎。
> '-a2b-'.toUpperCase() '-A2B-' > 'αβγ'.toUpperCase() 'ΑΒΓ' -
.toLowerCase(): string^([ES1])返回字符串的副本,其中所有大写字母都转换为小写。这对各种字母表的工作效果取决于 JavaScript 引擎。
> '-A2B-'.toLowerCase() '-a2b-' > 'ΑΒΓ'.toLowerCase() 'αβγ' -
.trim(): string^([ES5])返回字符串的副本,其中所有前导和尾随空白(空格、制表符、行终止符等)都消失了。
> '\r\n#\t '.trim() '#' > ' abc '.trim() 'abc' -
.trimEnd(): string^([ES2019])类似于
.trim(),但只修剪字符串的末尾:> ' abc '.trimEnd() ' abc' -
.trimStart(): string^([ES2019])类似于
.trim(),但只修剪字符串的开头:> ' abc '.trimStart() 'abc '
20.8.7?来源
练习:使用字符串方法
exercises/strings/remove_extension_test.mjs
测验
查看测验应用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Pika Labs】图片&想法转视频-使用教程
- setattr()函数的理解
- 从零构建属于自己的GPT系列5:模型部署1(文本生成函数解读、模型本地化部署、文本生成文本网页展示、代码逐行解读)
- 分布式技术之分布式共享状态调度架构
- 自动化测试时基于Python常用的几个加密算法实现,你有用到吗?
- CF457C Elections 题解 二分
- jvm内存模型
- 亚信安慧AntDB数据库容灾复制原理
- opencv期末练习题(8)附带解析
- APP端网络测试与弱网模拟!