模型性能评估-混淆矩阵简介
发布时间:2023年12月25日
混淆矩阵
- Positive § - 正例
- Negative (N) - 负例
结果:
预测为正类别 预测为负类别
真实为正类别 True Positive (TP) False Negative (FN)
真实为负类别 False Positive (FP) True Negative (TN)
- TP - 预测 P, 实际 P, 模型预测正确
- FP - 预测 P, 实际 N, 模型预测错误
- FN - 预测 N, 实际 P, 模型预测错误
- TN - 预测 N, 实际 N, 模型预测正确
指标
- 准确率(Accuracy) - 判断模型正确分类的能力.
(TP + TN) / (TP + TN + FP + FN) - 精确率(Precision)- 判断模型识别出来的结果有多精确的指标.
TP / (TP + FP) - 召回率(Recall)- 查全率, 判断模型识别广度的指标.
TP / (TP + FN) - F1 值 - 综合反应 精确率 和 召回率, 越高越好
2 * Precision * recall / (precision + recall)
精确率说明找到的 P 有多少是对的.
召回率说明所有的 P 中找到了多少个.
总结:

-
准确率:理解成本最低,但不要滥用。在样本不均衡情况下,指标结果容易出现较大偏差;
-
精确率:用于关注筛选结果是不是正确的场景,宁可没有预测出来,也不能预测错了。 比如,在刷脸支付的场景下,我们宁可告诉用户检测不通过,也不能让另外一个人的人脸通过检测;
-
召回率:用于关注筛选结果是不是全面的场景,“宁可错杀一千,绝不放过一个”。 比如,在信贷场景下,我要控制逾期率,所以宁可把好用户拦在外面,不让他们贷款,也不能放进来一个可能逾期的用户。毕竟,用户一旦逾期,无法收回的本金产生的损失,比我多放过几个好用户带来的收益要多很多。
-
KS
-
AUC
基础指标:
- TPR(True Positive Rate)真正率 - 评估模型正确预测的能力.
TP / (TP + FN) - FPR(False Positive Rate)假正率 - 评估模型误判的比率或者误伤的比率.
FP / (FP + TN)
ROC 曲线
在没有准确阈值的情况下,对所有分数进行分段处理,计算每一个切分点对应的TPR和FPR,以FPR做横轴、TPR做纵轴绘制出的一条曲线。
ROC代表的是模型召回率和误伤率之间的变化关系
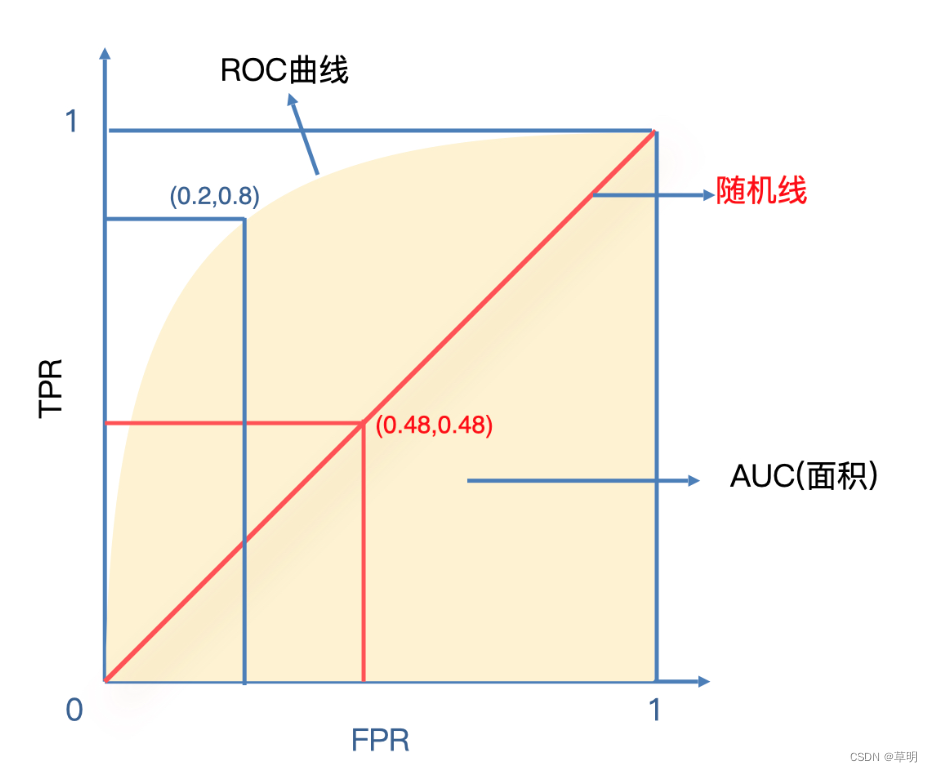
红线是随机线.
模型的ROC曲线越贴近这条随机线,模型的分类效果就越差。
当ROC曲线越偏离随机线并且靠近左上方(0,1)点的时候,说明模型分类效果越好.
AUC
AUC: 把曲线右下方和横坐标轴闭合起来的面积作为一个评估指标。
AUC 一般在 0.5 到 1 之间.
AUC = 0.5- 表示模型没有区分能力, 结果等于是随机猜测AUC < 0.5- 表示这个模型大概率很差AUC > 0.5 && AUC < 1- AUC 越高代表模型的区分能力越好
KS
KS 统计量是一种衡量累积分布函数(Cumulative Distribution Function,CDF)差异的指标。
KS代表的是在某一点上,模型召回率最大并且误伤率最小。
把召回率和误伤率都作为纵轴,把切分的分数点作为横轴。
一个切分点会同时得到TPR和FPR两个值,所以可以画出来两条曲线。

KS就是图中红色线和绿色线间隔最大时候的距离。
如果模型的KS或者AUC值很高,不一定是一件好事情。需要了解背后的原因,这有可能是数据不准确导致的。
文章来源:https://blog.csdn.net/galoiszhou/article/details/135189460
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 小程序常用实用例子
- Vue3使用高德地图,自定义InfoWindow窗口
- Windows下Tomcat内存占用过高问题跟踪(ProcessExplorer+jstack)
- 2024第一篇: 架构师成神之路总结,你值得拥有
- MyBatisPlus最新的3.5.2以上的代码生成器
- mysql基础演练
- NeRF 其二:Mip-NeRF
- CentOS 7 制作openssh 9.6 rpm包更新修复安全漏洞 —— 筑梦之路
- 记一次 .NET某工控 宇宙射线 导致程序崩溃分析
- fastadmin新增头部成为师傅按钮,批量更新用户为师傅