毫无基础的人如何入门 Python ?

一、写在前面
其实不止是 Python,任何学习都会遇到这么几个难点
- 迷茫,对于学习过程中,对新的、未知的概念欠缺了解;
- 彷徨,没有目的性的学习,不知道学完之后可以怎么用;
- 乏力,知道很重要,缺乏完整的知识体系,怎么都感觉没有学好;
- 无知,学习后觉得自己可以了,用到实际的时候依然不知所以然;
首先,不能不说的一点,学习python,一开始不要想着和数据分析有什么关系,而是了解完python可以做什么,再去想想哪些过程能应用到这些功能,解决什么问题;更不要想着和数学有什么关系,撇开其他不谈,python也是一门程序语言,和C、C++、VBA、R语言并没有什么区别,用类别的方式进行学习,事半功倍!
以下是一些可以去做检索的关键词,利用好百度、Google、知乎、CSDN、Stackoverflow、github,可以很好的进行自我学习;
11~13年的时候python学习的社区还不成熟,躺了无数多个坑。发展到现在,有特别多的在线课程可以跟着学习,站在前人的基础上进行翱翔。可以跟着循循渐进的进行学习,在理论知识、工具介绍、模块拆解、语法讲解上都有特别细的说明,也可以根据自己的目标去选择性学习(提高办公效率、高逼格分析可视化、算法实践),把知识嵌入到实际项目中去!
二、塑造清晰的认知(解决迷茫)
对于python学习来说,没有具体场景、数据的支撑,看了书、看了视频、看了课程,学完之后依然觉得很难应用,绝大多数情况下是因为只看了浅层的知识介绍,忽略了原有知识体系和本我工作的锲合度。
2.1 了解和认识Python的应用范围
应用1:利用python进行数据分析;
场景:替换原来在Excel中的函数统计、绘图的过程,对分析过程中的数据进行聚合处理,直接利用python相应的库进行分析结果呈现,实现多因素的可视化呈现,增加数据的可读性;

应用2:python爬虫;
场景:这应该是绝大多数初学者最容易上手的切入点,也应该是最感兴趣的一个点,通过爬虫去做数据采集,模拟业务场景去进行数据探索分析,必不可少的要去了解HTML的构成、元素、框架和规则; 然后就是爬图片、爬视频、爬评论,git上最经典的一个案例就是豆瓣、 但是爬虫有风险,一定要关注法律,不要因小失大!!! 参考链接:github地

应用3:机器学习和深度学习;
场景:在信息化程度比较高的企业,往往会有大数据算法分析应用的场景,利用sklearn提供的算法能力,可以快速建立模型,实现预测、分类、聚类、回归等目的;

应用4:Web应用开发;
当了解到python可以搭建网站的时候,跟着刘江老师的博客,手把手复刻了一个项目,利用django做了一个可视化系统,出来的效果如下图;同样的,还有flask的案例;

应用5:自动化测试和运维;
自动化的运维,省时省力省心,凡是能够自动化的过程,都可以在过程中有效的进行优化(偷懒) 关于nginx的开源网站介绍,一些开源项目可以直接拿来部署应用的项目情况,gitee

应用6:……
2.2?了解和认知Python的运行平台
工具1:IDLE;
IDLE是python自带的一个编辑器,相当简洁,简洁到简陋的地步;当安装好python之后,就伴生存在了,不需要再做额外的动作,基本功能有语法加亮、段落缩进、基本文本编辑、TABLE键控制、调试程序。

工具2:CMD and 终端命令行;
学习python过程中的一大阻力!!!尤其是对计算机系统并不是那么熟悉的同学,但是不得不去克服这种困难,在后续的学习过程中可能需要通过终端的命令来进行库的安装、查看,尤其是要做定时运行的时候。 windows下:win+R,输入CMD;mac下:直接打开终端;

工具3:Pycharm;
一开始有点难用,都是纯E的菜单、信息,但是它的诸多功能都特别实用,语法高亮、提示、补全、运行预览,而且安装包比较方便,属于熟悉之后就离不开的那种;

工具4:Anaconda;
naconda是最省心的一个平台工具,一站式解决了python安装、库安装的问题,直接集成了多个GUI的应用,并且提供了比较好的节目进行脚本开发;

工具5:Jupyterlab / Jupyter Notebook;
实现网页版的交互式脚本撰写,支持Markdown格式,在做数据探索的时候,顺便生成一份分析报告;

工具6:iPython;
python 的交互式 shell,比默认的python shell 好用得多,支持变量自动补全,自动缩进,支持 bash shell 命令,内置了许多很有用的功能和函数。 在cmd命令行窗口直接输入ipython,得到如下界面:

工具7:Spyder;?适合科学计算,界面和 Rstudio类似,可以逐行调试;

2.3 了解和认知Python的基础知识
python基础知识就不展开了,在很多基础知识的网站上都会有介绍,在学习之初,最重要的几个概念理解清楚,然后不断的去发散。 知识1:pip; 知识2:import库操作; 知识3:文件读写; 知识4:pyhon的常用库及解决什么问题; 知识5:python2.x和python3.x的区别
三、建立明确的目标(消除彷徨)
在不同应用范围下,对相关的库所需要了解和掌握的程度差异略大,本质上是工作类别的差异性。 以数据分析岗为例,对于python的学习,可以集中在以下一些库上:
3.1 文件类
os——学习Python最优先看的应该就是os包,对文件夹、文件进行操作:
3.2 数据计算类
Pandas——像用Excel一样对数据进行统计分析; Numpy——拥有大量的计算函数,可以进行矩阵计算; Scipy——用于数学、科学、工程领域的常用软件包;
3.3?Python绘图类
Matplotlib——绘图必备,可以和seaborn结合一起,绘制出和ggplot风格的图; Pyecharts——百度可视化的开源库,可以做出丰富的JS图表;

3.4?交互类
Openpyxl——Python和Excel的交互包,可以对Excel进行操作; Pymysql——Python和mysql的交互包,直接连到数据库获取数据源;
3.5 文本处理类
re——必须要学会的正则表达式,对于文本处理有非常好的用途; json——非结构式的key:value数据处理;
四、构建完整的体系(丢掉乏力)
为什么要去构建知识体系?让知识有层次、有结构、有深浅。参考一本书的目录,从浅入深的做好知识沉淀; 脱离于认知期和熟悉期之后,对于python能够实现的功能有了大概的了解,能够定向的去解决一些问题,用来用去也就那么几个方法。这时候,就需要对所用的包有一个具体的了解,而且一定要围绕自己学习的重点来展开,
4.1?官网的知识地图(以pandas为例)
参考一下官网的知识结构梳理:?语法 - 数据整理 - 数据重塑 - 行列操作 - 数据统计用法 - 缺失值处理 - 数据集合并 - 数据分组 - 绘图呈现


可以按照这个思路对所用的库进行拆解,能够有更清晰的认知,针对某一场景的时候,可以用多个不同的方法进行解决,以及如何高效的进行解决!
4.2?用Xmind构建知识树(adaboost)
参考一本书的目录,从浅入深的做好知识沉淀; 譬如:

知识体系的构建,不是一朝一夕的事情,需要依赖长时间的经验沉淀,根据自己对知识的掌握,绘制一些知识树,把python可解决的一些能力具象出来。
五、完善场景的练习(不要无知)
刻意练习,不能闭门造车!!! 从实际的业务场景中进行需求提炼,把场景和python学习结合在一起,基于需求的学习可以事半功倍。 我用python主要是还是用在数据分析上,从数据采集、清洗、处理、建模、结果、可视化、汇报的流程链路上,用不同的库分别解决各自的问题,实现效率的提升。在这个过程里面,需要结合大量的数理知识、算法知识、设计理念来把事情串起来。可以把数据场景和Python的库进行一一对应,也可以进行对比学习,把所有Excel处理的场景通过Python进行复现,然后逐步的去Excel化!?1.基础 -> 2.统计 -> 3.编程 -> 4.机器学习 -> 5.NLP -> 6.可视化 -> 7.大数据 -> 8.资料撷取 -> 9.数据清洗 -> 10.工具箱
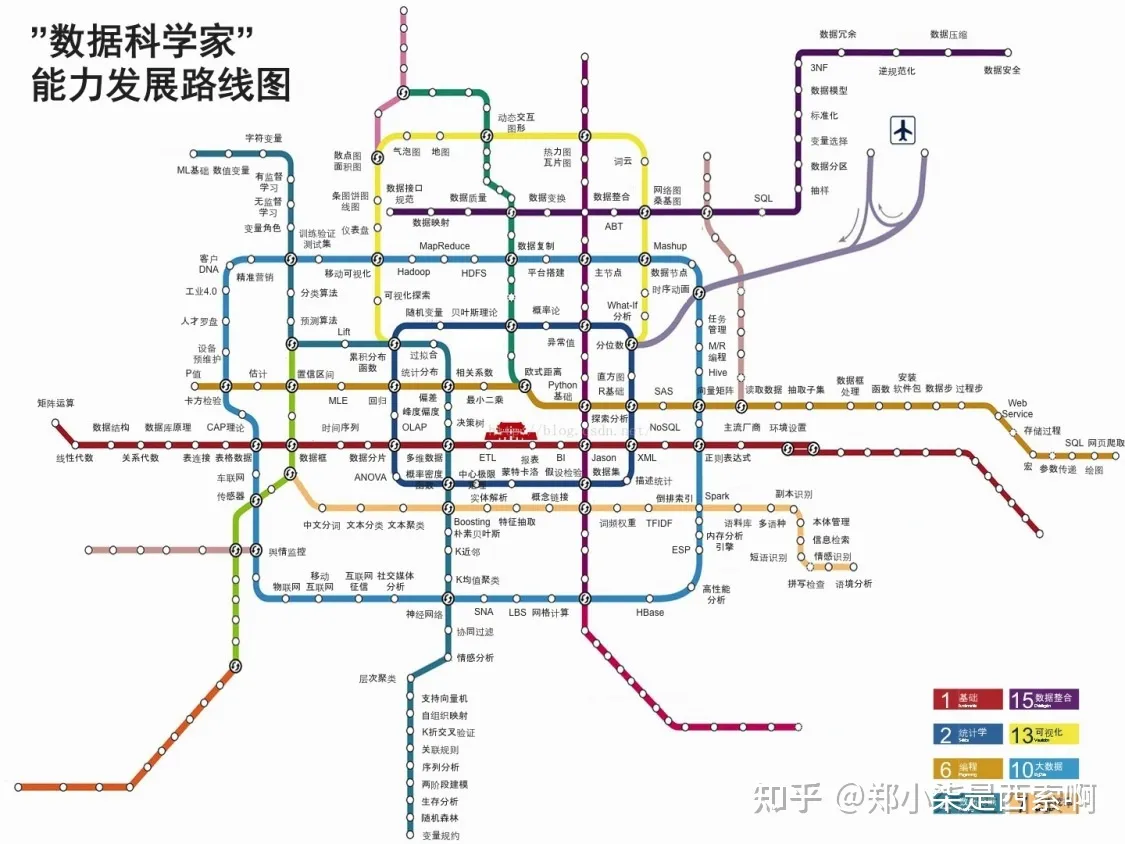
python是工具,工具即利器,磨刀不误砍柴工,把工具研究透彻,就能在实际的项目上大刀阔斧,而不是临阵磨枪,乱了阵脚。 碰到问题解决问题,建立自己的一套问题词库,在碰到困难的饿时候,可以优先通过平台搜索解决很大一部分问题,问题解决的优先级:?搜索引擎 > 厉害的知识博主 > 周边的大牛 > 较早学习的前辈 > 视频课程 > 书籍;
六、写在最后
在学习的路上,就是一个塑造自我认知的过程,一定要清晰,且明朗,知之为知之,把每一个概念理解清楚,扩散的知识点了解清楚,在碰到问题的时候就会游刃有余,而不是不知所措。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!