数据操作——缺失值处理
缺失值处理
缺失值的处理思路
如果想探究如何处理无效值, 首先要知道无效值从哪来, 从而分析可能产生的无效值有哪些类型, 在分别去看如何处理无效值
-
什么是缺失值
一个值本身的含义是这个值不存在则称之为缺失值, 也就是说这个值本身代表着缺失, 或者这个值本身无意义, 比如说 null, 比如说空字符串
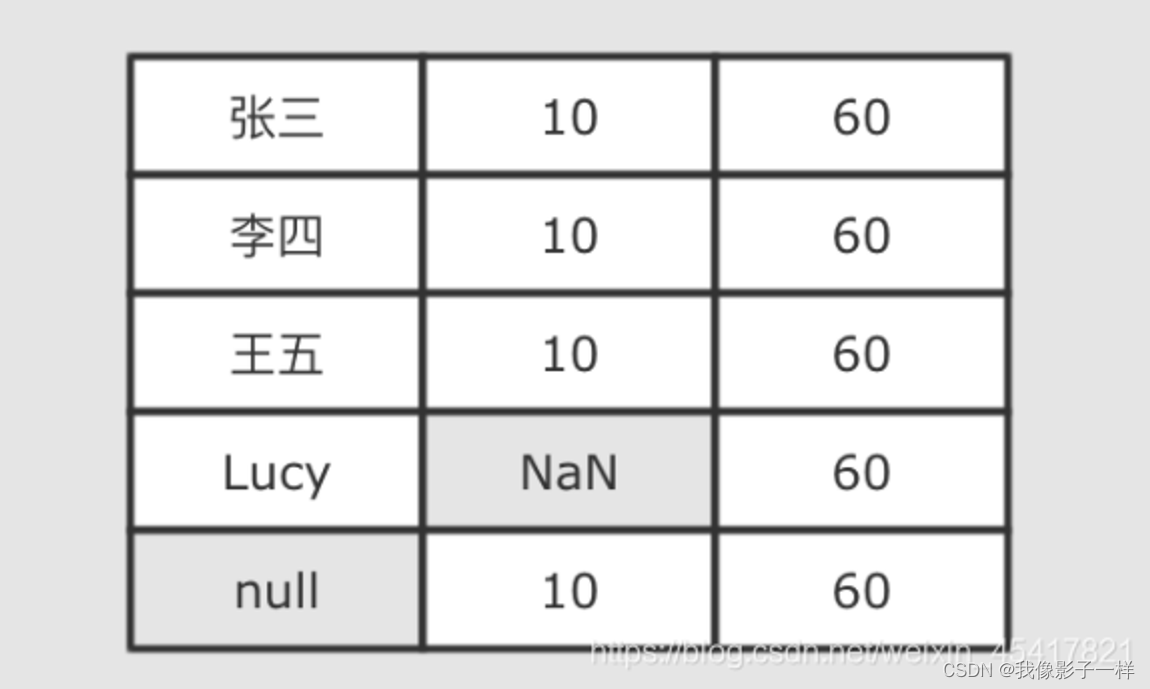
关于数据的分析其实就是统计分析的概念, 如果这样的话, 当数据集中存在缺失值, 则无法进行统计和分析, 对很多操作都有影响
-
缺失值如何产生的
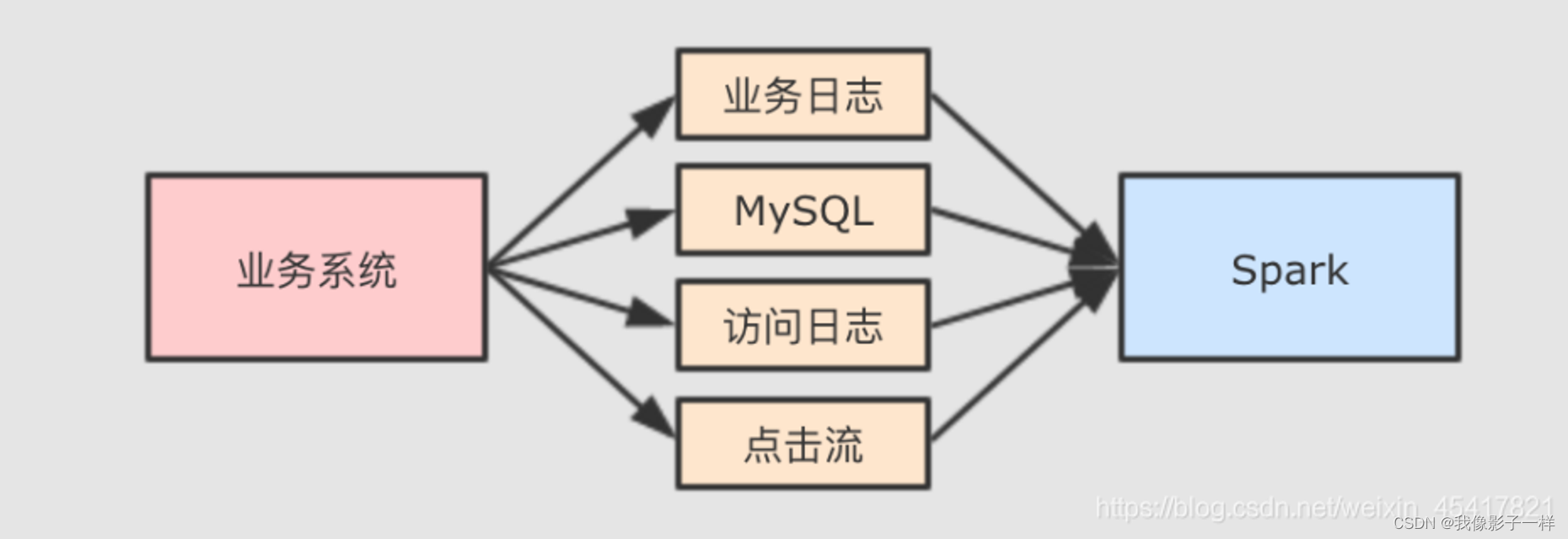
Spark 大多时候处理的数据来自于业务系统中, 业务系统中可能会因为各种原因, 产生一些异常的数据
例如说 因为前后端的判断失误, 提交了一些非法参数. 再例如说因为业务系统修改 MySQL 表结构产生的一些空值数据等. 总之在业务系统中出现缺失值其实是非常常见的一件事, 所以大数据系统就一定要考虑这件事.
-
缺失值的类型
常见的缺失值有两种
-
null, NaN 等特殊类型的值, 某些语言中 null 可以理解是一个对象, 但是代表没有对象, NaN 是一个数字, 可以代表不是数字
针对这一类的缺失值, Spark 提供了一个名为 DataFrameNaFunctions 特殊类型来操作和处理
-
“Null”, “NA”, " " 等解析为字符串的类型, 但是其实并不是常规字符串数据
针对这类字符串, 需要对数据集进行采样, 观察异常数据, 总结经验, 各个击破
-
-
DataFrameNaFunctions
DataFrameNaFunctions 使用 Dataset 的 na 函数来获取
val df = ... val naFunc: DataFrameNaFunctions = df.na当数据集中出现缺失值的时候, 大致有两种处理方式, 一个是丢弃, 一个是替换为某值, DataFrameNaFunctions 中包含一系列针对空值数据的方案
- DataFrameNaFunctions.drop 可以在当某行中包含 null 或 NaN 的时候丢弃此行
- DataFrameNaFunctions.fill 可以在将 null 和 NaN 充为其它值
- DataFrameNaFunctions.replace 可以把 null 或 NaN 替换为其它值, 但是和 fill 略有一些不同, 这个方法针对值来进行替换
-
如何使用 SparkSQL 处理 null 和 NaN(Double.NaN → Not a number) ?
首先要将数据读取出来, 此次使用的数据集直接存在 NaN, 在指定 Schema 后, 可直接被转为 Double.NaN
@Test def nullAndNaN():Unit ={ // 2. 导入数据集 // 3. 读取数据集 // 1.通过Spark-csv自动的推断类型来读取,推断数字的时候会将NaN推断为字符串 // spark.read // .option("header",true) // .option("inferSchema",true) // .csv(....) // 2. 直接读取字符串,在后续的操作中使用 map 算子转类型 // spark.read.csv().map(row => row....) // 3. 指定 Schema ,不要自动推断 // 创建 Schema val schema = StructType( List( StructField("id", LongType), StructField("year", IntegerType), StructField("month", IntegerType), StructField("day", IntegerType), StructField("session", IntegerType), StructField("pm", DoubleType) ) ) // Double.NaN val sourceDF = spark.read .option("header",true) .schema(schema) .csv("./dataset/beijingpm_with_nan.csv") // pm下的NaN 自动转为 Double.NaN sourceDF.show() }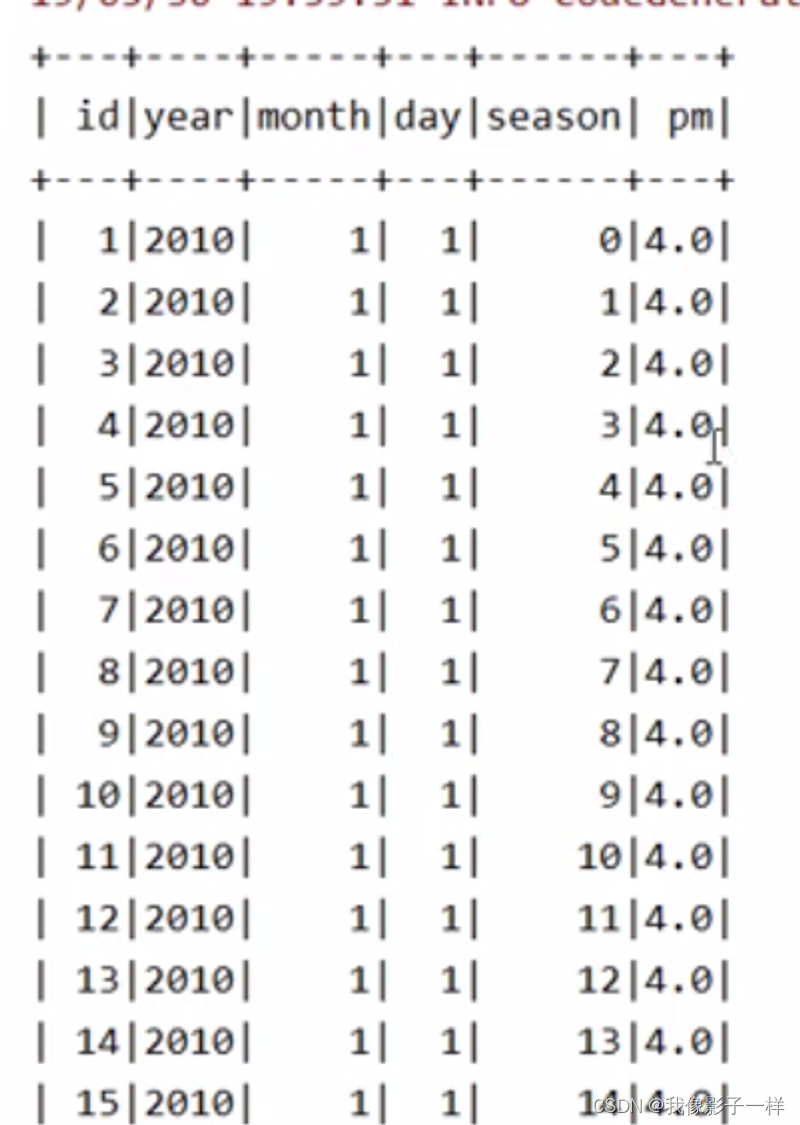
对于缺失值的处理一般就是丢弃和填充
-
丢弃包含 null 和 NaN 的行
// 4.丢弃 // 2019,12,12,Nam // 规则: // 1. any, 只要有一个 NaN 的行就丢弃 sourceDF.na.drop("any").show() // sourceDF.na.drop().show() 默认 any // 2. all, 所有数据都是 NaN 的行才丢弃 sourceDF.na.drop("all").show() // 3. 某些列的规则 sourceDF.na.drop("any",List("year","month","day")).show()** -
填充包含 null 和 NaN 的列
**// 5.填充 // 规则: // 1. 针对所有列数据进行默认值填充 sourceDF.na.fill(0).show() // 2. 针对特定列填充 sourceDF.na.fill(0, List("year", "month")).show() }**
-
-
如何使用 SparkSQL 处理异常字符串 ?
读取数据集, 这次读取的是最原始的那个 PM 数据集
**val df = spark.read .option("header", value = true) .csv("./dataset/BeijingPM20100101_20151231.csv")**使用函数直接转换非法的字符串
**// 1. 替换 // select name, age, case // when .. then... // else import org.apache.spark.sql.functions._ // 使用when 需要导入 sourceDF.select( 'No as "id", 'year, 'month, 'day, 'hour, 'season, when('PM_Dongsi === "NA", Double.NaN) // 当 PM_Donsi 里的数据 等于 NA 时,变为 Double.NaN .otherwise('PM_Dongsi cast DoubleType) // 如果不是上面的条件,要将它的正常值转换成对应的Double类型 .as("pm") // 起别名 ).show() // replace 注意:原类型和转换过后的类型,必须一致 sourceDF.na.replace("PM_Dongsi", Map("NA" -> "NaN")).show() // sourceDF.na.replace("PM_Dongsi", Map("NA" -> "NaN", "NULL" -> "null")).show()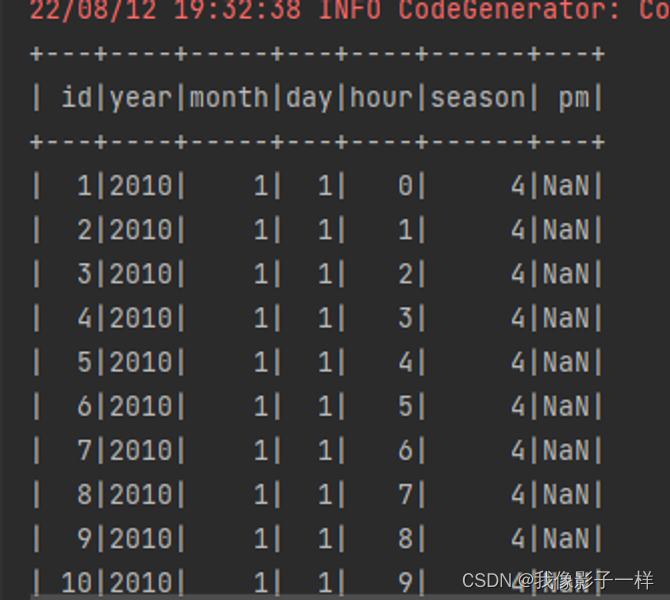
使用 where 直接过滤
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season, 'PM_Dongsi) .where('PM_Dongsi =!= "NA") // =!= 不等于 .show()
-
所用文件
[beijingpm_with_nan.rar]
[BeijingPM20100101_20151231.rar](前面已上传,自己根据名称去资源下载)
-
以上代码的前置条件
// 1. 创建SparkSession对象 val spark = SparkSession.builder().appName("column").master("local[6]").getOrCreate() import spark.implicits._ case class Person(name: String, age: Int)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!