Scrapy 爬取壁纸

先看看壁纸爬取的结果,这是动漫部分壁纸,总共有几个分类。
本次爬取其实只需要了解两个基础知识点即可:
本文爬取的网站是 彼岸网图,初看觉得网站反爬等安全处理不是很到位,较容易爬取,希望大家以学习为目的,也希望作者能加强反爬等安全措施,现在能爬,随着网站服务升级以后不一定能爬 。
注:彼岸图网为用户免费分享产生,请勿用于商业用途!
分析网站
下一页跳转链接
分页显示,通过打开过个页面观察 URL很容易知道他的分页就是 URL 上跟随页数(index)变化,这样通过 URL 拼接分别请求不同页数。这里就以动漫壁纸分类为例:
动漫壁纸:只有首页没有 index 是个特例
https://pic.netbian.com/4kdongman/
https://pic.netbian.com/4kdongman/index_2.html
https://pic.netbian.com/4kdongman/index_3.html
https://pic.netbian.com/4kdongman/index_4.html
假设,通过页面 URL 请求拿到了本页的 html 文本数据,接下来是解析当前页面获得图片信息(图片地址、跳转地址,文字描述等)。
class ImageListInfoItem(scrapy.Item):
# 图片地址,缩略图
img_src = scrapy.Field()
# 图片的一些其他信息,如标题、描述
img_alt = scrapy.Field()
img_href = scrapy.Field()
img_desc = scrapy.Field()
# 点击图片详情页
img_detail_url = scrapy.Field()
图片下载地址
检查元素,复制 xpath,可直接上手爬取~
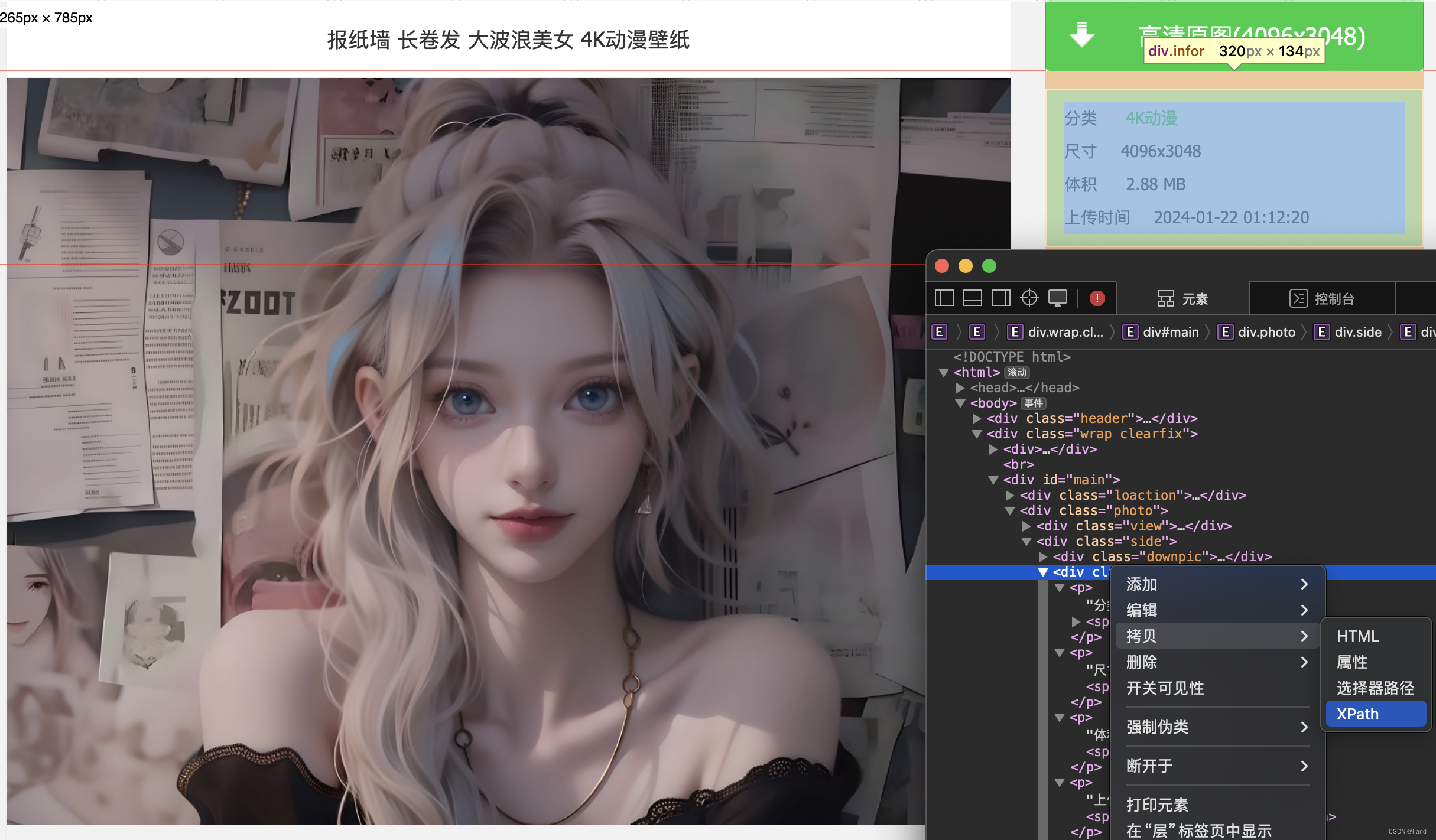
class ImageDetailInfoItem(scrapy.Item):
# 图片标题:报纸墙 长卷发 大波浪美女 4K动漫壁纸
img_title = scrapy.Field()
# 图片下载地址
img_src = scrapy.Field()
# 图片大小:2.88MB
img_size = scrapy.Field()
# 上传时间:2024-01-22 01:12:20
img_time = scrapy.Field()
# 图片尺寸:4096x3048
img_dimension = scrapy.Field()
# 图片分类:4k动漫
img_type = scrapy.Field()
开始爬取
scrapy?
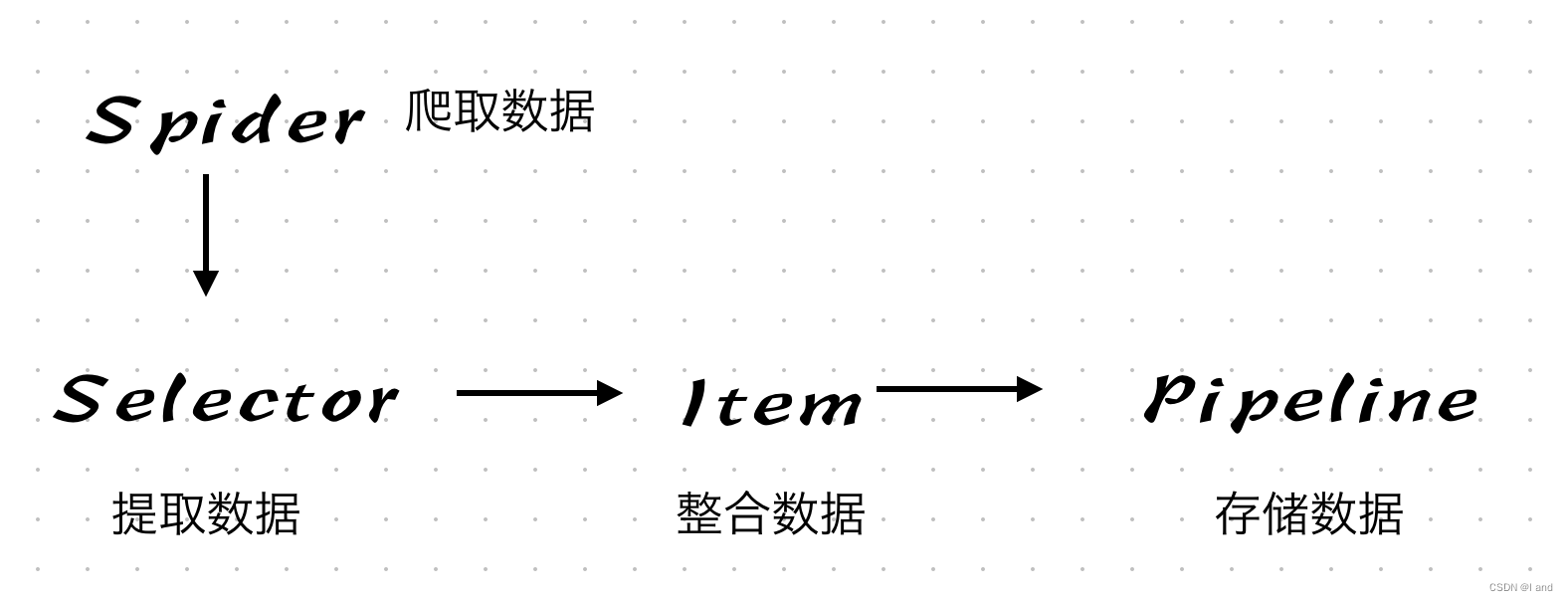
Spider:是用户自定义的类,定义爬取逻辑,包括开始请求的 URL、如何解析响应内容、提取数据或生成新的请求等。
Selectors:内置了基于 XPath 和 CSS 选择器的方法,用来从 HTML 或 XML 文档中提取数据。
Item:一种数据容器,用于表示爬取到的数据条目,是一个 Python 字典子类,具有预定义的字段名和类型,便于组织和持久化爬取结果。
Pipeline:是一组可自定义的组件,负责处理 Spider 抓取到的 Item。这些组件按顺序执行,可以实现对 Item 的清洗、验证、去重、存储等。
这几个是本文用到的,需深入了解还需查阅官方文档比较好,下面列举获取动漫壁纸为例。
Spider
获取动漫壁纸每一页数据:
import json
import os
from typing import Any
import scrapy
from scrapy.http import Response
from wallpaper.items import ImageListInfoItem
# 动漫壁纸
# https://pic.netbian.com/4kdongman/
# https://pic.netbian.com/4kdongman/index_2.html
# https://pic.netbian.com/4kdongman/index_3.html
# https://pic.netbian.com/4kdongman/index_4.html
class DongmanImageListSpider(scrapy.Spider):
name = "dongman_image_list_spider"
def start_requests(self):
start_page_index = 2
end_page_index = 133
for page_index in range(start_page_index, end_page_index):
url = "https://pic.netbian.com/4kdongman/index_" + str(page_index) + ".html"
yield scrapy.Request(url=url, callback=self.parser_dongman_image_list_info)
# 测试
break
# 图片列表数据
def parser_dongman_image_list_info(self, response: Response):
xpath_selector = scrapy.Selector(text=response.text)
lu_li_a_elements = xpath_selector.xpath(
'//*[@id="main"]/div[3]/ul[@class="clearfix"]//li//a'
).getall()
for a_tag in lu_li_a_elements:
a_selector = scrapy.Selector(text=a_tag)
a_href = a_selector.xpath("//a/@href").get()
img_src = a_selector.xpath("//a//img/@src").get()
img_alt = a_selector.xpath("//a//img/@alt").get()
b_text = a_selector.xpath("//a//b/text()").get()
baseUrl = "https://pic.netbian.com"
info = ImageListInfoItem()
info["img_href"] = a_href
info["img_src"] = baseUrl + img_src
info["img_alt"] = img_alt
info["img_desc"] = b_text
info["img_detail_url"] = baseUrl + a_href
yield info
获取每一个图片详细信息:
import json
import os
from typing import Any
import scrapy
from scrapy.http import Response
from wallpaper.items import ImageDetailInfoItem
class DongmanImageDetailSpider(scrapy.Spider):
name = "dongman_image_detail_spider"
def start_requests(self):
current_dir = os.getcwd()
dongman_file_path = os.path.join(
current_dir, "data/dongman_image_list_spider.jl"
)
with open(dongman_file_path, "r", encoding="utf-8") as f:
for line in f:
if line == None or len(line.split()) == 0:
continue
json_dict = json.loads(line.strip())
img_detail_url = json_dict["img_detail_url"]
print("img_detail_url ====" + img_detail_url)
yield scrapy.Request(
url=img_detail_url, callback=self.parser_dongman_image_detail_info
)
# 测试
break
# 解析页面详情
def parser_dongman_image_detail_info(self, response: Response):
if response.text is None:
return
pageDetailInfo = ImageDetailInfoItem()
xpath_selector = scrapy.Selector(text=response.text)
title = xpath_selector.xpath(
'//*[@id="main"]/div[2]/div[1]/div[1]/h1/text()'
).get()
pageDetailInfo["img_title"] = title
img_src = xpath_selector.xpath('//*[@id="img"]/img/@src').get()
pageDetailInfo["img_src"] = "https://pic.netbian.com" + img_src
info_element = xpath_selector.xpath(
'//*[@id="main"]/div[2]/div[2]/div[2]//p'
).getall()
for element in info_element:
div_selector = scrapy.Selector(text=element)
value = div_selector.xpath("//span//a/text()").get()
if value is None:
value = div_selector.xpath("//span//text()").get()
if value is None:
continue
if "MB" in value:
pageDetailInfo["img_size"] = value
elif "-" in value and ":" in value:
pageDetailInfo["img_time"] = value
elif "x" in value:
pageDetailInfo["img_dimension"] = value
else:
pageDetailInfo["img_type"] = value
yield pageDetailInfo
Item
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ImageListInfoItem(scrapy.Item):
img_src = scrapy.Field()
img_alt = scrapy.Field()
img_href = scrapy.Field()
img_desc = scrapy.Field()
img_detail_url = scrapy.Field()
class ImageDetailInfoItem(scrapy.Item):
img_title = scrapy.Field()
img_src = scrapy.Field()
img_size = scrapy.Field()
img_time = scrapy.Field()
img_dimension = scrapy.Field()
img_type = scrapy.Field()
pipeline
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import json
from itemadapter import ItemAdapter
# 图片列表详情
class ImageListPipeline:
data_index = 1
def open_spider(self, spider):
self.file = open(spider.name + ".jl", "w", encoding="utf-8")
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
self.data_index = self.data_index + 1
return item
爬取结果大概是这样:
TODO:
我这里爬取到的应该不是原图,比如高清原图是 4MB,可是我拿到的是 400KB,不过没关系,后面打算本地使用类似高清图片修复框架自己再处理一次。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Arduino】编程语言:定时函数、数学函数、字符函数(功能、语法格式、参数说明、返回值) | 软件开发环境:安装步骤介绍(EXE安装版、ZIP安装版)
- 网络工程师:软件编程基础知识面试题(十二)
- 07、Kafka ------ 消息生产者(演示 发送消息) 和 消息消费者(演示 监听消息)
- vue实现框粘贴图片自动上传图片
- 【Leetcode】1599. 经营摩天轮的最大利润
- 什么是架构设计?
- RK3568驱动指南|第九篇 设备模型-第105章 platform总线设备注册流程实例分析实验
- 【云原生之Docker实战】Docker环境下部署群晖DSM系统(详细教程)
- [java数据结构] 栈(Stack)和队列(Queue)
- tess4j 实现 OCR 图片文字识别