深入理解 Spark(三)SparkTask 执行与 shuffle 详解
SparkTask 的分发部署与启动流程分析
Spark Action 算子触发 job 提交
Spark 当中 Stage 切分源码详解
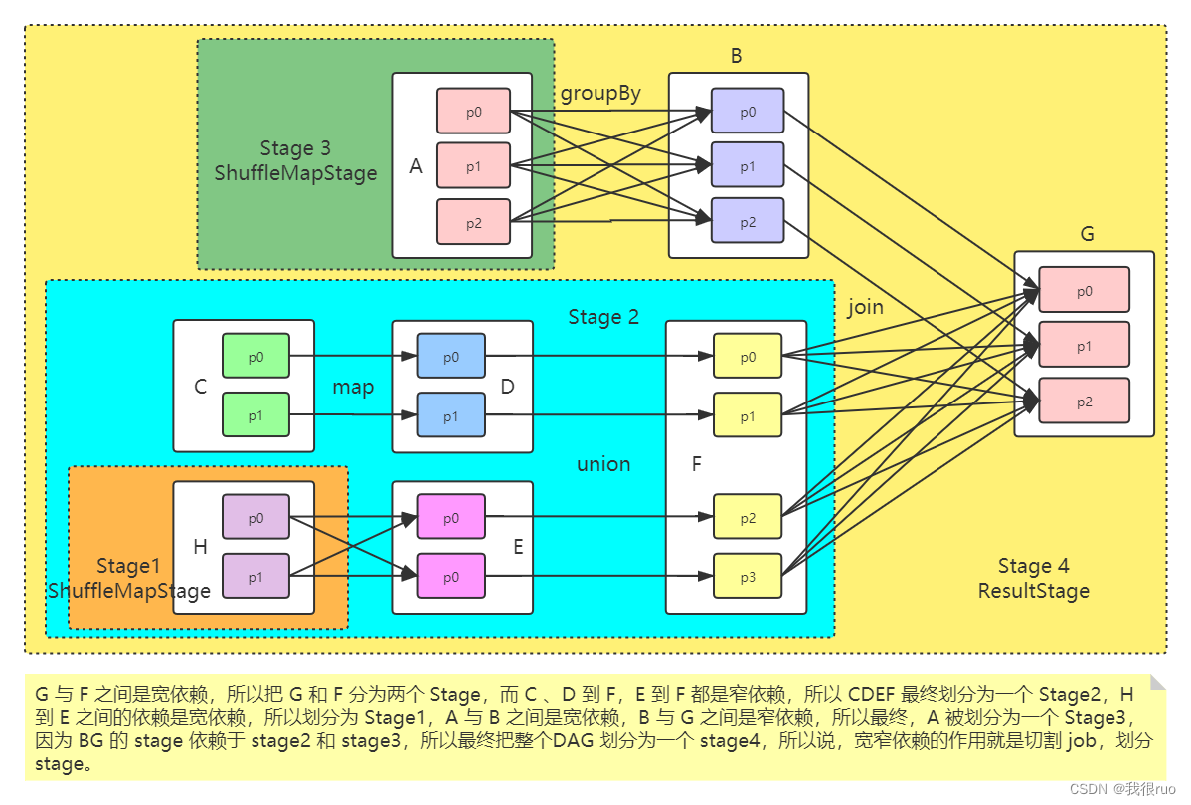
Task 的提交与执行
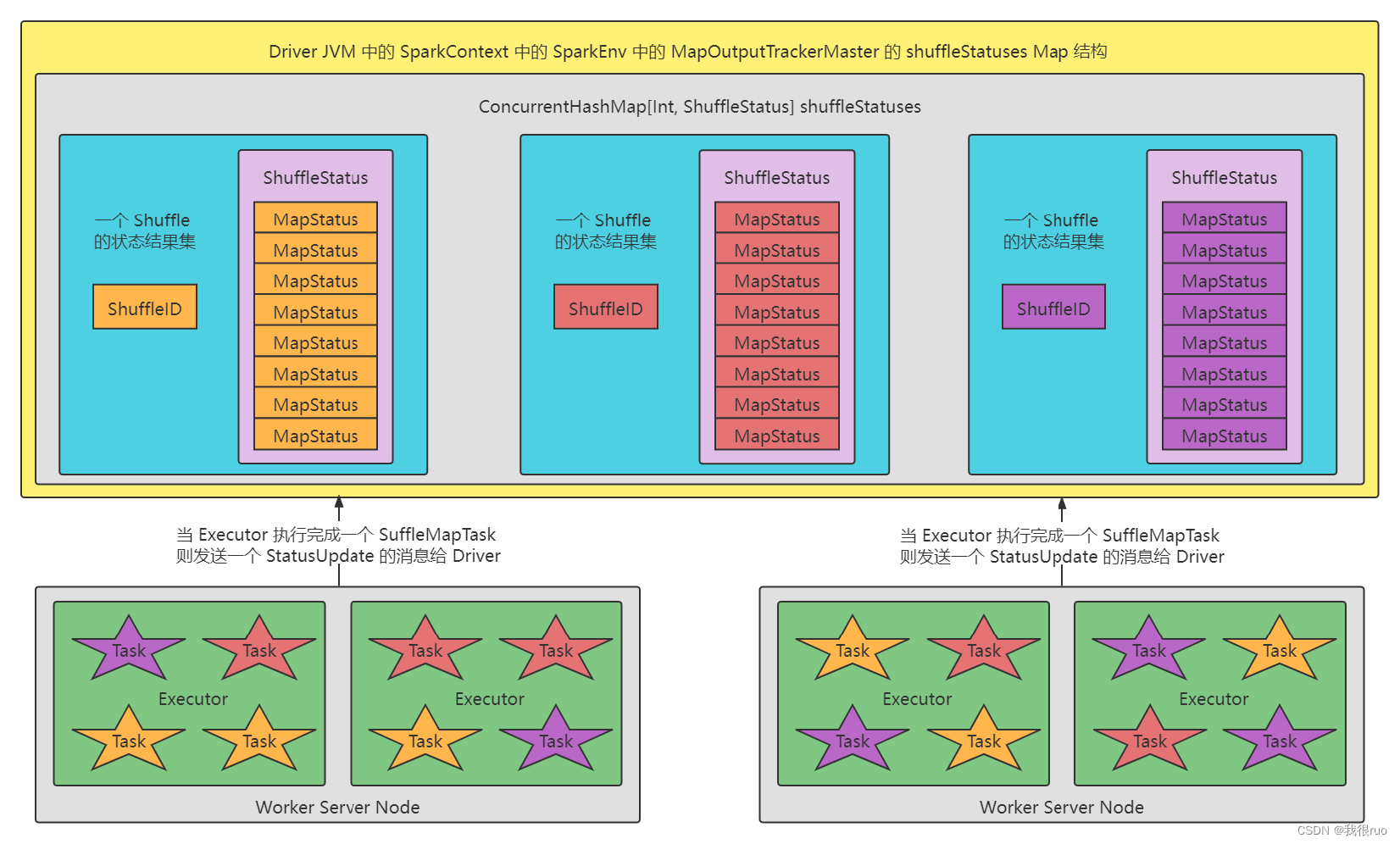
SparkShuffle 机制详解
MapReduceShu?e 全流程深度剖析
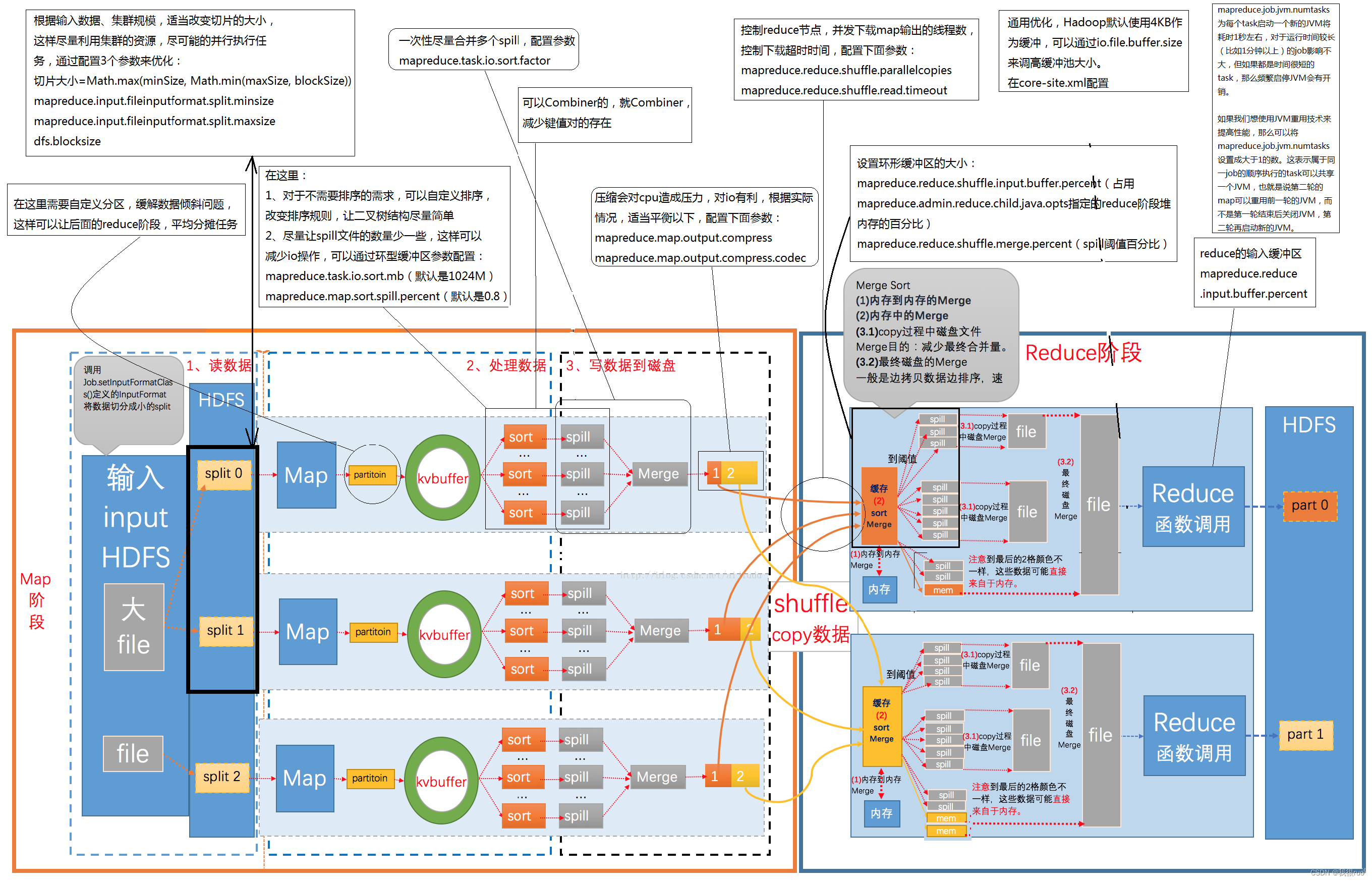
MapReduce 全流程执行过程中参与工作的组件以及他们的执行先后顺序:InputFormat => RecordReader => Mapper => Partitioner => Sorter => Combiner => Fetch => Group => Reducer => OutputFormat => RecordWriter
Partitioner 的常见规则

MapReduce Shu?e 为什么要排序?
- ReduceTask 的输入数据来自于上游 MapTask 的输出,并且普遍情况下,每个 MapTask 都会为每个 ReduceTask 提供部分输入。
- ReduceTask 的执行逻辑是:将 ReduceTask 的输入数据,按照标记分组之后,每次针对一组数据执行一次逻辑计算。
- 那么如果不排序,则每次为了得到待计算的一组数据,都需要完整扫描这个输入数据集一次,如果该 ReduceTask 的输入数据集的标记特比多,则需要扫描这个数据集成千上万次,这效率是非常低下的。
- 所以解决方案,就是给 ReduceTask 的输入数据集进行按照标记排序,然后 ReduceTask 在执行逻辑计算的时候只需要按照顺序扫描一次就能完成所有数据组的逻辑计算
- 既然 ReduceTask 的输入数据是需要排序的,而且 ReduceTask 的输入数据是来自于上游的MapTask 的,那为什么不让 MapTask 先给结果数据排序,最终 ReduceTask 拉取到所有数据再来做归并呢?利用分布式思想,本来该一个 ReduceTask 完成排序的,结果该排序的压力分散到多个上游 MapTask 之中,进一步提高效率。
- 所以 MapTask 的输出就不能直接写磁盘了,如果直接写磁盘,就只能最后做一次磁盘扫描将数据读取到内存再完成排序之后溢写到磁盘。这样做未免效率低,所以好方式是:MapTask 输出的时候,先将数据输出到内存,当然内存不可能是无限大,总有装不下的时候,所以当一定内存装满的时候,就对这部分输出数据进行排序,再刷写到磁盘,释放内存。
- 但是这样做,又发现一个新问题:当内存装满了之后,要先排序,然后溢写到内存,那这样是不是就阻塞了 MapTask 的继续输出呢?是的。所以又提供了优化方案:这个固定内存 100M 当写满 80% 的时候,就对这 80% 的数据执行排序后溢写到磁盘,这样子剩下的 20% 区域就可以继续接收 MapTask 的输出了。
- 最后再补充一点:当 MapTask 的输出做了排序之后,也可以让标记相同的待计算数据提前做预汇总,降低 Shuffle 中网络数据传输量,节省带宽。
MapReduce Shuffle 执行排序的局限性:
- 如果最终需要计算得到的结果集并不需要排序,这个排序则是多此一举。
- 多次溢写形成的多个临时磁盘文件需要做合并,这会导致磁盘 IO 的负担很重,这也是 MapReduce 效率低但是稳定的重要原因。
MapReduce Shuffle 为什么要文件合并?
- 由于 MapTask 输出数据的时候,是先写入 100M 的内存区间中,每次装满 80% 则执行一次溢写形成一个磁盘临时文件,这样必定会导致 MapTask 的输出磁盘文件会特别多,给文件系统带来负担。
- 如果不合并,那么 ReduceTask 过来拉取 MapTask 的输出数据的时候,需要打开很多的文件句柄,进一步增加负担。
- 每个 MapTask 输出的单个文件是有序的,但是不代表该 MapTask 输出的所有结果都是有序的,所以还需要做文件的合并来保证 MapTask 的输出有序。
Spark 当中的 Shuffle 机制介绍
大多数 Spark 作业的性能主要就是消耗在了 shuffle 环节,因为该环节包含了大量的磁盘 IO、序列化、网络数据传输等操作。理解 Spark 的 shuffle 的工作原理,有助于对 spark application 进行调优,减少资源消耗,提升生产效率。
在 Spark 的源码中,负责 shuffle 过程的执行、计算和处理的组件主要就是 ShuffleManager,也即shuffle 管理器。
- Spark-1.2 版本以前:默认实现是:HashShuffleManager
- Spark-1.2 版本以后:默认实现是:SortShuffleManager
- Spark-3.x 版本以后:彻底移除了:HashShuffleManager,只留下 SortShuffleManager
HashShuffleManager 的缺点是 shuffle 过程中会产生大量的临时结果文件,SortShuffleManager 的改进是让每个 Task 只产生一个结果文件(多个临时文件会合并到一个文件中),下游的 Task 过来拉取对应分区数据的时候,只需要去根据索引按需获取即可。
spark shuffle 概念介绍
Spark Job 依赖图:
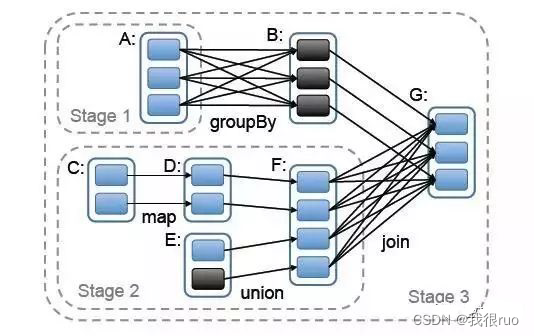
将对应的 RDD 标注上去后:
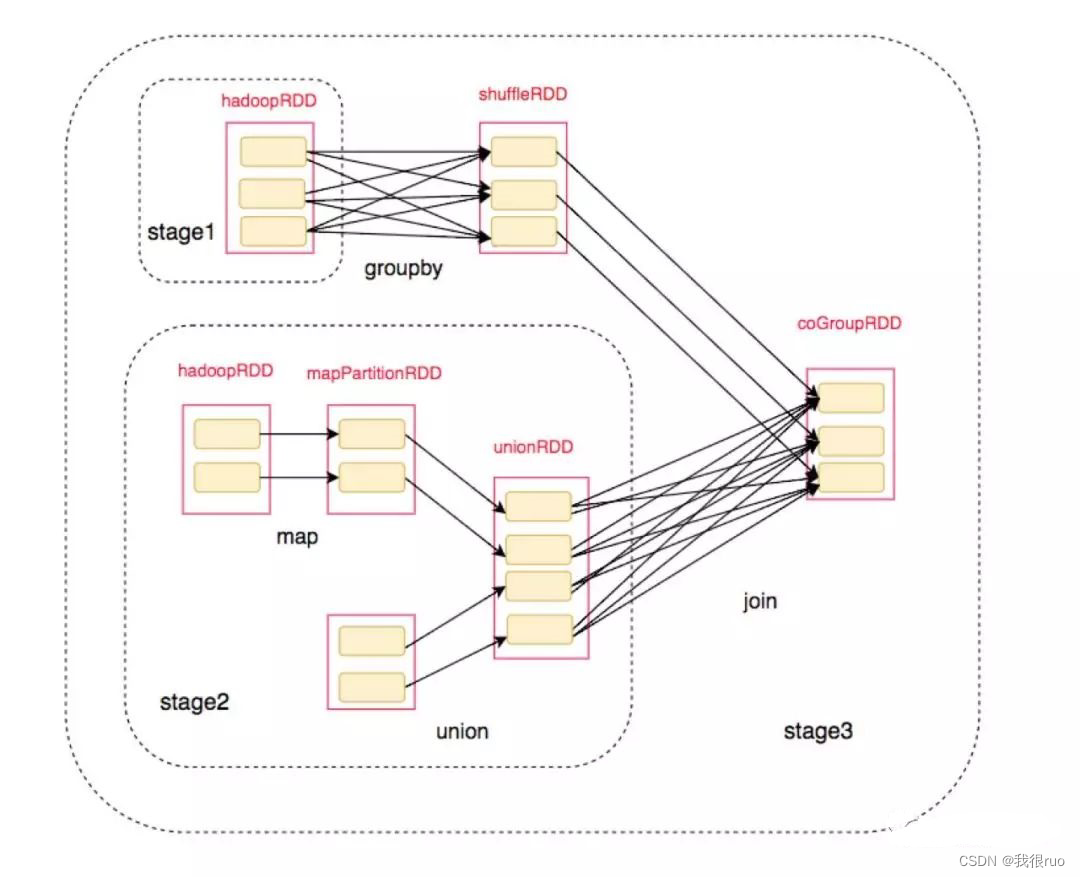
其中的 shuffle 过程:
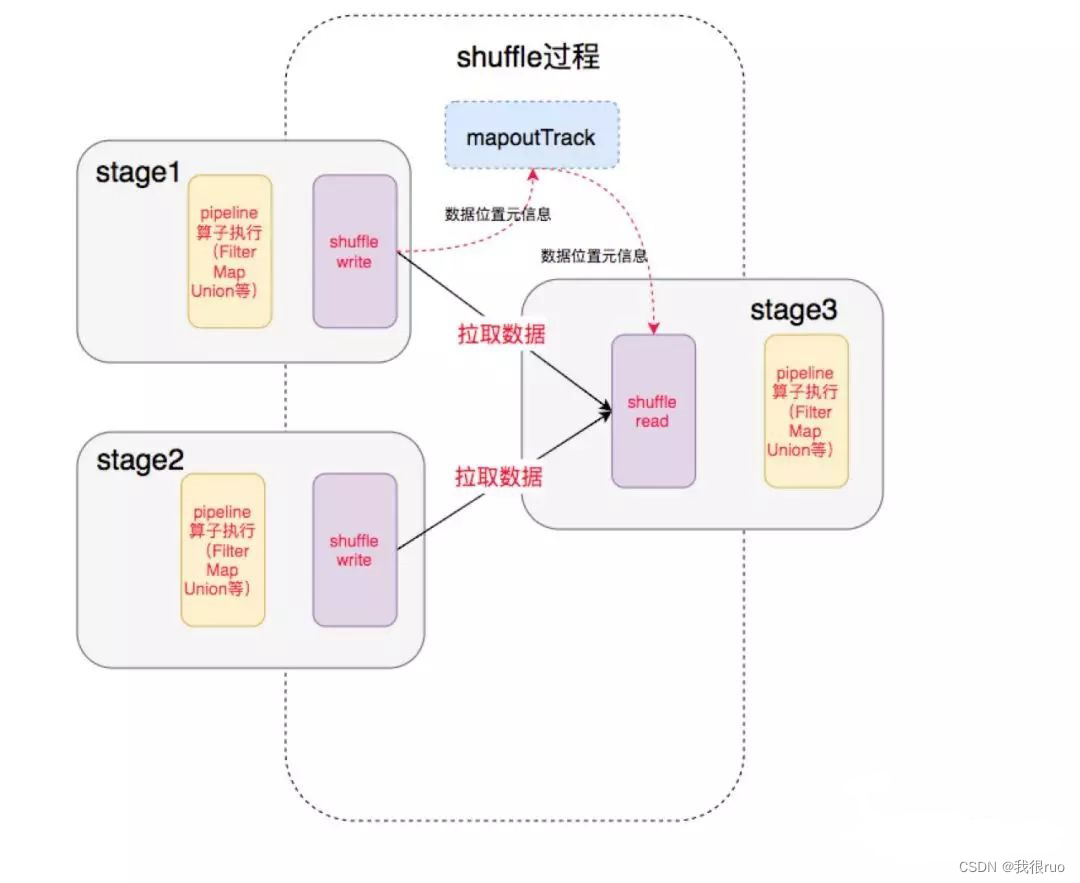
前一个 Stage 的 ShuffleMapTask 进行 Shuffle Write, 把数据存储在 BlockManager 上面, 并且把数据位置元信息上报到 Driver 的 MapOutTrack 组件中, 下一个 Stage 根据数据位置元信息, 进行 Shuffle Read, 拉取上个 Stage 的输出数据。
HashShuffle 过程详解
普通的 Hash Shuffle 机制
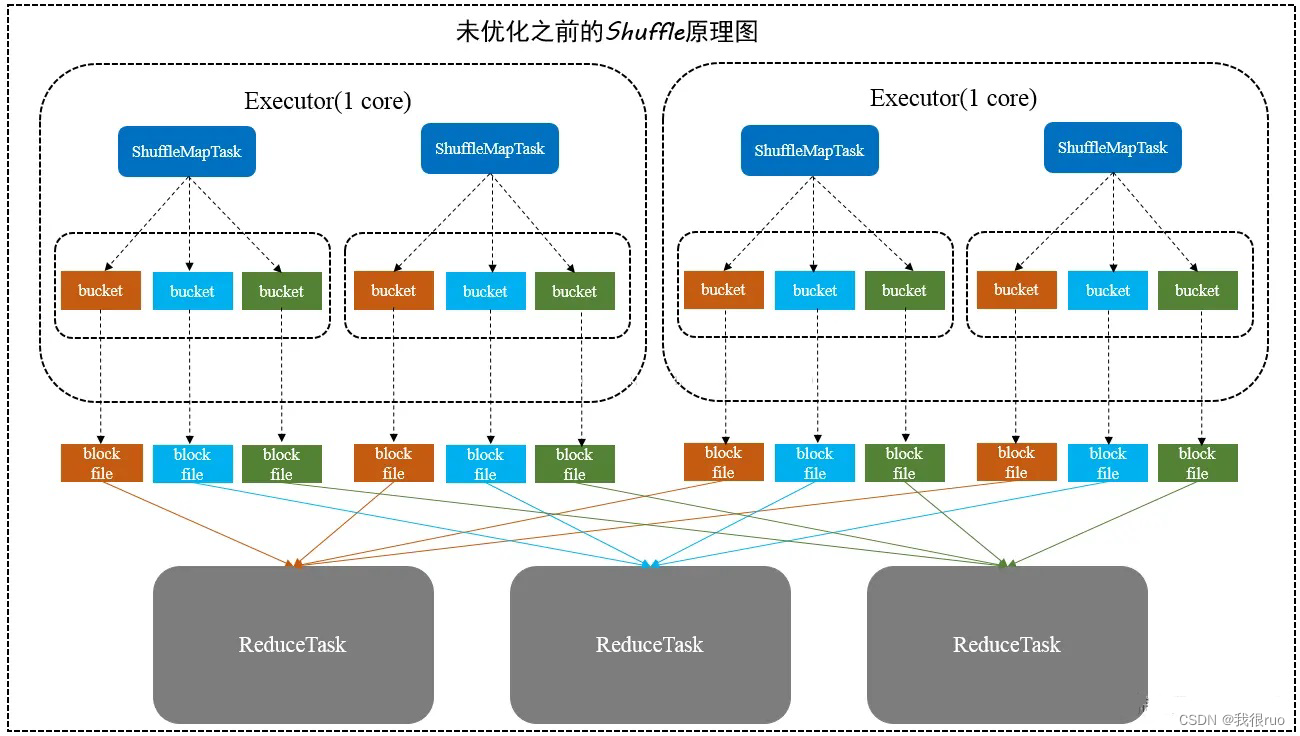
上图中,
- buffer 起到的是缓存作用,缓存能够加速写磁盘,提高计算的效率,buffer 的默认大小 32k。
- 分区器:根据 hash/numRedcue 取模决定数据由几个 Reduce 处理,也决定了写入几个 buffer 中。
- block file:磁盘小文件,从图中我们可以知道磁盘小文件的个数计算公式:block_file_cnt = M * R 。 M 为 map task 的数量,R 为 Reduce 的数量,一般 Reduce 的数量等于 buffer 的数量,都是由分区器决定的。
- Shuffle 阶段在磁盘上会产生海量的小文件,建立通信和拉取数据的次数变多,此时会产生大量耗时低效的 IO 操作 (因为产生过多的小文件)
- 大量耗时低效的 IO 操作 ,导致写磁盘时的对象过多,读磁盘时候的对象也过多,这些对象存储在堆内存中,会导致堆内存不足,相应会导致频繁的 GC,GC 会导致 OOM。由于内存中需要保存海量文件操作句柄和临时信息,如果数据处理的规模比较庞大的话,内存不可承受,会出现 OOM 等问题。
合并机制的 Hash shuffle
合并机制就是复用 buffer 缓冲区,开启合并机制的配置是 spark.shuffle.consolidateFiles。该参数默认值为 false,将其设置为 true 即可开启优化机制。通常来说,如果我们使用 HashShuffleManager,那么都建议开启这个选项。
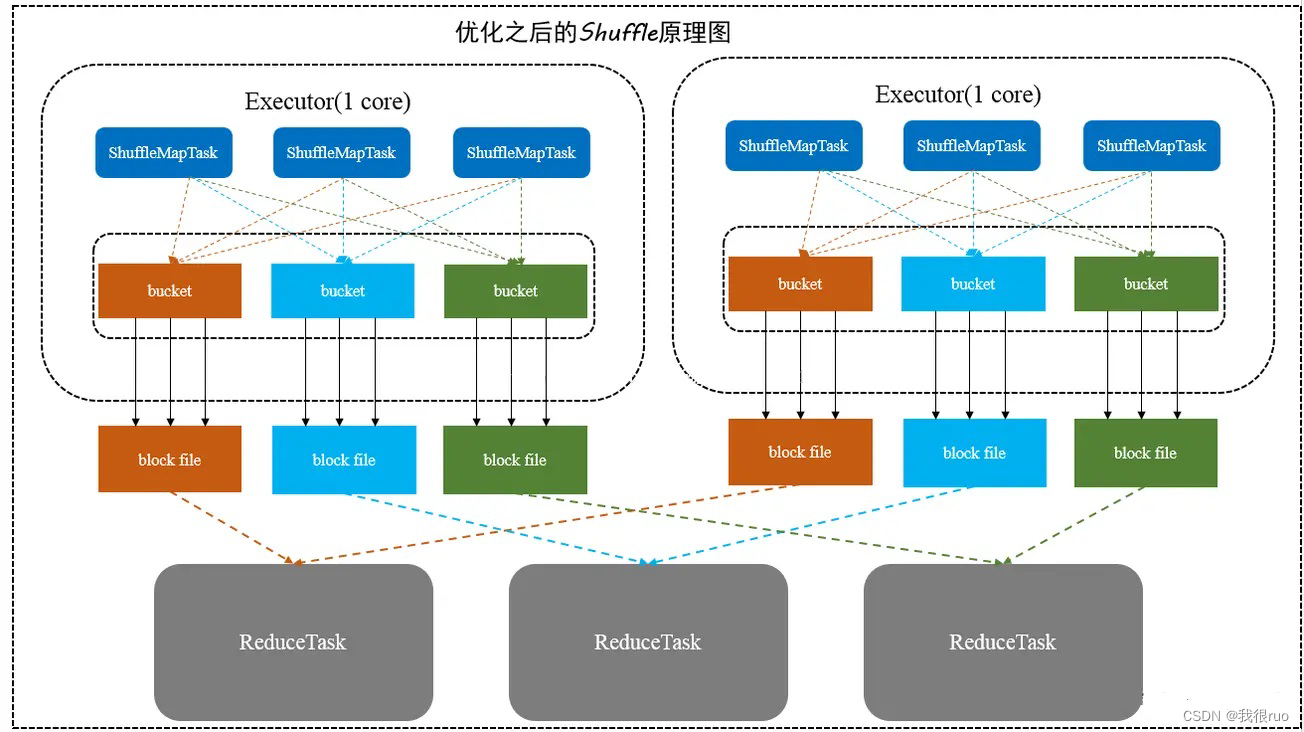
此时 block_file = Core * R ,Core 为 CPU 的核数,R 为 Reduce 的数量,但是如果 Reducer 端的并行任务或者是数据分片过多的话则 Core * Reducer Task 依旧过大,也会产生很多小文件。
SortShuffle 过程详解
Sort shuffle 的普通机制
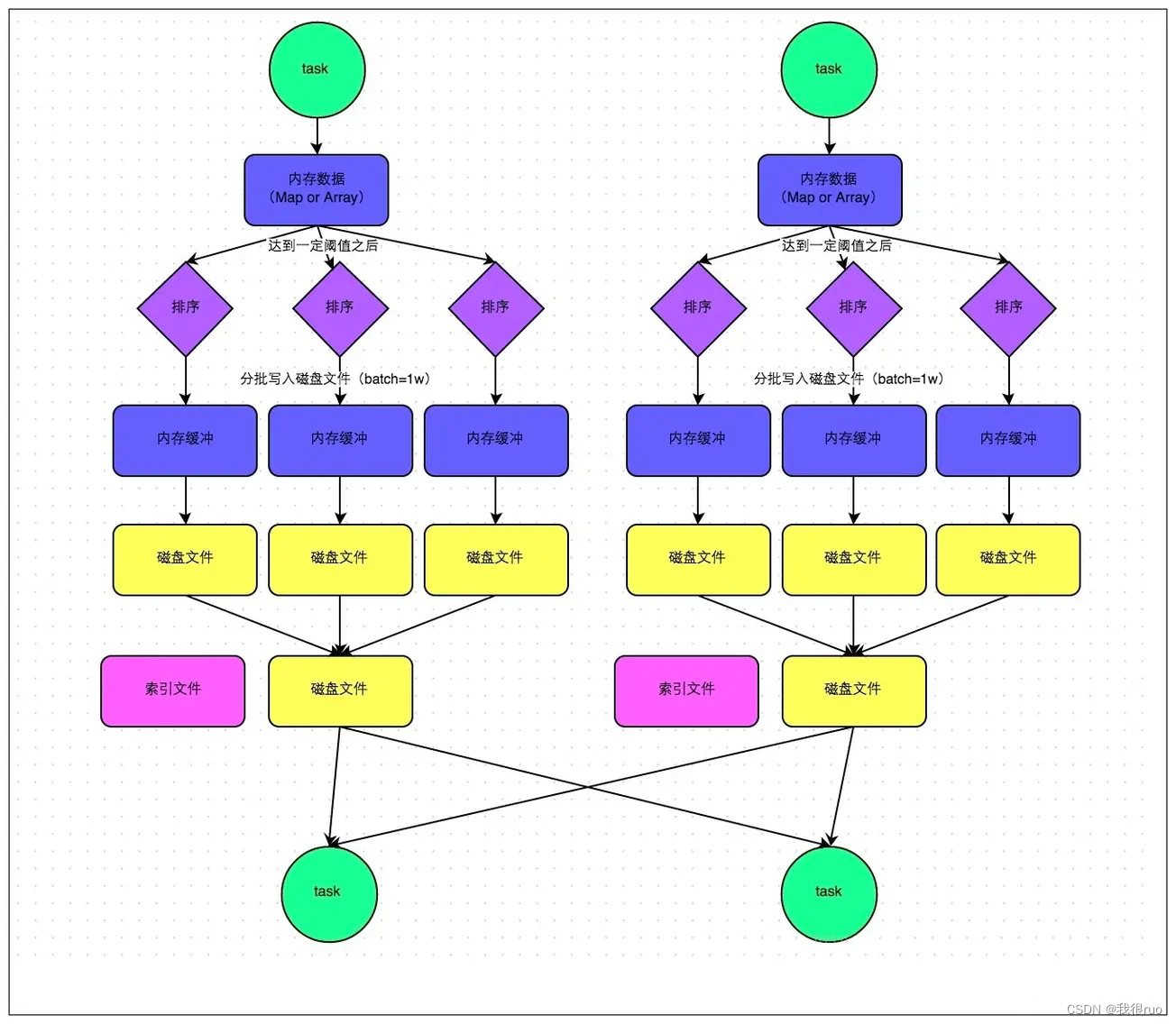
这个机制的好处:
- 小文件明显变少了,一个 task 只生成一个 file 文件
- file 文件整体有序,加上索引文件的辅助,查找变快,虽然排序浪费一些性能,但是查找变快很多
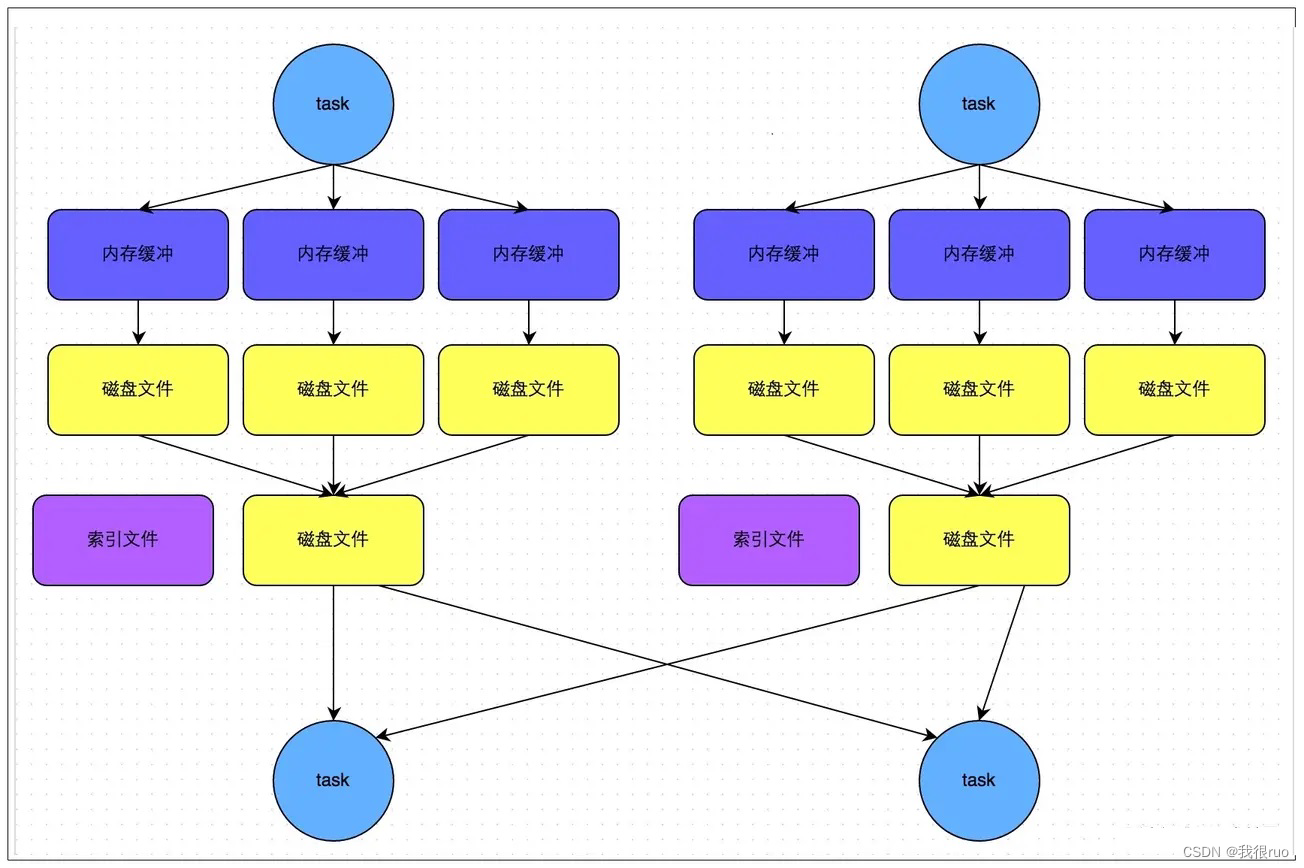
ByPass 模式的 SortShuffle 机制
bypass 机制运行条件是 shuffle map task 数量小于 spark.shuffle.sort.bypassMergeThreshold 参数(默认值 200)的值,且不是聚合类的 shuffle 算子(比如 reduceByKey)。
补充
- hash-based shuffle 中,排序发生在 reduce 阶段
- sort-based shuffle 中,排序发生在 shuffle 阶段
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- FMETP STREAM 2.0
- 伺服电机转矩控制实验(电机互扭)
- 使用ChatGLM3自定义工具实现大模型查询MySQL数据库
- 内网穿透方案&FRP内网穿透实战(基础版)
- 记edusrc一处信息泄露登录统一平台
- 服务器硬件监控的重要性及监控方法(PIGOSS BSM )
- 如何快速打造属于自己的接口自动化测试框架
- 第137期 Oracle的数据生命周期管理(20240123)
- WPF中使用ListView封装组合控件TreeView+DataGrid
- 客服系统配置之Nginx处理静态资源和动态请求