[Linux进程(一)] 什么是进程?PCB的底层是什么?以及进程标识符pid与ppid

文章目录
1、前言
大家经常都在讲进程,而它到底是什么呢?
这里给大家先简单的介绍一下:
- 课本概念:程序的一个执行实例,正在执行的程序等。
- 内核观点:担当分配系统资源(CPU时间,内存)的实体。
2、描述进程 — PCB(os怎么管理进程呢)
在操作系统中我们说到,os管理的本质并不是对事物本体的管理,而是对数据的管理。
这里虽然我们并不知道进程是什么,但是按照上面的理解,我们对进程的管理,也是对进程的数据进行管理,这里就用到那六个字“先描述,再组织”。我们来画图理解一下:
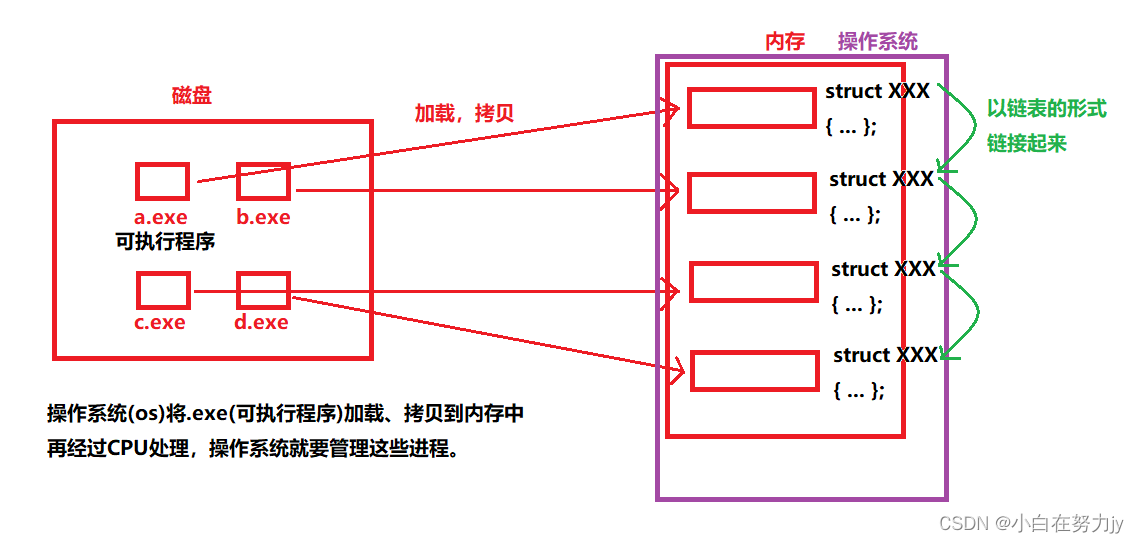
操作系统可能会同时管理非常多的“进程”,因此在管理的时候,管理这些进程的数据即可,将这些进程共有的属性提取出来,用结构体将其存起来,再使用链表将其链接起来,这样就能有效的管理进程,这样的机制就叫做“先描述,再组织”。
这个进程属性的集合就叫做PCB,也叫做进程控制块。
PCB是一个统称,在Linux中,PCB叫做 task_struct。
最终,我们操作系统对PCB的管理就被建模成了对链表的增删查改。
我们得出:进程 = 可执行程序 + 内核数据结构
3、查看进程
3.1 方法一
在Linux下我们可以使用下面的这个命令来查看进程:
ps ajx
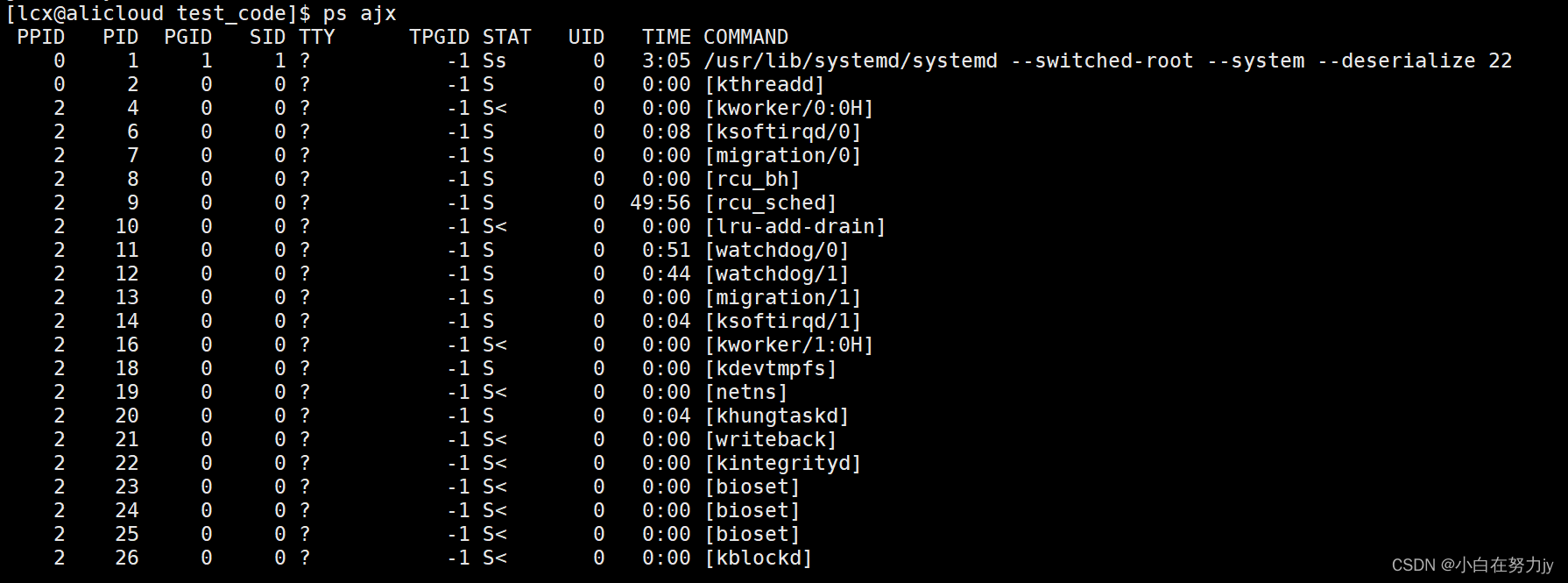
这是所有的进程,如果我们只是对其中一个进程查看呢?我们看下面的:
我们先写一段C语言程序,编译为可执行程序并执行,然后使用该命令来查看一下进程:
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("我是一个进程\n");
sleep(1);
}
return 0;
}
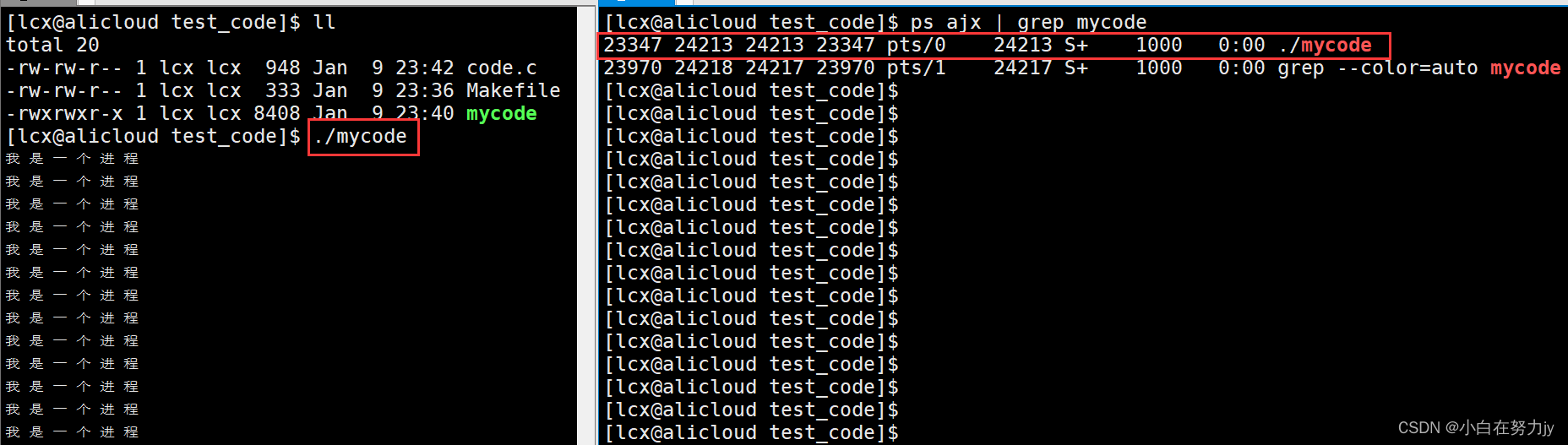
命令:
ps ajx | grep mycode
这里用到我们以前学到的 管道符与过滤,筛选出我们想找的进程。
3.2 方法二
我们可以通过根目录下的proc目录来查看。proc目录下保存有进程的信息。
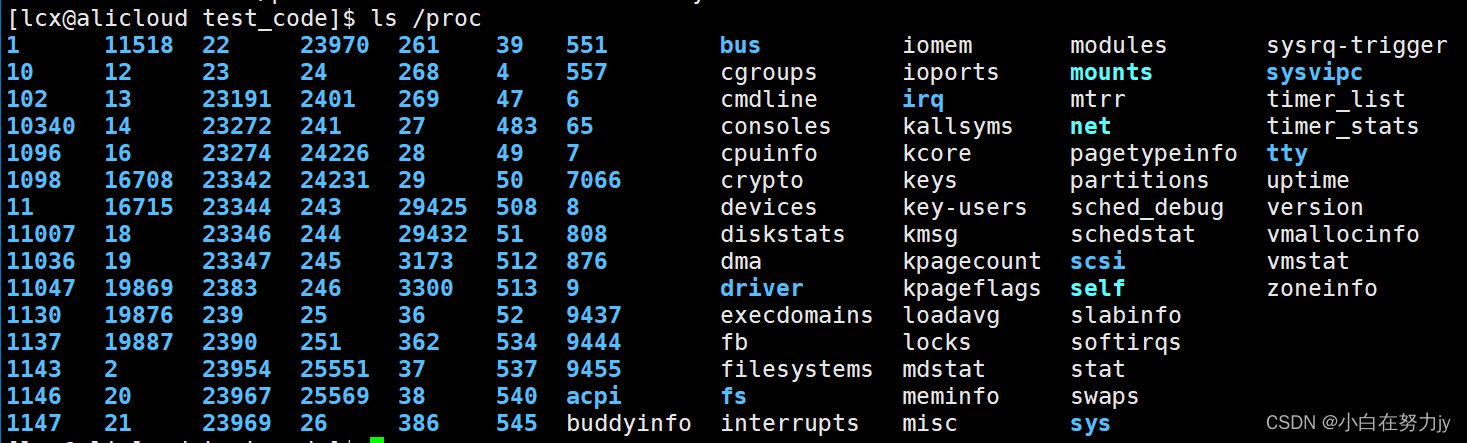
proc目录下的蓝色数字就是每一个进程的pid(Process ID),这就跟我们的身份证号一样,一人只有一个,每个进程都只有这么一个标识符。
我们再次以刚才那段C语言为例,来查看进程:

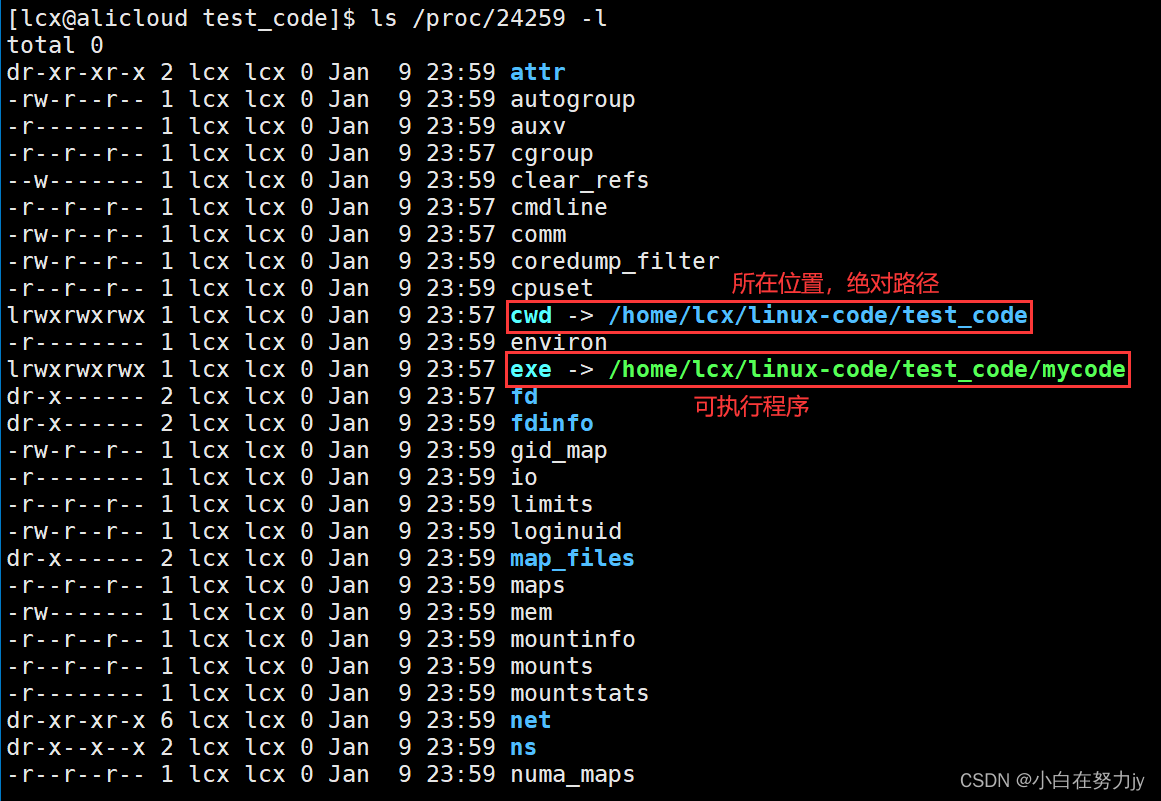
如果我们删掉磁盘上可执行程序,进程没有终止的话,我们仍然是可以查到的,因为进程是程序拷贝到内存中的,代码+数据都被拷贝下来了,所以删掉磁盘上的可执行程序不会影响的。
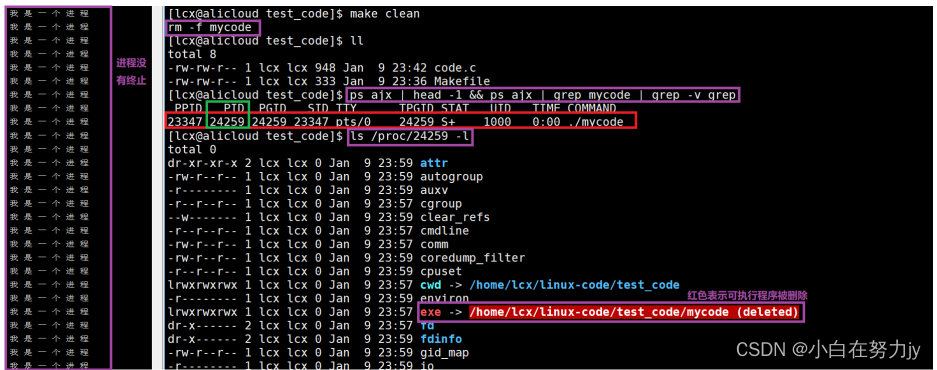
当终止掉程序,内存中拷贝的可执行程序与数据都被释放掉了,因此再去查就查不出来了。

4、系统调用获取进程标示符(PID)
- 进程id(PID)
- 父进程id(PPID)
我们在上面使用 ps ajx 命令的时候发现,有一个PID,还有一个PPID,我们不难猜到,这些都是PCB中的属性。
如果获取呢?这里要介绍我们第一个要学习系统调用,getpid与getppid了。我们使用man手册查一下看看怎么说。
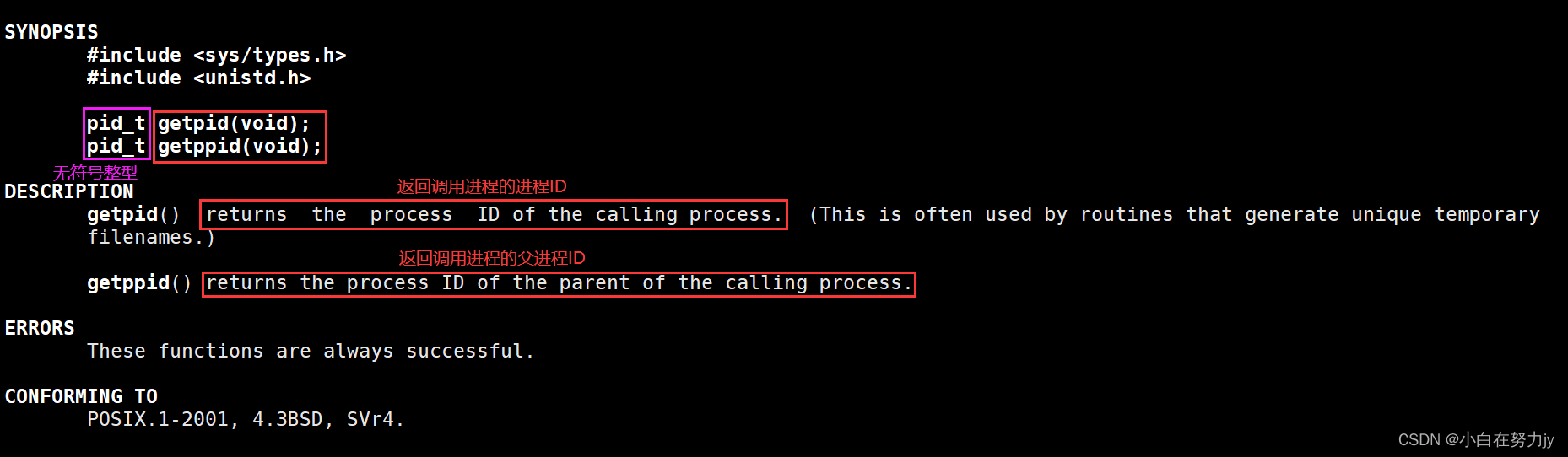
我们接下来就使用getpid与getppid系统调用接口来看看能不能查到pid与ppid。
4.1 获取进程的ID
这里我们写一段C语言程序来调用看看:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("我是一个进程,pid = %d\n", getpid());
sleep(1);
}
return 0;
}
编译后我们运行可执行程序,并使用下面 ps ajx 命令来对比看,pid是否正确。
ps ajx | head -1 && ps ajx | grep mycode | grep -v grep

我们发现,getpid确实是没错的,并且我们调用是没有出错的。
当我们想要终止掉一个进程的时候,我们总是用 ctrl + c,今天我们再来学一个终止命令,kill 命令。
kill -9 pid // 这里的9是9号信号

4.2 获取进程的父进程ID
我们继续改写上面的C语言代码,再来看看 getppid() 系统调用接口。
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("我是一个进程,pid = %d, ppid = %d\n", getpid(), getppid());
sleep(1);
}
return 0;
}

经过我的不断调用发现,每次运行pid都是在变化的,但是ppid确实一直没有变化,我猜它是一直在运行的,我们来查看一下它是谁。

原来它是命令行解释器 bash 呀。我们由此也知道了,我们所敲出来的命令都是 bash 的子进程。
那我们Linu下有没有创建子进程的系统接口呢,有,我们再来学一下。
5、系统调用创建子进程-fork
我们可以使用fork创建子进程,先查一下man手册看看:
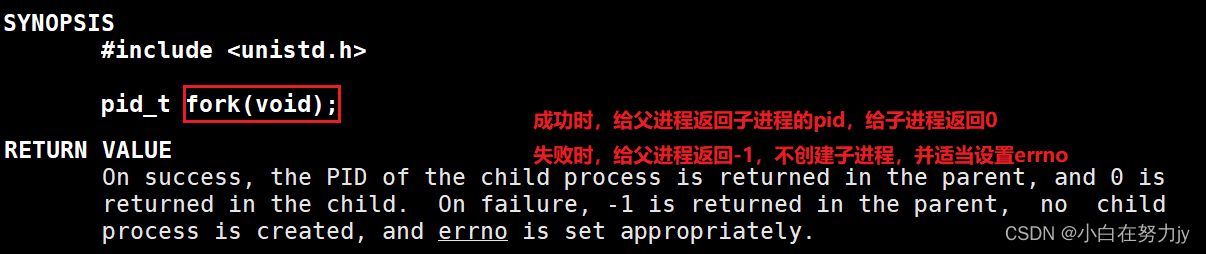
我们写一份 C语言代码来试着调用系统接口 fork()。
我们先想一下,我们有自己的进程为什么还要去创建子进程呢?
在上面的学习我们看到,我们输入的命令是执行命令得到结果,而父进程bash是解释你所输入的命令,这就说明,我们父子进程各自做各自的事。由此,我们想是不是可以,按照fork的返回值配合 if-else 语句来执行不同的事。我们试一下:
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("我是一个父进程,我的pid:%d\n", getpid());
pid_t id = fork();
// fork之后用if分流
if(id < 0) return -1;
else if(id == 0)
{
// child
while(1)
{
printf("我是子进程,pid:%d, ppid:%d\n", getpid(), getppid());
sleep(1);
}
}
else
{
// parent
while(1)
{
printf("我是父进程,pid:%d, ppid:%d\n", getpid(), getppid());
sleep(1);
}
}
return 0;
}
我们编译后运行可执行程序。
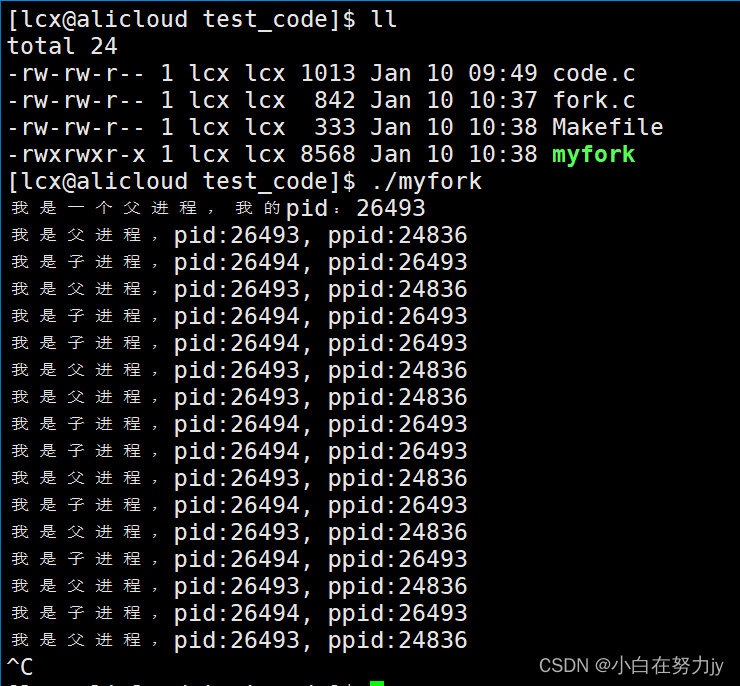
通过打印出来的结果,我们发现刚我们的猜测是正确的!!!
这里我们可以总结出几个问题,对fork作以总结:
1、fork干了什么事情?
调用fork()后,创建了子进程,父子进程可以协作,干不同的事。
2、为什么fork会有两个返回值?
我们在查文档的时候,就有返回值的介绍。
成功时,给父进程返回子进程的pid,给子进程返回0;失败时,给父进程返回-1,不创建子进程。
3、为什么fork的两个返回值,会给父进程返回子进程pid,给子进程返回0?
我们与现实生活联系起来。现实中,父 : 子 = 1 : n(n >= 1),父亲给孩子不同名字,可以更好的区分孩子(保证唯一性)。这样类比到这里,给父进程返回子进程的pid,父进程必须有标识子进程的方式,而子进程只需要知道自己是否被创建成功,以及知道父进程是谁即可 (调用 getppid())。
4、fork之后谁先运行?
我们上面运行了可执行程序后,发现先跑了父进程的代码片段,然后跑子进程的代码片段,但是后面并不是这样的规律。
当创建完子进程后,系统的其他进程,以及父进程和子进程都要被调度。父子进程的PCB都被创建并在运行队列中排队,哪个进程的PCB先被调度,哪个进程就先被运行,是由操作系统决定的,不确定的。
5、如何理解同一个id变量,怎么会有不同的值?
当父子进程都被运行时,他们共用一份代码与数据,但是一旦发生数据的写入,就会发生写时拷贝,数据就不再共享,而是父子进程各一份自己的数据,因此就会出现同一个变量,值不相同。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux应急响应基础和常用命令
- openFeign调用接口时传递表单参数、Json参数、HttpServletRequest对象
- 【Kubernetes】控制器Daemonset
- vue中的过滤器filter
- OV5640:寄存器 自用
- 81%成功率!纽约大学研究人员推出训练家用多技能机器人的框架Dobb-E
- TensorFlow
- FastReport .NET 2024.1.2 Crack
- 【十五】【动态规划】115. 不同的子序列、44. 通配符匹配、10. 正则表达式匹配 ,三道题目深度解析
- 计算机毕业设计SSM基于的助贫公益募捐管理系统1i6pi9【附源码】