深入理解 Spark(四)Spark 内存管理模型
Spark 中的内存管理和资源管理模型
Executor 进程作为一个 JVM 进程,其内存管理建立在 JVM 的内存管理之上,整个大致包含两种方式:堆内内存和堆外内存。
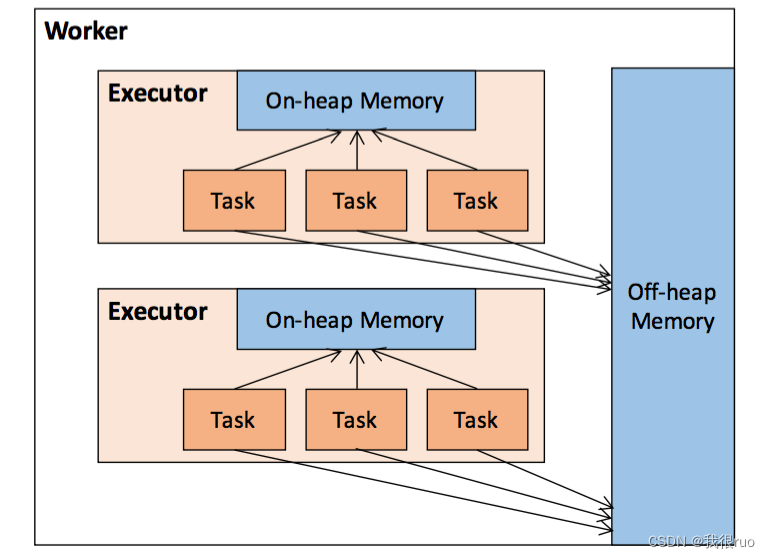
一个 Executor 当中的所有 Task 是共享堆内内存的。一个 Work 中的多个 Executor 中的多个 Task 是共享堆外内存的。
Executor 内存划分
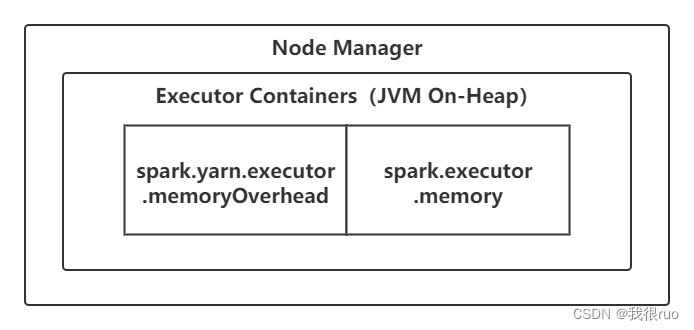
堆内内存和堆外内存
大数据领域两个比较常见的内存优化方案:
- 引入堆外内存
- 内存池化管理
作为一个 JVM 进程,Executor 的内存管理建立在 JVM 的内存管理之上,Spark 对 JVM 的堆内(Onheap)空间进行了更为详细的分配,以充分利用内存。同时,Spark 引入了堆外(Off-heap)内存,使之可以直接在工作节点的系统内存中开辟空间,进一步优化了内存的使用。
- 没有堆外内存之前:min = n, max = m (假设 executor 的内存: x, executor 上运行的 Task 的数量: y,则每个 Task 均分得到的资源应该是: m = x / y , 设 n = m / 2,Task 能否运行取决于是否能申请到大小为 n 的初始内存)。每个 Task 能使用的资源使用量的区间:【m/2, m】,m = x/y
- 引入堆外内存之后:堆外内存的大小:z, min = n, max = m + z。每个 Task 能使用的资源使用量的区间:【m/2, m + z】
Spark 对堆内内存的管理是一种逻辑上的规划式的管理,因为对象实例占用内存的申请和释放还是都由 JVM 完成,Spark 只能在申请后和释放前记录这些内存。堆内内存的大小,由 Spark 应用程序启动时的 --executor-memory 或 spark.executor.memory 参数配置。
- 存储内存:存储 cache RDD 数据 和 广播变量数据(代码注释:used for caching andpropagating internal data across the cluster)
- 执行内存:Shuffle 过程中占用的内存(代码注释:used for computation in shuffles, joins,sorts and aggregations)
- other 空间:应用程序对象实例占用内存
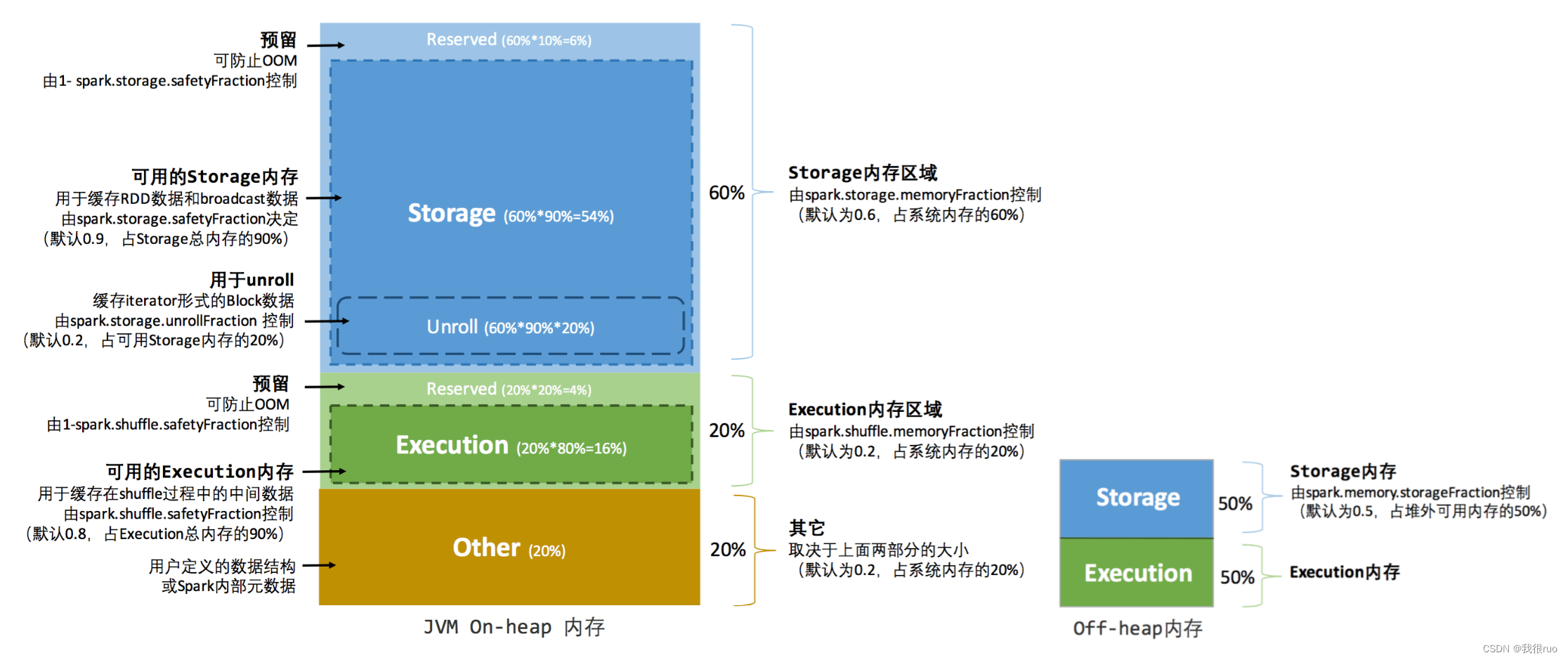
堆内内存(On-Heap Memory)
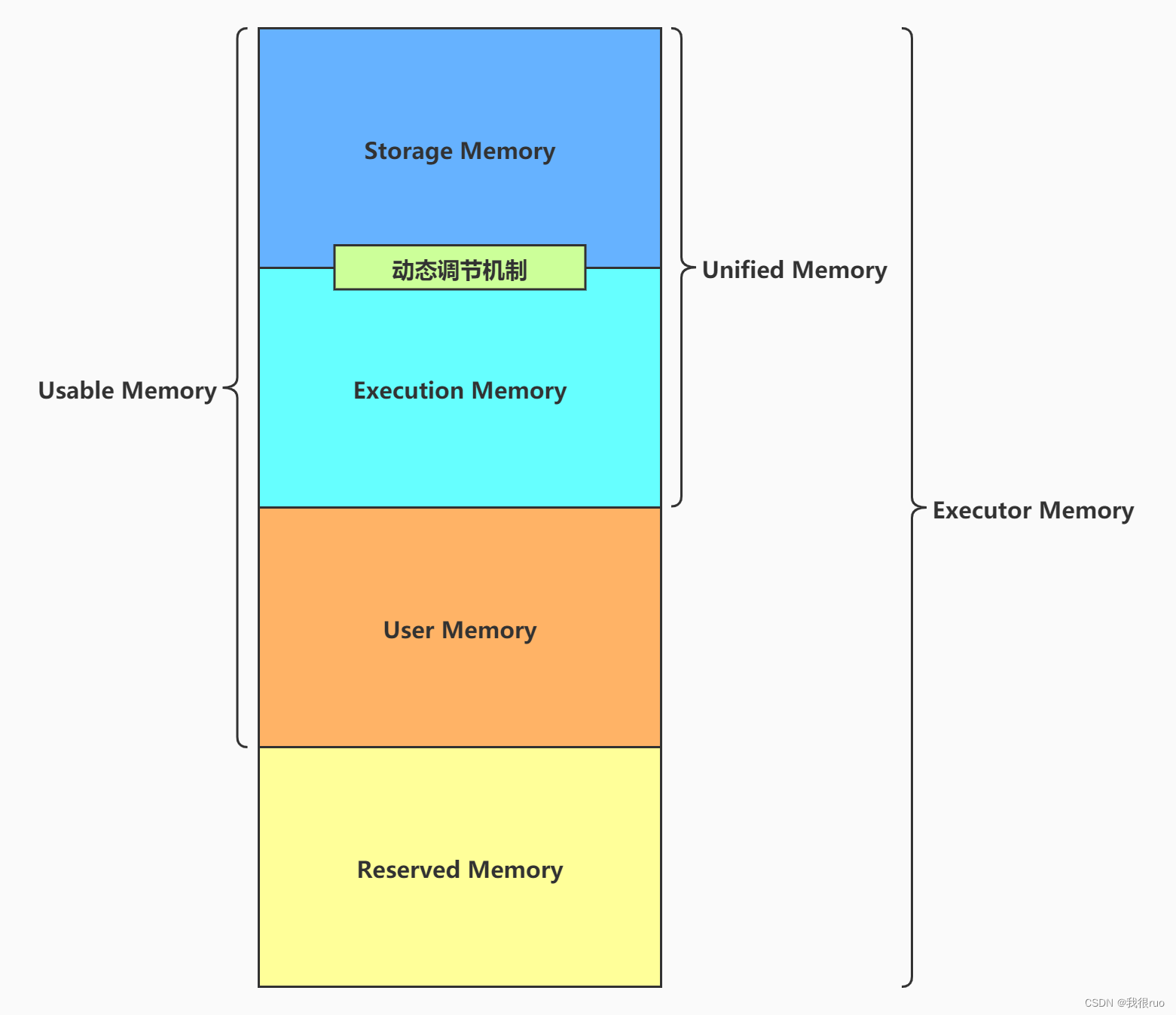
- Executor Memory: 由 spark.executor.memory 配置,或者在提交的时候使用 --executormemory 进行配置。
- Reserved Memory: 这个内存是写死了的,默认 300MB,但也可以修改,前提是在测试环境下,通过修改 spark.test.reservedMemory 参数对这个值进行修改;这块内存用于存储 Spark 内部的对象。
- Usable Memory: Executor Memory - Reserved Memory 就是可用内存。
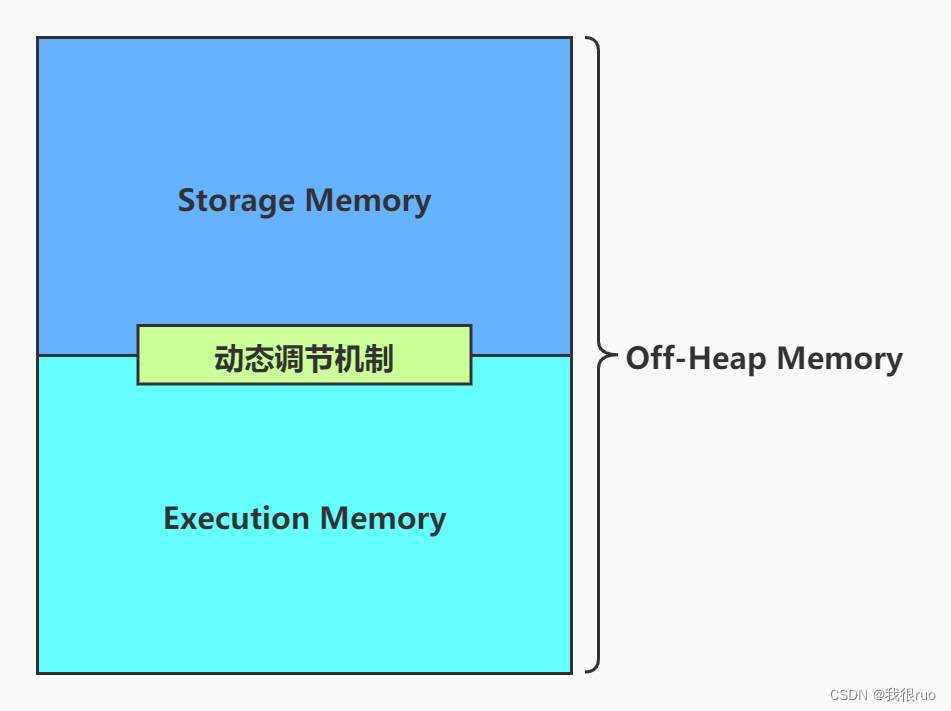
- Unified Memory: Usable Memory * spark.memeory.fraction 比例值(约等于 UsableMemory * 60%),这个内存由 Storage 和 Execution 共用,这两个之间有一个动态调节机制.
- Storage Memory: Unified Memory * spark.storage.storageFraction 比例值(约等于 UnifiedMemory * 50%),这块内存主要是用来存储一些缓存数据的,比如 cache(),persist(),RDD 的缓存数据等。
- Executor Memory: Unified Memory * (1 - spark.storage.storageFraction 比例值),这块内存用于存储 Shuffle,Join,Sort,Aggregate 等计算过程中的临时数据。
- User Memory: Usable Memory * (1 - spark.memeory.fraction 比例值),这块内存用于保存 RDD 转换操作时需要的一些数据,如父子 RDD 的依赖关系。
堆外内存(Off-Heap Memory)
Task 能申请到的内存
spark.executor.cores 参数值就是 Spark 程序运行时得到的核数(以下简称为 N),每个 Task 能够分配到的内存大小为 1/2N ~ 1/N(举例,N=4,分配到的内存为 10G,那内存大小为 1.25G ~ 2.5G)。
静态内存管理模型:StaticMemoryManager
这种内存模型最大的问题是不熟悉 Spark 这种内存分配的开发者无法根据数据规模和任务规模做出相应的合理配置,容易造成旱的旱死,涝的涝死的水火两重天局面。Spark 为了兼容老版本应用程序的目的仍然保留了这种内存模型的实现和使用。
统一内存管理模型:UnifiedMemoryManager
Spark-1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域。凭借统一内存管理机制,Spark 在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护 Spark 内存的难度。

- 如果存储内存已用完,可以占用执行内存中未用的内存。但是执行内存没有足够内存可用的时候,需要存储内存释放归还内存。
- 如果执行内存已用完,可以占用存储内存中未用的内存。但是存储内存没有足够内存可用的时候,执行内存占用的存储内存是不会归还的。
- 如果存储内存和执行内存都不足的时候,则他们会使用磁盘。
Spark MemoryManager 内存管理器

Spark BlockManager 资源管理机制原理
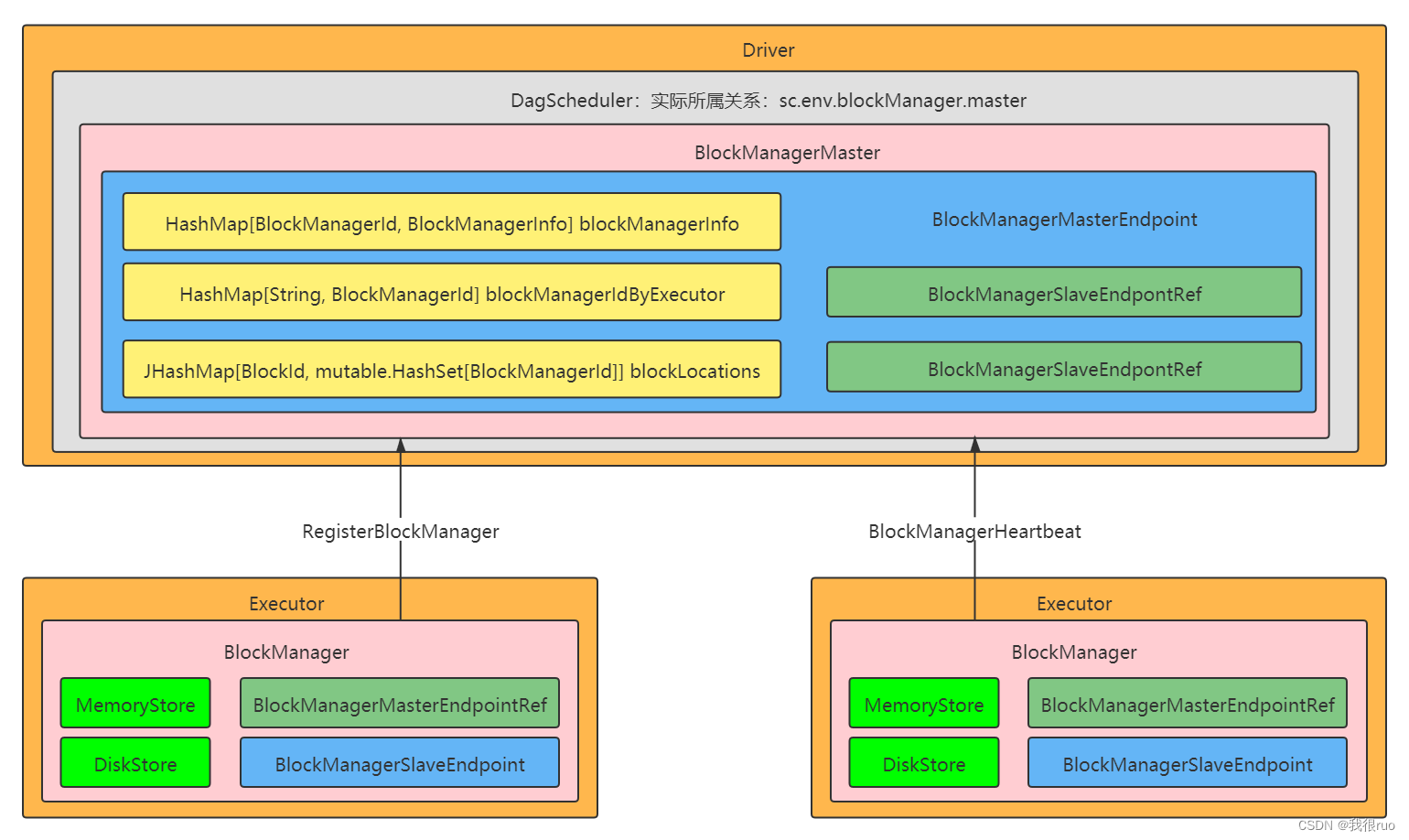
Spark-2.x 版本的 BlockManager 体系架构图:
Spark-3.x 版本的 BlockManager 体系架构图:
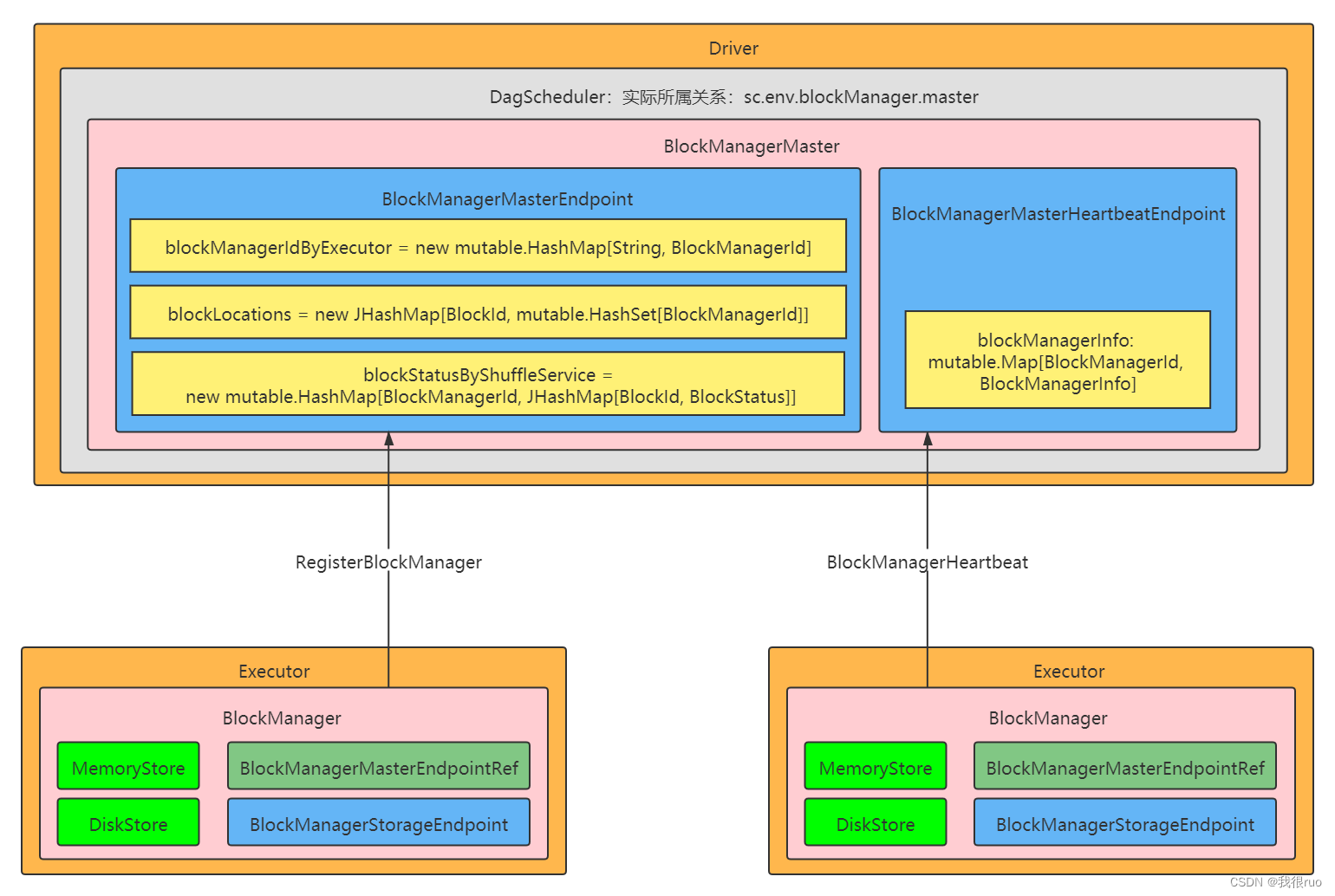
总共有四大类操作:
- 往本地存储数据
- 往远程复制数据副本
- 从本地读取数据
- 从远程拉取数据
Spark RDD 持久化机制 和 Checkpoint 机制
checkpoint 与 presist 持久化的区别:
- 持久化将数据保存到 cache 中,rdd 的 lineage 不变;checkpoint 执行完成 rdd 已经没有了依赖关系,同时把父 rdd 设置成了 CheckpointRDD,rdd 的lineage 改变。
- 持久化的数据存储在内存或磁盘,随着 Executor 的关闭,BlockManager 会被 Stop,则 cache 的数据会被清除;checkpoint 通常选择的是高容错性的文件系统,如 HDFS,数据的安全性非常高。
- RDD 持久化,不影响 job 执行效率,但是 RDD checkpoint 会使这个 Job 重复执行一次!这个效率低,所以一般建议 Spark cache 和 checkpoint 联合使用。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- golang反射(reflect)虽爽,但很贵
- 装饰器(1)
- 【算法集训】基础数据结构:十一、邻接矩阵
- 常微分方程数值解笔记-1
- 【消息队列】RocketMQ 并发消费和顺序消费
- 电缆护层保护器维护方法详解
- java 面向对象特征:继承(Inheritance)(概念、代码、图示)
- ubuntu开机卡在[OK],,,,,的界面无法正常开机后进入桌面
- 用python图形库实现的一个白球,简单记录一下(实现了简单的碰撞检测)
- Ubuntu 常用命令之 chmod 命令用法介绍