ML Design Pattern——Distribution Strategy
Data parallelism
The data is divided into multiple parts, and each part is processed independently on separate devices. The model parameters are shared across devices, and each device computes the gradients locally and then synchronizes with other devices to update the global model.
all-reduce algorithm
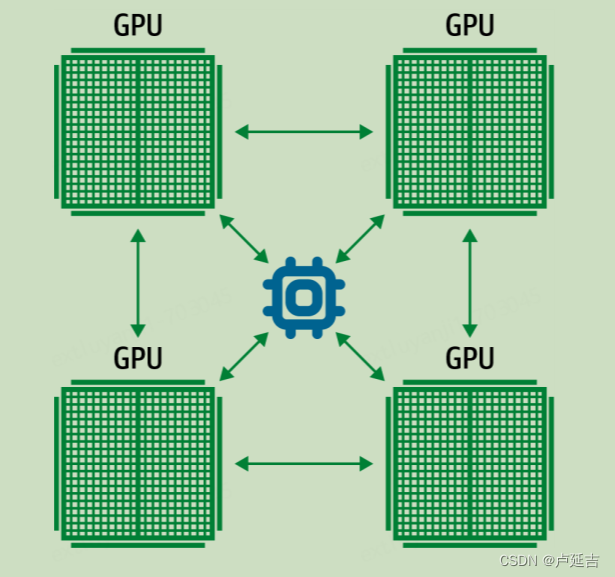
The all-reduce algorithm is commonly used in distributed computing frameworks for parallel processing of data across multiple machines or devices. The main idea behind this algorithm is to efficiently aggregate the data from all the workers and distribute the result back to all the workers.
The algorithm works by performing a series of reductions and broadcasts. In the reduction step, each worker locally reduces its own local data by applying a reduction operation (such as sum or average) to a subset of the data. This local reduction reduces the amount of data that needs to be communicated in subsequent steps.
After the local reductions, a series of broadcasts are performed to distribute the reduced data to all the workers. In each broadcast step, the reduced data is sent to all workers to ensure that they have access to the same information.
The all-reduce algorithm can be implemented using different communication primitives, such as point-to-point message passing or collective communication operations provided by the communication library. The choice of communication primitive depends on various factors like network topology, communication latency, and bandwidth.
The all-reduce algorithm offers several advantages in data parallelism. First, it enables efficient aggregation of data across workers, facilitating better coordination and collaboration in distributed training. Second, it helps in achieving load balancing as the reduction and broadcast steps involve equal participation from all workers. Additionally, the algorithm is fault-tolerant, enabling robustness in distributed systems by handling failures gracefully.
In summary, the all-reduce algorithm is a fundamental technique in data parallelism, allowing efficient aggregation and distribution of data across workers in an asynchronous manner. Understanding and implementing this algorithm in a machine learning framework design is essential for enabling scalable and efficient distributed training.
NVIDIA NCCL
NVIDIA Collective Communications Library (NCCL) is a library that provides communication primitives for multi-GPU and multi-node programming. It is designed to optimize the performance of deep learning and high-performance computing workloads by efficiently utilizing the available resources in multi-GPU systems.
NCCL provides a set of communication operations, such as all-gather, broadcast, reduce, and all-reduce, that can be used to exchange data between multiple GPUs in a high-performance and scalable manner. It takes advantage of low-latency, high-bandwidth interconnects, like InfiniBand and NVLink, to efficiently transfer data between GPUs.
NCCL supports different data types, including floating-point, integers, and custom user-defined data types. It also provides a flexible API that allows developers to integrate it with their existing GPU-accelerated applications.
Overall, NVIDIA NCCL plays a crucial role in enabling efficient and scalable communication between GPUs, which is essential for accelerating deep learning and other high-performance computing workloads.
Parameter Server Strategy
A parameter server strategy is a distributed computing approach where a network of computers collaboratively store and update shared model parameters.
In this strategy, the parameter server acts as a centralized store for the model parameters that are accessed by multiple workers. The workers are responsible for computing gradients and adjusting the parameters based on the gradients they compute. The parameter server receives the gradient updates from the workers and updates the shared parameters accordingly.
The parameter server strategy offers several advantages. First, it allows for easy parallelization of the model training process, as each worker can independently compute gradients and update parameters. Second, it reduces communication overhead between workers, as they only need to communicate with the parameter server rather than sharing updates directly. Third, it enables efficient memory usage, as the parameter server stores the shared parameters instead of duplicating them on each worker.
However, the parameter server strategy also has some disadvantages. First, it can introduce a single point of failure, as the parameter server is critical to the functioning of the system. If the parameter server fails, the entire system may be disrupted. Second, it can introduce communication bottlenecks, especially if the network bandwidth between the workers and the parameter server is limited.
To address some of these limitations, variants of the parameter server strategy have been proposed, such as decentralized parameter servers and asynchronous updates. These variants aim to improve fault tolerance and reduce communication overhead.
In synchronous training and In asynchronous training
each have their advantages, and disadvantages and choosing between the two often comes down to hardware and network limitations.
In synchronous training, also known as batch training, the model is trained using a fixed batch of data at a time. The training process occurs in a sequential manner, where each batch is processed one after the other. This training method is often used when the data can fit in memory, and all the steps, such as data preparation, model fitting, and evaluation, are executed in a step-by-step manner.

Advantages of synchronous training:
- Better convergence: Synchronous training allows for better convergence as each batch is processed sequentially, ensuring that the model updates are consistent and optimal.
- Simplicity in implementation: Synchronous training is straightforward to implement and understand since the steps flow in a linear fashion, making it easier to debug and troubleshoot any issues.
- Better resource utilization: Since all the computations happen in sequential order, synchronous training makes better use of computational resources by fully utilizing parallel processing capabilities.
Disadvantages of synchronous training:
- Slower training speed: Synchronous training can be slower compared to asynchronous training, especially when dealing with large datasets, as it waits for the completion of each batch before moving on to the next one.
- Limited scalability: Synchronous training can face scalability issues when training on large datasets or in distributed computing environments. If the data cannot fit into memory or the computational resources cannot handle the workload, synchronous training may become impractical.
On the other hand, asynchronous training involves training the model on multiple batches concurrently, without waiting for the completion of previous batches. Each batch is processed independently and asynchronously, decoupling the training steps from each other. This training method is useful when dealing with large datasets, distributed computing, or real-time training scenarios.
Advantages of asynchronous training:
- Faster training speed: Asynchronous training can be faster compared to synchronous training, especially in distributed computing environments, as it does not wait for the completion of each batch before moving on to the next one.
- Scalability: Asynchronous training is highly scalable, making it suitable for training on large datasets or in distributed computing setups. It can handle high-volume and high-velocity data efficiently.
- Real-time training: Asynchronous training is well-suited for real-time training scenarios where the model needs to continuously adapt to changing data streams.
Disadvantages of asynchronous training:
- Convergence challenges: Asynchronous training can suffer from convergence challenges due to the lack of synchronization. Updates from different batches may conflict with each other, leading to slower convergence or even divergence.
- Complexity: Asynchronous training is more complex to implement and debug due to the concurrent nature of batch processing. It requires careful handling of synchronization, communication, and conflict resolution among multiple training instances.
Choosing between synchronous and asynchronous training depends on the specific problem, available resources, and the nature of the data. Synchronous training is generally preferred for small to medium-sized datasets and resource-constrained environments, while asynchronous training is suitable for large-scale data, distributed computing, and real-time scenarios, but it requires careful handling to ensure convergence.
Model parallelism
The model is divided into smaller parts, and each part is processed independently on separate devices. The input data is divided and propagated through the different parts of the model, and the outputs are combined to generate the final result.
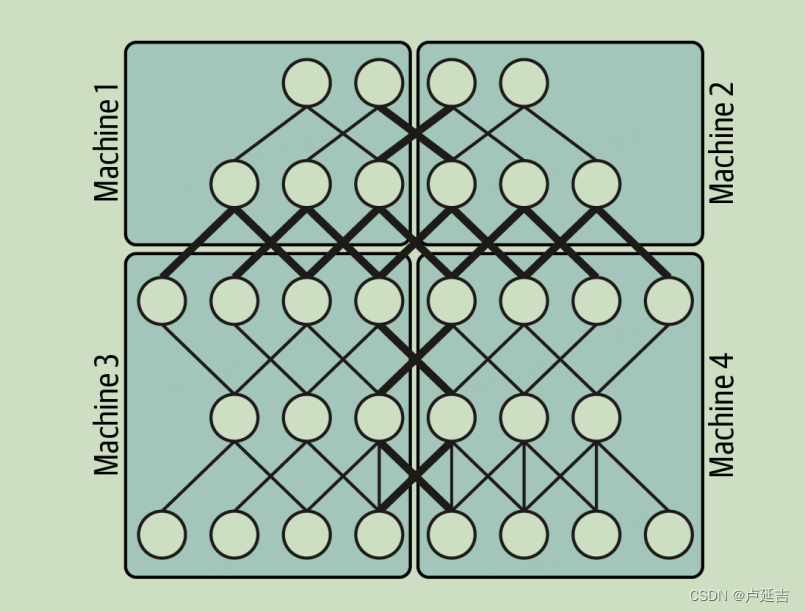
Pipeline parallelism
The model is divided into multiple stages, and each stage is processed independently on separate devices. The output of each stage is passed as input to the next stage, and the overall computation is done in a sequential manner.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- springCould中的zookeeper-从小白开始【3】
- 2023前端面试题总结:JavaScript篇完整版
- C# .NET读取Excel文件并将数据导出到DataTable、数据库及文本
- 【计算机网络基础】DHCP与DNS(学习笔记)
- 5分钟手把手教Tuxera NTFS 2023破解版安装激活图文使用教程
- go语言中反射的应用介绍和案例
- 四川云汇优想教育咨询有限公司引领电商未来
- 3Dmax灯光学习(Vray灯光应用)
- php-m和phpinfo之间不一致的问题的可能原因和解决办法
- Getway介绍和使用