Python中的h5py包使用
发布时间:2024年01月06日
h5py是一个非常强大的工具,可以用于存储和处理大量科学数据。它可以帮助我们提高数据处理的效率和可靠性。
一、h5py
h5py是Python中的一个库,提供了对HDF5文件的高级封装,使得在Python中处理HDF5文件变得更加简单和高效。HDF5(Hierarchical Data Format 5)是一种用于存储和组织大量科学数据的文件格式。
1.1 特点
支持层次化的数据组织,可以将数据分为多个组(group)和数据集(dataset)。
支持多种数据类型,包括整数、浮点数、字符串、复数、布尔值等。
支持压缩,可以减少文件的大小。
1.2 主要功能
创建和打开HDF5文件。
读取和写入HDF5文件中的数据。
管理HDF5文件中的组和数据集。
支持批量读写数据。
支持异步读写数据。
支持文件的版本控制。
1.3 常用场景
存储和处理图像数据。
存储和处理音频数据。
存储和处理视频数据。
存储和处理科学数据。
二、安装h5py
使用下面命令安装:
pip install h5py
三、示例代码
下面代码的后面每一句我都详细注释了。
import numpy as np
import h5py # h5py库则提供了操作HDF5文件的接口。
x = np.arange(100) # 创建了一个包含0到99的整数数组
with h5py.File('test.h5', 'w') as f: # 创建了一个名为’test.h5’的HDF5文件
f.create_dataset('test_numpy', data=x) # 然后在文件中创建了一个名为’test_numpy’的数据集,并将之前创建的数组x存储在其中
subgroup = f.create_group('subgroup') # 创建了一个名为’subgroup’的子组,并在子组中创建了一个同名的数据集
subgroup.create_dataset('test_numpy', data=x)
subsub = subgroup.create_group('subsub') # 代码在’subgroup’中创建了一个名为’subsub’的子子组,并在其中创建了一个同名的数据集。
subsub.create_dataset('test_numpy', data=x)
def read_data(filename): # 用于读取HDF5文件中的数据
with h5py.File(filename, 'r') as f:
def print_name(name):
print(name)
f.visit(print_name) # 先打开文件,然后使用visit方法遍历文件中的所有组和数据集,并打印出它们的名字
print('---------------------------------------')
subgroup = f['subgroup'] # 函数获取’subgroup’组,并打印出该组中的所有键
print(subgroup.keys())
print('---------------------------------------')
dset = f['test_numpy'] # 函数获取名为’test_numpy’的数据集,并打印出该数据集的详细信息,包括数据集本身、数据集的名字、形状、数据类型以及数据集中的所有数据
print(dset)
print(dset.name)
print(dset.shape)
print(dset.dtype)
print(dset[:])
print('---------------------------------------')
read_data('test.h5')
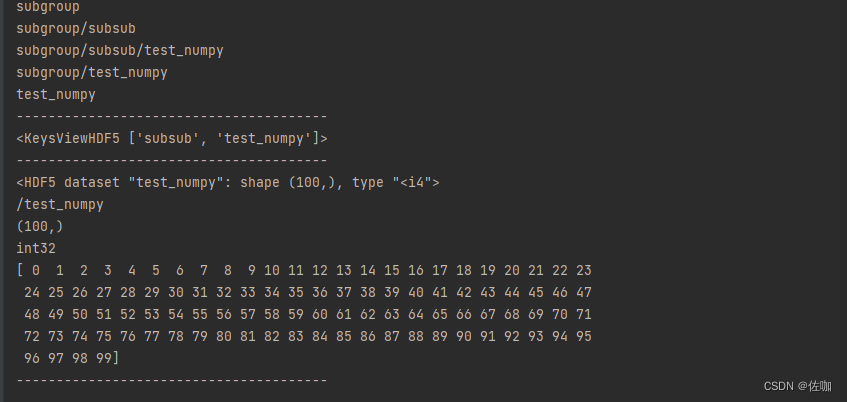
3.1 运行结果
运行上面示例代码后的结果如下:
四、总结
以上就是使用Python中的h5py包使用方法。
总结不易,多多支持,谢谢!
文章来源:https://blog.csdn.net/qq_40280673/article/details/135392999
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!