事务的隔离级别-实操论证
发布时间:2024年01月21日
事务的隔离级别
1.读未提交 (Read Uncommitted):
这是最低的隔离级别,在这个级别下,一个事务可以读取到另一个事务尚未提交的数据变更。这可能导致脏读(Dirty Read)、不可重复读(Non-Repeatable Read)和幻读(Phantom Read)等问题。
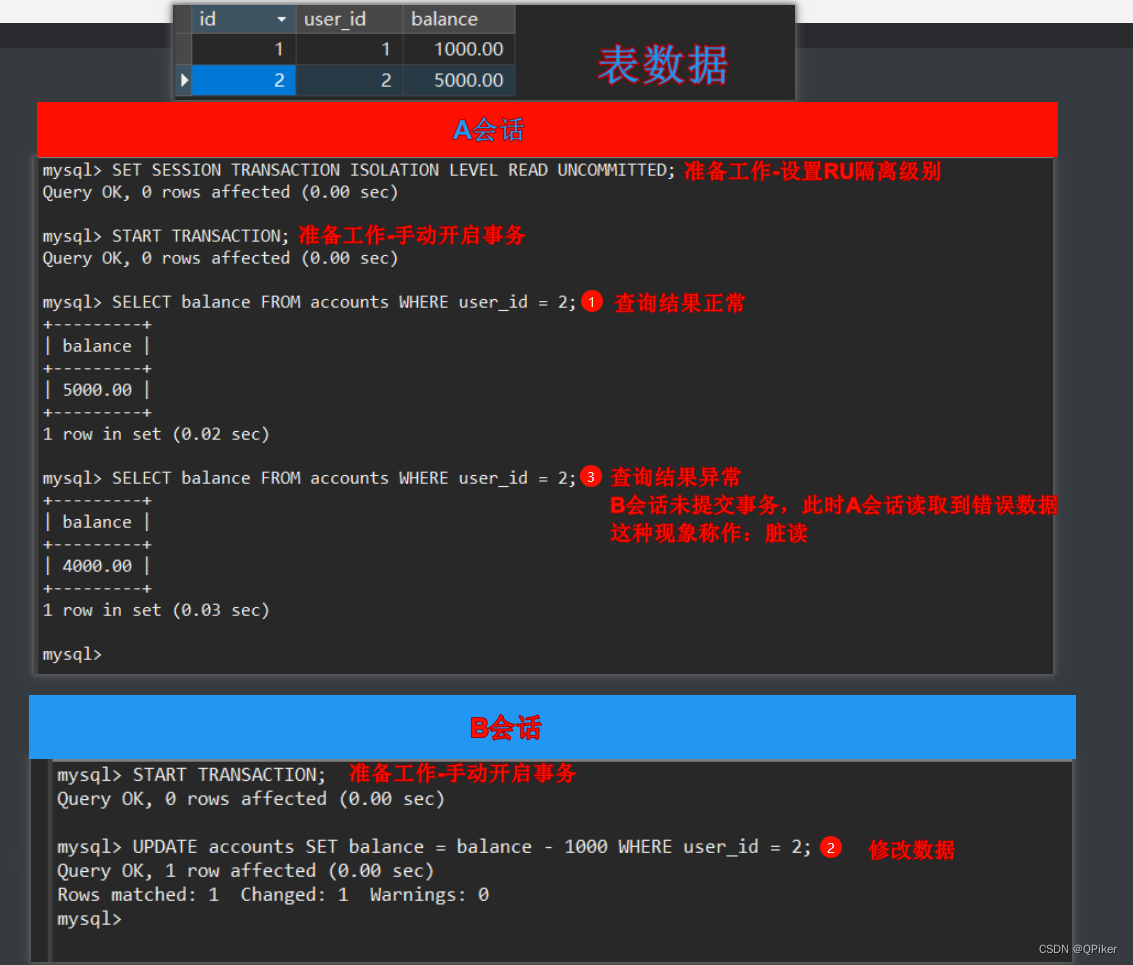
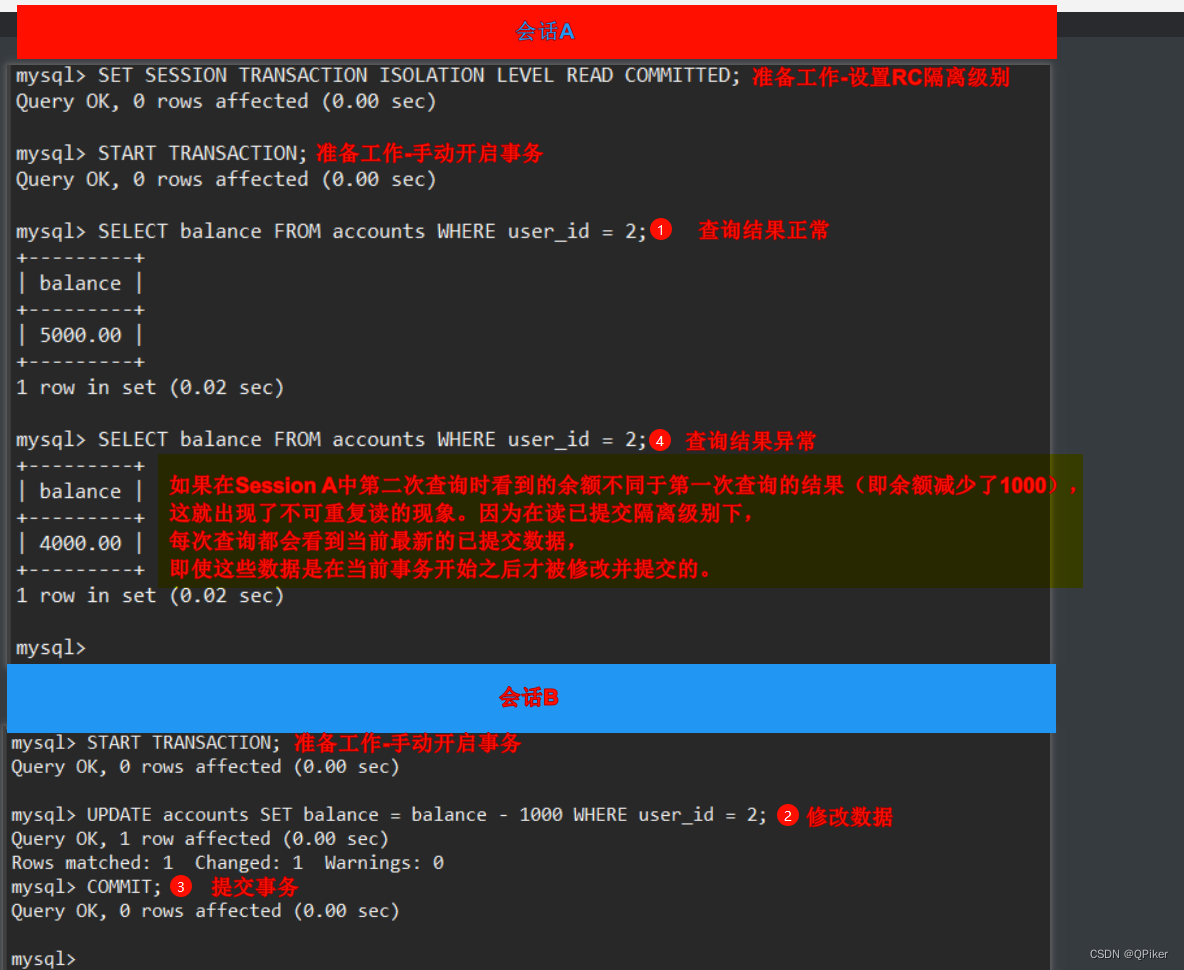
2.读已提交 (Read Committed):
在这个级别,一个事务只能看到已经提交的数据,即事务开始时已经存在的数据以及在其执行过程中其他事务提交的数据。这避免了脏读,但仍然可能出现不可重复读和幻读。
3.可重复读 (Repeatable Read):
这是MySQL InnoDB存储引擎默认的隔离级别。在一个事务内多次执行相同的查询语句将得到相同的结果,即使在这期间有其他事务对数据进行了修改并提交。InnoDB通过MVCC机制实现了这一特性,但需要注意的是,由于新插入的行可能满足查询条件,所以无法完全防止幻读现象的发生。
已提交都和可重复读的区分:
不可重复读 (Non-repeatable Read):
- 不可重复读指的是在一个事务内,同一个查询在同一时刻多次执行却返回了不同的结果。这是因为其他事务在这两次查询之间修改并提交了数据。
- 例如,在一个事务中第一次查询某个用户的账户余额是1000元,然后事务没有结束,另一个事务修改了这个用户的账户余额至2000元并提交了事务。当第一个事务再次查询时,发现用户余额已经变为2000元,这就是不可重复读。

幻读 (Phantom Read):
- 幻读特别关注的是范围查询。即使在可重复读隔离级别下,如果一个事务执行了一个范围查询(比如根据某个条件查找所有记录),而在此事务还未结束时,另一个事务插入了满足该查询条件的新记录并提交,那么第一个事务再次执行相同的范围查询时,会看到新增的“幻影”记录,尽管它在第一次查询时尚不存在。
- 例如,在一个事务中查询某个时间段内的所有订单,得到5个订单;而在事务执行过程中,另一个事务插入了一条新的、也符合此时间段条件的订单并提交。当第一个事务再次执行相同的时间段查询时,结果包含了6个订单,多出的一个就是“幻读”
4.串行化 (Serializable):
这是最高的事务隔离级别,提供严格的事务隔离。在此级别下,事务会按一定的顺序依次执行,如同单线程一样,从而避免了脏读、不可重复读和幻读。为了达到这种效果,通常需要使用表级锁或更高级别的锁定策略,但这可能会导致严重的并发性能下降。
总结
事务的隔离级别是数据库系统中用于控制并发事务之间相互影响的程度。按照SQL标准定义,主要有四种事务隔离级别:
- 读未提交(Read Uncommitted)
- 在这种隔离级别下,一个事务可以读取到另一个事务尚未提交的数据更改。
- 问题:由于允许读取未提交数据,可能导致脏读(Dirty Read),即事务读到了其他事务未提交且可能回滚的数据。
- 优点:并发性能最高,但数据一致性最低。
- 读已提交(Read Committed)
- 在这个级别,一个事务只能看到已经提交的数据,每次查询时都会获取最新的提交版本。
- 问题:虽然避免了脏读,但在同一事务内执行相同的查询可能会得到不同的结果,即出现不可重复读(Non-repeatable Read)现象。
- 优点:相比于读未提交,提高了数据一致性,但仍可能出现可重复问题。
- 可重复读(Repeatable Read)
- MySQL InnoDB存储引擎默认的事务隔离级别。
- 在此级别下,事务开始后对某一行的多次查询将返回相同的结果,即使在查询期间该行被其他事务修改并提交。
- 问题:尽管避免了脏读和不可重复读,但由于不锁定新插入的满足查询条件的记录,仍然可能出现幻读问题。
- InnoDB中的改进:通过使用Next-Key Locks(间隙锁+记录锁)机制,在一定程度上解决了幻读问题。
- 串行化(Serializable)
- 最高的事务隔离级别,提供严格的事务隔离。
- 在这个级别下,事务会按一定的顺序依次执行,如同单线程一样,从而避免了脏读、不可重复读和幻读。
- 问题:为了实现完全的隔离性,通常需要采用更为严格的锁定策略,这可能会导致严重的并发性能下降,特别是在高并发场景下。
**:为了实现完全的隔离性,通常需要采用更为严格的锁定策略,这可能会导致严重的并发性能下降,特别是在高并发场景下。
总结来说,不同的事务隔离级别提供了不同级别的并发性和数据一致性之间的平衡。选择适当的事务隔离级别应根据具体业务需求来确定。在实际应用中,开发者往往会在并发性能和数据一致性之间做出权衡,以达到最佳的系统设计效果。
文章来源:https://blog.csdn.net/m0_62649352/article/details/135617786
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!