Canal使用详解
Canal介绍
Canal是阿里巴巴开发的MySQL binlog增量订阅&消费组件,Canal是基于MySQL二进制日志的高性能数据同步系统。在阿里巴巴集团中被广泛使用,以提供可靠的低延迟增量数据管道。Canal Server能够解析MySQL Binlog并订阅数据更改,而Canal Client可以将更改广播到任何地方,例如数据库和Apache Kafka。Canal支持所有平台,细粒度系统监视,通过不同方式解析和预订MySQL Binlog,以及高性能、实时数据同步。同时,Canal Server和Canal Client均支持由Apache ZooKeeper支持的HA/可伸缩性。
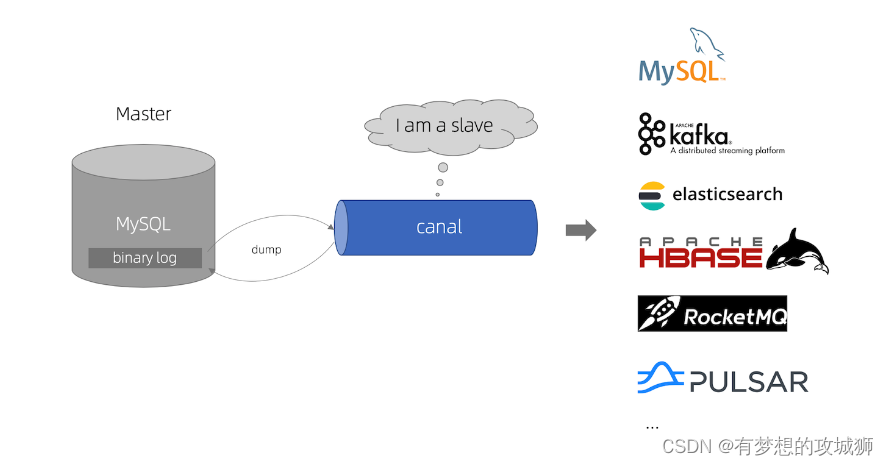
组件原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
组件特点
阿里巴巴的Canal组件的特点主要包括:
- 高性能和可扩展性 :Canal采用了多线程处理和分布式架构,能够实现高吞吐量和低延迟的数据同步。同时,它还支持动态调整数据同步的规模,以适应不同场景的需求。
- 灵活的数据同步方式 :Canal支持多种数据同步方式,包括全量同步、增量同步和混合同步等。可以根据实际需求选择最合适的方式,以达到最佳的数据同步效果。
- 数据一致性保证 :Canal通过Binlog解析和数据校验等方式,保证数据同步的一致性。在数据同步过程中,它会进行数据校验和重试机制,确保数据准确无误地传输到目标系统。
- 丰富的数据接口 :Canal提供了丰富的数据接口,包括数据库连接器、消息队列、缓存等。这些接口可以帮助开发者轻松地获取和传输数据,同时也可以与其他系统进行集成和交互。
- 自动化和智能化 :Canal提供了自动化和智能化的监控和告警功能。在数据同步过程中,可以实时监控各种指标,包括同步延迟、错误率等。如果出现异常情况,会及时发出告警,以便及时处理和解决问题。
- 易于使用和部署 :Canal的安装和部署非常简单,只需要将Canal Server部署到目标数据库所在的服务器上即可。同时,Canal提供了丰富的配置选项和API接口,可以根据实际需求进行灵活配置和定制化开发。
阿里巴巴的Canal组件具有高性能、可扩展性、数据一致性保证、丰富的数据接口、自动化和智能化以及易于使用和部署等特点。
Canal组件支持数据库
- MySQL
- Oracle
- SqlServer
- PostgreSQL
- Redis
- MQ
- ES
Canal的优缺点
Canal是一个基于MySQL数据库的增量日志解析组件,提供增量数据订阅和消费。其优点如下:
可靠性高:Canal通过解析MySQL的增量日志,能够实时追踪数据库的变化,并将数据同步到目标系统,确保数据的完整性和一致性。数据实时性高:Canal支持实时数据同步,能够将数据库中的数据变化实时推送到目标系统,大大提高了数据的实时性。灵活性高:Canal提供了丰富的配置选项和API接口,可以根据实际需求进行灵活配置和定制化开发,满足不同场景的数据同步需求。高效性能:Canal采用了多线程处理和分布式架构,能够实现高吞吐量和低延迟的数据同步,提高数据传输的效率。易于使用和部署:Canal的安装和部署非常简单,只需要将Canal Server部署到目标数据库所在的服务器上即可。同时,提供了丰富的文档和社区支持,方便开发者使用和解决问题。
Canal也存在一些缺点:
1. 对MySQL版本有限制:Canal主要支持MySQL数据库,并且对MySQL的版本有限制,如5.1.x、5.5.x、5.6.x、5.7.x、8.0.x等。对于其他数据库的支持不够完善。
2. 数据一致性问题 :在数据同步过程中,如果目标系统中的数据与源数据库中的数据不一致,可能会引发数据一致性问题。需要开发者谨慎处理数据同步过程中的异常情况。
3. 性能问题 :在处理大量数据和高并发的场景下,Canal可能会遇到性能瓶颈。需要对Canal进行优化和升级,以提高其性能和稳定性。
4. 维护成本高 :由于Canal是一个相对较新的组件,其维护成本可能会比一些成熟的组件高。需要开发者具备较高的技术水平和经验,以便更好地使用和维护Canal。
阿里巴巴的Canal是一个高性能、可扩展、易于使用和部署的数据同步组件。但也需要在使用过程中注意其限制和潜在的问题,以确保数据同步的可靠性和稳定性。
集群部署方案
Canal的集群部署方案主要包括以下步骤:
- 准备环境:首先需要准备相应的环境,包括JDK、MySQL、Zookeeper等。其中,JDK需要使用1.8版本,MySQL用于存储Canal的元数据,Zookeeper用于实现Canal的HA和高可用性。
- 下载安装:从Canal的GitHub发布页面下载最新的Canal二进制包,解压后放置到合适的位置。
- 配置Canal:根据实际情况,配置Canal的参数,包括MySQL和Zookeeper的地址等。同时,需要配置Canal的sharding规则,指定哪些数据库需要同步,以及同步的数据范围等。
- 启动Canal:启动Canal集群中的节点,每个节点都需要启动Canal Server和Canal Client两个进程。Canal Server主要负责接收数据库的增量日志,而Canal Client负责将这些日志同步到目标系统。
- 监控维护:需要定期查看Canal的运行状态,包括节点状态、同步情况等。同时,也需要及时处理异常和问题,保证Canal的正常运行。
需要注意的是,在集群部署中,为了保证高可用性和数据一致性,需要将Canal节点部署在不同的服务器上,避免单点故障的发生。同时,也需要根据实际情况选择合适的同步方式,如全量同步、增量同步等。
集群部署数据一致性保证
在Canal的集群部署中,为了保证数据的一致性,需要采取一些措施来实现。以下是一些可能的方案:
- 分布式事务 :使用分布式事务来保证数据的一致性。当Canal集群中的节点进行数据同步时,可以借助分布式事务来确保数据的完整性和一致性。
- 数据校验 :在数据同步过程中,对数据进行校验,确保数据的一致性。可以使用校验和、哈希等方式进行数据校验,以确保数据的准确性和完整性。
- 故障恢复 :在节点故障或网络故障等异常情况下,需要采取相应的措施进行故障恢复,以保证数据的一致性。可以使用Zookeeper等分布式协调服务来实现故障自动恢复和数据一致性保证。
- 数据备份和恢复 :定期对Canal集群中的数据进行备份,以防止数据丢失和损坏。在数据丢失或损坏的情况下,可以及时进行数据恢复,以保证数据的一致性。
- 监控和维护 :定期监控Canal集群的运行状态和数据同步情况,及时发现和处理异常和问题,以保证数据的一致性。
需要注意的是,在实现数据一致性的过程中,需要考虑性能和可用性的平衡。不能为了追求数据一致性而牺牲性能和可用性。需要根据实际情况选择合适的方案,并进行充分的测试和验证。
Java应用案例
Canal是开源的一个基于数据库增量日志解析的数据同步工具,主要用于实时数据同步和数据订阅的场景。以下是使用Canal进行Java开发的示例:
- 引入Canal客户端依赖
在Java项目中,需要引入Canal客户端的依赖,可以通过Maven或Gradle等构建工具进行引入。以Maven为例,可以在pom.xml文件中添加以下依赖:
<dependency>
<groupId>com.alibaba.canal</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.5</version>
</dependency>
- 创建Canal客户端连接
在Java代码中,需要创建Canal客户端连接,并指定Canal服务器的地址和端口号。示例代码如下:
import com.alibaba.canal.client.CanalConnector;
import com.alibaba.canal.client.CanalConnectors;
public class CanalClientExample {
public static void main(String[] args) {
// 创建Canal客户端连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost", 11111), "example", "", "");
try {
// 连接Canal服务器
connector.connect();
// 订阅数据库表
connector.subscribe(".*\\..*");
// 处理数据变更事件
connector.rollback();
while (true) {
Message message = connector.getWithoutAck(100L); // 获取数据变更事件
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
Thread.sleep(1000);
} else {
// 处理数据变更事件
process(message.getEntries());
// 确认处理完成
connector.ack(batchId);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭Canal客户端连接
connector.disconnect();
}
}
}
在示例代码中,我们首先创建了一个Canal连接器,指定了Canal服务器的地址和端口号,以及要订阅的数据库表。然后,通过调用connect()方法连接Canal服务器,通过调用subscribe()方法订阅数据库表。最后,使用getWithoutAck()方法获取数据变更事件,并处理事件。处理完成后,调用ack()方法确认处理完成。最后,在程序结束时,需要调用disconnect()方法关闭Canal客户端连接。
需要注意的是,在实际使用中,需要根据具体的业务场景和需求进行定制化开发。例如,可以通过实现自定义的数据处理逻辑、使用过滤器过滤无用的数据变更事件等方式来优化数据处理效率。同时,也需要注意异常处理和性能优化等方面的问题。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言K&R圣经笔记 4.10递归 4.11 C预处理
- 搭建DHCP 服务
- AUTOSAR中 CAN总线数据通过COM模块收发流程
- 工智能基础知识总结--什么是RNN
- 提升WiFi安全的有效措施
- 很想写一个框架,比如,spring
- 微服务治理:为什么要分析微服务的依赖关系?
- 【Flink on k8s】- 14 - Flink kubernetes operator 使用经验分享
- 开源的局域网文件共享工具更新到v1.0啦
- K8S从harbor中拉取镜像的规则imagePullPolicy