Transform环境搭建与代码调试——Attention Is All Y ou Need
发布时间:2023年12月28日
1、源代码
2、环境搭建
conda create -n transform python=3.8 -y
conda activate transform
cd /media/lhy/Transforms/annotatedtransformer
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# # Uncomment for colab
pip install -q torchdata==0.3.0 torchtext==0.12 spacy==3.2 altair GPUtil -i https://pypi.tuna.tsinghua.edu.cn/simple
python -m spacy download de_core_news_sm
python -m spacy download en_core_web_sm
#或者离线下载
pip install de_core_news_sm-3.2.0-py3-none-any.whl
pip install en_core_web_sm-3.2.0-py3-none-any.whl
3、构建Teamsform模型(Model Architecture)
1、编码器、解码器以及预测部分
class EncoderDecoder(nn.Module):
"""
A standard Encoder-Decoder architecture. Base for this and many
other models.
"""
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(EncoderDecoder, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):
"Define standard linear + softmax generation step."
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return log_softmax(self.proj(x), dim=-1)
Transformer遵循这个整体架构,使用堆叠的自关注层和点方向层,完全连接编码器和解码器层,分别如图1的左半部分和右半部分所示。
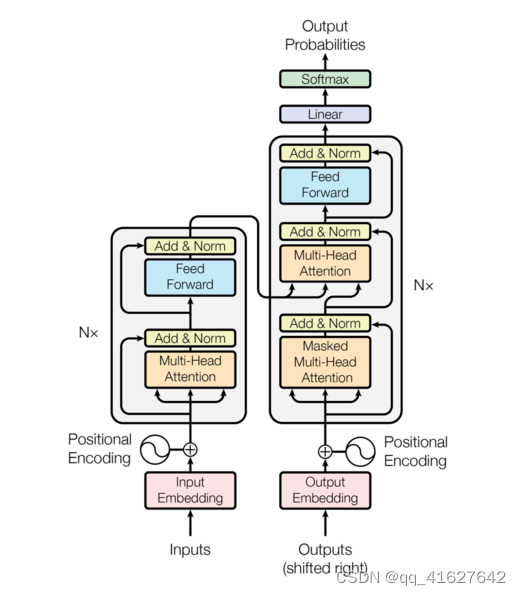
2、Encoder and Decoder Stacks
def clones(module, N):
"Produce N identical layers."
return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):
"Core encoder is a stack of N layers"
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
"Pass the input (and mask) through each layer in turn."
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_2
class SublayerConnection(nn.Module):
"""
A residual connection followed by a layer norm.
Note for code simplicity the norm is first as opposed to last.
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
"Apply residual connection to any sublayer with the same size."
return x + self.dropout(sublayer(self.norm(x)))
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
"Follow Figure 1 (left) for connections."
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
def subsequent_mask(size):
"Mask out subsequent positions."
attn_shape = (1, size, size)#batch=1
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)#保留主对角线以上的数据
return subsequent_mask == 0
结果保留主对角线及以下的数据
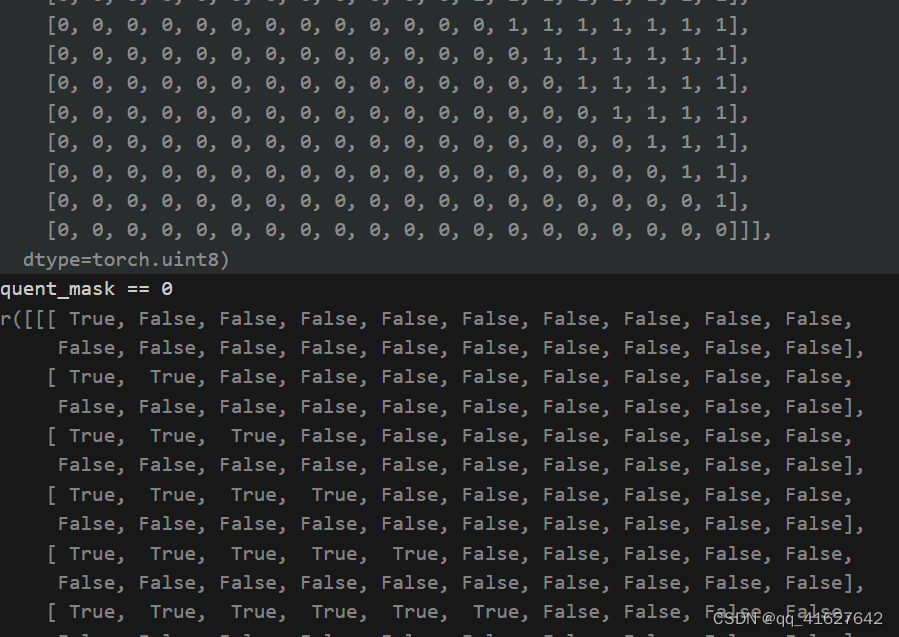
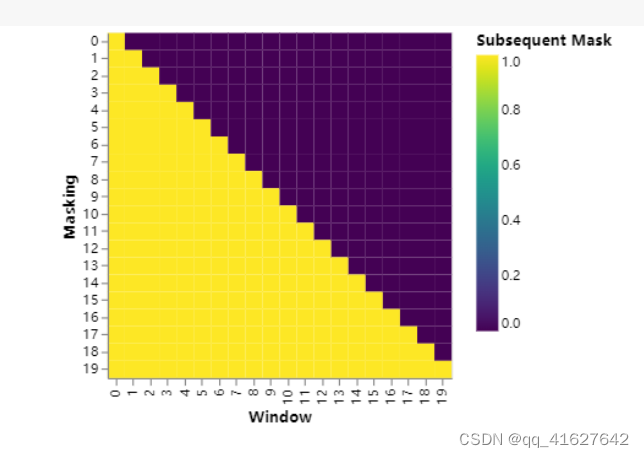
attention
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for lin, x in zip(self.linears, (query, key, value))
]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
x = (
x.transpose(1, 2)
.contiguous()
.view(nbatches, -1, self.h * self.d_k)
)
del query
del key
del value
return self.linears[-1](x)
FFN
class PositionwiseFeedForward(nn.Module):
"Implements FFN equation."
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(self.w_1(x).relu()))
Embeddings and Softmax
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
Positional Encoding
class PositionalEncoding(nn.Module):
"Implement the PE function."
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
return self.dropout(x)
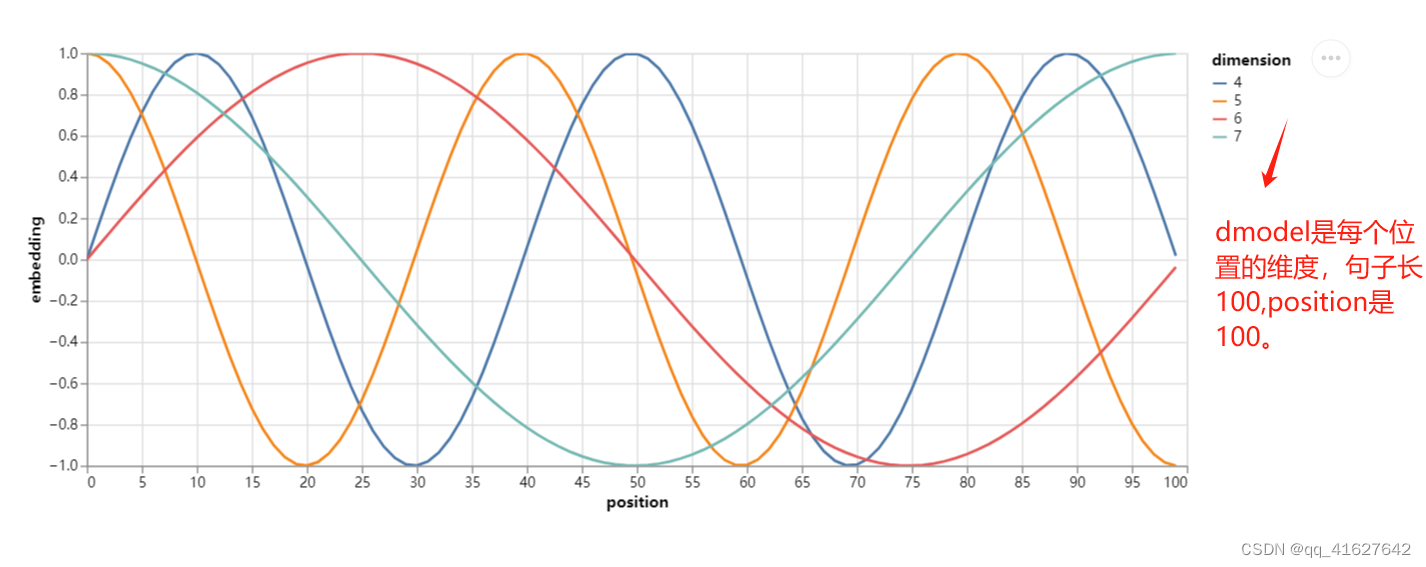
Optimizer

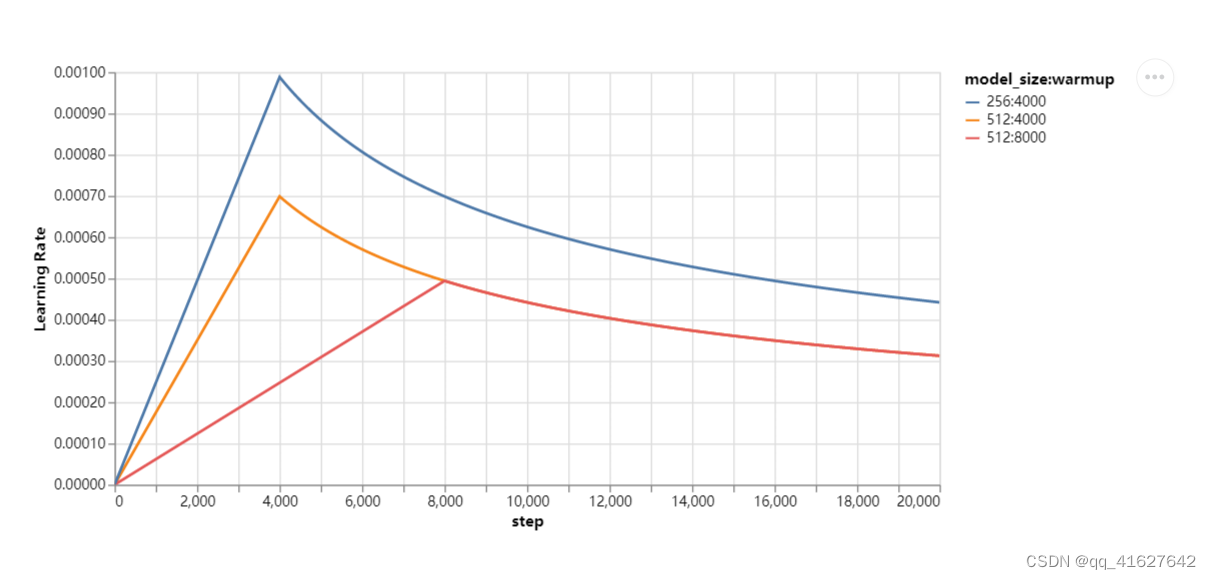
这对应于在第一个warmup_steps训练步骤中线性增加学习率,然后按步数的倒数平方根成比例地降低学习率。我们使用了warmup_steps = 4000。
def rate(step, model_size, factor, warmup):
"""
we have to default the step to 1 for LambdaLR function
to avoid zero raising to negative power.
"""
if step == 0:
step = 1
return factor * (
model_size ** (-0.5) * min(step ** (-0.5), step * warmup ** (-1.5))
)
#---------------------------------4、测试学习率---------------------------------
def example_learning_schedule():
opts = [
[512, 1, 4000], # example 1
[512, 1, 8000], # example 2
[256, 1, 4000], # example 3
]
dummy_model = torch.nn.Linear(1, 1)
learning_rates = []
# we have 3 examples in opts list.
for idx, example in enumerate(opts):
# run 20000 epoch for each example
optimizer = torch.optim.Adam(
dummy_model.parameters(), lr=1, betas=(0.9, 0.98), eps=1e-9
)
print(optimizer.state_dict())
lr_scheduler = LambdaLR(
optimizer=optimizer, lr_lambda=lambda step: rate(step, *example)
)
tmp = []
# take 20K dummy training steps, save the learning rate at each step
for step in range(20000):
tmp.append(optimizer.param_groups[0]["lr"])
optimizer.step()
lr_scheduler.step()
learning_rates.append(tmp)
learning_rates = torch.tensor(learning_rates)
# Enable altair to handle more than 5000 rows
alt.data_transformers.disable_max_rows()
opts_data = pd.concat(
[
pd.DataFrame(
{
"Learning Rate": learning_rates[warmup_idx, :],
"model_size:warmup": ["512:4000", "512:8000", "256:4000"][
warmup_idx
],
"step": range(20000),
}
)
for warmup_idx in [0, 1, 2]
]
)
chart=(alt.Chart(opts_data)
.mark_line()
.properties(width=600)
.encode(x="step", y="Learning Rate", color="model_size:warmup:N")
.interactive())
# 展示数据,调用display()方法
altair_viewer.show(chart)
Regularization
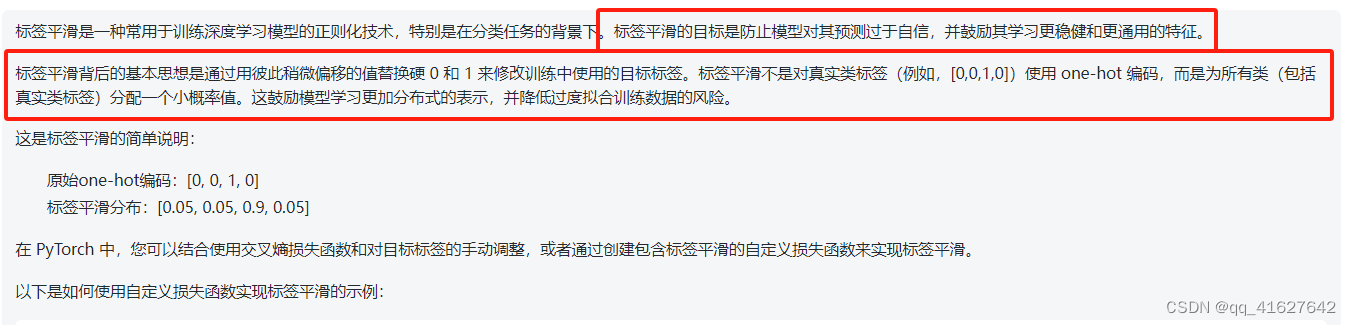
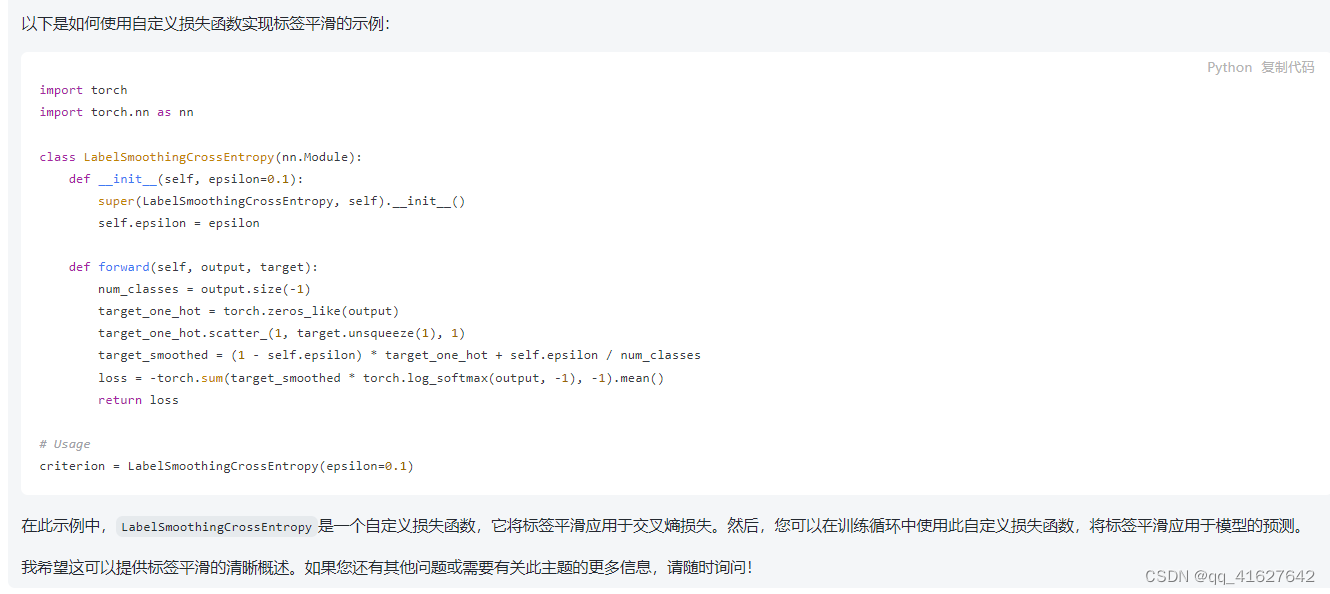
在训练过程中,我们使用值es =0.1的平滑标签。这损害了困惑,因为模型学的更加不确定,但提高了准确性和BLeU分数。
Kullback-Leibler散度损失。
class LabelSmoothing(nn.Module):
"Implement label smoothing."
def __init__(self, size, padding_idx, smoothing=0.0):
super(LabelSmoothing, self).__init__()
self.criterion = nn.KLDivLoss(reduction="sum")
self.padding_idx = padding_idx
self.confidence = 1.0 - smoothing
self.smoothing = smoothing
self.size = size
self.true_dist = None
def forward(self, x, target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing / (self.size - 2))
true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence)
true_dist[:, self.padding_idx] = 0
mask = torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0, mask.squeeze(), 0.0)
self.true_dist = true_dist
return self.criterion(x, true_dist.clone().detach())
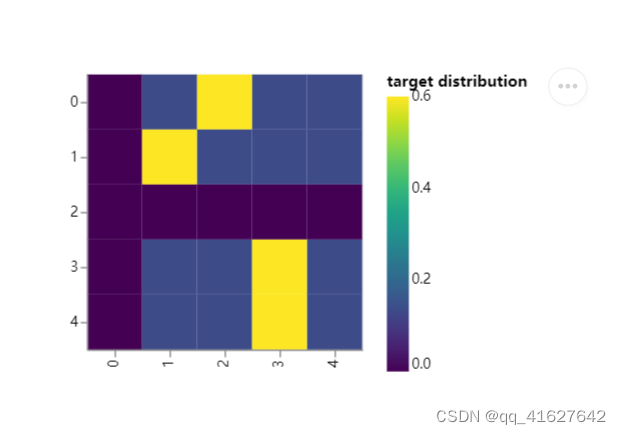
#-------------------5、测试 正则化标签平滑-------------------------------------
def example_label_smoothing():
crit = LabelSmoothing(5, 0, 0.4)
predict = torch.FloatTensor(
[
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
]
)
crit(x=predict.log(), target=torch.LongTensor([2, 1, 0, 3, 3]))
LS_data = pd.concat(
[
pd.DataFrame(
{
"target distribution": crit.true_dist[x, y].flatten(),
"columns": y,
"rows": x,
}
)
for y in range(5)
for x in range(5)
]
)
chart= (
alt.Chart(LS_data)
.mark_rect(color="Blue", opacity=1)
.properties(height=200, width=200)
.encode(
alt.X("columns:O", title=None),
alt.Y("rows:O", title=None),
alt.Color(
"target distribution:Q", scale=alt.Scale(scheme="viridis")
),
)
.interactive()
)
# 展示数据,调用display()方法
altair_viewer.show(chart)
数据加载解析
模型训练解析
模型测试解析
问题
1、无法从 http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/training.tar.gz 获取文件。[请求异常] 无
离线下载放入缓存
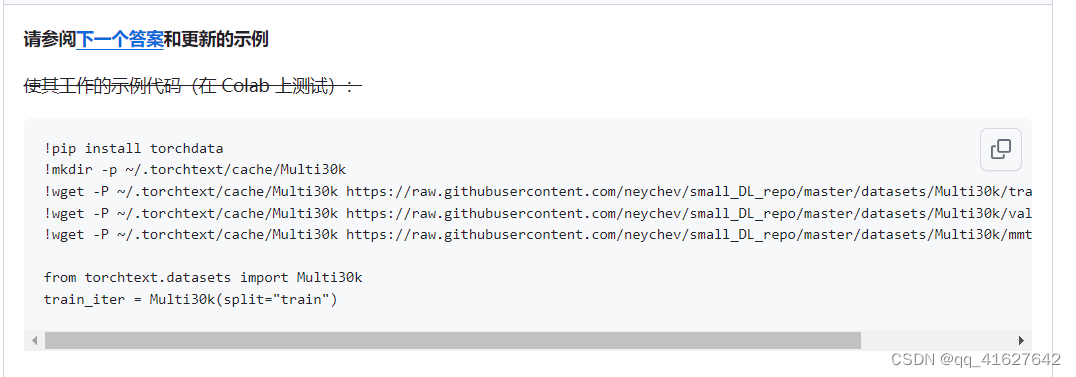
或者修改URL
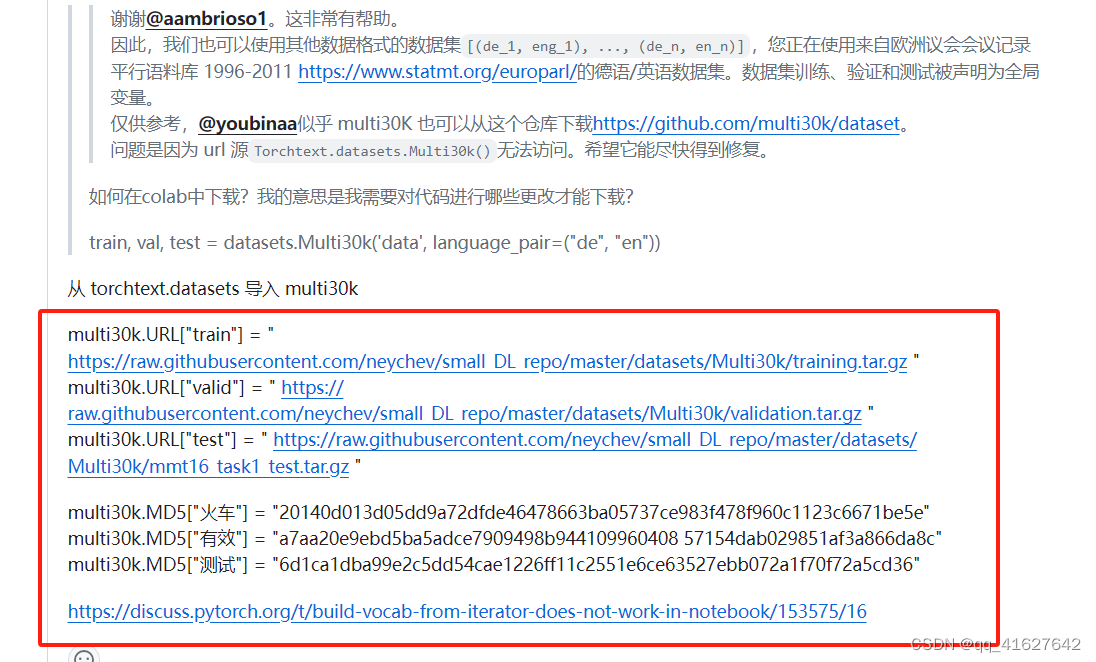
2、

pip install altair_viewer==0.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
文章来源:https://blog.csdn.net/qq_41627642/article/details/133157657
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 建站指南,如何将拥有的域名自定义链接到wordpress
- 华为发布的工业软件三大难题:适用于CAD领域的NURBS裁剪曲面自交快速检测
- 每日一练 | 华为认证真题练习Day38
- DOTA 铭文如何与 Polkadot 生态深度交互?
- 【MySQL】存储引擎
- Maya-UE xgen-UE 毛发导入UE流程整理
- 圈子论坛社交实名制系统---H5小程序APP,三端源码交付,允许二开!PHP系统uni书写!
- Linux基础——进程初识(三)
- 【教3妹学编程-算法题】赎金信
- 【12.3K?】ChatALL:一款让你同时与多个AI模型对话的软件