机器学习_7、KNN
发布时间:2024年01月11日
数据采用:电离层数据
代码
import os
import csv
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
from matplotlib import pyplot as plt
from collections import defaultdict
data_filename = "电离层数据\\ionosphere.data"
X = np.zeros((351, 34), dtype='float')
y = np.zeros((351,), dtype='bool')
with open(data_filename, 'r') as input_file:
reader = csv.reader(input_file)
# print(reader) # csv.reader类型
for i, row in enumerate(reader):
data = [float(datum) for datum in row[:-1]]
# Set the appropriate row in our dataset
X[i] = data
# 将“g”记为1,将“b”记为0。
y[i] = row[-1] == 'g'
# 划分训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=14)
# 即创建估计器(K近邻分类器实例) 默认选择5个近邻作为分类依据
estimator = KNeighborsClassifier()
# 进行训练,
estimator.fit(X_train, y_train)
# 评估在测试集上的表现
y_predicted = estimator.predict(X_test)
# 计算准确率
accuracy = np.mean(y_test == y_predicted) * 100
print("The accuracy is {0:.1f}%".format(accuracy))
# 进行交叉检验,计算平均准确率
scores = cross_val_score(estimator, X, y, scoring='accuracy')
average_accuracy = np.mean(scores) * 100
print("The average accuracy is {0:.1f}%".format(average_accuracy))
#由于KNN算法对于近邻K的选择依赖度较大,因此需要用实验法确定K值
#在1到20之间确定K值,记录不同K值下的准确率
avg_scores = []
all_scores = []
parameter_values = list(range(1, 21)) # Including 20
for n_neighbors in parameter_values:
estimator = KNeighborsClassifier(n_neighbors=n_neighbors)
scores = cross_val_score(estimator, X, y, scoring='accuracy')
avg_scores.append(np.mean(scores))
all_scores.append(scores)
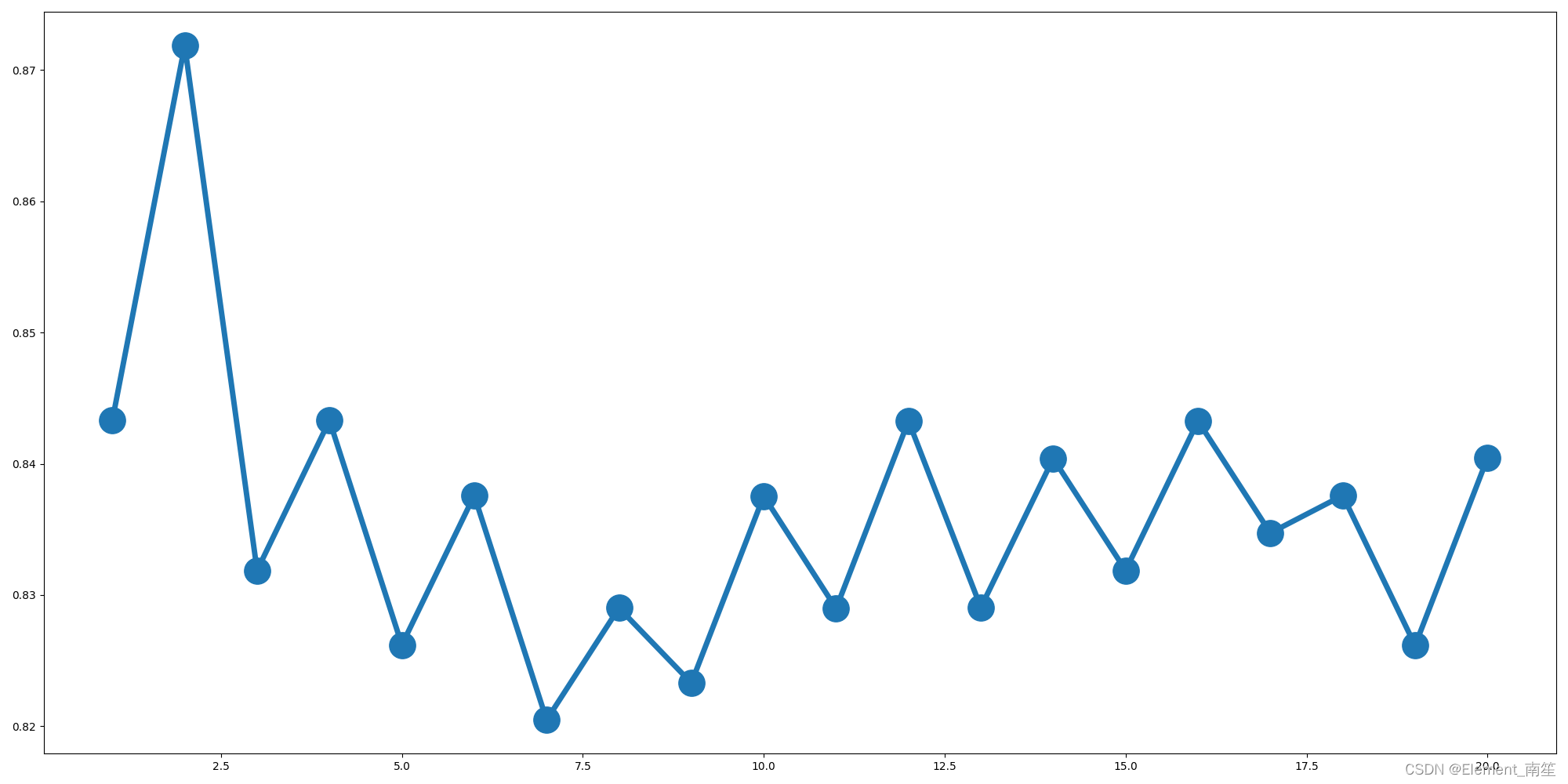
# 绘制n_neighbors的不同取值与分类正确率之间的关系
plt.figure(figsize=(20, 10))
plt.plot(parameter_values, avg_scores, '-o', linewidth=5, markersize=24)
plt.show()
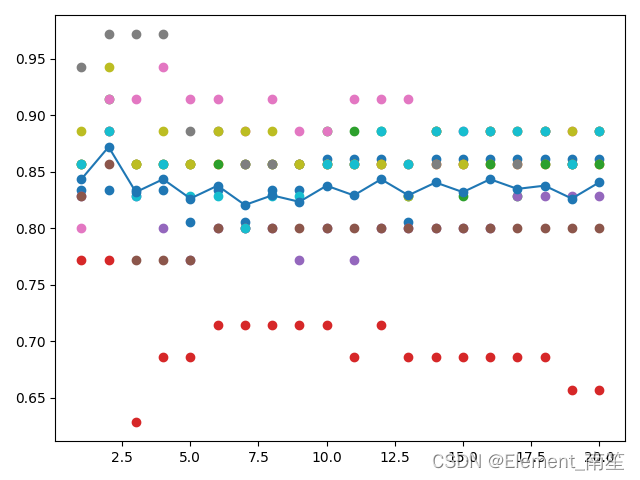
#交叉检验
all_scores = defaultdict(list)
parameter_values = list(range(1, 21)) # Including 20
for n_neighbors in parameter_values:
estimator = KNeighborsClassifier(n_neighbors=n_neighbors)
scores = cross_val_score(estimator, X, y, scoring='accuracy', cv=10)
all_scores[n_neighbors].append(scores)
for parameter in parameter_values:
scores = all_scores[parameter]
n_scores = len(scores)
plt.plot([parameter] * n_scores, scores, '-o')
plt.plot(parameter_values, avg_scores, '-o')
plt.show()
#由图可知K取2的情况下准确率最高,因此确定K值为2
#以k值为2重新训练最近邻分类器,并输出结果
Estimator = KNeighborsClassifier(n_neighbors=2)
Estimator.fit(X_train, y_train)
Y_predicted = Estimator.predict(X_test)
accuracy = np.mean(y_test == Y_predicted) * 100
pre_result = np.zeros_like(Y_predicted, dtype=str)
pre_result[Y_predicted == 1] = 'g'
pre_result[Y_predicted == 0] = 'b'
print(pre_result)
print("The accuracy is {0:.1f}%".format(accuracy))

 ?
?
文章来源:https://blog.csdn.net/cfy2401926342/article/details/135538527
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 0012Java安卓程序设计-ssm记账app
- (23)Linux的软硬连接
- 各大护眼台灯品牌改如何挑选?多款护眼台灯测评大对比
- 举个栗子!Tableau 技巧(261):自由切换图表的背景颜色
- Linux Mii management/mdio子系统分析之三 mii_bus注册、注销及其驱动开发流程
- PostgreSQL10数据库源码安装及plpython2u、uuid-ossp插件安装
- matlab 交通流量PI和P控制
- 动态规划汇总
- 第2章 经济管理与应用数学
- IntelliJ IDEA使用学习