Transformer基本结构
Transformer基本结构
输入部分、编码部分、解码部分、输出部分
1、输入部分
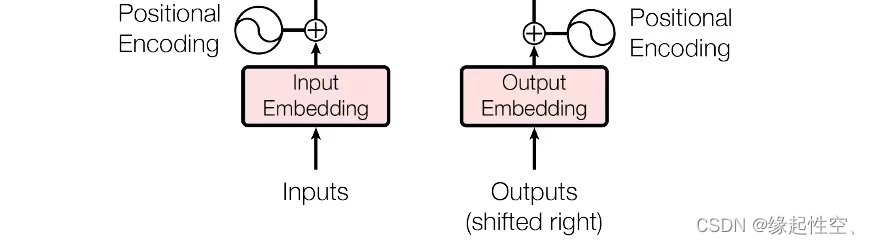
- 原文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
位置编码器(PositionalEncoding):将词汇位置不同可能会产生不同语义的信息加入到词张量中,以弥补位置信息的缺失
文本嵌入层(Embedding):将文本中词汇的数字表示转变为向量表示,实现高纬空间捕捉词汇间的关系
?
2、编码部分

?
自下向上分别是:
- 残差连接
- 多头自注意力子层(Multi-Head Attention)
- 规范化层(Add & Norm)
- 残差连接
- 前馈全连接层(Feed Forward)
- 规范化层(Add & Norm)
残差连接:残差连接就是把网络的输入和输出相加,即网络的输出为F(x)+x,在网络结构比较深的时候,网络梯度反向传播更新参数时,容易造成梯度消失的问题,但是如果每层的输出都加上一个x的时候,就变成了F(x)+x,对x求导结果为1,所以就相当于每一层求导时都加上了一个常数项‘1’,有效解决了梯度消失问题。
多头自注意力子层(Multi-Head Attention):它负责在输入序列中计算每个位置的上下文信息。多头自注意力子层的主要功能是将输入序列中的每个元素与其他所有元素进行交互,从而捕捉到更丰富的上下文信息。
规范化层(Add & Norm):"add&norm"是指在每个子层(Self-Attention和Feed-Forward)的输入和输出之间进行加法和归一化操作。这个操作有助于减轻梯度消失和梯度爆炸问题,并提高模型的训练效果。
前馈全连接层(Feed Forward):Feed Forward的作用是引入非线性变换,增强模型的表示能力。通过Feed Forward,模型可以学习到更复杂的特征表示,从而更好地捕捉输入序列中的上下文信息。
?
3、解码部分?

?
?自下向上分别是:
- 残差连接
- 多头自注意力层(Masked Multi-Head Attention)
- 规范化层(Add & Norm)
- 残差连接
- 多头注意力层(Multi-Head Attention)
- 规范化层(Add & Norm)
- 残差连接
- 前馈全连接层(Feed Forward)
- 规范化层(Add & Norm)
残差连接、规范化层、前馈全连接层解释同编码部分
多头注意力层(Multi-Head Attention):主要作用是将输入序列的信息分散到多个不同的子空间中,然后通过计算这些子空间中的点积来得到每个位置的注意力权重。Multi-Head Attention的结构包括Query、Key和Value。首先,它们会经过一个线性变换,然后输入到缩放点积attention中。这里的“多头”是指这个过程会进行多次,每一次算一个头,每次Q、K、V进行线性变换的参数W是不一样的。然后将多次缩放点积attention的结果进行拼接,再进行一次线性变换得到的值作为Multi-Head Attention的结果。
多头自注意力层(Masked Multi-Head Attention):主要用于处理目标语言,因为在预测下一个词时,我们不能让模型看到下一个词及之后的信息。Masked Multi-Head Attention的原理是在attention机制中引入掩码矩阵,将某个位置的注意力权重强制置为0,从而屏蔽掉该位置的信息。
?
4、输出部分?
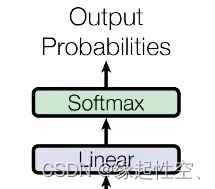
自下而上分别是:
- 线性层(Liner)
- Softmax层
线性层(Liner):通过对上一步的线性变化得到指定维度的输出,也就是转换维度的作用
Softmax层:使得最后一维的向量中的数字缩放到0到1概率值域内,并满足他们的和为1
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RabbitMQ 和 Kafka 对比
- 2023版本QT学习记录 -6- UDP通信之UDP接收端
- 【深度学习每日小知识】Co-occurrence matrix 共现矩阵
- Jmeter和Testlink自动化测试框架研究与实施
- 阿里云日志表盘配置-图上展示想要的名称
- 【Go之道】探索Go语言之旅:基础与进阶指南
- 计算机二级试题——附答案
- DolphinScheduler伪集群部署
- MySQL undo日志精讲2-undo日志写入
- 【MyBatis-Plus】简化你的Java持久层开发