【LLM的概念理解能力】Concept Understanding In Large Language Models: An Empirical Study
大语言模型中的概念理解:一个实证研究
摘要
大语言模型(LLMs)已经在广泛的任务中证明了其卓越的理解能力和表达能力,并在现实世界的应用中显示出卓越的能力。因此,研究它们在学术界和工业界的值得信赖的性能的潜力和局限性是至关重要的。在本文中,我们着重探讨大语言理解概念的能力,特别是抽象概念和具体概念。为此,我们构建了一个基于WordNet的数据集,其中包含一个抽象概念的子集和一个具体概念的子集。我们选择了六个预训练后的大语言模型,并做了一个上下位关系发现这个经典的NLP任务,以作为大语言模型在概念理解方面的(实验)依据。实验结果表明,大语言模型对抽象概念的理解明显弱于对具体概念的理解。
1 介绍
在过去几年里,大语言模型已经成为了学术研究的前沿。最近发布的ChatGPT进一步展示了大语言模型在各种先进技术和工程规划的下游任务中的潜力(Brown et al., 2020)。另一方面,大语言模型理解的能力也会受到其在现实场景中的部署,这使得这一研究问题的探索成为一个新的课题。
本文主要从抽象概念和具体概念的角度来研究大语言模型的理解能力。这种探索的灵感来自于现实世界中不同的任务通常需要不同抽象级别的理解能力。在与物理实体相关的任务中,例如对动物的类型进行分类,可能需要更好地具体概念。相比之下,其他任务要求大语言模型了解更多关于抽象实体的信息,比如区分不同的人类情感或逻辑推理。
为了实现这一步目标,我们首先基于WordNet构建了一个新的数据集D-Concept,这是一个单词之间语义关系的词汇数据库(Miller, 1995)。该数据库遵循着一个经典的NLP任务的上下位关系发现设定,它可以反映语言模型理解抽象和具体概念的能力。WordNet中的名词被明确地分为一个抽象分支和一个物理分支,因此这个数据集是一个合适的先例。因此,我们按照这种划分,分别根据抽象分支和物理分支构造两个子集。每个数据示例由来自相应分支的一对实体组成。上下位关系发现任务是确定这两个实体是否为上下位关系。所探索的大语言模型包括BERT到GPT系列模型(包括OpenAI文本嵌入模型和ChatGPT)。实验结果表明,在上下位关系发现任务中,大语言模型对抽象概念的理解能力要比对具体概念的理解能力更弱,这表明给大语言模型还有(对抽象概念理解能力的)提升空间。
我们的贡献主要在以下几个方面:(1)我们构建了一个新的上下位关系发现的数据集来比较大语言模型对抽象概念和具体概念的理解能力。(2)我们调查了不同尺度下的大语言模型 在该任务上的性能,我们发现随着模型规模的增大,大语言模型的性能有所提升,但在(理解)抽象概念上的性能始终弱于(理解)具体概念。
2 实验
2.1 实验设置
数据集 WordNet(数据集中)将名词分组为认知同义词集,将每个同义词集表示为一个不同的概念,将一个词集作为一个实体。抽象分支和物理分支是WordNet中的两个主要组成部分,分别表示抽象概念(如“公平”和“幸福”)和具体概念(如“动物”和“家具”)。为了探索怎样让大语言模型去表示概念,我们在WordNet数据中,通过GPT嵌入模型(text-similarity-ada-001)构建概念嵌入,再使用T-SNE将概念嵌入可视化。如图1所示,将两类概念嵌入大致分为两个簇,揭示出它们之间确实存在一些差异。
为了更深入地研究这些差异,我们为概念理解任务创建了一个新的数据集,即上位词发现。由于WordNet是一个层次图,其实体是结点,上下位关系是边,故上下位关系(例如:“床”-“家具”,在这里家具是上位词,床是下位词)是WordNet中一个典型地词汇关系。在构建数据集时,我们首先在每个分支上随机选择一个距离值d作为正例(即一个实体与其对应的上位词,因为WordNet是一个树状结构,一个下位词往上不同高度地的祖先都是其上位词)其次,我们随机选择一个实体,然后从一个实体集合中选取第二个实体,其中每个实体与第一个实体的距离为d。(而)负实体对是随机和单独选择的,总共有10000个样本,被拆分为训练集、验证集和测试集,其比例为2:4:4。
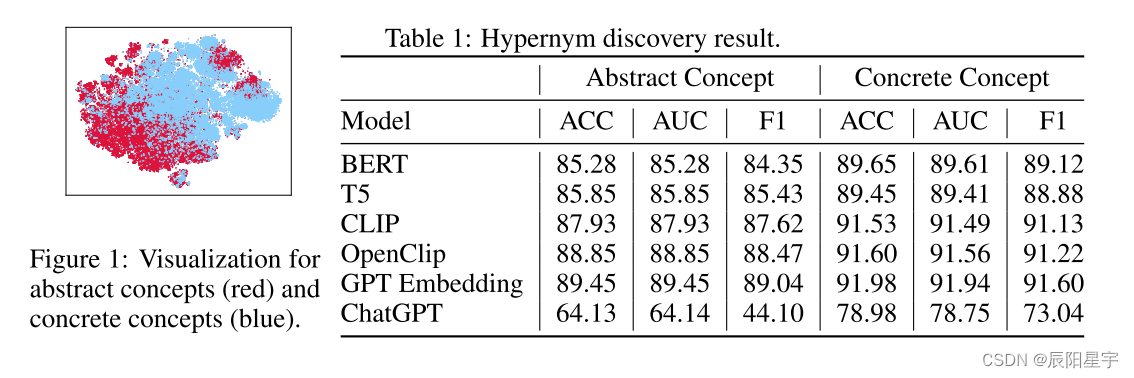
设置 我们比较了六个大语言模型,包括Bert(Devlin et al., 2018),T5(Raffel et al., 2020),CLIP(Radford et al., 2021),OpenCLip(Cherti et al., 2022),GPT嵌入模型(Brown et al., 2020)和ChatGPT。我们冻结它们的嵌入,并添加一个线性层用于二分类,损失函数采用CrossEntropy Loss,精确度(ACC)、AUC和F1评分作为评价指标。对于ChatGPT,我们使用提示-回答范例来获取它的答案(例如,我们使用 “{entity1} the hypernym of {entity2}?” 作为一个提示,从ChatGPT那里获得(返回结果)“Yes”或“No”)
2.2 实验结果
表1显示了大语言模型在上下关系发现任务中表现的性能。我们可以发现,与具体概念相比,大语言模型的抽象概念方面的表现始终较差。这意味着大语言模型在学习高质量的嵌入方面有改进空间,特别是在抽象概念方面。在应用大语言模型时,抽象概念的糟糕结果可能会增加处理与抽象概念相关任务的风险。我们还可以发现,当模型规模增大时,除了ChatGPT之外,其余模型(BERT、T5、CLIP、OpenClip、GPT Embedding)在抽象概念和具体概念任务上的性能都有所提高。在ChatGPT中没有微调过或者少次学习情况下,无法获得嵌入并进行测试。
3 结论
为了探索大语言模型对抽象和具体概念的理解能力,我们构建了一个新的基于WordNet的数据集,用于发现上位词。实验结果表明,无论模型的大小如何,大语言模型都很难理解抽象概念,这启发研究人员未来去缩小大语言模型理解抽象概念这一差距。
A D-CONCEPT 数据集简介
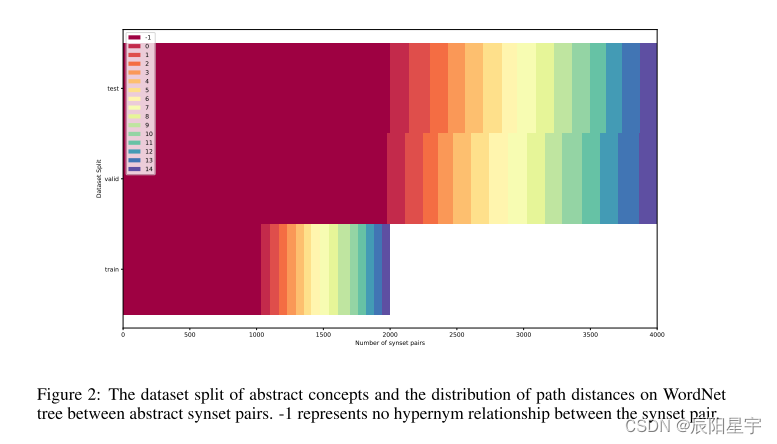
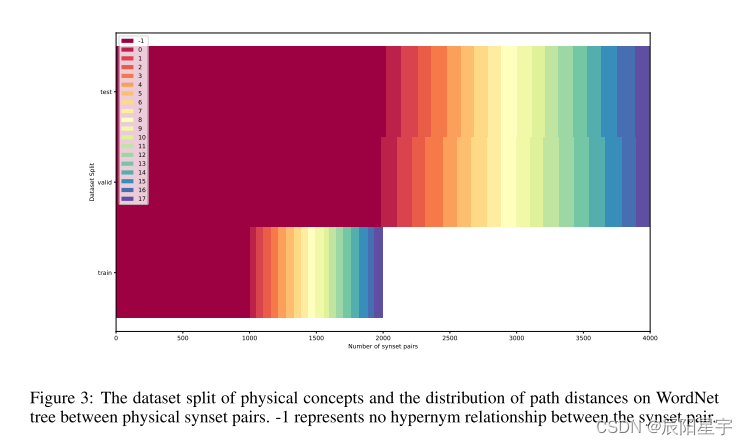
D-Concept数据集总共包括219692个同义词集,它们名称和定义来自WordNet。D-Concept中的同义词对被分成两个子集,一个用于抽象概念,另一个用于具体概念。抽象概念子集中同义词对的一个例子是“蒲式耳”-“容量单位”,(它们之间的)距离d=3,其中蒲式耳是指大英帝国的容量计量单位(液体或干的)等于4克,而体积单位是指体积或容量的度量单位。来自具体概念子集的上位词对的一个例子是“埃尔郡乳牛”-“家牛”,(它们之间的)距离d=2,其中埃尔郡乳牛指的是来组苏格兰埃尔的耐寒奶牛品种,而家牛是不考虑其性别或年龄,作为一个群体而驯养的牛。
同义词对的数量(划分)为2000,4000和4000,将会被分别用于训练,验证和测试。关于数据集的纤细信息,如图2和图3所示。
B 实验细节
主干网络 (1)BERT(Devlin et al., 2018):我们将bert-base-uncased模型pooler层的输出作为嵌入,该嵌入的维度为768。(2)T5(Raffel et al., 2020):我们将google/t5-v1_1-large模型最后一隐藏层的平均池化作为嵌入,该嵌入的维度为1024。(3)CLIP(Radford et al., 2021)和OpenClip(Cherti et al., 2022):我们从CLIP和OpenClip的文本编码器得到的嵌入维度分别为768和1024。(4)GPT系列的模型(Brown et al., 2020):我们采用OpenAI的嵌入服务(text-similarity-ada-001)和OpenAI的聊天完成服务。Text-similarity-ada-001的嵌入维度是1024,而ChatGPT的提示是 “Is {synset-1} a hypernym of {synset-2}? {synset-1} means {the definition of synset-1}. {synset-2} means {the definition of synset-2}. Please directly answer YES or NO. (Do not return any explanation or any additional information.)”({synset-1} 是 {synset-2} 的上位词吗?{synset-1} 代表 {synset-1的定义},{synset-2} 代表 {synset-2的定义}。请直接回答“是”或“否”(你不能返回任何解释或者任何其他附加信息))。为ChatGPT提供同义词集的目的是为了帮助实体消除歧义,格式化的ChatGPT的答案有助于为评估的后处理。
训练过程 如果经过20个epoch后的损失不减少,学习率将会下降到原来的1/3。每个10个epoch进行一次验证,根据AUC选取最有模型。如果在验证集上得到的AUC在100个epoch内没有增加,则采用早停法(提前停止训练)。在[0.0001, 0.1]范围内对MLP参数的学习速率进行对数均匀搜索。表1中的每一个结果都是经过40次实验的最佳结果。
C 相关工作
在概念理解中的大语言模型 虽然大语言模型在各种NLP任务中表现出了非凡的能力,但人们对大语言模型是否具有概念理解的能力,或者它们的强大的性能是否仅归因于模型规模增大时发现的统计相关性而存在激烈的争议(Mitchell & Krakauer, 2023)。Sahu等人(2022)致力于探索大语言模型能否是否能够理解概念。我们选择从大语言模型对抽象概念的理解能力这一角度,来分析上述问题。
在上位词发现任务中的大语言模型 先前的研究,如Vuli′c等人(2020)和Hanna & Mareˇcek(2021)利用词汇关系预测(包括上位词发现)等任务探索了大语言模型中的语言知识(如:BERT)。这表明大语言模型对上位词的知识仍然是有限的。上位词发现数据集是一种经典的NLP任务,也在Baroni & Lenci(2011)、Snow et al.(2004)、Roller et al.(2014)、Vyas & Carpuat(2017)、Camacho-Collados et al.(2018)等许多著作中提出。然而,我们的D-Concept数据集是基于WordNet数据集将概念对明确的划分为抽象概念和具体概念对,并分别对其进行上位词发现任务。这种数据集的形成更便于研究抽象概念的理解。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 在机器学习领域,有一个备受瞩目的概念——Kernel(核函数)
- SDRAM小项目(1)
- kubuctl patch 直接修改yaml文件,不使用edit
- VD6283TX环境光传感器(2)----移植闪烁频率代码
- ios 上textarea placeholder不换行的问题
- 如何本地部署虚VideoReTalking
- 翻译: Pyenv管理Python版本从入门到精通二
- MyBatis-Flex 尝鲜
- Redis 过期删除策略、内存回收策略、单线程理解
- 阶段三-Day05-JDBC