TensorRt(5)动态尺寸输入的分割模型测试
这里主要说明使用TensorRT进行加载编译优化后的模型engine进行推理测试,与前面进行目标识别、目标分类的模型的网络输入是固定大小不同,导致输入维度不能直接获取需要自己手动调整的问题。
1、固定输入尺寸逻辑
基本逻辑如下:
- 读取engine文件到内存
- 使用TensorRT运行时
IRuntime序列化一个引擎ICudaEngine,在创建一个上下文对象IExecutionContext - 从引擎中
ICudaEngine获取输入、输出的纬度和数据类型,并分配显存 - 将输入从host内存中拷贝到输入device显存中
- 利用创建的上下文对象
IExecutionContext执行推理 - 将推理结果从输出device显存拷贝到host内存中
至于显存分配,根据engine是可以获取网络输入输出的尺寸的。以前面 【TensorRt(3)mnist示例中的C++ API】 博客中的简要代码为例说推理代码路程:
int simple2()
{
/// 2.1 加载engine到内存
// .... 省略
std::vector<char> buf(buflen);
// ....
/// 2.2 反序列化
std::unique_ptr<IRuntime> runtime{ createInferRuntime(sample::gLogger.getTRTLogger()) };
auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
runtime->deserializeCudaEngine(buf.data(),buf.size()),[](nvinfer1::ICudaEngine* p) {delete p; });
// inference上下文
auto context = std::unique_ptr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
// 网络输入、输出信息
auto mInputDims = mEngine->getBindingDimensions(0); // 部署使用 [1,1,28,28]
auto mOutputDims = mEngine->getBindingDimensions(1); // 部署使用 [1,10]
int inputH = mInputDims.d[2];
int inputW = mInputDims.d[3];
//---------- 整个网络输入只有1个,输出只有1个,且均为float类型,分配cuda显存
std::vector<void*> bindings(mEngine->getNbBindings());
for (int i = 0; i < bindings.size(); i++) {
nvinfer1::DataType type = mEngine->getBindingDataType(i);// 明确为 float
size_t volume =
sizeof(float) * std::accumulate(dims.d,dims.d + dims.nbDims,1,std::multiplies<size_t>());
CHECK(cudaMalloc(&bindings[i],volume));
}
// 加载一个random image
srand(unsigned(time(nullptr)));
std::vector<uint8_t> fileData(inputH * inputW);
// 省略....
//---------- 输入host数据类型从uint8_t转换为float, 这里明确知道 1*1*28*28
std::vector<float> hostDataBuffer(1 * 1 * 28 * 28);
for (int i = 0; i < inputH * inputW; i++) {
hostDataBuffer[i] = 1.0 - float(fileData[i] / 255.0);
}
//---------- 将图像数据从host空间拷贝到device空间
CHECK(cudaMemcpy(bindings[0],static_cast<const void*>(hostDataBuffer.data()),hostDataBuffer.size() * sizeof(float), cudaMemcpyHostToDevice));
//---------- excution执行推理
bool status = context->executeV2(bindings.data());
/// 2.3 处理推理结果数据,
//---------- 将推理结果从device空间拷贝到host空间
std::vector<float> pred(1 * 10); // 这里明确知道 1*10)
CHECK(cudaMemcpy(static_cast<void*>(pred.data()),bindings[1], pred.size() * sizeof(float),cudaMemcpyDeviceToHost));
// .... 省略
}
2、动态输入尺寸
以paddle中的语义语义分割模型 OCRNet + backbone HRNet_w18 为例进行说明测试。
2.1、模型导出
默认训练模型导出推理模型是不带softmax和argmax层的,为避免后续实现效率降低,添加这两层之再导出推理模型,使用paddle2onnx导出onnx模型,
paddle2onnx --model_dir saved_inference_model \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_file model.onnx \
--enable_dev_version True
# --opset_version 12 # default 9
使用netron工具查看输入和输出的尺寸信息截图如下
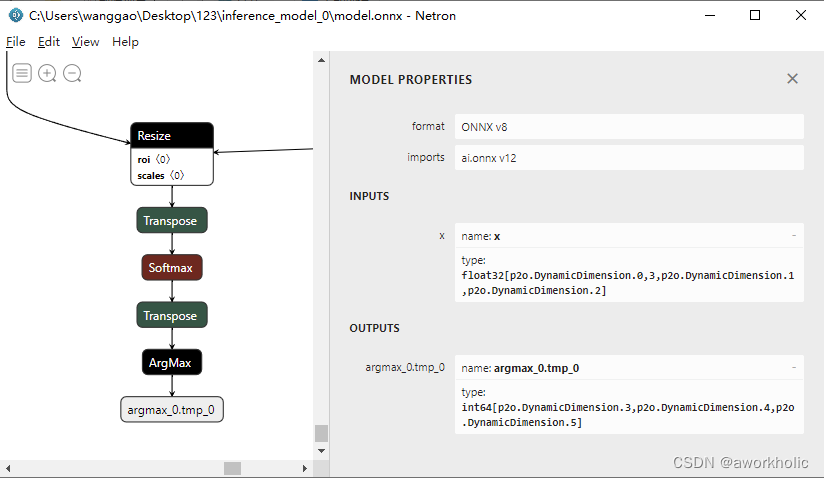
输入尺寸为 [n, 3, h, w],原始输出为[n,c,h,w],由于使用soft和argmax,输出直接为[1, h, w]。输出和输入图像宽高一致,输出的每个像素位置就是像素分类的类别数。
之后使用 trtexec 将onnx模型编译优化导出为engine类型,由于是动态输入,因此指定了输入尺寸范围和最优尺寸。
trtexec.exe
--onnx=model.onnx
--explicitBatch --fp16
--minShapes=x:1x3x540x960
--optShapes=x:1x3x720x1280
--maxShapes=x:1x3x1080x1920
--saveEngine=model.trt
2.2、推理测试
(0)基本类型数据准备
我们仅使用#include "NvInfer.h" ,来使用TensorRT sdk,定义几个需要的宏和对象
#define CHECK(status) \
do \
{ \
auto ret = (status); \
if (ret != 0) \
{ \
std::cerr << "Cuda failure: " << ret << std::endl; \
abort(); \
} \
} while (0)
class Logger : public nvinfer1::ILogger
{
public:
Logger(Severity severity = Severity::kWARNING) :
severity_(severity) {}
virtual void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if(severity <= severity_)
std::cout << msg << std::endl;
}
nvinfer1::ILogger& getTRTLogger() noexcept
{
return *this;
}
private:
Severity severity_;
};
struct InferDeleter
{
template <typename T>
void operator()(T* obj) const
{
delete obj;
}
};
template <typename T>
using SampleUniquePtr = std::unique_ptr<T, InferDeleter>;
(1)加载模型
Logger logger(nvinfer1::ILogger::Severity::kVERBOSE);
/*
trtexec.exe --onnx=inference_model\model.onnx --explicitBatch --fp16 --minShapes=x:1x3x540x960 --optShapes=x:1x3x720x1280 --maxShapes=x:1x3x1080x1920 --saveEngine=model.trt
*/
std::string trtFile = R"(C:\Users\wanggao\Desktop\123\inference_model_0\model.trt)";
//std::string trtFile = "model.test.trt";
std::ifstream ifs(trtFile, std::ifstream::binary);
if(!ifs) {
return false;
}
ifs.seekg(0, std::ios_base::end);
int size = ifs.tellg();
ifs.seekg(0, std::ios_base::beg);
std::unique_ptr<char> pData(new char[size]);
ifs.read(pData.get(), size);
ifs.close();
// engine模型
//SampleUniquePtr<nvinfer1::IRuntime> runtime{nvinfer1::createInferRuntime(logger.getTRTLogger())};
//auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
// runtime->deserializeCudaEngine(pData.get(), size), InferDeleter());
//auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
std::shared_ptr<nvinfer1::ICudaEngine> mEngine;
{
SampleUniquePtr<nvinfer1::IRuntime> runtime{nvinfer1::createInferRuntime(logger.getTRTLogger())};
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
runtime->deserializeCudaEngine(pData.get(), size), InferDeleter());
}
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
(2)输入
将RGB三通道图像转换为NCHW格式数据,数据类型为float。
// 输入 前处理
//cv::Mat img = cv::imread("dog.jpg");
cv::Mat img = cv::imread(R"(C:\Users\wanggao\Desktop\123\data\test\t.jpg)");
cv::Mat blob = cv::dnn::blobFromImage(img, 1 / 255., img.size(), {0,0,0}, true, false);
//blob = blob * 2 - 1; // 测试使用,可以不归一化
(3)显存分配
不同于固定输入,通过engine获取尺寸并分配显存大小
// 固定输入尺寸的显存分配方式
std::vector<void*> bindings(mEngine->getNbBindings());
for (int i = 0; i < bindings.size(); i++) {
nvinfer1::DataType type = mEngine->getBindingDataType(i);
nvinfer1::Dims dims = mEngine->getBindingDimensions(i);
//size_t volume =
// sizeof(float) * std::accumulate(dims.d,dims.d + dims.nbDims,1,std::multiplies<size_t>());
size_t volume = std::accumulate(dims.d,dims.d + dims.nbDims,1,std::multiplies<size_t>());
switch (type)
{
case nvinfer1::DataType::kINT32:
case nvinfer1::DataType::kFLOAT: volume *= 4; break; // 明确为类型 float
case nvinfer1::DataType::kHALF: volume *= 2; break;
case nvinfer1::DataType::kBOOL:
case nvinfer1::DataType::kINT8:
default:break;
}
CHECK(cudaMalloc(&bindings[i],volume));
}
这里通过模型获取的输入类型为float尺寸为[-1,3,1,1]、输出类型为int32尺寸为[-1,-1,-1],即获取不到尺寸信息。所以,只能根据输入的尺寸来分配显存大小。(文后说明在实际推理中应该如何分配)
// 设置网络的输入尺寸
context->setBindingDimensions(0, nvinfer1::Dims4{1, 3 , img.rows, img.cols});
// 分配显存
std::vector<void*> bindings(mEngine->getNbBindings());
//auto type1 = mEngine->getBindingDataType(0); // kFLOAT float
//auto type2 = mEngine->getBindingDataType(1); // kINT32 int
CHECK(cudaMalloc(&bindings[0], sizeof(float) * 1 * 3 * img.rows * img.cols*3)); // n*3*h*w
CHECK(cudaMalloc(&bindings[1], sizeof(int) * 1 * 1 * img.rows * img.cols*3)); // n*1*h*w
注意,必须通过context->setBindingDimensions()设置网络的输入尺寸,否则网络在推理时报错,即输入维度未指定,导出网络输出无结果。
3: [executionContext.cpp::nvinfer1::rt::ShapeMachineContext::resolveSlots::1541] Error Code 3: API Usage Error (Parameter check failed at: executionContext.cpp::nvinfer1::rt::ShapeMachineContext::resolveSlots::1541, condition: allInputDimensionsSpecified(routine)
)
9: [executionContext.cpp::nvinfer1::rt::ExecutionContext::executeInternal::564] Error Code 9: Internal Error (Could not resolve slots: )
(4)推理
将前处理后的图片数据拷贝到显存中,之后进行推理,之后将推理结果数据从显存拷贝到内存中
cv::Mat pred(img.size(), CV_32SC1, {255,255,255}); // 用于输出
//cv::reduceArgMax() //opencv 4.8.0
//buffers.copyInputToDevice();
CHECK(cudaMemcpy(bindings[0], static_cast<const void*>(blob.data), 3 * img.rows * img.cols * sizeof(float), cudaMemcpyHostToDevice));
context->executeV2(bindings.data());
// buffers.copyOutputToHost()
CHECK(cudaMemcpy(static_cast<void*>(pred.data), bindings[1], pred.total() * sizeof(int), cudaMemcpyDeviceToHost));
(5)结果数据展示(后处理)
这里仅显示,运行截图如下

2.3、显存分配问题
在示例中,我们根据图片大小来分配显存,实际应用将进行多次推理,有多种方案:
- 1、根据实际输入大小,每次进行动态分配(使用完后释放原已分配显存)
- 2、在1基础上,如果显存不够再分配(分配前释放原已分配显存)
- 3、预分配一块较大的显存,程序退出时释放显存
为提高效率,我们可以选择第三种,已知我们动态输入最大尺寸为 --maxShapes=x:1x3x1080x1920,因此我们直接根据网络输入输出类型分配显存
std::vector<void*> bindings(mEngine->getNbBindings()); // 1个输入,1个输出
CHECK(cudaMalloc(&bindings[0], sizeof(float) * 1 * 3 * 1280 * 1920)); // n*3*h*w
CHECK(cudaMalloc(&bindings[1], sizeof(int) * 1 * 1 * * 1280 * 1920)); // n*1*h*w
当输入尺寸超过我们设置的 maxShapes 时,context->setBindingDimensions()将报异常提示,这一种情况就不应该继续执行分配显存,属于输出错误。
2.4、完整代码
#include "opencv2\opencv.hpp"
#include "NvInfer.h"
#include <cuda_runtime_api.h>
#include <random>
//using namespace nvinfer1;
//using samplesCommon::SampleUniquePtr;
#include <fstream>
#include <string>
#define CHECK(status) \
do \
{ \
auto ret = (status); \
if (ret != 0) \
{ \
std::cerr << "Cuda failure: " << ret << std::endl; \
abort(); \
} \
} while (0)
class Logger : public nvinfer1::ILogger
{
public:
Logger(Severity severity = Severity::kWARNING) :
severity_(severity) {}
virtual void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if(severity <= severity_)
std::cout << msg << std::endl;
}
nvinfer1::ILogger& getTRTLogger() noexcept
{
return *this;
}
private:
Severity severity_;
};
struct InferDeleter
{
template <typename T>
void operator()(T* obj) const
{
delete obj;
}
};
template <typename T>
using SampleUniquePtr = std::unique_ptr<T, InferDeleter>;
int inference();
int main(int argc, char** argv)
{
return inference();
}
int inference()
{
Logger logger(nvinfer1::ILogger::Severity::kVERBOSE);
/*
trtexec.exe --onnx=inference_model\model.onnx --explicitBatch --fp16 --minShapes=x:1x3x540x960 --optShapes=x:1x3x720x1280 --maxShapes=x:1x3x1080x1920 --saveEngine=model.trt
*/
std::string trtFile = R"(C:\Users\wanggao\Desktop\123\inference_model_0\model.trt)";
//std::string trtFile = "model.test.trt";
std::ifstream ifs(trtFile, std::ifstream::binary);
if(!ifs) {
return false;
}
ifs.seekg(0, std::ios_base::end);
int size = ifs.tellg();
ifs.seekg(0, std::ios_base::beg);
std::unique_ptr<char> pData(new char[size]);
ifs.read(pData.get(), size);
ifs.close();
// engine模型
//SampleUniquePtr<nvinfer1::IRuntime> runtime{nvinfer1::createInferRuntime(logger.getTRTLogger())};
//auto mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
// runtime->deserializeCudaEngine(pData.get(), size), InferDeleter());
//auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
std::shared_ptr<nvinfer1::ICudaEngine> mEngine;
{
SampleUniquePtr<nvinfer1::IRuntime> runtime{nvinfer1::createInferRuntime(logger.getTRTLogger())};
mEngine = std::shared_ptr<nvinfer1::ICudaEngine>(
runtime->deserializeCudaEngine(pData.get(), size), InferDeleter());
}
auto context = SampleUniquePtr<nvinfer1::IExecutionContext>(mEngine->createExecutionContext());
// 输入
//cv::Mat img = cv::imread("dog.jpg");
cv::Mat img = cv::imread(R"(C:\Users\wanggao\Desktop\123\data\test\t.jpg)");
cv::Mat blob = cv::dnn::blobFromImage(img, 1 / 255., img.size(), {0,0,0}, true, false);
//blob = blob * 2 - 1;
cv::Mat pred(img.size(), CV_32SC1, {255,255,255});
//cv::reduceArgMax() //4.8.0
context->setBindingDimensions(0, nvinfer1::Dims4{1, 3 , img.rows, img.cols});
// 分配显存
std::vector<void*> bindings(mEngine->getNbBindings());
//auto type1 = mEngine->getBindingDataType(0); // kFLOAT float
//auto type2 = mEngine->getBindingDataType(1); // kINT32 int
CHECK(cudaMalloc(&bindings[0], sizeof(float) * 1 * 3 * img.rows * img.cols*3)); // n*3*h*w
CHECK(cudaMalloc(&bindings[1], sizeof(int) * 1 * 1 * img.rows * img.cols*3)); // n*1*h*w
// 推理
// warmingup ...
CHECK(cudaMemcpy(bindings[0], static_cast<const void*>(blob.data), 1 * 3 * 640 * 640 * sizeof(float), cudaMemcpyHostToDevice));
context->executeV2(bindings.data());
context->executeV2(bindings.data());
context->executeV2(bindings.data());
context->executeV2(bindings.data());
CHECK(cudaMemcpy(static_cast<void*>(pred.data), bindings[1], 1 * 84 * 8400 * sizeof(int), cudaMemcpyDeviceToHost));
auto t1 = cv::getTickCount();
//buffers.copyInputToDevice();
CHECK(cudaMemcpy(bindings[0], static_cast<const void*>(blob.data), 3 * img.rows * img.cols * sizeof(float), cudaMemcpyHostToDevice));
context->executeV2(bindings.data());
// buffers.copyOutputToHost()
CHECK(cudaMemcpy(static_cast<void*>(pred.data), bindings[1], pred.total() * sizeof(int), cudaMemcpyDeviceToHost));
auto t2 = cv::getTickCount();
std::cout << (t2-t1) / cv::getTickFrequency() << std::endl;
// 资源释放
cudaFree(bindings[0]);
cudaFree(bindings[1]);
return 0;
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!