使用OpenCV DNN模块进行人脸检测
内容的一部分来源于贾志刚的《opencv4应用开发、入门、进阶与工程化实践》。这本书我大概看了一下,也就后面几章比较感兴趣,但是内容很少,并没有想像的那种充实。不过学习还是要学习的。
在实际工程项目中,并不是说我们将神经网络训练好拿来就直接落地,事实上,一个深度学习网络的落地在训练验证好才是开始的第一步,剩下为了部署网络,需要考虑场景问题,硬件配置,软件配置。需要对网络进行蒸馏,剪枝,轻量化,是模型大小适宜硬件配置,此外为了更好,更快速的推理,还需要将模型转成不同的模型格式,使其更加适配软件推理。目前使用较多推理加速工具英特尔的OpenVINO,Nvidia的TensorRT,都是目前主流的加速推理引擎软件,后期会继续学习。
OpenCV DNN模块在OpenCV3系列就已经正式发布,该模块是一个深度学习网络库,它支持多种预训练的深度学习模型,并可以用于多种图像和视频分析任务,如面部识别、对象检测、图像分类等。这个模块使得在OpenCV中使用深度学习模型变得相对简单,因为它可以加载由不同深度学习框架(如TensorFlow、Caffe、Torch/PyTorch等)训练的模型。其不仅可以基于CPU推理,也可基于GPU加速推理。使用方便。
使用dnn模块时,一般的步骤如下:
-
加载模型:使用
cv2.dnn.readNetFrom*系列函数(例如readNetFromCaffe、readNetFromTensorflow等)加载预训练模型。 -
准备输入:对输入图像进行必要的预处理(如缩放、中心化、标准化等),并将其转换为网络所需的格式。
-
前向传播:将处理后的图像传入网络进行前向传播,得到输出。
-
解析输出:根据模型的特性和应用需求,解析模型的输出,以得到最终的结果。
?Opencv samples 提供了基于resnet的SSD人脸检测模型示例,有基于caffe生成的,也有基于Tensorflow生成的。如果你安装opencv时是编译源码安装,则可以去源码位置处看看opencv4.6\opencv\sources\samples下有各类的示例,dnn文件夹下的face_detector下就有需要的网络权重文件与网络配置文件。
网络配置文件描述了一个神经网络的架构和结构。它包含了网络中的各层(如卷积层、池化层、全连接层等)的定义,以及这些层的参数(如核大小、步长、填充等)。此文件不包含训练后的模型权重,只定义了模型的结构。
这种文件通常是一个文本文件,可以使用JSON、XML、YAML或特定框架的专用格式(如Caffe的.prototxt文件)编写。在不同的深度学习框架中,配置文件的格式可能会有所不同。
网络权重文件包含了神经网络在训练过程中学习到的权重和偏置参数。这些参数是通过训练数据集上的反向传播过程优化得到的,它们决定了模型对新数据的预测能力。
权重文件通常是一个二进制文件,包含了数值型的参数数据。这种文件的格式也取决于使用的深度学习框架,常见格式包括TensorFlow的.ckpt、PyTorch的.pt或.pth、Caffe的.caffemodel等。
如果你找不到,也可以在链接:https://pan.baidu.com/s/1suEmF7zgmgamnJbToegQ6Q?pwd=gcxy? ?提取码:gcxy 这里下载。
好了有了这些,那我还想实现一个视频检测,但是又没有摄像头,那没办法了,也可以整一个显示桌面窗口的。由于本人这里又两个显示屏,所以在将电脑显示屏窗口的一个内容获得,可以在另外一个窗口中用opencv的imshow观察。
下面提供一些重要代码。
1.window_capture
#include <opencv2/opencv.hpp>
#include <Windows.h>
#include <iostream>
using namespace std;
using namespace cv;
Mat hwnd2mat(HWND hwnd)
{
HDC hwindowDC, hwindowCompatibleDC;
int height, width, srcheight, srcwidth;
HBITMAP hbwindow;
Mat src;
BITMAPINFOHEADER bi;
hwindowDC = GetDC(hwnd);
hwindowCompatibleDC = CreateCompatibleDC(hwindowDC);
SetStretchBltMode(hwindowCompatibleDC, COLORONCOLOR);
RECT windowsize; // get the height and width of the screen
GetClientRect(hwnd, &windowsize);
srcheight = windowsize.bottom;
srcwidth = windowsize.right;
height = windowsize.bottom / 1; //change this to whatever size you want to resize to
width = windowsize.right / 1;
src.create(height, width, CV_8UC4);
// create a bitmap
hbwindow = CreateCompatibleBitmap(hwindowDC, width, height);
bi.biSize = sizeof(BITMAPINFOHEADER); //http://msdn.microsoft.com/en-us/library/windows/window/dd183402%28v=vs.85%29.aspx
bi.biWidth = width;
bi.biHeight = -height; //this is the line that makes it draw upside down or not
bi.biPlanes = 1;
bi.biBitCount = 32;
bi.biCompression = BI_RGB;
bi.biSizeImage = 0;
bi.biXPelsPerMeter = 0;
bi.biYPelsPerMeter = 0;
bi.biClrUsed = 0;
bi.biClrImportant = 0;
// use the previously created device context with the bitmap
SelectObject(hwindowCompatibleDC, hbwindow);
// copy from the window device context to the bitmap device context
StretchBlt(hwindowCompatibleDC, 0, 0, width, height, hwindowDC, 0, 0, srcwidth, srcheight, SRCCOPY); //change SRCCOPY to NOTSRCCOPY for wacky colors !
GetDIBits(hwindowCompatibleDC, hbwindow, 0, height, src.data, (BITMAPINFO*)&bi, DIB_RGB_COLORS); //copy from hwindowCompatibleDC to hbwindow
// avoid memory leak
DeleteObject(hbwindow);
DeleteDC(hwindowCompatibleDC);
ReleaseDC(hwnd, hwindowDC);
//src是BGRA 4通道显示
return src;
}有几个需要注意的问题,windows.h头文件需要在iostream或者其他C++标准库的前面,至于问什么就是如果写反了,windows会对一个量报重定义的错误,没法解决,应该是个冲突。
此外这段代码是将hwindowCompatibleDC的数据传给Mat类src,这里传入的输入是4通道的即RGBA类型,在 OpenCV 中处理图像时,一个常见的格式是 RGBA,其中包括四个通道:红色(R)、绿色(G)、蓝色(B)和 Alpha(A)。Alpha 通道代表透明度,其中值 0 表示完全透明,255 表示完全不透明。 这里非常重要,因为我们后续的处理时将一幅3通道的图传入网络进行推理,传入的数据格式错误就会报错。所以需要后期将RGBA格式转为RGB格式。
哦对了,这里再提一嘴,以上只是为了方便,说成RGB。在opencv中,彩色图像时BGR格式的,所以读入的4通道也是BGRA格式。
2.face_detect
void face_detect(Mat& image, Net& net) {
int h = image.rows;
int w = image.cols;
cv::Mat inputBlob = cv::dnn::blobFromImage(image, 1.0, cv::Size(300, 300),
Scalar(104.0, 177.0, 123.0), false, false);
net.setInput(inputBlob, "data");
cv::Mat detection = net.forward("detection_out");
cv::Mat detectionMat(detection.size[2], detection.size[3], CV_32F, detection.ptr<float>());
for (int i = 0; i < detectionMat.rows; i++)
{
float confidence = detectionMat.at<float>(i, 2);
if (confidence > 0.125)
{
int x1 = static_cast<int>(detectionMat.at<float>(i, 3) * w);
int y1 = static_cast<int>(detectionMat.at<float>(i, 4) * h);
int x2 = static_cast<int>(detectionMat.at<float>(i, 5) * w);
int y2 = static_cast<int>(detectionMat.at<float>(i, 6) * h);
cv::rectangle(image, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(0, 255, 0),
2, 8);
}
}
namedWindow("人脸检测演示", WINDOW_NORMAL);
imshow("人脸检测演示", image);
}?这段代码就是推理的主要流程,其中几个比较重要的点就是blobFromImage函数是将待预测的图片转成网络输入的格式,一般网络的图像输入格式为N,C,H,W。N就是batch数,在推理时一般为1,C即通道数,H,W即为图像的高宽,除此之外这个函数还可缩放图像的像素值,默认1.0表示不变,也可以resize图像宽高,这里缩放到(300X300)为网络的输入。还有是否互换图像的R与B通道,数据类型(默认为浮点数)等。
然后将图像传入网络,前向推理获得结果,该网络的输出层是“detection_out”需要加输出层名称获得输出结果,我们这里是将结果用一个Mat类 detection获得。
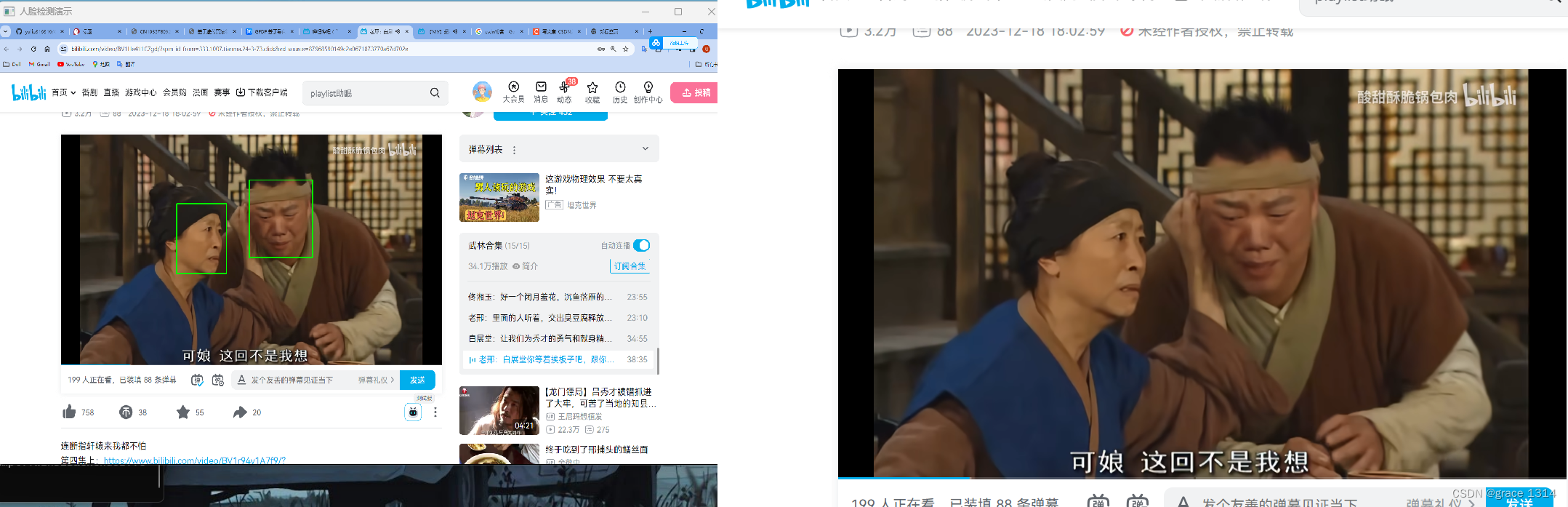
该结果中输出格式为Nx7,N表示检测到的对象数目,7分别表示,批次,类别,得分,检测狂的左上角与右下角坐标。所以可以采用上面的代码对推理结果进行解析。这里根据置信度得分,筛选符合的条件,并将其绘制在图像显示。
3.整体流程
void screen_capture_facedetection(bool tf) {
const std::string caffe_config = model_dir + "face_detector/deploy.prototxt";
const std::string caffe_weight = model_dir + "face_detector/res10_300x300_ssd_iter_140000_fp16.caffemodel";
const std::string tf_config = model_dir + "face_detector/opencv_face_detector.pbtxt";
const std::string tf_weight = model_dir + "face_detector/opencv_face_detector_uint8.pb";
Net net;
if (tf) {
net = cv::dnn::readNetFromTensorflow(tf_weight, tf_config);
}
else {
net = cv::dnn::readNetFromCaffe(caffe_config, caffe_weight);
}
HWND hwndDesktop = GetDesktopWindow();
//namedWindow("window", WINDOW_NORMAL);
while (true) {
Mat frame = hwnd2mat(hwndDesktop);
if (frame.empty()) {
break;
}
//从窗口获得的图像是BGRA4通道显示,可以将其转为3通道显示
Mat frame3Channel;
cvtColor(frame, frame3Channel, COLOR_BGRA2BGR);
//imshow("window", frame3Channel);
//cout << frame3Channel.channels() << endl;
//break;
face_detect(frame3Channel, net);
char c = waitKey(10);
if (c == 27) {
break;
}
}
}可以看到这里使用cvtColor将4通道转为3通道。
在int main 中调用即可,注意bool tf 选择caffee model,或者tensorflow model即可。推出,在显示窗口中按ESC即可退出。
后期当然也可以使用opencv的video writer,将视频录制下来。这里就不接着做了,感兴趣的可以试一下。
一下是一些效果。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!