2023_Spark_实验三十三:配置Standalone模式Spark3.4.2集群
发布时间:2023年12月25日
实验目的:掌握Spark Standalone部署模式
实验方法:基于centos7部署Spark standalone模式集群
实验步骤:
一、下载spark软件
下载的时候下载与自己idea里对应版本的spark
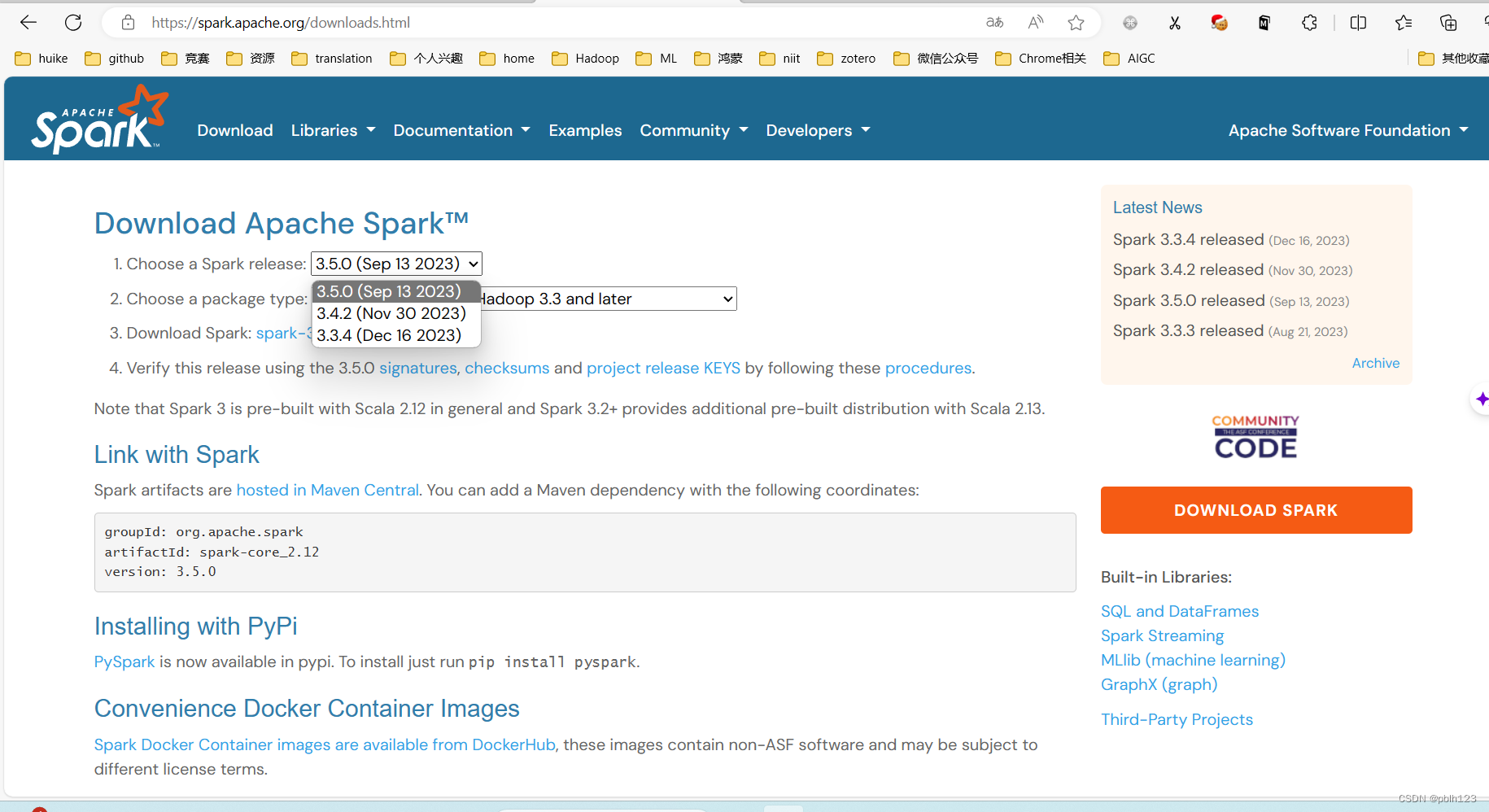

选择任意一个下载即可
- spark 3.4.1
- spark 3.4.2
二、安装Standalone模式部署spark
将下载好的spark软件上传到指定的linux集群中
# 解压到指定目录
tar -zxvf spark-3.4.2-bin-hadoop3-scala2.13.tgz -C /opt/module/spark/
# 更改所有权
chown -R hadoop:hadoop spark-3.4.2-bin-hadoop3-scala2.13/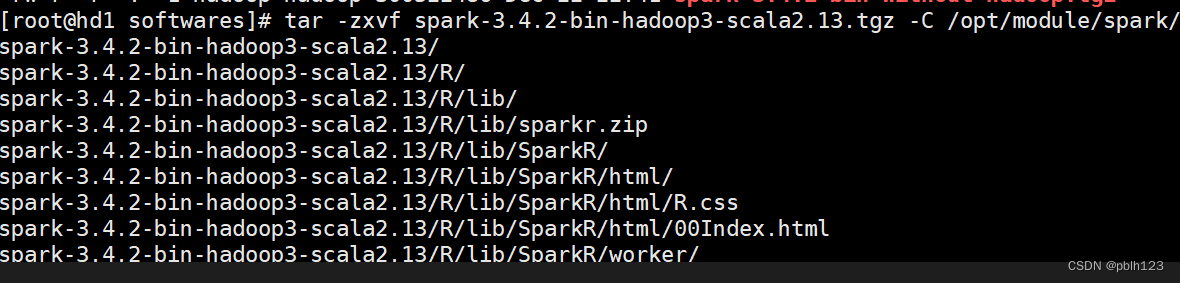
配置环境变量

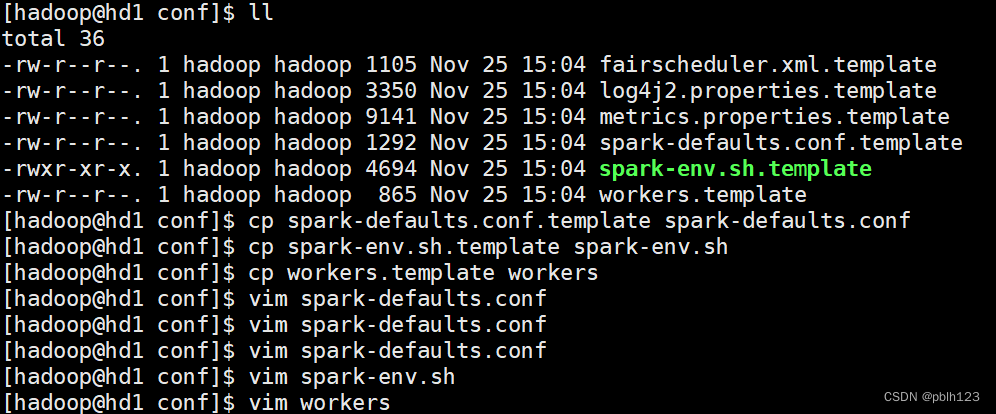
配置Spark配置文件
- spark-defaults.conf
- spark-env.sh
- workers
spark-defaults.conf配置如下
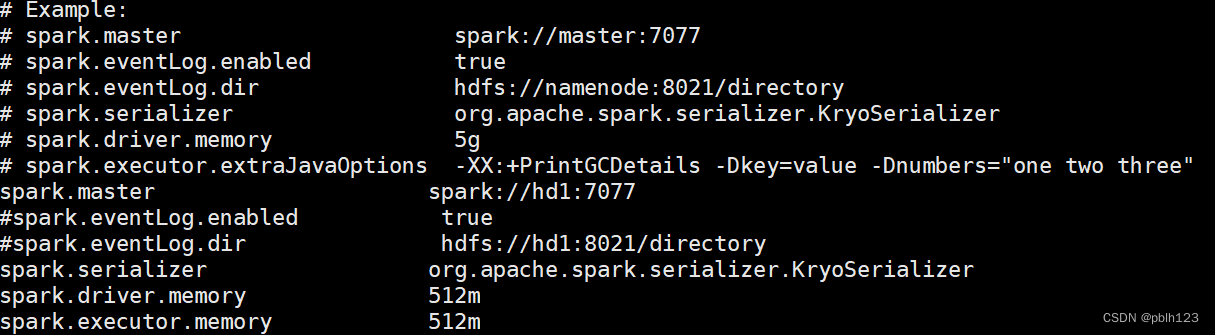
spark-env.sh配置如下
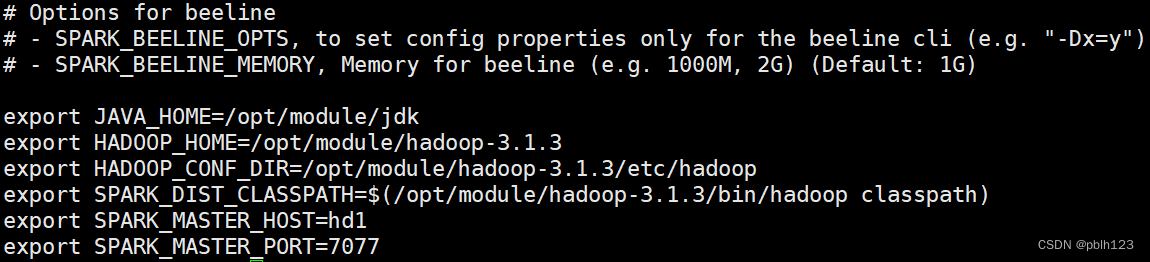
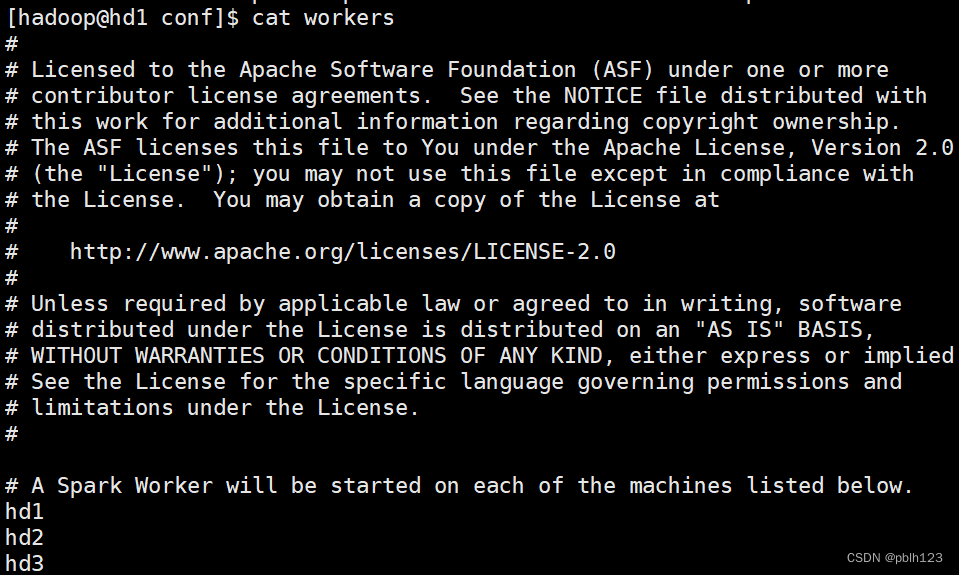
workers配置如下
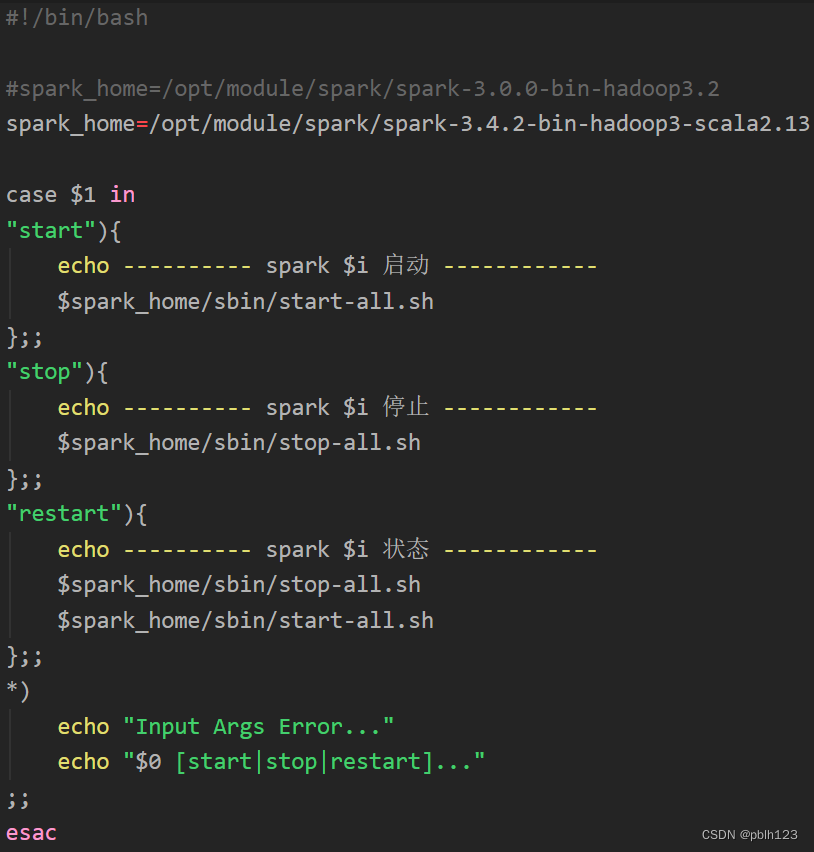
配置spark一键启动脚本
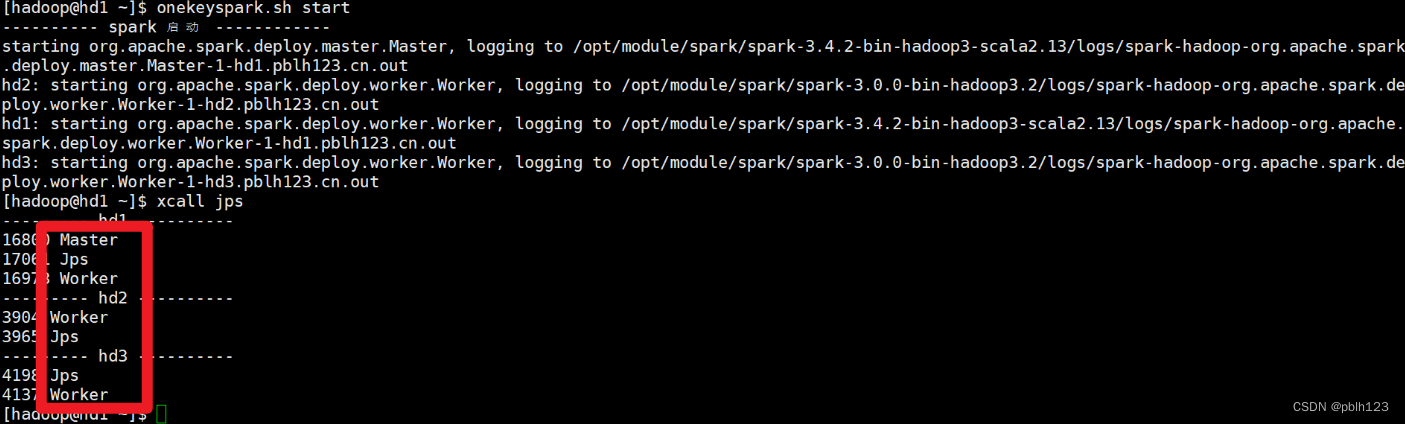
启动spark standalone模式集群
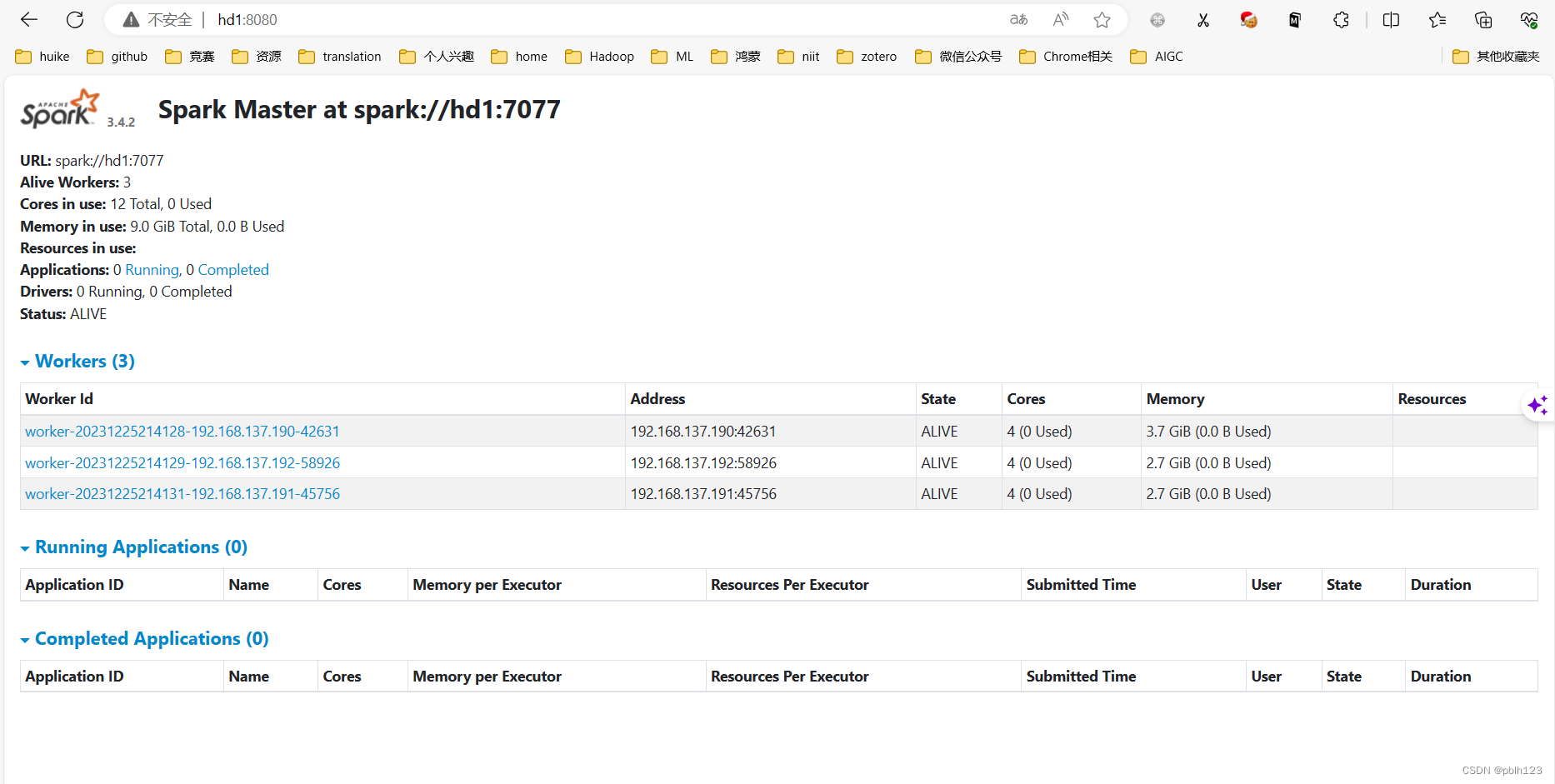
三、验证Spark Standalone模式集群
登录hd1节点查看spark webUI 【记得改成自己对应的集群ip】
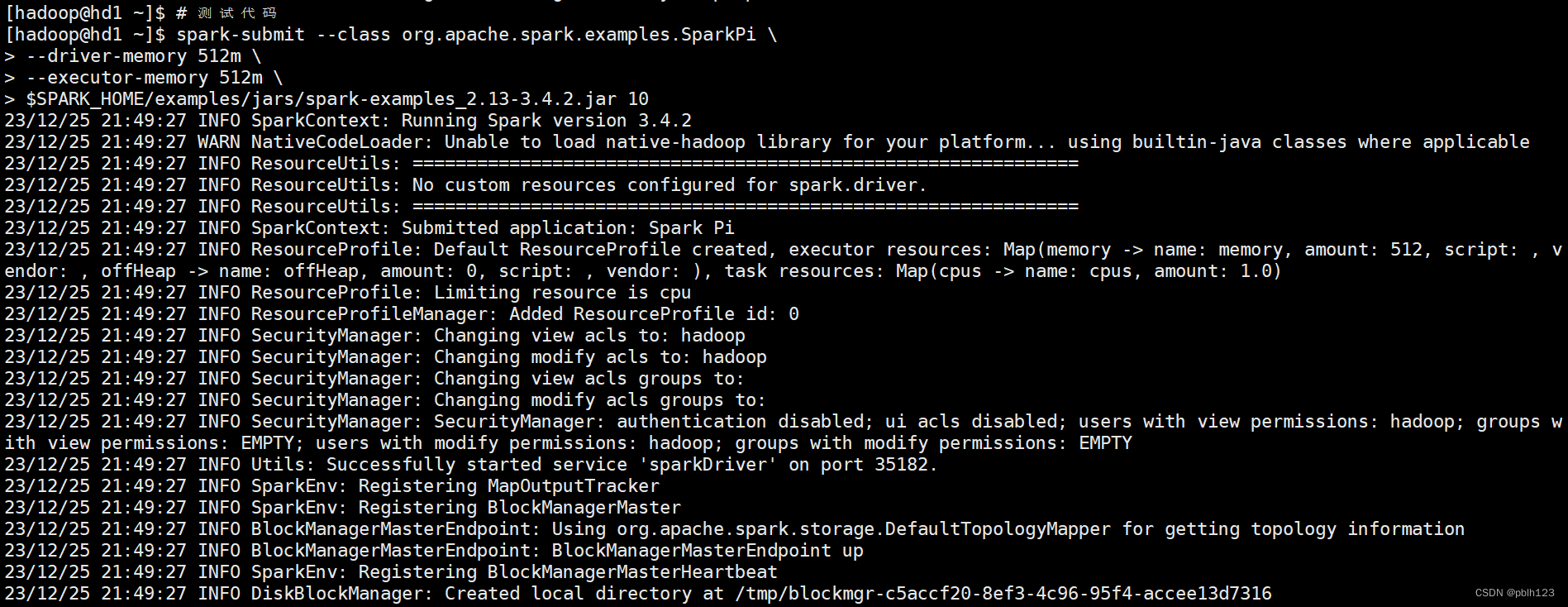
# 测试代码
spark-submit --class org.apache.spark.examples.SparkPi \
--driver-memory 512m \
--executor-memory 512m \
$SPARK_HOME/examples/jars/spark-examples_2.13-3.4.2.jar 10
spark-submit --class org.apache.spark.examples.SparkPi \
$SPARK_HOME/examples/jars/spark-examples_2.13-3.4.2.jar 10
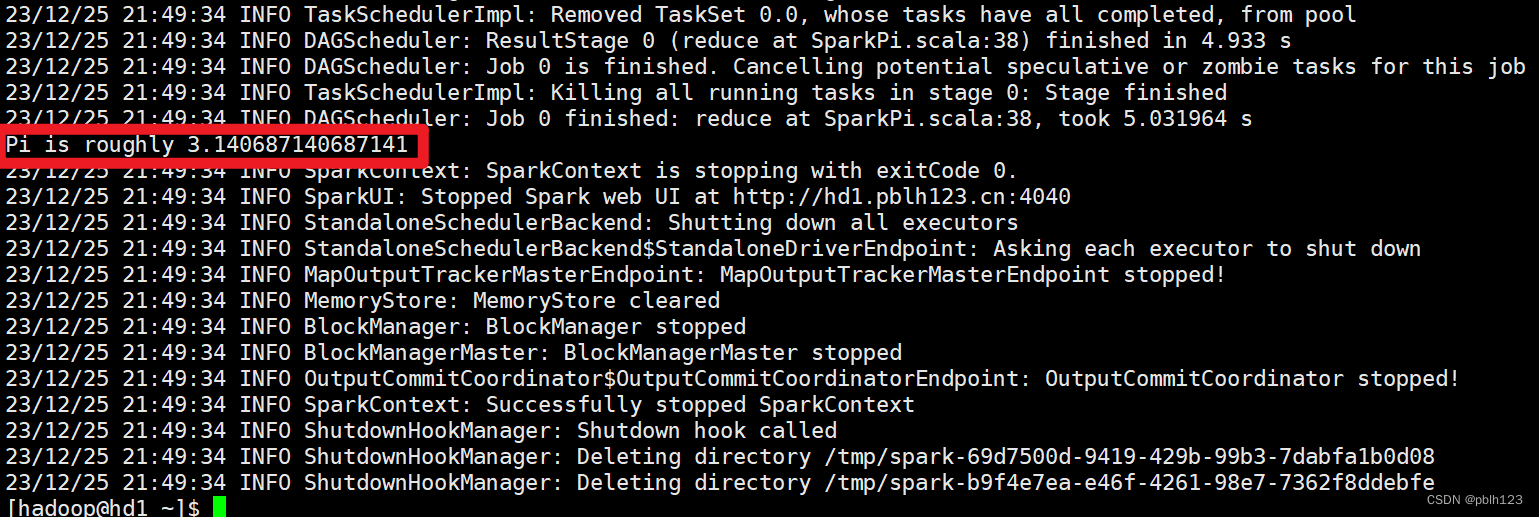


实验结果:基于centos7完成Spark standalone模式集群部署
分析一个小工具,文件同步工具xsync,该工具可以将hd1节点上文件,文件夹分发到hd1,hd2,hd3节点

?
文章来源:https://blog.csdn.net/pblh123/article/details/135196923
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java finally语句到底是在return之前还是之后执行?
- VSCode安装GitHub Copilot插件方法
- Oracle 静态注册与动态注册监听以及Sqldev连接PDB容器数据库
- R语言学习笔记-R包的安装
- 1月下半笔记(个人向)
- 论文翻译 | 【深入挖掘Java技术】「底层原理专题」深入分析一下并发编程之父Doug Lea的纽约州立大学的ForkJoin框架的本质和原理
- 移动机器人规划 - 概述
- RAID的基本介绍
- 天锐绿盾加密电脑文件资料,防止核心文件、文档、设计图纸、源代码、音视频等核心文件数据\资料外泄,自动智能透明加密防泄密软件系统
- RM3100 stm32驱动(硬件i2c)