【Spark精讲】一文讲透Spark RDD
MapReduce的缺陷
MR虽然在编程接口的种类和丰富程度上已经比较完善了,但这些系统普遍都缺乏操作分布式内存的接口抽象,导致很多应用在性能上非常低效 。 这些应用的共同特点是需要在多个并行操 作之间重用工作数据集 ,典型的场景就是机器学习和图应用中常用的迭代算法 (每一步对数据 执行相似的函数) 。
RDD
RDD是只读的。
RDD五大属性:①分区、②依赖、③计算函数、④分区器、⑤首选运行位置。
RDD 则是直接在编程接口层面提供了一种高度受限的共享内存模型,如图下图所示。 RDD 是 Spark 的核心数据结构,全称是弹性分布式数据集 (Resilient Distributed Dataset),其本质是一种分布式的内存抽象,表示一个只读的数据分区( Partition)集合 。一个 RDD 通常只能通过其他的 RDD转换而创建。 RDD 定义了各种丰富的转换操作(如 map、 join和 filter等),通过这些转换操作,新的 RDD 包含了如何从其他 RDD 衍生所必需的信息,这些信息构成了 RDD 之间的依赖关系( Dependency) 。 依赖具体分为两种, 一种是窄依赖, RDD 之间分区是一一对应的;另一种是宽依赖,下游 RDD 的每个分区与上游 RDD (也称之为父 RDD)的每个分区都有关,是多对多的关系 。 窄依赖中的所有转换操作可以通过类似管道(Pipeline)的方式全部执行,宽依赖意味着数据需要在不同节点之间 Shuffle 传输 。

RDD计算的时候会通过一个 compute函数得到每个分区的数据。 若 RDD是通过已有的文件系统构建的,则 compute 函数读取指定文件系统中的数据;如果 RDD 是通过其他 RDD 转换而来的,则 compute 函数执行转换逻辑,将其他 RDD 的数据进行转换。 RDD 的操作算子包括两 类, 一类是 transformation,用来将 RDD 进行转换,构建 RDD 的依赖关系;另一类称为 action, 用来触发 RDD 的计算,得到 RDD 的相关计算结果或将 RDD 保存到文件系统中。
在 Spark 中, RDD 可以创建为对象 ,通过对象上的各种方法调用来对 RDD 进行转换 。 经过一系列的 transformation逻辑之后,就可以调用 action来触发 RDD 的最终计算。 通常来讲, action 包括多种方式,可以 是 向应用程序返回结果( show、 count 和 collect等),也可以是向存 储系统保存数据(saveAsTextFile等)。 在Spark中,只有遇到 action,才会真正地执行 RDD 的计算(注:这被称为惰性计算,英文为 LazyEvqluation),这样在运行时可以通过管道的方式传输多个转换 。
总结而言,基于 RDD 的计算任务可描述为从稳定的物理存储(如分布式文件系统 HDFS) 中加载记录,记录被传入由一组确定性操作构成的 DAG (有向无环图),然后写回稳定存储。 RDD还可以将数据集缓存到内存中,使得在多个操作之间可以很方便地重用数据集。 总的来讲,RDD 能够很方便地支持 MapReduce 应用、关系型数据处理、流式数据处理(Stream Processing) 和迭代型应用(图计算、机器学习等)。
在容错性方面,基于 RDD 之间的依赖, 一个任务流可以描述为 DAG。 在实际执行的时候, RDD 通过 Lineage 信息(血缘关系)来完成容错,即使出现数据分区丢失,也可以通过 Lineage 信息重建分区。 如果在应用程序中多次使用同一个 RDD,则可以将这个 RDD 缓存起来,该 RDD 只有在第一次计算的时候会根据 Lineage 信息得到分区的数据,在后续其他地方用到这个 RDD 的时候,会直接从缓存处读取而不用再根据 Lineage信息计算,通过重用达到提升性能的目的 。 虽然 RDD 的 Lineage 信息可以天然地实现容错(当 RDD 的某个分区数据计算失败或丢 失时,可以通过 Lineage信息重建),但是对于长时间迭代型应用来说,随着迭代的进行,RDD 与 RDD之间的 Lineage信息会越来越长,一旦在后续迭代过程中出错,就需要通过非常长的 Lineage信息去重建,对性能产生很大的影响。 为此,RDD 支持用 checkpoint机制将数据保存到持久化的存储中,这样就可以切断之前的 Lineage信息,因为 checkpoint后的 RDD不再需要知道它的父 RDD ,可以从 checkpoint 处获取数据。
DAG
顾名思义,DAG 是一种“图”,图计算模型的应用由来已久,早在上个世纪就被应用于数据库系统(Graph databases)的实现中。任何一个图都包含两种基本元素:节点(Vertex)和边(Edge),节点通常用于表示实体,而边则代表实体间的关系。
DAG,有向无环图,Directed Acyclic Graph的缩写,常用于建模。Spark中使用DAG对RDD的关系进行建模,描述了RDD的依赖关系,这种关系也被称之为lineage,RDD的依赖关系使用Dependency维护,参考Spark RDD之Dependency,DAG在Spark中的对应的实现为DAGScheduler。
基础概念
介绍DAGScheduler中的一些概念,有助于理解后续流程。
- Job:调用RDD的一个action,如count,即触发一个Job,spark中对应实现为ActiveJob,DAGScheduler中使用集合activeJobs和jobIdToActiveJob维护Job
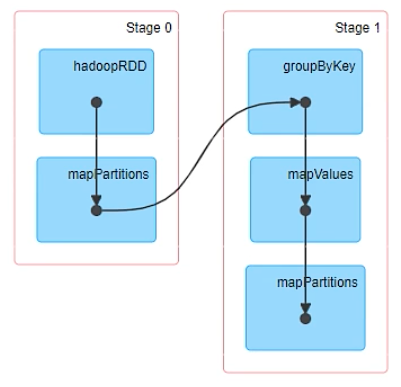
- Stage:代表一个Job的DAG,会在发生shuffle处被切分,切分后每一个部分即为一个Stage,Stage实现分为ShuffleMapStage和ResultStage,一个Job切分的结果是0个或多个ShuffleMapStage加一个ResultStage
- TaskSet:一组Task
- Task:最终被发送到Executor执行的任务,和stage的ShuffleMapStage和ResultStage对应,其实现分为ShuffleMapTask和ResultTask
把 DAG 图反向解析成多个阶段,每个阶段中包含多个任务,每个任务会被任务调度器分发给工作节点上的 Executor 上执行。

Web UI上DAG举例?
Checkpoint
RDD的依赖
checkpoint先了解一下RDD的依赖,比如计算wordcount:
scala> ?sc.textFile("hdfs://leen:8020/user/hive/warehouse/tools.db/cde_prd").flatMap(_.split("\\\t")).map((_,1)).reduceByKey(_+_);
res0: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:28
?
scala> res0.toDebugString
res1: String =?
(2) ShuffledRDD[4] at reduceByKey at <console>:28 []
?+-(2) MapPartitionsRDD[3] at map at <console>:28 []
? ? | ?MapPartitionsRDD[2] at flatMap at <console>:28 []
? ? | ?hdfs://leen:8020/user/hive/warehouse/tools.db/cde_prd MapPartitionsRDD[1] at textFile at <console>:28 []
? ? | ?hdfs://leen:8020/user/hive/warehouse/tools.db/cde_prd HadoopRDD[0] at textFile at <console>:28 []1、在textFile读取hdfs的时候就会先创建一个HadoopRDD,其中这个RDD是去读取hdfs的数据key为偏移量value为一行数据,因为通常来讲偏移量没有太大的作用所以然后会将HadoopRDD转化为MapPartitionsRDD,这个RDD只保留了hdfs的数据。
2、flatMap 产生一个RDD MapPartitionsRDD
3、map 产生一个RDD MapPartitionsRDD
4、reduceByKey 产生一个RDD ShuffledRDD
如何建立checkPoint
1、首先需要用sparkContext设置hdfs的checkpoint的目录,如果不设置使用checkpoint会抛出异常:
scala> res0.checkpoint
org.apache.spark.SparkException: Checkpoint directory has not been set in the SparkContext
scala> sc.setCheckpointDir("hdfs://leen:8020/checkPointDir")sc.setCheckpointDir("hdfs://leen:8020/checkPointDir")
执行了上面的代码,hdfs里面会创建一个目录:
/checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d
2、然后执行checkpoint
scala> res0.checkpoint
1发现hdfs中还是没有数据,说明checkpoint也是个transformation的算子。
scala> res0.count()
INFO ReliableRDDCheckpointData: Done checkpointing RDD 4 to hdfs://leen:8020/checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4, new parent is RDD 5
res5: Long = 73689
1
2
3
hive > dfs -du -h /checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4;
147 ? ?147 ? ?/checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4/_partitioner
1.2 M ?1.2 M ?/checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4/part-00000
1.2 M ?1.2 M ?/checkPointDir/9ae90c62-a7ff-442a-bbf0-e5c8cdd7982d/rdd-4/part-00001但是执行的时候相当于走了两次流程,前面计算了一遍,然后checkpoint又会计算一次,所以一般我们先进行cache然后做checkpoint就会只走一次流程,checkpoint的时候就会从刚cache到内存中取数据写入hdfs中,如下:
rdd.cache()
rdd.checkpoint()
rdd.collect在源码中,在checkpoint的时候强烈建议先进行cache,并且当你checkpoint执行成功了,那么前面所有的RDD依赖都会被销毁,如下:
/**
? ?* Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint
? ?* directory set with `SparkContext#setCheckpointDir` and all references to its parent
? ?* RDDs will be removed. This function must be called before any job has been
? ?* executed on this RDD. It is strongly recommended that this RDD is persisted in
? ?* memory, otherwise saving it on a file will require recomputation.
? ?*/
?
? def checkpoint(): Unit = RDDCheckpointData.synchronized {
? ? // NOTE: we use a global lock here due to complexities downstream with ensuring
? ? // children RDD partitions point to the correct parent partitions. In the future
? ? // we should revisit this consideration.
? ? if (context.checkpointDir.isEmpty) {
? ? ? throw new SparkException("Checkpoint directory has not been set in the SparkContext")
? ? } else if (checkpointData.isEmpty) {
? ? ? checkpointData = Some(new ReliableRDDCheckpointData(this))
? ? }
? }RDD依赖被销毁
scala> res0.toDebugString
res6: String =?
(2) ShuffledRDD[4] at reduceByKey at <console>:28 []
?| ?ReliableCheckpointRDD[5] at count at <console>:30 []本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!