由浅入深走进Python异步编程【asyncio上层api】(含代码实例讲解 || create_task,gather,wait,wait_for)
写在前面
从底层到第三方库,全面讲解python的异步编程。这节讲述的是asyncio实现异步的上层api,详细了解需要配合上下一节观看哦。纯干货,无概念,代码实例讲解。
本系列有6章左右,点击头像或者专栏查看更多内容,陆续更新,欢迎关注。
部分资料来源及参考链接:
https://www.bilibili.com/video/BV1Li4y1j7RY/
https://docs.python.org/zh-cn/3.7/library/asyncio-eventloop.html
直接await协程
考虑下面一段代码
import time
import asyncio
async def one_data():
print('正在暂停1号靓仔')
await asyncio.sleep(3)#沉睡3秒
print('正在恢复1号靓仔')
async def two_data():
print('正在暂停2号靓仔')
await asyncio.sleep(1)#沉睡1秒
print('正在恢复2号靓仔')
'事件循环判断两个协程的独立的,变成了同步状态'
async def get_data():
await one_data()#等待3秒
await two_data()#等待1秒
start_time = time.time()#程序启动时间
asyncio.run(get_data())
print('程序总耗时:{}'.format(time.time() - start_time))
在这段代码中,我们仅使用了协程(coroutine)这个概念,单单使用协程是无法完成异步编程的。因为它不能被调度,虽然都写成了协程的形式,但是不能同时加入一个事件循环,变成了两个协程,分别完成,又变回同步了。
上述代码的结果就是4s多一点。表明了协程不能被直接调度,局限性很高,没有什么方法。所以一定要引入Task的概念,实现多任务并发从而达到异步的效果。
task与协程混用
考虑以下代码
import time
import asyncio
async def one_data():
print('正在暂停1号靓仔')
await asyncio.sleep(3)#沉睡3秒
print('正在恢复1号靓仔')
async def two_data():
print('正在暂停2号靓仔')
await asyncio.sleep(1)#沉睡1秒
print('正在恢复2号靓仔')
async def one_event_loop():
print('\n***我是第1个event_loop***')
loop = asyncio.get_event_loop()#获取当前事件循环
task = loop.create_task(one_data())#创建Task
await two_data()#等待1秒
await task#等待3秒
start_time = time.time()
asyncio.run(one_event_loop())
print('耗时:{}'.format(time.time() - start_time))
执行结果为:

这表明,是可以进行混用的,但是只有协程在task前面,才能被识别到,进行并发。如果先等待task,就无法识别成功了,会创造出独立的协程空间。
但是一般情况下不会混用,了解一下
create_task
获取事件循环并创建,是python3.5及之前的写法,现在可以直接使用create_task进行创建,在3.11的版本下,源码是这样的:
def create_task(coro, *, name=None, context=None):
"""Schedule the execution of a coroutine object in a spawn task.
Return a Task object.
"""
loop = events.get_running_loop()
if context is None:
# Use legacy API if context is not needed
task = loop.create_task(coro)
else:
task = loop.create_task(coro, context=context)
_set_task_name(task, name)
return task
关键的get_running_loop()官方释义是这样的:
链接:https://docs.python.org/zh-cn/3.7/library/asyncio-eventloop.html#asyncio.get_running_loop
返回当前 OS 线程中正在运行的事件循环。
如果没有正在运行的事件循环则会引发 RuntimeError。 此函数只能由协程或回调来调用。
那么,这两个写法有区别吗?
await asyncio.create_task(one_data())
await asyncio.create_task(two_data())
和
task1 = asyncio.create_task(one_data())
task2 = asyncio.create_task(two_data())
await task1
await task2
答案当然是有的。
前者的写法调用create_task的时候返回task,然后迅速await,task开始运行,已经有了自己的上下文。下面再次运行时,上下文仍然是None,又会重新创建Task。无法完成并发需求。
后者的写法,第一次使用create_task后,没有开始执行等待,仍然存在于线程中,第二次使用时,就可以识别出同一上下文,加入同一事件循环。开始await之后,就可以达到并发效果,先后顺序也没有什么关系,因为都在一个事件循环中。
小总结
基于上述内容,可以得到:
- 协程不可以调度,不能达到并发效果。
- Task与协程混用,必须将协程写在Task之前,可以达到并发效果,但不推荐。
- Task调度需要保证在同一事件循环中才可完成并发。
ensure_future
或许你会问,为什么不讲future呢?
future类属于基类,会暴露很多api ,但是,在这里也可以了解一下。使用ensure_future就可以创建了。
同时这个方法也可以返回Task,在函数内部有一个判断,如果传入的是coroutine,task就返回task,传入的是future就会返回future。
如果想深入了解:
https://docs.python.org/zh-cn/3.7/library/asyncio-future.html#asyncio.ensure_future
gather
官方解释在这里:https://docs.python.org/zh-cn/3.7/library/asyncio-task.html#asyncio.gather
它是这样说的:
并发 运行 aws 序列中的 可等待对象。
如果 aws 中的某个可等待对象为协程,它将自动作为一个任务加入日程。
(aws即awaitable)
如果所有可等待对象都成功完成,结果将是一个由所有返回值聚合而成的列表。结果值的顺序与 aws 中可等待对象的顺序一致。
那么向这个方法传入task,coroutine都是可以的。这个方法产生的返回值就是一个有序列表的形式。考虑一下代码:
import time
import asyncio
async def one_data():
print('正在暂停1号靓仔')
await asyncio.sleep(3)
print('正在恢复1号靓仔')
return '我是1号靓仔'
async def two_data():
print('正在暂停2号靓仔')
await asyncio.sleep(1)
print('正在恢复2号靓仔')
return '我是2号靓仔'
async def get_data():
print('\n***我是第1个gather***')
# print(await asyncio.gather(one_data(), two_data()))
'使用Task写法'
task1 = asyncio.create_task(one_data())
task2 = asyncio.create_task(two_data())
print(await asyncio.gather(task1, task2))
start_time = time.time()
asyncio.run(get_data())
print('耗时:{}'.format(time.time() - start_time))
运行结果:

这说明,顺利产生了并发,进入了同一个事件循环,返回值会以有序列表存储,顺序为传入aws的顺序。
gather当然也提供了错误处理的方式。在常规情况下,为停止模式,产生错误后,会立刻发送异常信号并在gather中传播,代码终止。例如这样:

awaitable asyncio.gather(*aws, return_exceptions=False)
如果 return_exceptions 为 True,异常会和成功的结果一样处理,并聚合至结果列表。
更改示例代码为这样:
import time
import asyncio
async def one_data():
print('正在暂停1号靓仔')
await asyncio.sleep(3)
print('正在恢复1号靓仔')
return '我是1号靓仔'
async def two_data():
print('正在暂停2号靓仔')
await asyncio.sleep(1)
1/0
print('正在恢复2号靓仔')
return '我是2号靓仔'
async def get_data():
print('\n***我是第1个gather***')
# print(await asyncio.gather(one_data(), two_data()))
'使用Task写法'
task1 = asyncio.create_task(one_data())
task2 = asyncio.create_task(two_data())
print(await asyncio.gather(task1, task2,return_exceptions=True))
start_time = time.time()
asyncio.run(get_data())
print('耗时:{}'.format(time.time() - start_time))
执行结果:

捕获gather异常值及任务取消
任务取消,使用task.cancel(),可以主动发出取消信号,引发异常。异常名为CancelledError。同样可以根据设置return_exceptions=True来选择对异常进行停止还是忽略。
大概就像这样:
task1 = asyncio.create_task(one_data())
task2 = asyncio.create_task(two_data())
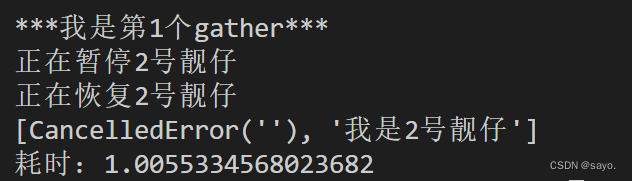
task1.cancel()#取消
print(await asyncio.gather(task1, task2,return_exceptions=True))
执行结果:
推荐写法为try-except结构:
try:
asyncio.run(get_data())
except asyncio.CancelledError as e:
print('\n异常值:{}'.format(e))
print('触发了CancelledError异常')
3.11下的新版写法:TaskGroup
gather已经是较为上层的api,在3.11的版本下,有了更加简洁和优雅的写法。在前面gather的使用中,需要先create_task,再放入 gather,再await。TaskGroup可以把这几个过程再次整合。示例是这样的:
async def main():
async with asyncio.TaskGroup() as tg:
task1 = tg.create_task(some_coro(...))
task2 = tg.create_task(another_coro(...))
print("Both tasks have completed now.")
可以快速而优雅的完成并发。但是需要较高版本,这里不过多介绍,可以看下面的官方链接
官方链接:
https://docs.python.org/zh-cn/3.11/library/asyncio-task.html#asyncio.TaskGroup
wait
官方链接:
https://docs.python.org/zh-cn/3.7/library/asyncio-task.html#asyncio.wait
在3.11官方文档的解释是这样的:

注意注意:如果你现在使用的是3.11的版本,现在已经不能直接传入协程对象,那么你需要先转换为Task对象。
显然,通过这个方法,你可以对并发的退出条件进行颗粒化控制。不会局限于完成所有可等待任务后退出。阅读可知,通过return_when来对退出条件进行控制,默认为ALL_COMPLETED
代码示例:
async def one_data():
print('正在暂停1号靓仔')
await asyncio.sleep(3)
print('正在恢复1号靓仔')
return '我是1号靓仔'
async def two_data():
print('正在暂停2号靓仔')
await asyncio.sleep(1)
print('正在恢复2号靓仔')
return '我是2号靓仔'
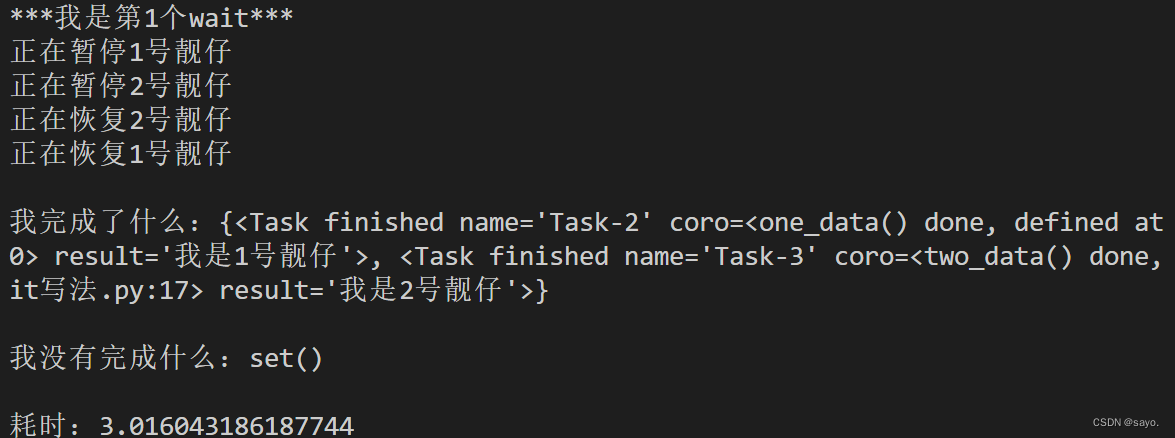
async def get_data():
print('\n***我是第1个wait***')
list_data = [asyncio.create_task(i) for i in (one_data(), two_data())]
done, pending = await asyncio.wait(list_data,return_when = asyncio.FIRST_COMPLETED)
# done, pending = await asyncio.wait(list_data,return_when = asyncio.FIRST_EXCEPTION)
print('\n我完成了什么:{}'.format(done))
print('\n我没有完成什么:{}'.format(pending)
start_time = time.time()
asyncio.run(get_data())
print('\n耗时:{}'.format(time.time() - start_time))
运行结果:

可以看到,可以设置首次完成任务即可退出,所以耗时仅一秒,Task有finished,pending状态。
设置为FIRST_EXCEPTION,会在第一次出现错误的时候停止,可以先设置一个错误代码。这里不再演示,如果你感兴趣,可以动手试试。
读取wait返回值
显然地,在上述示例中返回的done,pending是set类型,就像这样:
直接for循环就可以读取:
for i in done:#读取全部完成的任务
print('\n我完成了什么:{}'.format(i.result()))
for i in pending:#读取全部没有完成的任务
print('\n我没有完成什么:{}'.format(i))
wait_for
下面是3.11的wait_for官方解释,仍然是等待aw对象完成,这个方法可以从时间维度上对协程进行控制。

注意下面的版本更迭提示。
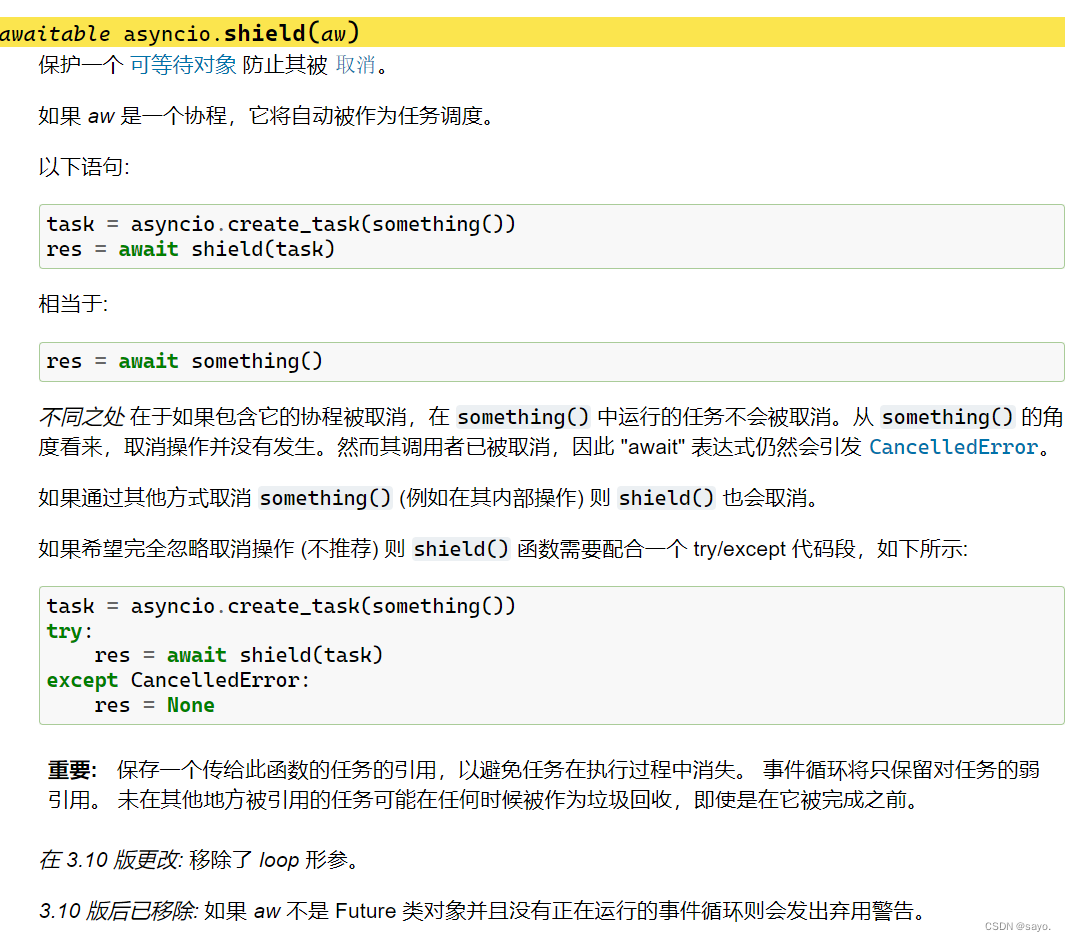
shield
shield方法用于保护任务不被取消,官方文档是这样说的,仍然有版本更迭,注意区分
虽然可以保护取消,但是在并发的时候,asyncio的run方法会获取新的事件循环并指定为当前事件循环,设定保护后可能会带来冲突。例如设定一个等待三秒的任务同时设有保护(相当于加了一个壳),还有一个等待两秒的任务,取消第一个任务并使用gather进行并发。最后的结果会丢失第一个任务。这是因为外侧的任务完成后,无法识别到里面的任务为同一个事件循环,无法进入并发。
可以参考以下代码:
import asyncio
async def one_data():
print('正在暂停1号靓仔')
await asyncio.sleep(1)
print('正在恢复1号靓仔')
return '我是1号靓仔'
async def two_data():
print('正在暂停2号靓仔')
await asyncio.sleep(2)
print('正在恢复2号靓仔')
return '我是2号靓仔'
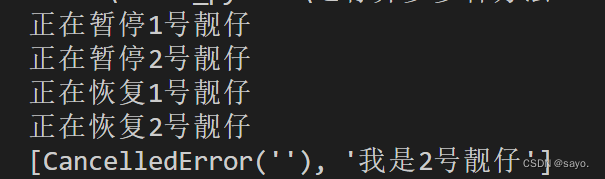
async def mainx():
task1 = asyncio.shield(one_data())
task2 = asyncio.create_task(two_data())
task1.cancel()
shield = asyncio.gather(task1, task2,return_exceptions = True)
print(await shield)
asyncio.run(mainx())
执行结果:
最好是保证保护的任务时长比普通任务时长短,可以保证保护。也可以修改最后的run方法。采用轮询的方法
loop = asyncio.get_event_loop()#获取当前事件循环
loop.run_until_complete(shield())
如果这里有点没理解到也没关系。后续会结合实例继续讲解。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java中比好用的工具
- 诺德物业管理系统(JSP+java+springmvc+mysql+MyBatis)
- 计算机毕业设计 | SpringBoot+vue校园问卷调查系统(附源码)
- VL53L5CX距离传感器
- 如何使用ChatGPT写出优质文章
- 一文解读Transformer神经网络中的注意力机制
- 20240106-换一种思维,工作也不过就是一种挣钱的方式而已了
- C++类与对象(四):再谈构造函数(详解初始化列表)、Static成员
- Pytest 测试框架与Allure 测试报告——Allure2测试报告-L3
- 羚羊创客少儿编程——孩子创造力的助燃器