【博士每天一篇论文-综述】Brain Inspired Computing_ A Systematic Survey and Future Trends
阅读时间:2023-11-17
1 介绍
年份:2023
作者:李国琪
期刊:TechRxiv
引用量:2
这篇论文主要介绍了脑启发计算(Brain Inspired Computing,BIC)以及其在人工智能(Artificial Intelligence,AI)领域的相关性。BIC是一个交叉学科的领域,涵盖了众多的领域,如计算神经科学、统计物理学、芯片设计、材料科学、计算机科学和人工智能。论文指出,BIC旨在基于生物神经系统的信息处理机制和结构,构建基本理论、模型、硬件架构和应用系统。并提出了建立基于脉冲神经网络(SNN)的理论模型、训练算法、硬件架构和应用系统的概念。本文重点关注BIC基础设施开发的四个组成部分:建模/算法、硬件平台、软件工具和基准数据。
2 创新点
(1)系统性的综述:这篇论文提供了对脑启发计算(BIC)领域的系统性综述,包括模型/算法、硬件平台、软件工具和基准数据四个组成部分的最新进展、主要挑战和未来趋势。
(2)多领域跨学科:这篇论文的作者团队拥有涵盖脑启发计算理论、数据、计算架构、软件和芯片设计等方面的全栈知识,在多个领域跨学科的背景下进行了广泛的综述,使读者能够从更广阔的视角思考这个领域。
(3)提出了BIC系统框架:在论文中,提出了一个面向真实世界应用的BIC系统的框架,该框架有望对人工智能和脑科学都产生积极影响。
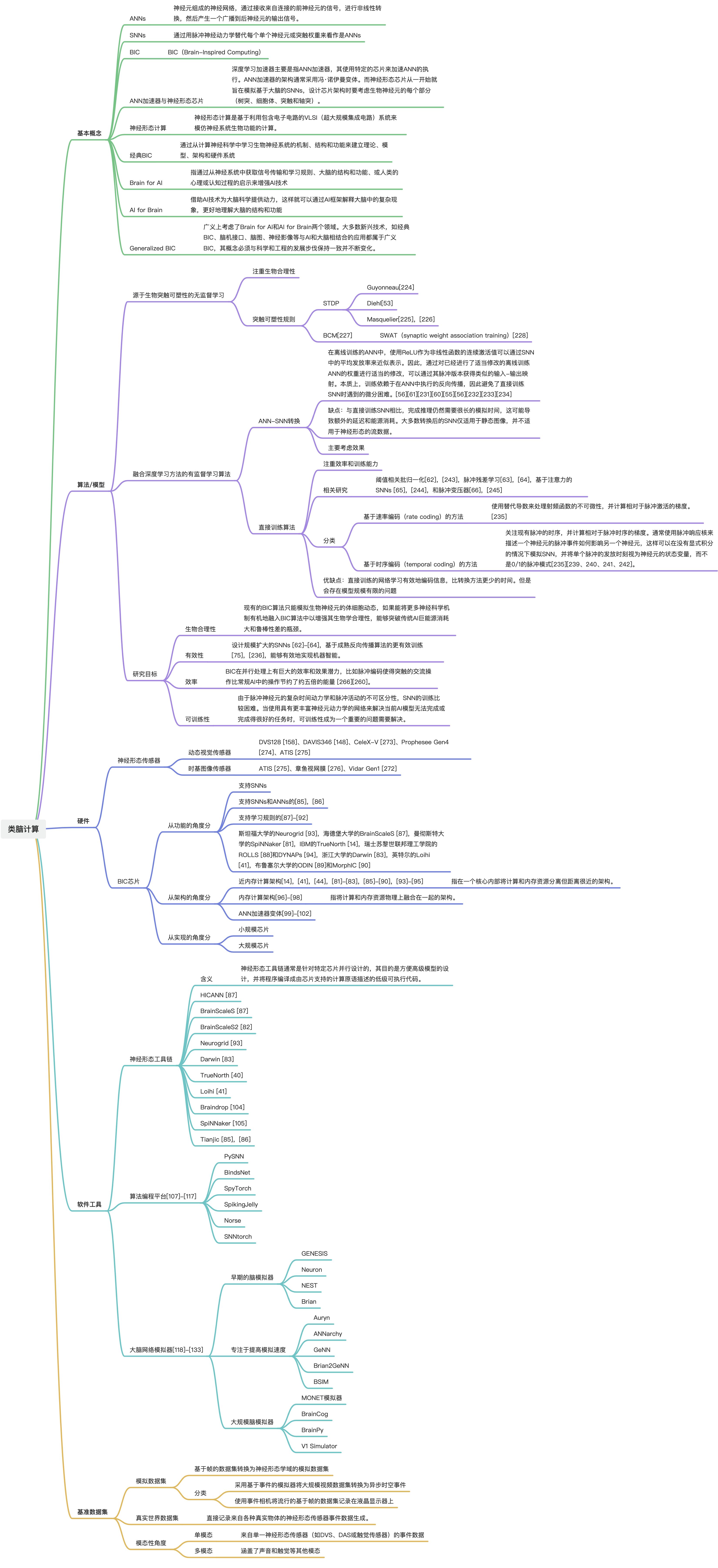
3 相关概念
(1)ANNs
人工神经网络(ANNs)是由神经元组成的神经网络,通过接收来自连接的前神经元的信号,进行非线性转换,然后产生一个广播到后神经元的输出信号。
(2)SNNs
脉冲神经网络(SNNs)可以通过用脉冲神经动力学替代每个单个神经元或突触权重来看作是ANNs。脉冲神经动力学的范围变化很大,可以是简单的一阶微分方程,也可以是一组微分方程,甚至动力学存在于细胞体和树突之中。ANN和SNN共享相同的网络拓扑,区别在于SNN中的神经元由于神经动力学而具有微分方程的特性。由于SNN具有丰富的动态特性,其中的脉冲依赖于神经线路的概念,能量效率要比传统神经计算高。
(3)BIC
BIC(Brain-Inspired Computing)与深度学习需要明确区分,深度学习模型主要是建立在ANNs上的,其中每个神经元都是一个MAC单元后面跟随一个非线性函数,无论网络有多深、多宽和复杂。另一方面,BIC主要建立在SNNs上,其中每个神经元具有丰富的动态特性。
(4)ANN加速器与神经形态芯片
深度学习加速器主要是指ANN加速器,其使用特定的芯片来加速ANN的执行。ANN加速器的架构通常采用冯·诺伊曼变体。而神经形态芯片从一开始就旨在模拟基于大脑的SNNs,设计芯片架构时要考虑生物神经元的每个部分(树突、细胞体、突触和轴突)。
(5)神经形态计算
神经形态计算是基于利用包含电子电路的VLSI(超大规模集成电路)系统来模仿神经系统生物功能的计算。“神经形态”常用来描述模拟神经系统模型的模拟、数字、模拟-数字混合VLSI和软件系统。在本文中,“神经形态”是经过硬件加速的经典BIC的子集。
(6)经典BIC
经典BIC旨在通过从计算神经科学中学习生物神经系统的机制、结构和功能来建立理论、模型、架构和硬件系统。从建模的角度来看,经典BIC主要指SNN模型、神经形态芯片及其受计算神经科学启发的应用。从计算架构的角度来看,经典BIC通常利用近存储计算架构和内存计算架构。经典BIC是神经形态计算的超集,因为经典BIC不仅限于硬件,其理论、模型、架构和硬件系统都可以受到生物神经系统行为和物理的启发,因此神经形态芯片也可以被称为BIC芯片。
(7)Brain for AI
“Brain for AI”是指通过从神经系统中获取信号传输和学习规则、大脑的结构和功能、或人类的心理或认知过程的启示来增强AI技术。这可以减少AI消耗的资源和电能,在大脑中是基本的但对传统AI来说困难的任务上取得可比较的性能,建立下一代AI的通用原则或框架,或解决深度学习领域的现有问题。经典BIC是Brain for AI的一个子集,因为前者主要关注系统的计算/学习能力,而后者还可以涉及与AI技术相关的一般概念。
(8)AI for Brain
“AI for Brain”可以借助AI技术为大脑科学提供动力,这样就可以通过AI框架解释大脑中的复杂现象,更好地理解大脑的结构和功能。此外,AI可以加强大脑成像技术,并促进对大脑结构或功能的研究。
(9)Generalized BIC
Generalized BIC广义上考虑了Brain for AI和AI for Brain两个领域。大多数新兴技术,如经典BIC、脑机接口、脑图、神经影像等与AI和大脑相结合的应用都属于广义BIC,其概念必须与科学和工程的发展步伐保持一致并不断变化。
4 相关研究
4.1 算法/模型
现有的类脑算法和模型包含了单个神经元在细胞层面上的模型,以及SNN模型在网络层面上的模型和训练机制。
(1)SNN等于ANN加上神经元动力学
ANN和SNN可以共享相同的网络拓扑,不同之处在于SNN中的神经元由于神经元动力学而被表征为微分方程,其中脉冲依赖于这样的动力学。人工神经网络(ANN)神经元在没有时间维度的情况下产生输出[215],[216]。脉冲模型则模拟细胞体(和树突分区)中膜电位(以及可能的其他状态变量)的动力学,其输出是在一定时间内的脉冲列。
(2)神经元动力学的范围差异很大
- 一阶微分方程:leaky integrate-and-fire(LIF)模型[48]
- 一组微分方程:Hodgkin-Huxley(H-H)模型[49]、zhikevich模型[213]
- 动力学不仅存在于细胞体中,还存在于树突[50、51、52]
(3)关于学习算法,现有的方案可以分为三类,
- 无监督学习[24],[53]
- ANN-SNN转换[54]-[61]
- 直接训练算法[20],[62] -[75]
(4)其他类脑算法模型
- liquid state machine液态机器[76]
- echo state networks回声状态网络(ESN)[77]
- continuous attractor neural networks连续吸引子神经网络(CANN)[78]
(5)ANN的网络学习算法
ANN的训练是一个依赖于数据的过程,其目标是优化网络的关键参数以完成特定的任务。包括SGD、ADAM、AMSGrad。
(6)SNNs的网络学习算法
- 源于生物突触可塑性的无监督学习:注重生物合理性
突触可塑性是神经记忆和学习的生物基础,突触可塑性规则包括Hebbian learning and spike-timing dependent plasticity(STDP)和Bienenstock-Cooper-Munro(BCM)[227]。Guyonneau[224]发现在STDP规则下,通过传入神经元群体对目标脉冲进行模拟,可以在单个突触后神经元中实现快速识别和选择性响应。Diehl等人[53]展示了一个仅由单层兴奋型神经元和相应的抑制型神经元构成的双层SNN,其中来自输入的兴奋型连接通过STDP进行训练,随后的抑制层确保神经元之间的侧向抑制和竞争。完成无监督训练后,兴奋型神经元能够有选择地对输入特征进行响应,在MNIST上达到95%的准确率。Masquelier等人[225],[226]设计了一种基于STDP的前馈SNN,模仿大脑中腹侧视觉通路的特点。该网络逐渐发展出对共同特征的选择性,并缩短了激活神经元所需的延迟,最终重要特征信息的脉冲会快速发出,并可用于分类任务。此外,将STDP规则应用于脉冲卷积神经网络(CNNs)[24]。最后神经元的膜电位被插入支持向量机(SVM)作为分类器的输入,实现了在MNIST上98.4%的准确率。
BCM(Bienenstock-Cooper-Munro)规则[227]是另一种基于视觉皮层实验提出的突触可塑性规则,最初于1982年提出。原始的STDP规则没有包括用于突触连接的衰减或增强机制,导致构建模型时不稳定。因此,BCM规则假设神经元具有根据历史的权重变化动态调整的阈值,并被用于确定突触变化的趋势,使得连接最终能达到稳定状态。随后的SWAT(synaptic weight association training)[228]在BCM规则中引入了变化阈值,形成了对STDP窗口形状的负反馈调节,增强了训练的稳定性。
- 融合深度学习方法的有监督学习算法
- ANN-SNN转换算法:主要考虑效果。该方法的基本思想是,在离线训练的ANN中,使用ReLU作为非线性函数的连续激活值可以通过SNN中的平均发放率来近似表示。因此,通过对已经进行了适当修改的离线训练ANN的权重进行适当的修改,可以通过其脉冲版本获得类似的输入-输出映射。本质上,训练依赖于在ANN中执行的反向传播,因此避免了直接训练SNN时遇到的微分困难。为了使模型在转换后对脉冲活动更具适应性,对原始的ANN模型施加一定的结构约束。[56][61][231][60][55][56][232][233][234]。缺点:与直接训练SNN相比,完成推理仍然需要很长的模拟时间,这可能导致额外的延迟和能源消耗。大多数转换后的SNN仅适用于静态图像,并不适用于神经形态的流数据。此外,转换方法更关注缩小ANN和SNN之间的性能差距,而不是探索SNN的内在动力学或独特性,因此它们在推动脑启发式智能方面的作用相对有限。
- 直接训练算法:注重效率和训练能力。直接训练是指直接使用梯度下降算法训练SNN。直接训练方法可以分为以下两类。优缺点:直接训练的网络学习有效地编码信息,比转换方法更少的时间。但是会存在模型规模有限的问题,因此进一步的研究包括阈值相关批归一化[62],[243],脉冲残差学习[63],[64],基于注意力的SNNs [65],[244],和脉冲变压器[66],[245]。
- 基于速率编码(rate coding)的方法通过使用替代导数来处理射频函数的不可微性,并计算相对于脉冲激活的梯度。通常采用替代梯度函数或平滑的激活函数,将不连续的脉冲活动连续化,以便通过时间的反向传播(BPTT)来训练SNN。这种方法可以通过空间和时间域解决信用分配问题。[235 ]
- 基于时序编码(temporal coding)的方法则关注现有脉冲的时序,并计算相对于脉冲时序的梯度。通常使用脉冲响应核来描述一个神经元的脉冲事件如何影响另一个神经元,这样可以在没有显式积分的情况下模拟SNN,并将单个脉冲的发放时刻视为神经元的状态变量,而不是0/1的脉冲模式[235][239、240、241、242]。
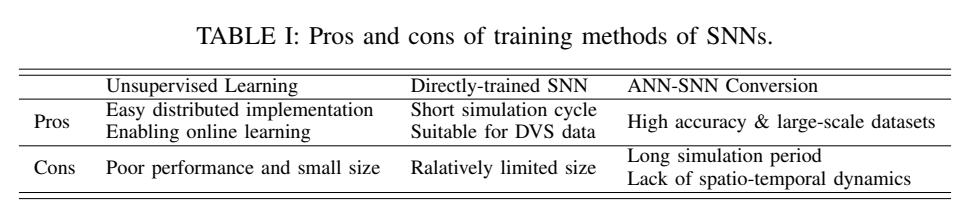
(7)研究目标
- 生物合理性
现有的BIC算法只能模拟生物神经元的体细胞动态,如果能将更多神经科学机制有机地融入BIC算法中以增强其生物学合理性,能够突破传统AI巨能源消耗大和鲁棒性差的瓶颈。
- 有效性
设计规模扩大的SNNs [62]-[64],基于成熟反向传播算法的更有效训练[75],[236],能够有效地实现机器智能。
- 效率
BIC在并行处理上有巨大的效率和效果潜力,比如脉冲编码使得突触的交流操作比常规AI中的操作节约了约五倍的能量 [266][260]。已知提升效率的一些影响因素包括脉冲神经元建模、网络结构和规模、数据集大小、训练技术、惩罚函数等等。比如,引入可学习的膜时间常数[69],融合长短期记忆单元[260],或调节神经元级别的膜电位分布[267],可以起到调节脉冲活动和任务准确性的作用。基于参数正则化方法包括活动正则化或网络压缩[237],[268],[269]。以及基于数据依赖处理的方法,即根据输入调整脉冲响应,例如在时序维度直接屏蔽不重要的信息[68],以减少脉冲同时保持任务性能。
- 可训练性
由于脉冲神经元的复杂时间动力学和脉冲活动的不可区分性,SNN的训练比较困难。当使用具有更丰富神经元动力学的网络来解决当前AI模型无法完成或完成得很好的任务时,可训练性成为一个重要的问题需要解决。尤其网络规模已被证明是提高深度学习模型性能和可扩展性的关键因素。所以,需要进一步开发更符合生理学的细粒度脉冲神经元模型,提高BIC算法的可训练型。
4.2 硬件
4.2.1 神经形态传感器
用脉冲输出的神经形态相机使用时空一位点来编码光强度[277]。一般来说,这些仿生相机可以分为两类,包括动态视觉传感器(DVS)[158]和时基图像传感器[278]。
(1)动态视觉传感器
一些典型的事件相机包括DVS128 [158]、DAVIS346 [148]、CeleX-V [273]、Prophesee Gen4 [274]、ATIS [275]等。由于具有高时间分辨率(微秒级)、高动态范围(HDR)、低冗余、低延迟和低功耗的优势。
(2)时基图像传感器
典型的视觉传感器包括ATIS [275]、章鱼视网膜 [276]、Vidar Gen1 [272]等。空间分辨率、传输带宽和填充因子有明显的增加趋势,而芯片尺寸和像素尺寸有所减小。时基图像传感器可以通过脉冲频率或脉冲间隔重构出细腻的纹理,但无法直接从读出电路中获取动态信息。
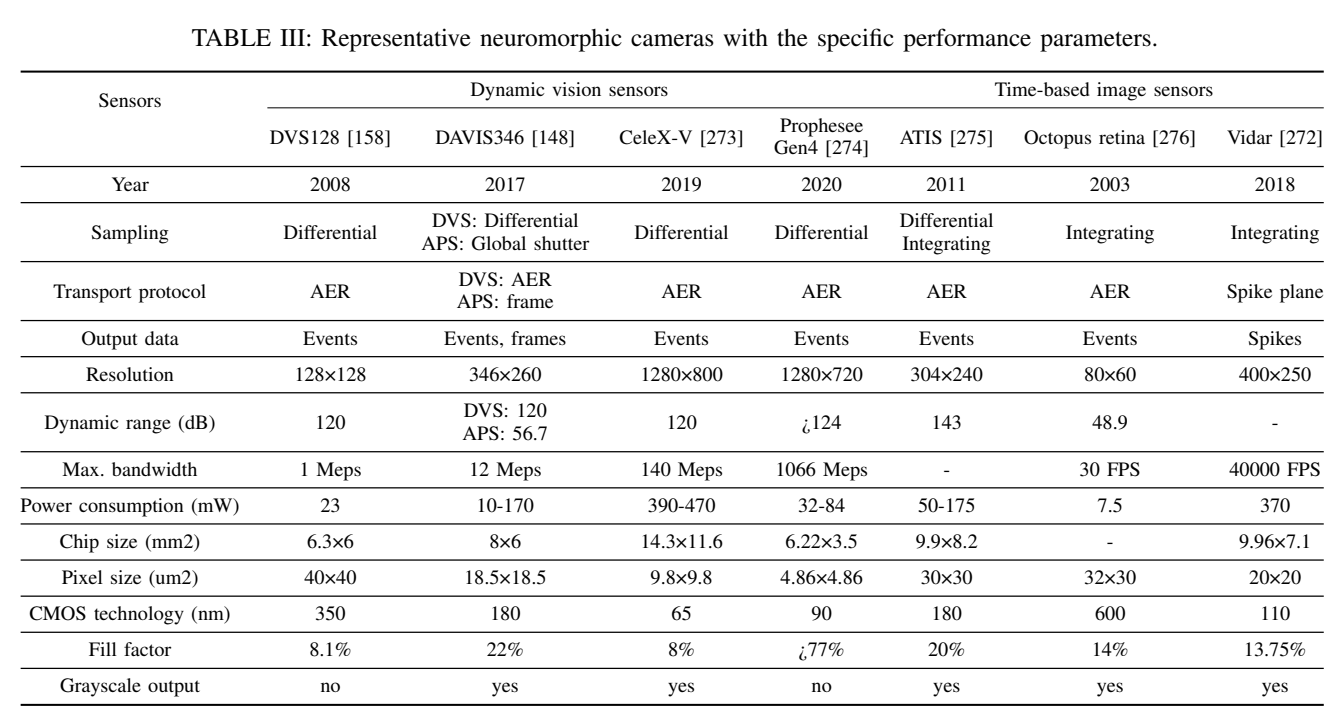
4.2.1 BIC芯片
BIC芯片也可以被称为神经形态芯片。不同于深度学习加速器,BIC芯片是仿真以大脑为灵感的SNNs。在大脑皮层中,计算和存储器是集成在一起的,而不是在冯·诺依曼架构中明确分离。因此,大多数BIC芯片采用了多核分散架构[84],每个核心都具有紧密耦合的局部计算和存储资源。BIC芯片具有巨大的计算并行性和高内存局部性,无需访问片外存储器。主流的神经形态/BIC芯片和平台可以根据功能、计算架构和实现技术分为三个独立的角度。
(1)从功能的角度来看,现有的BIC芯片可以分为三类
- 支持SNNs
- 支持SNNs和ANNs的[85],[86]
- 支持学习规则的[87]-[92]
一些经典的功能芯片,包括斯坦福大学的Neurogrid [93],海德堡大学的BrainScaleS [87],曼彻斯特大学的SpiNNaker [81],IBM的TrueNorth [14],瑞士苏黎世联邦理工学院的ROLLS [88]和DYNAPs [94],浙江大学的Darwin [83],英特尔的Loihi [41],布鲁塞尔大学的ODIN [89]和MorphIC [90]等。
一些团队提出开发跨范式平台,结合SNN和ANN。清华大学的天机 [85],[86]是首个发明混合模型和架构的BIC芯片,可以支持SNN,ANN和混合神经网络(HNNs)[283]。
(2)从架构的角度来看
- 近内存计算架构[14],[41],[44],[81]-[83],[85]-[90],[93]-[95]:近内存计算架构是指在一个核心内部将计算和内存资源分离但距离很近的架构。多数早期的神经形态芯片都采用了近内存计算架构。TrueNorth、Tianjic、Darwin、Loihi、ODIN和MorphIC等芯片都在每个核心中采用了分离但紧密的内存和计算。SpiNNaker将外部内存密集地放置在每个计算芯片上,也可以看作是与常见的冯·诺依曼架构相比的近内存计算。最近,研究人员在设计人工神经网络加速器时,也借鉴了BIC领域的类似架构。例如,Graphcore的出现IPU、Habana的Goya和Gaudi、阿里巴巴的Hanguang以及NVIDIA的Simba都将分布式多核架构应用于其ANN加速器中以提高吞吐量。这些芯片中每个核心的组织方式也属于近内存计算架构。
- 内存计算架构[96]-[98]:指将计算和内存资源物理上融合在一起的架构。在这种架构中,突触积分的矩阵操作在突触内存中执行。通常有两种类型的计算用内存:基于传统内存和基于新兴内存。传统内存,如SRAM、DRAM和Flash,可以重新设计以支持一些逻辑操作。新兴内存主要指基于记忆电阻器的存储设备。
- ANN加速器变体[99]-[102]
(3)从实现的角度来看
需要考虑的因素包括应用场景、PPA(性能、功耗和面积)和可编程性[103]。小规模芯片和大规模芯片是两个不同的类别,对于小规模芯片来说,边缘应用、低功耗和实时响应是刚性需求。然而,对于大规模芯片来说,主要目标是构建一个大脑模拟器来探索人工通用智能。大规模芯片的设计原则与小规模芯片不同,需要考虑可扩展性、可编程性、可靠性和兼容性等因素。目前,BIC芯片面临的挑战包括跨域融合、传感器集成、性能挑战和系统易用性。最近的BIC芯片越来越关注BIC系统、软件工具链和应用领域,以提高用户体验。

4.3 软件工具

大脑启发软件可以根据其用途和基础结构分为三类
(1)神经形态工具链[40],[41],[82],[83],[85]-[87],[93],[104]-[106]
神经形态工具链通常是针对特定芯片并行设计的,其目的是方便高级模型的设计,并将程序编译成由芯片支持的计算原语描述的低级可执行代码。
HICANN [87]使用PyNN [122]作为Python接口,用于指定模型架构、输出的评估以及部署到硬件上的实验形式。由于生物网络具有基于图的表示,因此配置数据的计算方式与将用HDL编写的设计部署到FPGA上的过程类似。
BrainScaleS [87]软件通过PyNN [122]提供了实验电子规范的统一表示,并将生物设计转化为硬件原语。BrainScaleS2 [82]使用修改后的GCC编译器作为工具链,支持矢量指令。基于该编译器,硬件与C++标准库兼容。因此,硬件抽象库(HAL)可以在芯片和主机系统上都可用。
Neurogrid [93]的软件具有用于交互可视化的GUI界面和用于将模拟网络转化为硬件空间的硬件抽象层(HAL)。
Darwin [83]提供了一个层次结构和模块化的操作系统Darwin-S,具有自己的模型定义语言。应用IDE包括模型开发工具包和调试工具,方便用户使用。
TrueNorth [40]团队开发了一种用于模型定义的本地Corelet语言,以及用于模拟芯片架构的Compass软件。它还支持各种可组合的算法用于应用开发。
Loihi [41]的工具链包括一个Python API,用于设计SNN的拓扑结构和自定义学习规则。编译器和运行时库用于将模型转化为在芯片上执行的原语。Loihi 2 [106]是Loihi的第二代,它提供了一个名为Lava的开源软件,该软件是与硬件无关的。Lava不针对特定芯片,声称可在传统处理器和神经形态学处理器之间实现可移植性。
Braindrop [104]提供一个将抽象计算转化为在芯片上执行的可执行代码的自动化合成软件。该软件包括与Nengo [309]软件的前端交互和与驱动软件的后端接口。
SpiNNaker [105]提供了一个基于PyNN描述或其他格式的配置软件。它获取神经电路的定义并生成路由信息。神经网络和节点拓扑被视为一个图,可以通过软件配置,然后上传到节点网格。
Tianjic [85],[86]是第一个将ANN和SNN集成到具有多核架构的混合神经形态学芯片的尝试。他们开发了一个软件框架,用于对各种神经网络进行统一描述和转换。
(2)算法编程平台[107]-[117]
算法编程平台中的软件希望促进snn的实现并利用计算机科学的进步。
BindsNet、PySNN、SpyTorch、SpikingJelly、Norse和SNNtorch支持通用的SNN。BindsNet特别适用于机器学习和强化学习,并具有与OpenAI gym的接口。PySNN专注于基于相关性的学习方法。SpyTorch提出了一种名为SuperSpike的新型替代梯度方法,用于平滑尖峰信号。SpikingJelly集成了许多神经形态学数据集,如CIFAR10-DVS、ASL-DVS和DVS Gesture,用户可以轻松加载这些数据集。Norse试图引入SNN的稀疏和事件驱动特性,并支持许多典型的神经元模型。SNNtorch建立了一些在线变种的反向传播方法,更符合生物学的可行性。
(3)大脑网络模拟器[118]-[133]
脑网络模拟器旨在模拟支持多种神经活动和突触模型的生物神经网络,或作为验证硬件性能,测试潜在硬件修改以及在没有广泛部署硬件的情况下开发脑启发算法的重要工具。BindsNet、PySNN、SpyTorch、SpikingJelly、Norse和SNNtorch支持通用的SNN。BindsNet特别适用于机器学习和强化学习,并具有与OpenAI gym的接口。PySNN专注于基于相关性的学习方法。SpyTorch提出了一种名为SuperSpike的新型替代梯度方法,用于平滑尖峰信号。SpikingJelly集成了许多神经形态学数据集,如CIFAR10-DVS、ASL-DVS和DVS Gesture,用户可以轻松加载这些数据集。Norse试图引入SNN的稀疏和事件驱动特性,并支持许多典型的神经元模型。SNNtorch建立了一些在线变种的反向传播方法,更符合生物学的可行性。
GENESIS、Neuron、NEST和Brian是早期的脑模拟器。Auryn、ANNarchy、GeNN、Brian2GeNN和BSIM等工具主要专注于提高模拟速度。大规模脑模拟器,包括MONET模拟器、BrainCog、BrainPy、V1 Simulator。
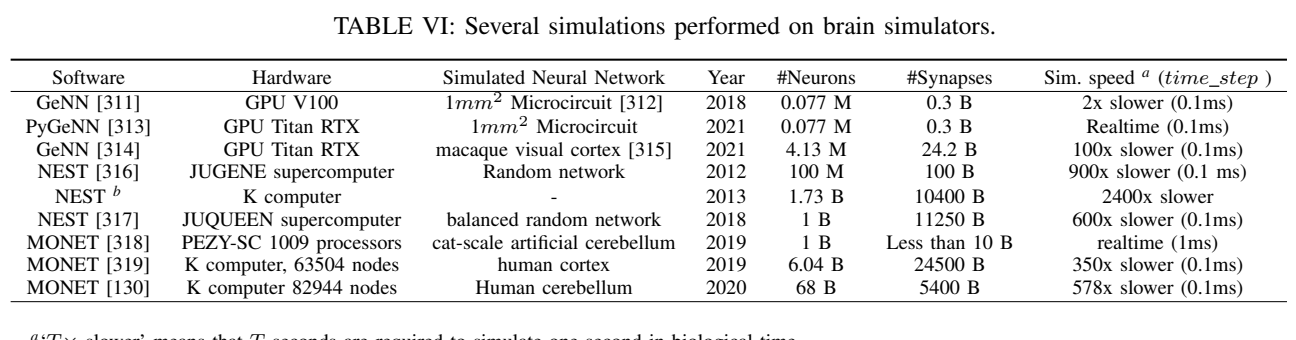
4.4 基准数据集
(1)模拟数据集
模拟BIC数据集通常基于基于事件的模拟器或事件相机生成,记录LCD显示器上受欢迎的基于帧的数据集的图像。模拟数据集将基于帧的数据集转换为神经形态学域的模拟数据集。其中一部分采用基于事件的模拟器将大规模视频数据集转换为异步时空事件。另一部分使用事件相机将流行的基于帧的数据集记录在液晶显示器上。
(2)真实世界数据集
真实世界数据集通过直接记录来自各种真实物体的神经形态传感器事件数据生成。
(3)从数据集的模态性角度
单模态和多模态。一些数据集仅包含来自单一神经形态传感器(如DVS、DAS或触觉传感器)的事件数据。大多数数据集是基于事件的视觉数据集,也有一些神经形态学数据集涵盖了声音和触觉等其他模态。另外,一些尝试将神经形态学传感器与其他感官模态(如LiDAR、RGB-D摄像头、红外摄像头、IMU和GPS)结合起来,用于具有挑战性场景的智能机器人。
5 实验分析
(1)比较了神经元模型的生物特征和能量消耗
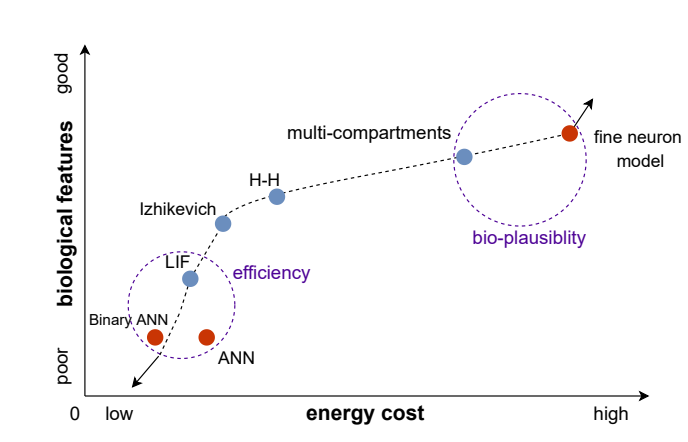
具有更高生物可行性的模型会消耗更多能量。LIF神经元模型不仅包含比典型ANN神经元更多的生物特征,而且能量消耗更低。Binary ANN神经元可以被视为最简单的没有时间动态的脉冲神经元,并且其能量消耗最低。fine neuron model在内的复杂神经元模型包含更多的生物可行性特征,但需要更高的计算复杂性和能量消耗。未来的研究可以着重于图中左下角的虚线圈,以提高计算效率和降低能量消耗,或者关注图中右上角的虚线圈,设计具有更多生物特征的模型,以完成传统人工智能难以实现的任务。
6 思考
本文非常系统全面的介绍了类脑的几大研究分支,并详细介绍了每个分布下的技术研究。非常完美优秀的一篇论文。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 捕捉“五彩斑斓的黑”:锗基短波红外相机的多种成像应用
- Nacos下载与安装【windows】
- 极狐 GitLab 冷知识:使用 git push 创建 Merge Request
- 图形处理工具:Photoshop Elements 2020 mac介绍说明
- 大文件上传原理
- 知识笔记(八十五)———Vue 3中toRaw和markRaw的使用
- 【工业智能】音频信号相关场景
- React中如何避免不必要的render?
- C# 常用数据类型及取值范围
- 轻量化CNN网络 - MobileNet