论文精读:VMamba Visual State Space Model
Author: Hongtian Yu, Lingxi Xie, Qixiang Ye, Yaowei Wang, Yue Liu, Yunfan Liu, Yunjie Tian, Yuzhong Zhao
Institution: 中国科学院大学(UCAS), 华为, 鹏城实验室
Publisher: arXiv
Publishing/Release Date: January 18, 2024
Summary: CNNs和ViTs是视觉特征表示领域常用的两个基座模型,CNNs具有显著的可扩展性,线性复杂度与图像分辨率相关,ViTs的拟合能力更强,通过注意力机制的全局感受野和动态权重可以有更好的表现,但是复杂度是二次的。本文提出了一种新的架构——VMamba(Visual State Space Model),继承了CNNs和ViTs的优点,同时还提高了计算效率,在不牺牲全局感受野的情况下可以达到线性复杂度。为了解决方向敏感问题,引入了交叉扫描模块( Cross-Scan Module,CSM )来遍历空间域,并将任何非因果的视觉图像转换为有序的块序列。VMamba不仅在各种视觉感知任务中表现出非常用前途的能力,而且随着图像分辨率的增加,与现有的基准相比,VMamba表现出更明显的优势。
Score /5: ????????
Type: Paper
论文链接: https://arxiv.org/abs/2401.10166
代码是否开源: 准备开源
代码链接: https://github.com/MzeroMiko/VMamba
数据集是否开源: 开源
数据集链接: https://paperswithcode.com/paper/vmamba-visual-state-space-model
读前先问
- 大方向的任务是什么?Task
视觉表征学习
- 这个方向有什么问题?是什么类型的问题?Type
ViT的表征能力虽然强,但是计算复杂度是二次的。
- 为什么会有这个问题?Why
注意力分数的计算机制决定的。
- 作者是怎么解决这个问题的?How
Mamba架构可以将计算复杂度降低到线性,利用Mamba重写了backbone。
- 怎么验证解决方案是否有效?
一方面验证效果有没有损失,另一方面验证计算复杂度有没有降低,以及提升图像分辨率后,计算复杂度的提升。
- 实验结果怎么样?What(重点关注有没有解决问题,而不是效果有多好)
看起来还可以,至少效果没有损失。
论文精读
引言
虽然CNNs和ViTs在计算视觉特征表示方面都取得了显著的成功,但与 CNN 相比,ViT 通常表现出更优越的性能,这主要归因于注意力机制促进的全局感受野和动态权重。然而注意力机制需要图像大小的二次复杂度,导致在处理下游稠密预测任务时计算开销很大。为了解决这个问题,本文设计了一种新的具有线性复杂度并且保留全局感受野和动态权重的模型架构——VMamba。
VMamba在有效降低注意力复杂度方面的关键概念继承自选择性扫描空间状态序列模型(Selective Scan Space State Sequential Model, S6 )。S6使一维数组(例如文本序列)中的每个元素通过压缩隐藏状态与先前扫描的任何样本进行交互,有效地将二次复杂度降为线性。
然而,由于视觉数据的非因果性质,直接将这种策略应用于补丁化和展平的图像将不可避免地导致受限的感受野,因为无法估计相对于未扫描的补丁的关系。作者将这个问题称为“方向敏感”问题,并提出通过新引入的**交叉扫描模块(Cross-Scan Module,CSM)**来解决它。CSM 不是以单向模式(列向或行向)遍历图像特征映射的空间域,而是采用四向扫描策略,即从特征映射的四个角到相对位置。这种策略确保特征映射中的每个元素从不同方向的所有其他位置集成信息,从而产生全局感受野,而不增加线性计算复杂性。

方法
状态空间模型(State Space Models)
状态空间模型(SSMs)通常被认为是将刺激 x ( t ) ∈ R L x(t) ∈ R^L x(t)∈RL 映射到响应 y ( t ) ∈ R L y(t) ∈ R^L y(t)∈RL 的线性时不变系统。从数学上讲,这些模型通常被构建为线性常微分方程(ODEs): h ′ ( t ) = A h ( t ) + B x ( t ) y ( t ) = C h ( t ) + D x ( t ) \begin{array}{l}h^{\prime}(t)=A h(t)+B x(t) \\y(t)=C h(t)+D x(t)\end{array} h′(t)=Ah(t)+Bx(t)y(t)=Ch(t)+Dx(t)?,其中 A ∈ C N × N A ∈ C^{N×N} A∈CN×N, B B B、 C ∈ C N C ∈ C^N C∈CN, N N N为状态大小,以及跳跃连接 D ∈ C 1 D ∈ C^1 D∈C1。
离散化(Discretization)
没看懂,后来再看一遍。
选择性扫描机制(Selective Scan Mechanism)
VMamba将选择性扫描机制(S6)作为核心 SSM 运算符,但它以因果方式处理输入数据,因此只能捕获数据的扫描部分内的信息。这使 S6 与涉及时间数据的 NLP 任务相吻合,但在应用到非因果数据(例如图像、图形、集合等)时面临重大挑战。解决这个问题的一种直接方法是沿两个不同方向(即前向和后向)扫描数据,允许它们互相补偿而不增加计算复杂性。
尽管图像具有非因果性质,但还有一个与文本的不同之处在于它们包含 2D 空间信息(例如局部纹理和全局结构)。为了解决这个问题,作者提出了交叉扫描模块(Cross-Scan Module,CSM)。选择沿行和列展开图像补丁成序列(扫描扩展),然后沿四个不同方向进行扫描:从左上到右下,从右下到左上,从右上到左下,从左下到右上。这样,任何像素都会从不同方向的所有其他像素中集成信息。然后将每个序列重新整形成单个图像,并将所有序列合并成一个新的序列。
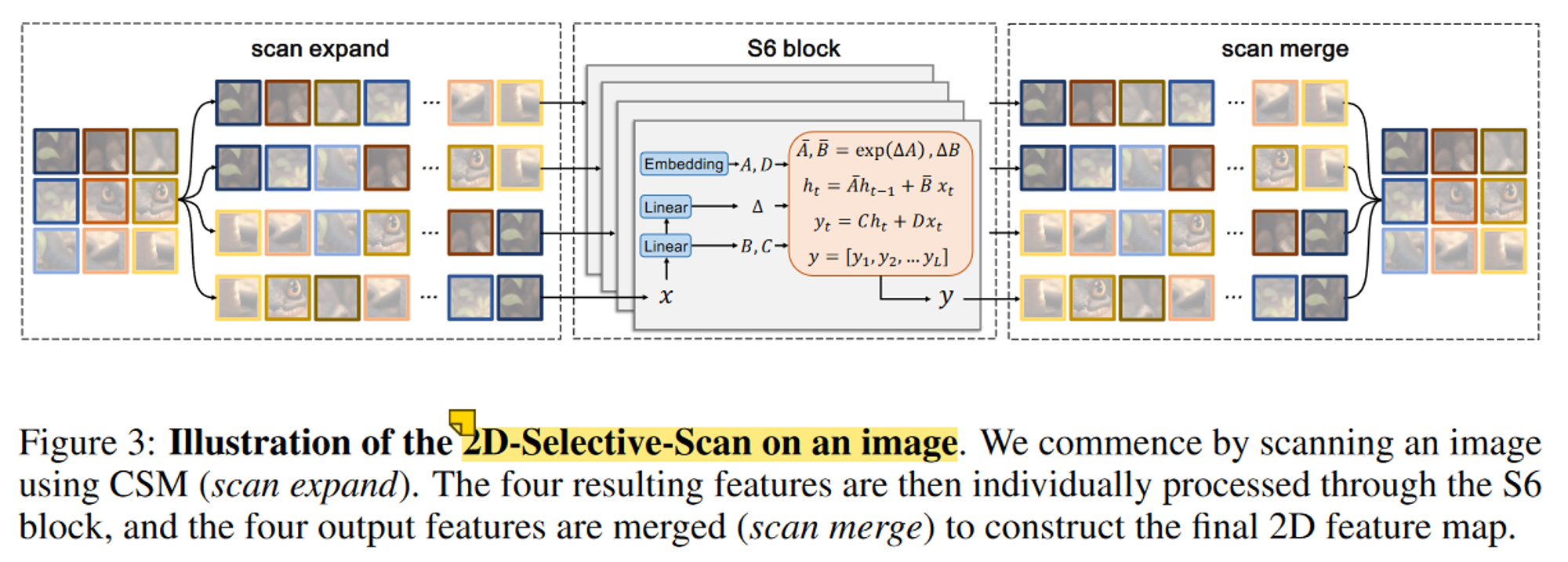
将 S6 与 CSM 集成,称为 S6 块,作为构建视觉状态空间(Visual State Space,VSS)块的核心元素,构成了 VMamba 的基本构建块。S6 块继承了选择性扫描机制的线性复杂性,同时保留了全局感受野。
VMamba
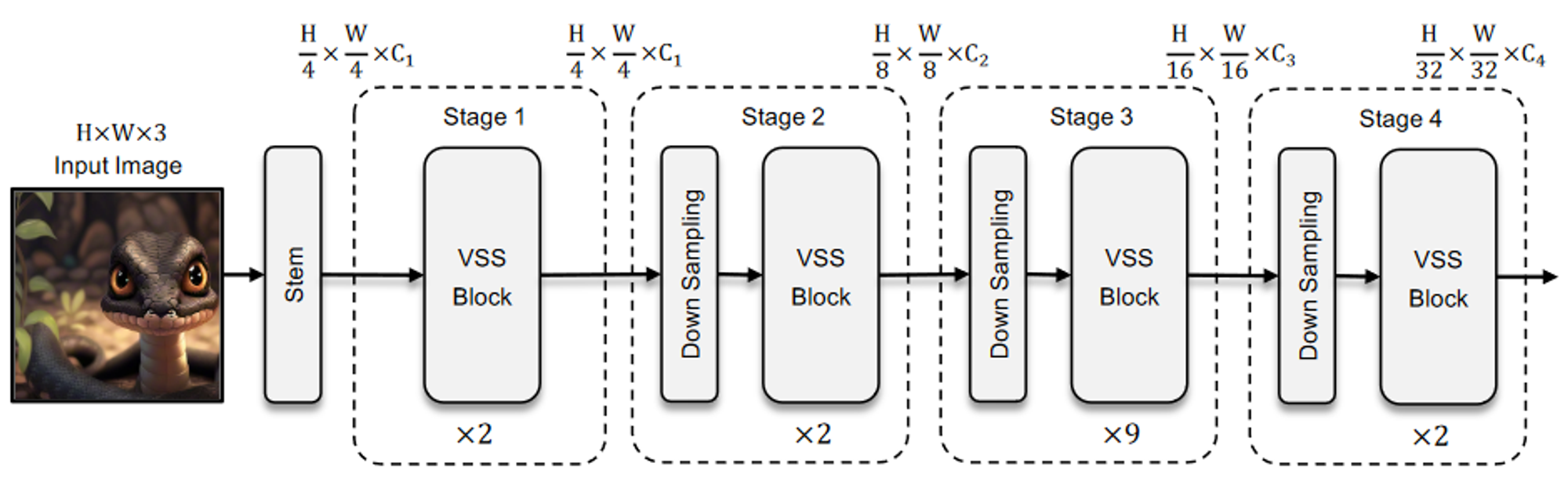
- 整体架构:VMamba-Tiny 的架构如下图所示。首先使用一个Stem节点将输入图像分割成多个patchs,类似于 ViTs,但没有将patchs进一步展平成 1-D 序列,这种修改保留了图像的 2D 结构。然后,堆叠多个 VSS 块,保持相同的维度,构成 “Stage 1”。之后通过patch合并操作对特征映射进行下采样,构建分层特征表示。随后再堆叠多个下采样和VSS块,创建“Stage 3” 和 “Stage 4”。这样就构成了一个类似CNN和ViT的基础模型,生成的架构可以在实际应用中作为对其它视觉模型的替代品。
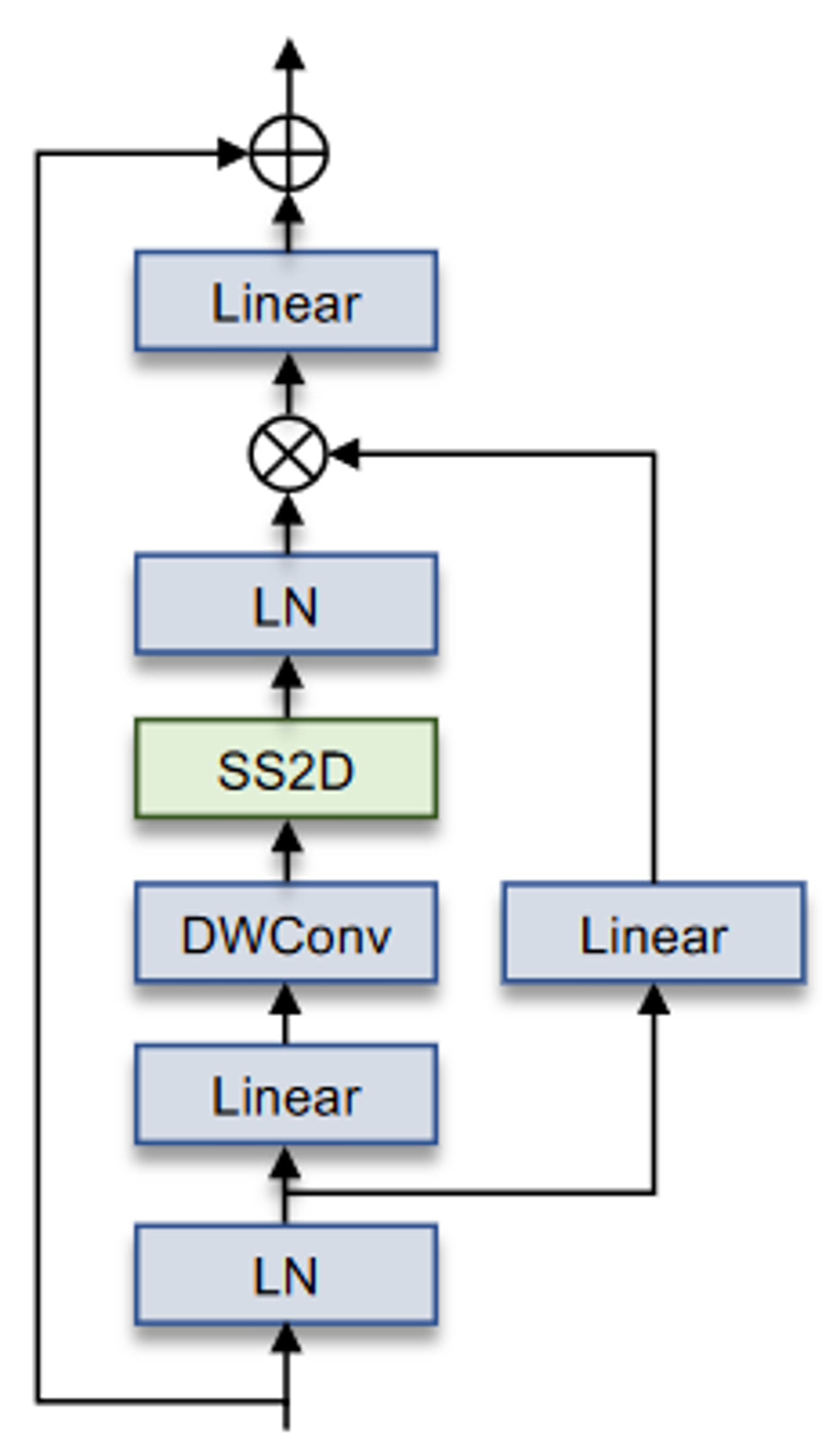
- VSS Block:输入经过初始线性嵌入层,输出分为两个信息流。一个流通过一个 3 × 3 的深度卷积层,然后通过 Silu 激活函数进入核心 SS2D 模块。SS2D 的输出通过一层标准化层,然后加到另一个信息流的输出上,该信息流经过 Silu 激活。由于 VMamba 的因果性质,不使用位置嵌入偏差。
实验
实验主要对比了VMamba、CNNs和ViTs,任务包括图像分类(ImageNet-1K)、目标检测(COCO)和语义分割(ADE20K)。
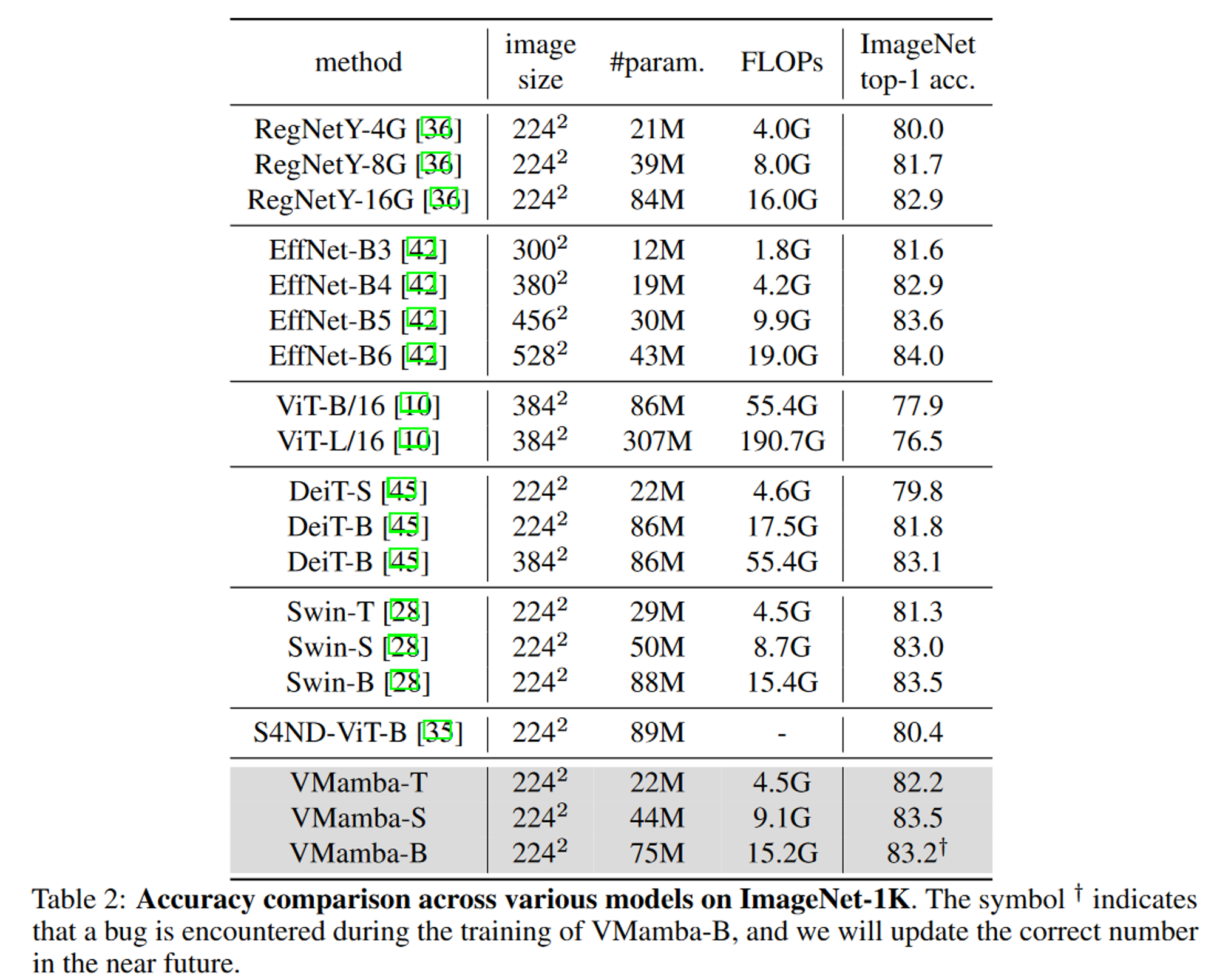
图像分类
采用类似Swin transformer v2的设定,VMamba-T/S/B从零开始训练300个epoch,使用的批大小为1024。训练过程包括AdamW优化器,betas设置为( 0.9、0.999),动量为0.9,余弦衰减学习率调度器,初始学习率为1 × 10-3,权重衰减为0.05。此外,还采用了标签平滑( 0.1 )和指数移动平均( EMA )等技术。
目标检测
训练框架是建立在mmdetection库上的,并且将Swin中的超参数与Mask-RCNN检测器结合。使用AdamW优化器,对预训练好的分类模型(在ImageNet-1K上)进行12和36个epoch的微调。VMamba-T/S/B的跌落路径率分别设置为0.2%/0.2%/0.2%。学习率初始化为1 × 10-4,在第9和第11 epoch时降低10 ×。实现了多尺度训练和随机翻转,批大小为16。
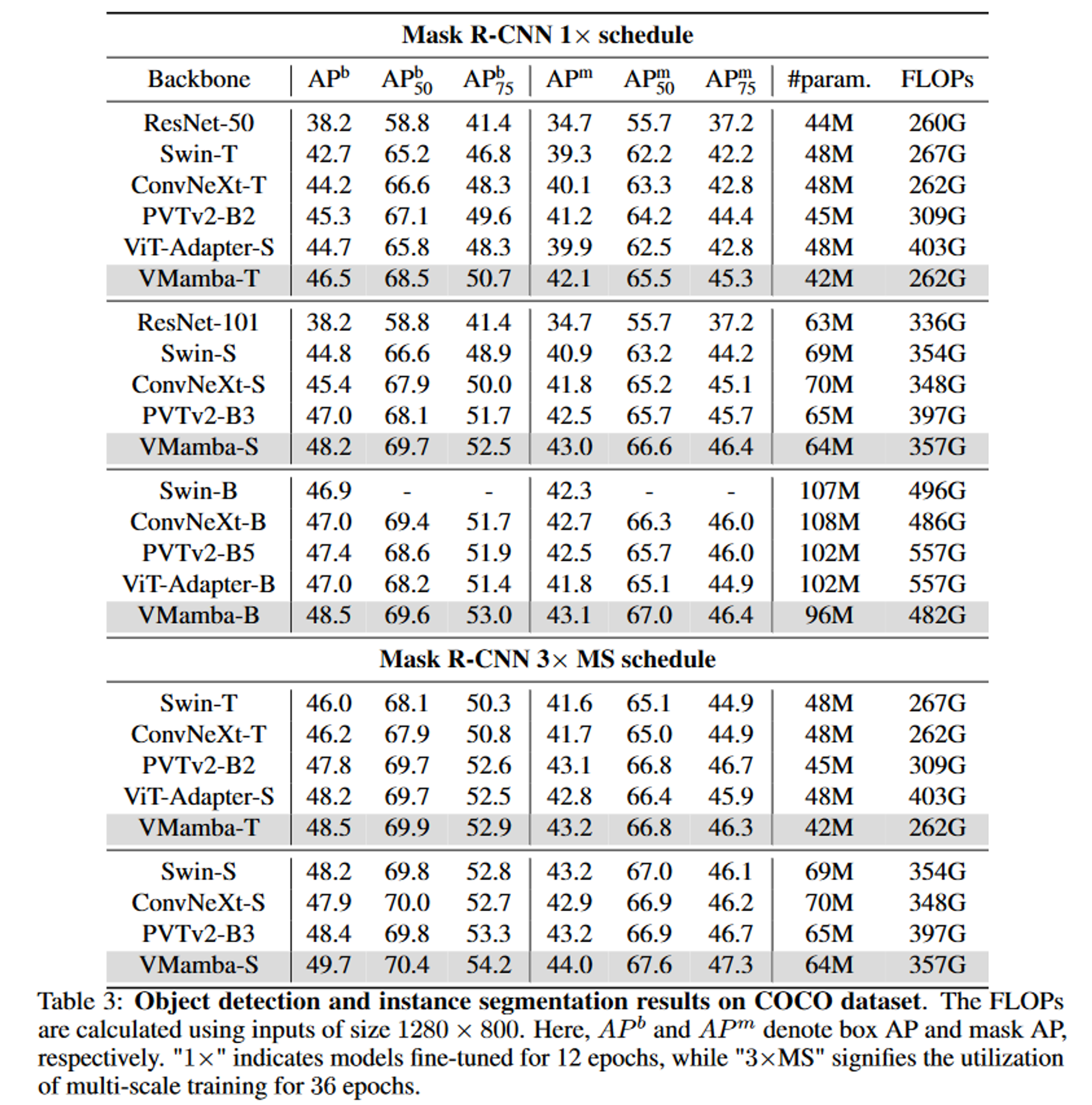
语义分割
继Swin之后,在预训练模型的基础上构造了一个UperHead。采用AdamW优化器,设置学习率为6×10-5。微调过程总共跨越160k次迭代,批大小为16。默认输入分辨率为512×512,此外还给出了使用640 × 640输入和多尺度( MS )测试的实验结果。
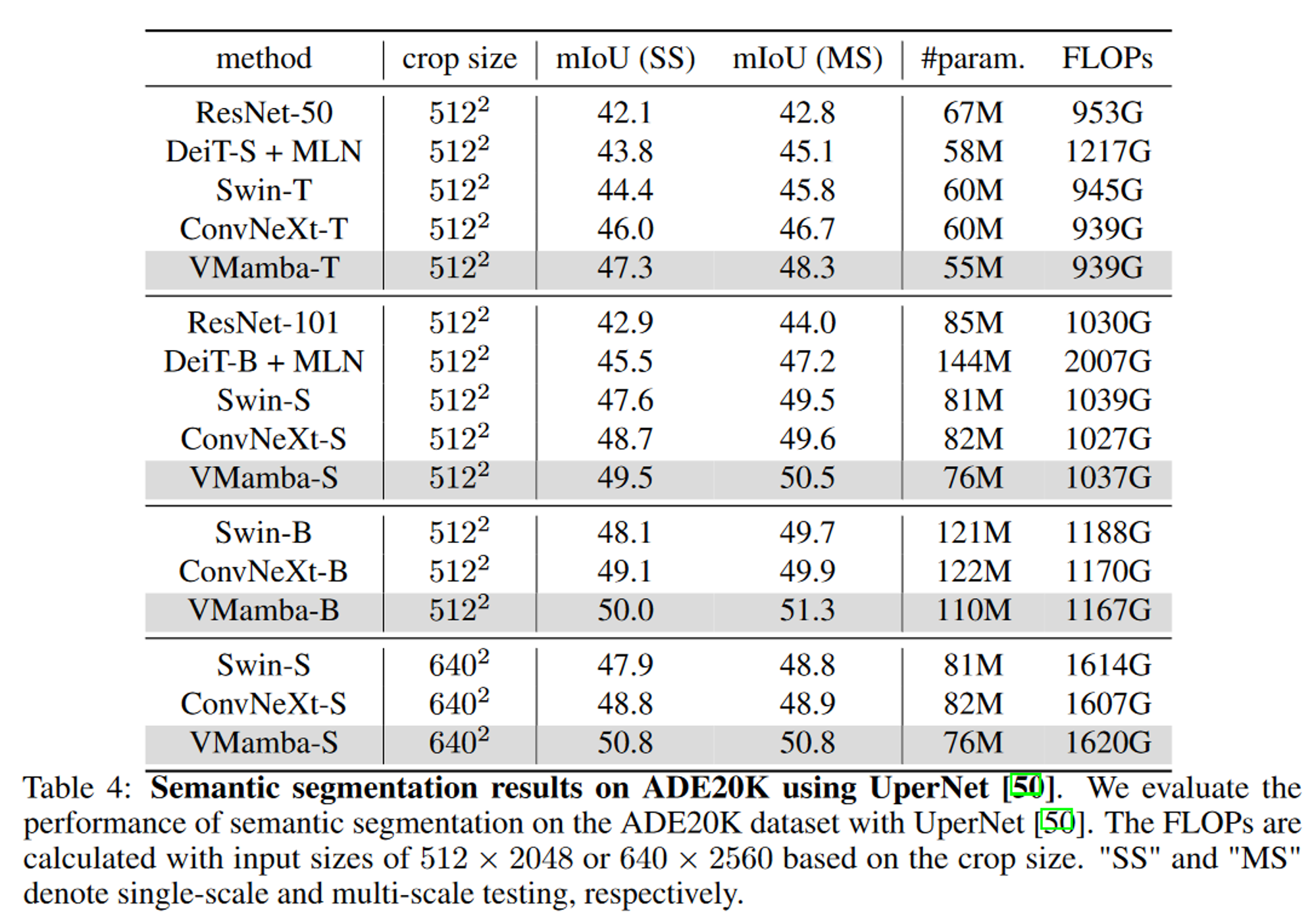
实验分析
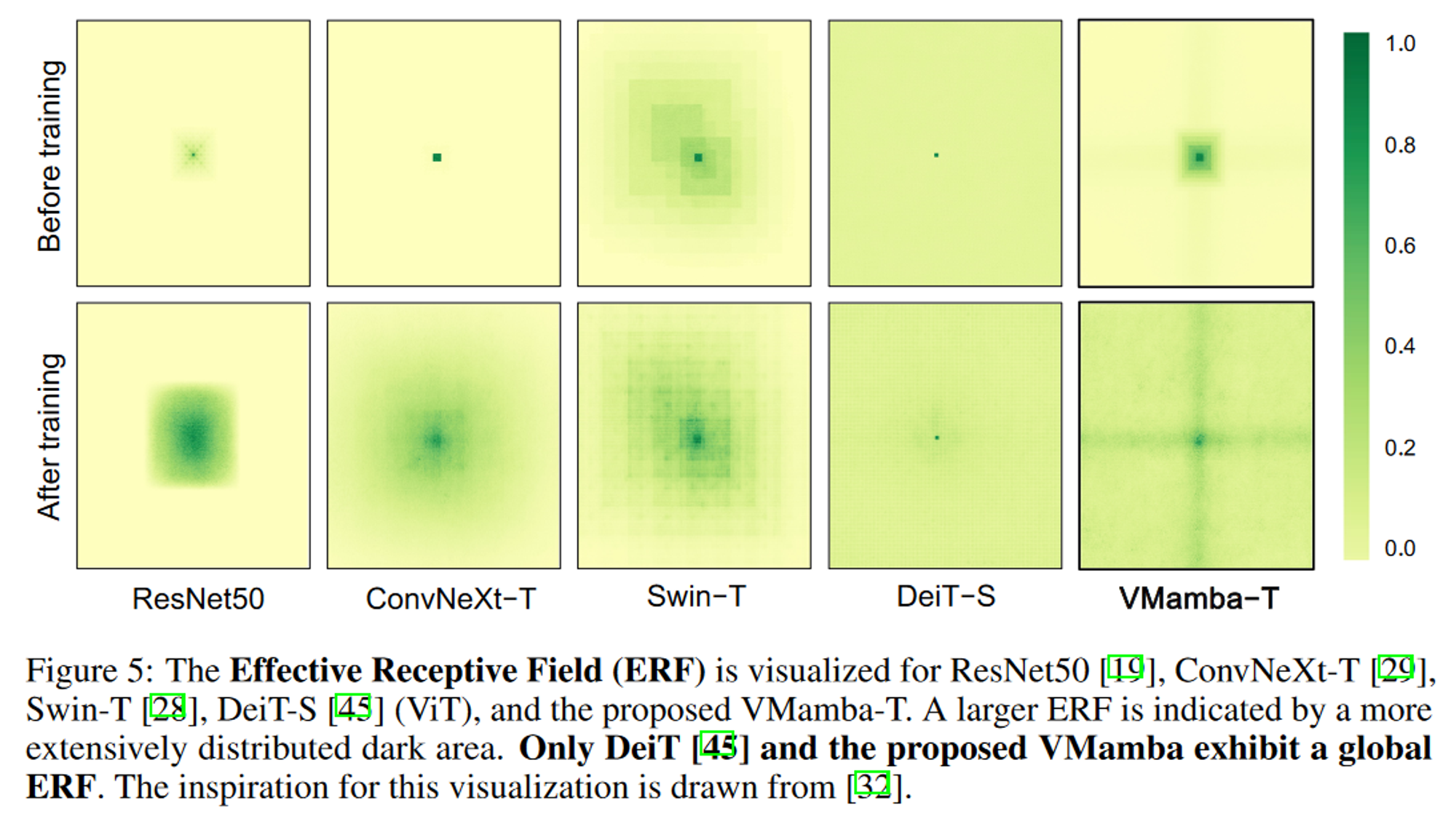
- 有效感受野
可视化1024×1024图像的中心像素感受野。结论如下:
- ResNet、ConvNeXt、Swin几个模型只有局部感受野,DeiT和VMamba具有全局感受野,而DeiT是复杂度是二次的;
- DeiT的注意力均匀的分布在所有像素上,VMamba的注意力虽然也分布在所有像素上,但是呈现出十字形,这主要归因于CSM模块;
- VMamba在训练前具有局部感受野,而训练后具有全局感受野,这意味着模型的全局感受能力是一个自适应的过程。
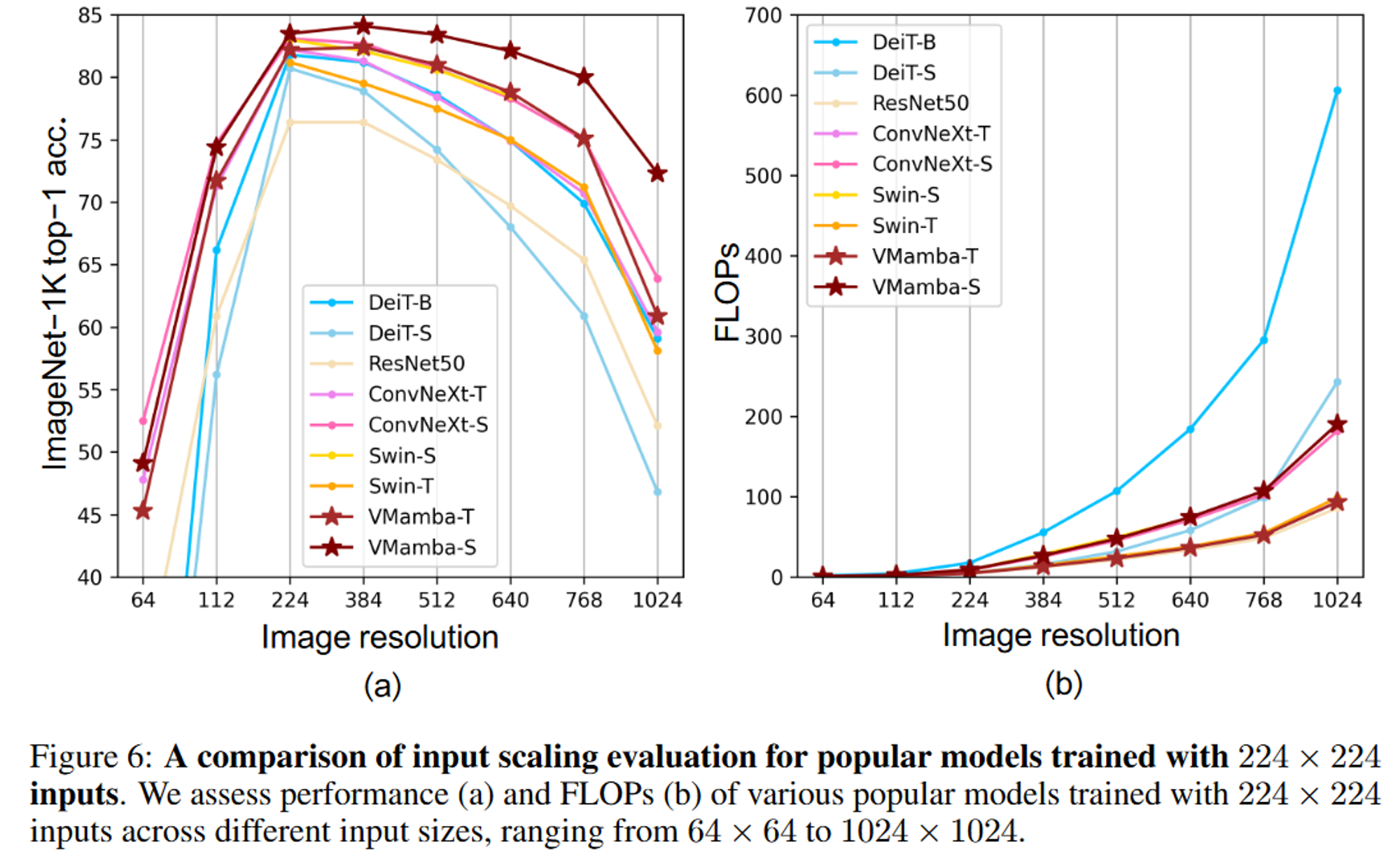
- 输入缩放
评估了多个模型在不同输入图片分辨率上的准确率和FLOPs,模型都是在224×224分辨率的图像上训练的。
结论
作者提出了一种新型的模型,称为“视觉状态空间模型”(VMamba),这个模型在处理图像时能够有效地保持线性复杂度,同时还具备全局感受野的优势。此外,作者还引入了一个名为“交叉扫描模块”(CSM)的技术,它能够将图像转换成有序的图像块序列,解决了方向敏感性的问题。经过大量实验,这个模型在各种视觉任务上都表现出色,特别是在处理高分辨率图像时,其性能超过了现有的基准。
速览笔记
Motivation
作者为什么做这件事?之前存在什么问题?
ViTs在计算视觉表征方面表现优异,但注意力机制需要图像大小的二次复杂度,这在处理高分辨率图像和复杂任务时导致计算成本过高。
Novelty
- 创建点在哪里?为什么要提出来这个?要解决什么问题?
为了克服这一限制,作者提出了一种新的模型架构,称为VMamba,该架构能够在保持全局感受野和动态权重的同时,将计算复杂度降低到线性。通过引入交叉扫描模块(CSM),VMamba有效地解决了因ViTs计算复杂度高而带来的性能限制,特别是在处理高分辨率图像时。
Methods
对照代码,整理模型整体结构,分析每个模块的作用以及对性能的提升贡献(重点,呼应实验),找到核心模块(提点最多),以及判断跟创新点是否匹配
VSSM(
(patch_embed): PatchEmbed2D(
(proj): Conv2d(3, 96, kernel_size=(4, 4), stride=(4, 4))
(norm): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
)
(pos_drop): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0): VSSLayer(
(blocks): ModuleList(
(0): VSSBlock(
(ln_1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=96, out_features=384, bias=False)
(conv2d): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
(act): SiLU()
(out_norm): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=192, out_features=96, bias=False)
)
(drop_path): timm.DropPath(0.0)
)
(1): VSSBlock(
(ln_1): LayerNorm((96,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=96, out_features=384, bias=False)
(conv2d): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=192)
(act): SiLU()
(out_norm): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=192, out_features=96, bias=False)
)
(drop_path): timm.DropPath(0.014285714365541935)
)
)
(downsample): PatchMerging2D(
(reduction): Linear(in_features=384, out_features=192, bias=False)
(norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
)
)
(1): VSSLayer(
(blocks): ModuleList(
(0): VSSBlock(
(ln_1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=192, out_features=768, bias=False)
(conv2d): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384)
(act): SiLU()
(out_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=384, out_features=192, bias=False)
)
(drop_path): timm.DropPath(0.02857142873108387)
)
(1): VSSBlock(
(ln_1): LayerNorm((192,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=192, out_features=768, bias=False)
(conv2d): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=384)
(act): SiLU()
(out_norm): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=384, out_features=192, bias=False)
)
(drop_path): timm.DropPath(0.04285714402794838)
)
)
(downsample): PatchMerging2D(
(reduction): Linear(in_features=768, out_features=384, bias=False)
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
(2): VSSLayer(
(blocks): ModuleList(
(0): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.05714285746216774)
)
(1): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.0714285746216774)
)
(2): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.08571428805589676)
)
(3): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.10000000149011612)
)
(4): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.11428571492433548)
)
(5): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.12857143580913544)
)
(6): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.1428571492433548)
)
(7): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.15714286267757416)
)
(8): VSSBlock(
(ln_1): LayerNorm((384,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=384, out_features=1536, bias=False)
(conv2d): Conv2d(768, 768, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=768)
(act): SiLU()
(out_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=768, out_features=384, bias=False)
)
(drop_path): timm.DropPath(0.17142857611179352)
)
)
(downsample): PatchMerging2D(
(reduction): Linear(in_features=1536, out_features=768, bias=False)
(norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
)
)
(3): VSSLayer(
(blocks): ModuleList(
(0): VSSBlock(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=768, out_features=3072, bias=False)
(conv2d): Conv2d(1536, 1536, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1536)
(act): SiLU()
(out_norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=1536, out_features=768, bias=False)
)
(drop_path): timm.DropPath(0.18571428954601288)
)
(1): VSSBlock(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(self_attention): SS2D(
(in_proj): Linear(in_features=768, out_features=3072, bias=False)
(conv2d): Conv2d(1536, 1536, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1536)
(act): SiLU()
(out_norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=True)
(out_proj): Linear(in_features=1536, out_features=768, bias=False)
)
(drop_path): timm.DropPath(0.20000000298023224)
)
)
)
)
(norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(avgpool): AdaptiveAvgPool1d(output_size=1)
(head): Linear(in_features=768, out_features=1000, bias=True)
)
Experiments
训练集和测试集
用的哪个数据集,规模多少,评价指标是什么
这篇论文主要使用了三个数据集:ImageNet-1K(用于图像分类)、COCO(用于目标检测)和ADE20K(用于语义分割)。ImageNet-1K包含约128万张图像,COCO包含超过20万张图像,ADE20K包含约2.5万张图像。评价指标包括图像分类的准确率(对于ImageNet-1K)、目标检测的平均精度(对于COCO)和像素级别的准确率(对于ADE20K)。
性能如何,好不好复现,是否有Code/Blog/知乎讨论
开源了代码和训练脚本,可以尝试复现。
有没有哪些实验没有做
跨领域迁移能力、消融实验
Thinking
能否迁移应用?(业务应用方向、模型改进、数据生产组织等方面)
能够对模型进行改进,降低算力消耗,提升推理速度。
参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux_Centos7安装snmp服务
- 大量的视频如何批量随机分割的方法:批量剪辑不求人
- 东方文化:野蛮的象征
- 2023年第四届 “赣网杯” 网络安全大赛 gwb-web3 Write UP【PHP 临时函数名特性 + 绕过trim函数】
- COST231-Hata模型信道仿真MATLAB编程源码程序
- k8s的集群调度
- 极智开发 | 解读英伟达软件生态 深度神经网络库cuDNN
- SLAM中使用闭环检测进行重定位 以及C++代码实现
- thinkphp6入门(13)-- 一对多关联模型
- 新能源时代-电动汽车充电桩设备建设及运维平台搭建