MySQL 分表真的能提高查询效率?
发布时间:2023年12月22日
背景
首先我们以InnoDB引擎,B+Tree 3层为例。我们需要先了解几个知识点:页的概念、InnoDB数据的读取方式、什么是树搜索?、一次查询花费的I/O次数,跨页查询。
页的概念
索引树的页(page)是指存储索引数据的最小单位。MySQL将索引数据分成固定大小的页来存储,一般情况下,默认的页大小是16KB。
InnoDB数据的读取方式
InnoDB 的数据是按数据页为单位来读写的。也就是说,当需要读一条或者多条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。
什么是树搜索?
从根节点到叶子节点的搜索过程,被称为"树搜索"。
一次树搜索需要花费的IO次数
从页1->页2>页3,每页进行了一次I/O操作,所以一共进行了3次I/O。如果需要回表,那就是6次I/O。
第一次I/O?
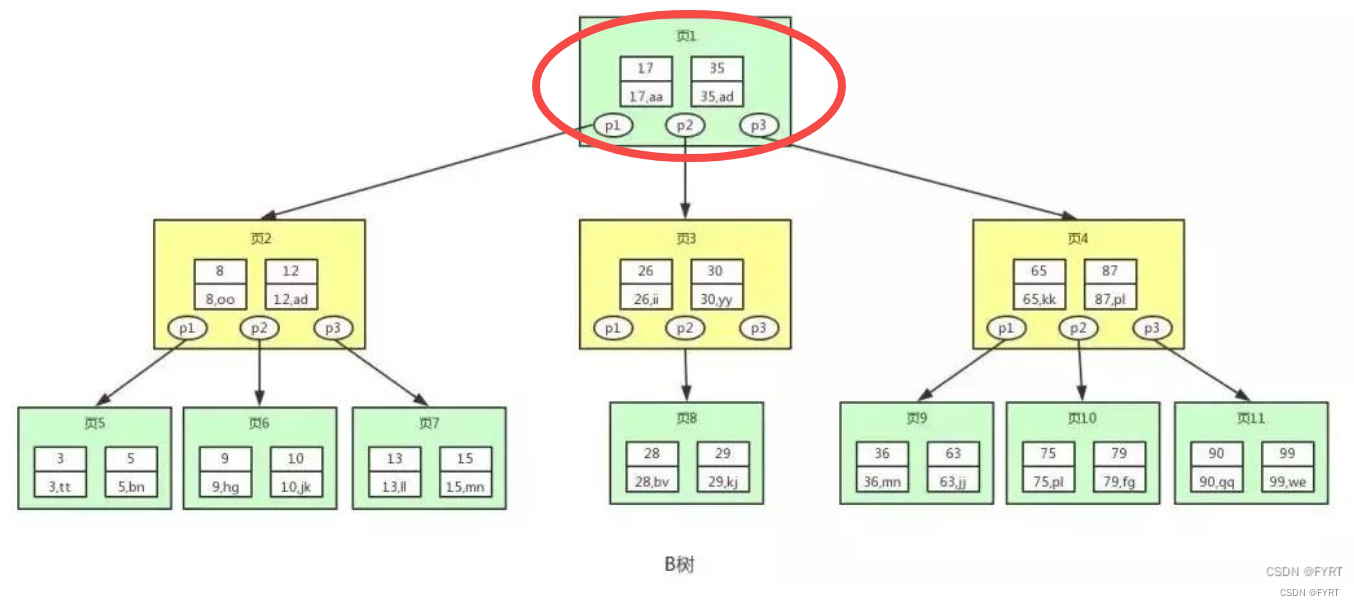
第二次I/O

第三次I/O
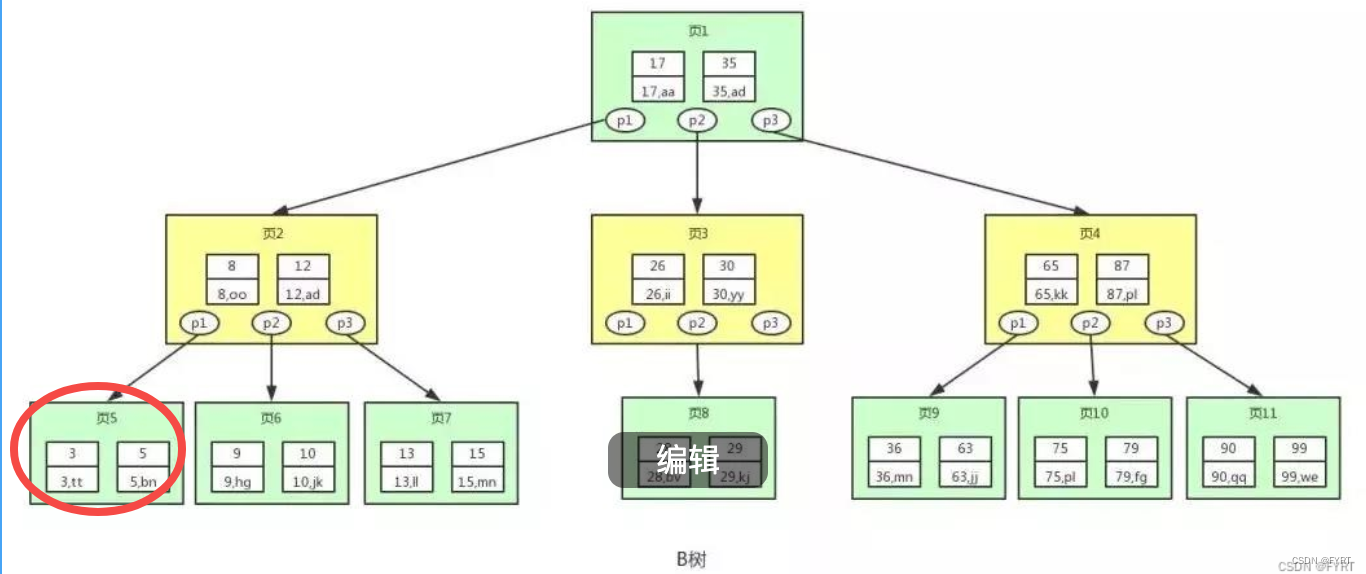
跨页查询
参考上图,跨页查询指在进行数据查询时,需要跨越多个数据页才能获取完整的查询结果。当MySQL中的表数据量很大时,数据可能会被存储在多个数据页中。每个数据页通常包含一定数量的数据行。当执行一个查询时,如果查询的结果需要跨越多个数据页才能完全获取,就称为跨页查询。
分表可以提高查询效率?
可以,接下来从垂直分表和水平分表两种方式展开说明:
垂直拆分
- 当进行垂直拆分后,每个小表只包含部分列数据,数据量减少,可以更容易地存放在一张或少数几张数据页中。这样,在进行跨页查询时,由于需要跨页查询的数据量减少,查询操作可能只需要访问更少的数据页,减少了磁盘I/O的次数,提升了查询性能。
例子:
- 假设我们有一张名为"users"的表,其中包含12万条数据,每张数据页储4万条数据。现在要查询这12万条数据。
- 拆分前,12万数据分布在3张数据页中,查询需要5次 I/O 才能获取全部的12万条数据。
- 拆分后,将每张数据页的容量增加到6万条数据,那么查询结果仍然是12万条数据,此时仅需4次 I/O 操作就可以获取结果。这样就减少了1次 I/O 操作,大大提升了查询效率。
水平拆分
- 在水平拆分后进行并行查询的情况下,每个节点可能需要进行独立的磁盘 I/O 操作,但整体查询速度仍然会比单表的 I/O 操作次数更快。虽然每个节点需要进行独立的 I/O 操作,但并行查询允许多个节点同时进行这些操作,而不是一个节点一个节点地进行。这样可以提高查询的并发性和整体查询速度。
例子:
- 假设我们有一张名为"users"的表,其中包含12万条数据,每张数据页储4万条数据。现在要查询这12万条数据。
- 拆分前,12万数据分布在3张数据页中,查询需要5次 I/O 才能获取全部的12万条数据。
- 拆分后,我们将数据分散到了3张表中,每张表存储4万条数据。当我们需要查询这12万条数据时,每次查询都需要同时对3张表进行操作。尽管每张表都需要进行3次I/O(输入/输出),但由于并行查询的优势,我们仍然只需要进行3次I/O。这样,我们可以通过并行处理在多个节点上同时执行查询操作,从而提高查询的效率。
树图
文章来源:https://blog.csdn.net/qq_36760953/article/details/135135246
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mysql单表查询
- Mac Install Parallels Desktop 19.1.0
- 基于springboot+vue的教师工作量管理系统(前后端分离)
- DAY 16 | 654, 617, 700, 98
- vue中使用mpegts.js播放flv的直播视频流
- 【python】startswith()函数的用法
- 第七章 函数(四)
- 【软件测试常见Bug清单】
- ASUS华硕ROG幻14笔记本2023款G14 GA402XV原装出厂Win11系统
- P2615 [NOIP2015 提高组] 神奇的幻方————C++