经典文献阅读之--SST-Calib(激光雷达与相机的同步时空参数标定法)
0. 简介
借助多种输入模态的信息,基于传感器融合的算法通常优于单模态。具有互补语义和深度信息的相机和激光雷达是复杂驾驶环境中的典型传感器配置。然而,对于大多数相机和激光雷达融合的算法,传感器的标定将极大地影响性能。具体来说,检测算法通常需要多个传感器之间的精确几何关系作为输入,并且默认传感器的时间戳是同步的。《SST-Calib: Simultaneous Spatial-Temporal Parameter Calibration between LIDAR and Camera》一文,提出了一种基于分割的框架来联合估计相机激光雷达套件校准中的几何参数和时间参数。
1. 主要贡献
这项工作提出了一个自动驾驶平台上激光雷达和相机之间的联合时空校准框架。所提出的框架的输入是相机和激光雷达帧的序列。这里,每个传感器模态都通过任意的语义分割网络进行处理,可以根据可用的训练数据进行选择。其次,将分割的LIDAR点云投影到语义图像上,计算新设计的双向对准损失,用于几何参数回归。不仅限于点对像素的损失,我们还对语义像素进行了点对点损失的下采样。估计两者之间的时间延迟,我们从两个连续的图像中估计视觉里程计,并预测用于匹配的偏移点云。本文贡献如下:
1、为激光雷达相机传感器套件提出了一种联合时空标定算法;
2、设计双向损失是为了在几何参数回归中获得更稳健的性能;
3、将时间参数与视觉里程计相结合,以估计传感器之间的时间延迟。
2. 主要方法
所提出的校准方法的工作流程如图1所示。校准过程包括用于空间初始猜测的静态空间参数校准模块和用于双参数估计的联合时空参数校准模块。
所提算法的输入是一个点云扫描 P k ∈ R 3 × N p P_k ∈ \mathbb{R}^{3×N_p} Pk?∈R3×Np?,以及两个连续的RGB图像 { I k + δ , I k + δ ? 1 } ∈ Z N h × N w × 3 \{I_{k+δ}, I_{k+δ?1}\} ∈ \mathbb{Z}^{N_h×N_w×3} {Ik+δ?,Ik+δ?1?}∈ZNh?×Nw?×3。其中 N p N_p Np?是扫描中的点数, N h N_h Nh?和 N w N_w Nw?是图像的尺寸。算法的目标是估计几何关系的6自由度 { R , t } \{R, t\} {R,t}(其中 R ∈ R 3 × 3 , t ∈ R 3 R ∈\mathbb{R}^{3×3},t ∈ \mathbb{R}^3 R∈R3×3,t∈R3)和 P k P_k Pk?与 I k + δ I_{k+δ} Ik+δ?之间的时间延迟 δ ∈ R δ ∈\mathbb{R} δ∈R。
为了实现这一目标,我们首先通过任意语义分割算法处理 P k P_k Pk? 和 I k + δ I_{k+δ} Ik+δ?,以获得语义掩码 P m , k P_{m,k} Pm,k?和 I m , k + δ I_{m,k+δ} Im,k+δ?。然后,利用粗略测量或采样得到的初始外参猜测 { R i n i t , t i n i t } \{R_{init}, t_{init}\} {Rinit?,tinit?} 和已知的内参 K ∈ R 3 × 3 K ∈ \mathbb{R}^{3×3} K∈R3×3,将激光雷达点云投影到相机图像平面上。通过找到点到像素和像素到点的最近邻,计算它们之间的欧氏距离,这是优化算法的损失函数。
第一次优化迭代(静态空间参数校准模块)将在车辆速度几乎为0的帧上进行。静态空间参数校准给出了旋转和平移的初始估计 { R ^ s t a t i c , t ^ s t a t i c } \{\hat{R}^{static},\hat{t}^{static}\} {R^static,t^static}。这个估计将被用作联合时空参数校准的初始猜测和正则化参考。
其次,对于动态场景,我们从视觉里程计中估计 I k + δ I_{k+δ} Ik+δ?和 I k + δ ? 1 I_{k+δ?1} Ik+δ?1?之间的时间信息,该里程计将预测两个相机帧之间的速度 v ^ k ∈ R 3 \hat{v}_k ∈ \mathbb{R}^3 v^k?∈R3。在这里, P k P_k Pk?和 I k + δ I_{k+δ} Ik+δ?之间的平移偏移可以表示为 t δ , k = v ^ k ? δ t_{δ,k} = \hat{v}_k · δ tδ,k?=v^k??δ。我们将 v ^ k \hat{v}_k v^k?作为优化的一部分,并估计 δ ^ \hat{δ} δ^和 { R ^ , t ^ } \{\hat{R}, \hat{t}\} {R^,t^}。
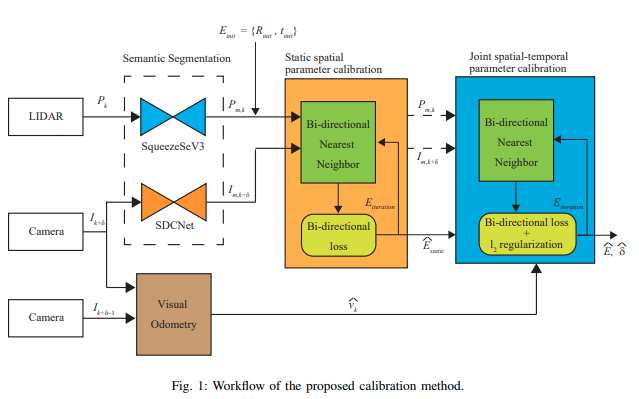
图1:所提出的校准方法的工作流程
2.1 语义分割
通过现成的语义分割模块,所提出的方法可以适用于具有语义标签的任何数据集。在本文中,我们分别使用SqueezeSegV3[26]和SDC-net[27]进行点云和图像的语义分割。考虑到城市环境中车辆的频繁出现,在这项工作中,我们只使用车辆类别进行语义分割。将这些语义分割模块应用于输入,我们得到语义掩码 P m , k P_{m,k} Pm,k?, I m , k + δ I_{m,k+δ} Im,k+δ?。
2.2 点云投影
为了计算语义损失,我们首先将点 p i , m , k ∈ P m , k ( p i , m , k ∈ R 3 ) p_{i,m,k} ∈ P_{m,k}(p_{i,m,k} ∈ \mathbb{R}^3) pi,m,k?∈Pm,k?(pi,m,k?∈R3)的语义掩码投影到二维图像平面上。根据经典的相机模型[28],我们可以通过以下方式实现投影

在这里, p u i , m , k pu_{i,m,k} pui,m,k?和 p v i , m , k pv_{i,m,k} pvi,m,k?是投影点 p ~ i , m , k ∈ R 2 \tilde{p}_{i,m,k}∈\mathbb{R}^2 p~?i,m,k?∈R2的图像坐标。
2.3 双向损失(重点内容)
让 p ~ 1 , m , k … p ~ n p , m , k \tilde{p}_{1,m,k}…\tilde{p}_{n_p,m,k} p~?1,m,k?…p~?np?,m,k?成为在相机视野内的一组投影的LIDAR点。现在对于投影点 p ~ i , m , k \tilde{p}_{i,m,k} p~?i,m,k?,让 q j , m , k + δ ∈ I m , k + δ q_{j,m,k+δ}∈I_{m,k+δ} qj,m,k+δ?∈Im,k+δ? 成为相同类别的最近邻像素。然后,可以如下计算第 k k k 帧上的单向点到像素(点到图像)语义对齐损失:
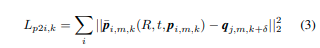
在这里,损失是根据每个投影点计算的。图2a展示了点到像素损失计算的过程。正如[10]所示,通过最小化这个损失函数,我们可以使得投影点云与具有相同语义标签的像素很好地重叠。因此,最小化这个损失函数可以使我们得到正确的 E ^ s t a t i c = { R ^ s t a t i c , t ^ s t a t i c } \hat{E}_{static} = \{\hat{R}_ {static}, \hat{t}_{static}\} E^static?={R^static?,t^static?}估计。然而,当外参矩阵的初始猜测与真值显著不同时,最近邻匹配并不一定能给出大多数配对的适当匹配结果,并且一些重要像素的信息将被丢弃。因此,最小化单向损失会陷入不适当的局部最小值。
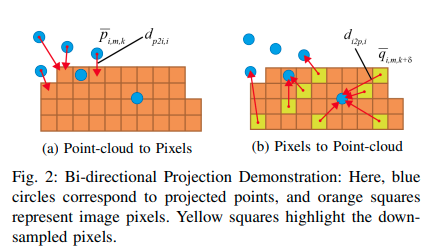
图2:双向投影演示:这里,蓝色圆圈对应投影点,橙色方块代表图像像素。黄色方块突出显示了下采样的像素。
为了避免信息的丢失,我们提出了一个双向损失,也利用了像素到点(图像到点)最近邻匹配(图2b)。考虑到一个图像中有太多像素需要实时匹配,我们对像素进行了下采样以进行像素到点匹配。设 { q ~ 1 , m , k + δ … q ~ n i , m , k + δ } ? I m , k + δ \{\tilde{q}_{1,m,k+δ}…\tilde{q}_{n_i,m,k+δ}\} ? I_{m,k+δ} {q~?1,m,k+δ?…q~?ni?,m,k+δ?}?Im,k+δ?为下采样像素的集合。现在对于像素 q ~ i , m , k + δ , p ~ j , m , k ∈ P m , k \tilde{q}_{i,m,k+δ},\tilde{p}_{j,m,k} ∈ P_{m,k} q~?i,m,k+δ?,p~?j,m,k?∈Pm,k?是最近邻的投影点。那么,第 k k k帧上的像素到点语义对齐损失可以计算如下:
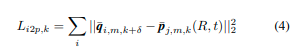
在这里,损失是针对每个采样像素计算的。然后,第 l l l次迭代的双向语义对齐损失可以表示如下,
…详情请参照古月居
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【好书推荐-第二期】《实战AI大模型 》:带你走进大模型GPTs、AIGC的世界(李开复、周鸿祎、颜水成倾力推荐)
- STM32 基础知识(探索者开发板)--115讲 OLED
- 哈希-力扣350. 两个数组的交集Ⅱ
- MySQL NULL值处理
- Windows7安装MySQL
- 动画中使用的3d模型贴图技巧--模大狮模型网
- JavaSE核心基础-流程语句-笔记
- 2023启示录丨自动驾驶这一年
- openssl3.2 - 官方demo学习 - cipher - ariacbc.c
- SqlServer 完全卸载