GMP模型学习笔记:概念、流程概述、设计机制及部分场景
前言
Go是并发而生的语言,其中则通过GMP模型来进行协程的分配与调度。本篇将记录自己学习GMP模型的笔记。
进程、线程、协程分配流程概述
计算机发展之初,是只有进程的。那时候是单进程时代,多个进程顺序执行,计算机也没有并发能力。
后来,多个进程/线程之间可以通过时间片轮转的方法进行调度。但是这样会导致大量的时间,耗费在时间片的切换上。

因此人们就又将线程分为了内核态和用户态,用户态线程就是协程。其二者可以通过1:1,N:1,N:M三种关系绑定。
关于用户态、内核态,先前的一篇学习笔记中曾记录过
https://blog.csdn.net/Ws_Te47/article/details/134790807
GMP模型属于M:N 多对多的模型,所谓GMP模型其实也更多就是这样一个协程调度器,用于将协程分配到线程之上。
题外话——在协程分配到线程之前,可能还会涉及到通过协程池进行协程复用,即任务分配给协程这一步。比如之前曾学习过的ants库就是这样一个协程池。(当时的习笔记)
GMP的前身——GM模型
在Go 1.1版本之前,采取的是GM模型而不上GMP模型。即直接将Goroutine分配给线程。
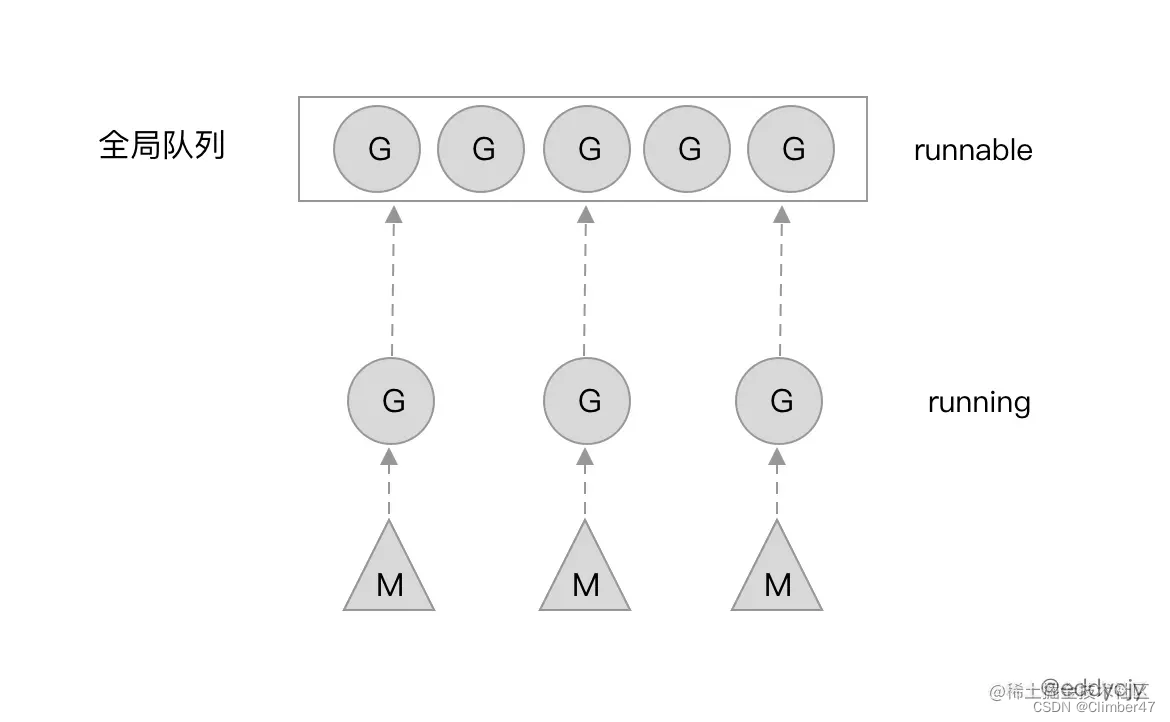
但是他存在以下问题:
1、创建、销毁、调度G都需要每个M获取锁,这就形成了激烈的锁竞争
2、M转移G会造成延迟和额外的系统负载。比如当G中包含创建新协程的时候,M创建了G’,为了继续执行G,需要把G’交给M’执行,也造成了很差的局部性,因为G’和G是相关的,最好放在M上执行,而不是其他M’
3、系统调用(CPU在M之间的切换)导致频繁的线程阻塞和取消阻塞操作增加了系统开销
因此退出了新的调度器,即GMP模型。
GMP模型概述
概念
GMP模型,G即Goroutine;M即machine 内核级线程;即processor处理器 其中包含了goroutine运行所需要的资源。
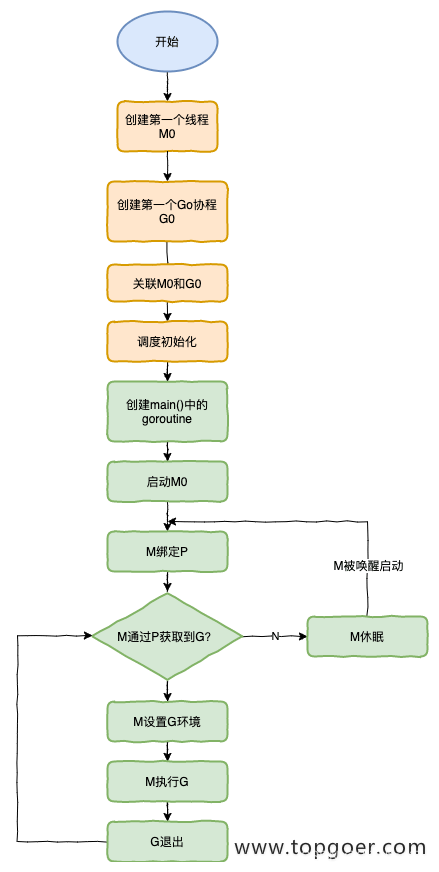
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0 是每次启动一个 M 都会第一个创建的 gourtine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
流程
其基本流程如下:
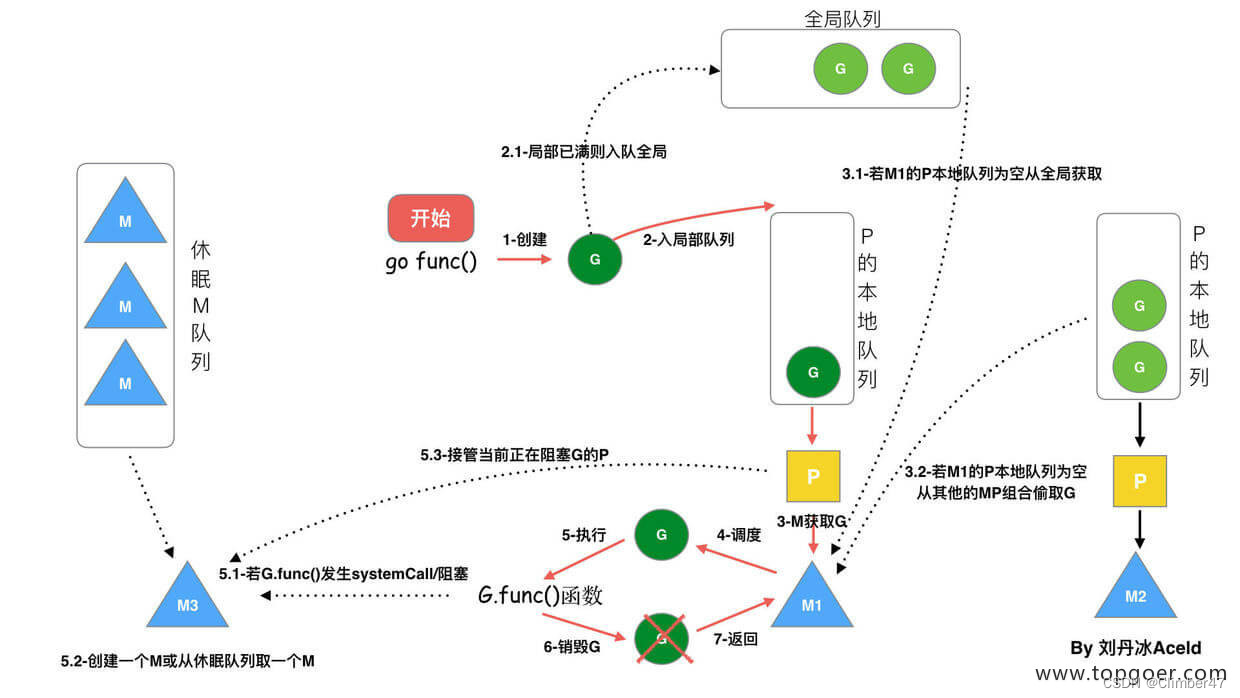
新建一个Goroutine,分配给P的队列中去,随后M从P种获取Goroutine 并运行。
在分配时,会优先分配给P的本地队列。但如果本地队列已满,则会分配到全局队列中去。
M与P是绑定关系,获取运行时,会从P中弹出一个Goroutine给M。若本地P队列无法获取到,则会去全局队列获取。若全局队列也为空,则去其他线程中偷取G(即work stealing机制)
若M在执行G时发生阻塞,则会将这个M从P中剔除,再寻找空闲M或新建一个M绑定到这个P上。(即hand off机制)
当一个M调用结束后,这个G会寻找一个空闲的P执行,若找不到,则M变为休眠状态,G加入全局队列。
GMP的几个机制
复用线程:即work stealing和hand off机制。
并行控制:即通过GOMAXPROCS设置最大P数量。
抢占:每一个goroutine最多占用CPU 10ms就被抢占。
全局G队列:相较于GM模型,其作用已被弱化,但还是有的。
GMP的部分场景
更多的见原文
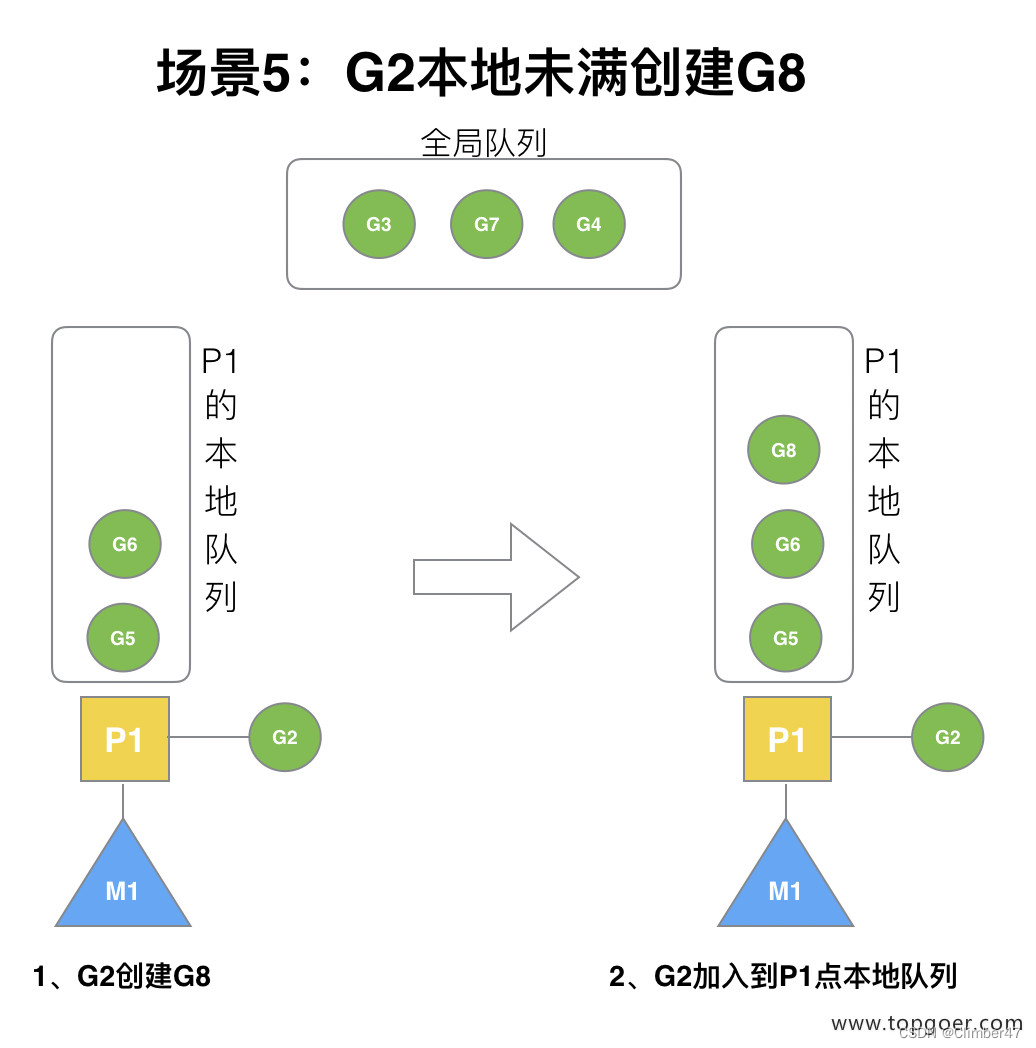
协程中创建协程时
会放到当前使用M对应P的本地队列。
这个机制也就是解决了前面提到的GM模型的问题“局部性较差”。
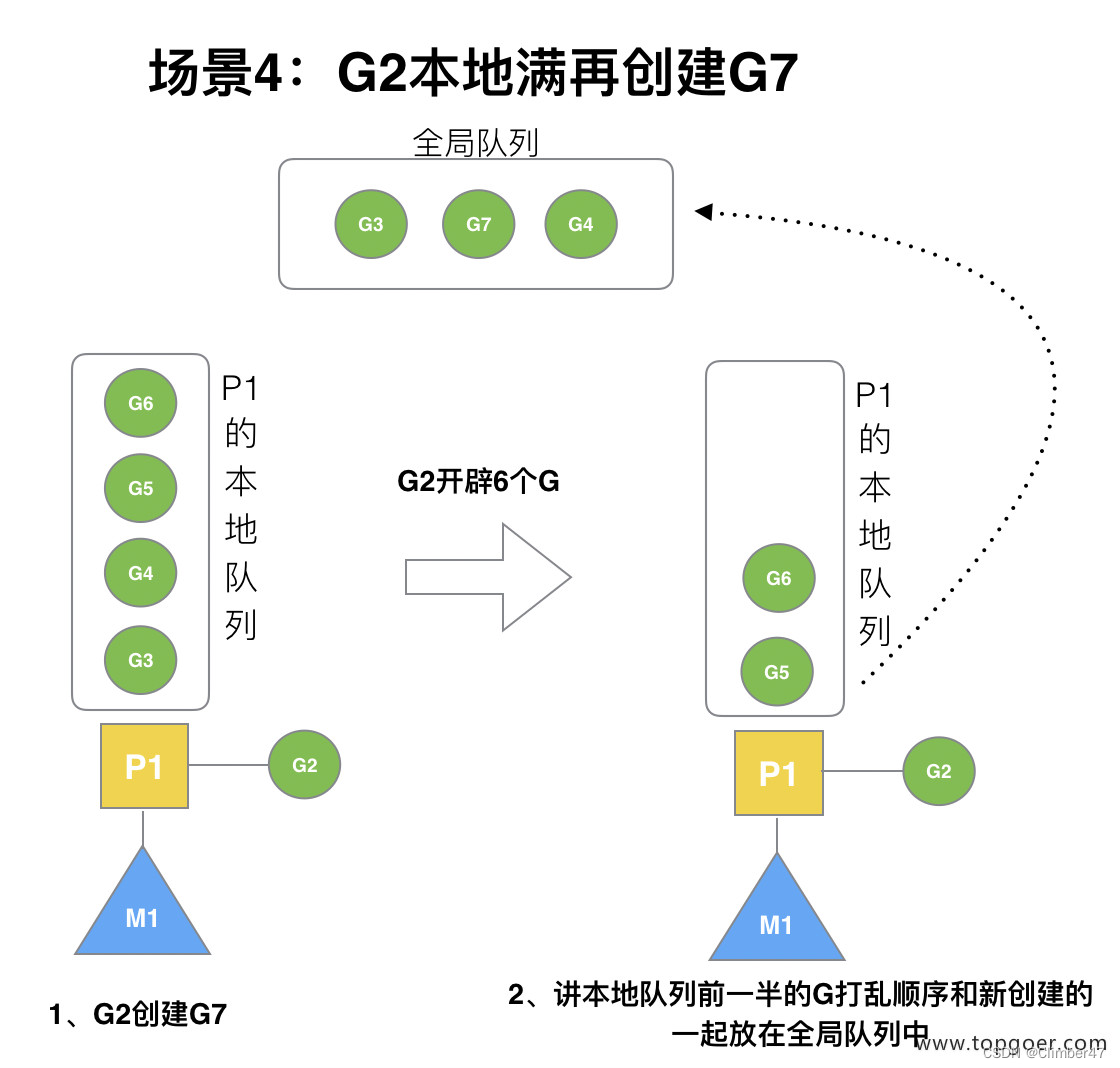
P本地队列已满的情况再创建
会移动到全局队列,具体移动的是 新创建的那个 和 本地队列的前一半(防止饿死)。
参考文献
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!