MySQL基础篇 | 聚合(分组)函数 、分组查询
?作者简介:大家好我是@每天都要敲代码,希望一起努力,一起进步!
📃个人主页:@每天都要敲代码的个人主页
🔥系列专栏:MySQL专栏
目录
一:聚合(分组)函数?
(1)聚合函数又叫做多行处理函数;
? ???????多行处理函数的特点:输入多行,最终输出的结果是一行;
(2)所有的分组函数都是对“某一组”数据进行操作的!
(3)5个聚合函数自动忽略空NULL,不需要在手动添加 is not null 条件!
注:其中AVG/SUM只适用于数值类型的字段,不适用于字符串和日期类型!

1. count 计数
(1)取得所有的员工数
注:count(*)和某个字段无关,统计的是总记录数!?
select count(*) from emp; 
那么count(具体的数字)是什么意思呢?
SELECT COUNT(1) ,COUNT(2)
FROM emp;表示那具体的数字1或者2来代表具体的一行数据,有多少个1或者2就有多少数据

?
(2)取得津贴不为null员工数
注:采用count(字段名称),统计的是当前字段不为NULL的个数
select count(comm) from emp; 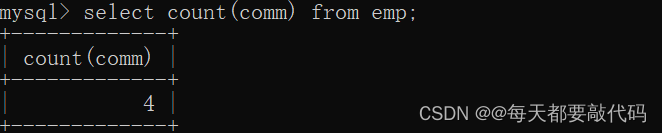
(3)count(*)和count(某个具体的字段),有什么区别?
count(*):不是统计某个字段中数据的个数,而是统计总记录条数。(和某个字段无关)
count(comm):表示统计comm字段中不为NULL的数据总数量。
小总结:
(1)如果计算表中有多少条记录,如何实现?
方式1:COUNT(*)
方式2:COUNT(1)
方式3:COUNT(具体字段) : 不一定对(如果该字段包含null就不对)!(2)如果需要统计表中的记录数,使用COUNT(*)、COUNT(1)、COUNT(具体字段) 哪个效率更高呢?
①如果使用的是MyISAM 存储引擎,则三者效率相同,都是O(1)
②如果使用的是InnoDB 存储引擎,则三者效率:COUNT(*) = COUNT(1)> COUNT(字段)
2.?sum 求和
sum可以取得某一个列的和,null会被自动忽略!
(1)取得薪水的合计
select sum(sal) from emp;
?(2)取得津贴的合计
select sum(comm) from emp;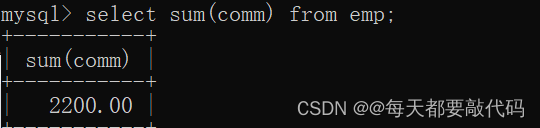 ()?
()?
(3)?取得总薪水的合计(sal+comm);ifnull()空处理函数的使用
select sum(sal+comm) from emp;
从结果上看,明显不对;?原因在于comm字段有null值,最终sal+comm结合在一块的一行的结果就是null,sum会忽略掉,正确的做法是将comm字段转换成0
重点:只要有NULL参与的运算结果一定是NULL,NULL+数=NULL;这就需要ifnull() 空处理函数:ifnull(可能为NULL的数据,被当做什么处理) : 属于单行处理函数;例如:IFNULL(comm,0)
select sum(sal+IFNULL(comm,0)) from emp;
(4)计算每个员工的年薪
select ename,(sal+comm)*12 as yearsal from emp; --错误写法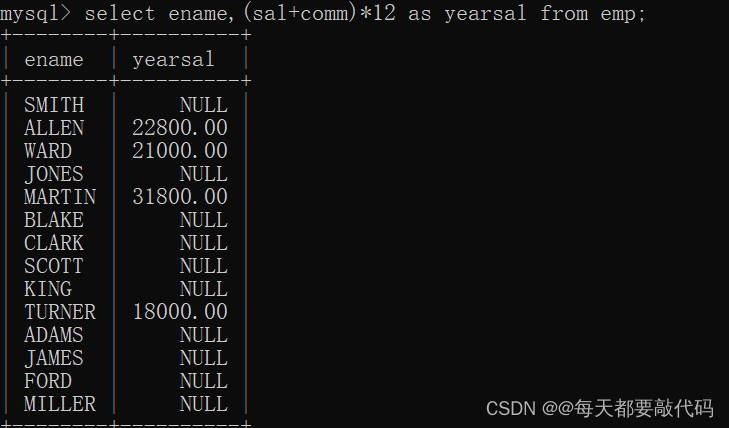
我们发现有些人的年薪居然是NULL,明显是不符合逻辑的;主要原因在于有些人的津贴comm为NULL;数据+NULL,在数据库中最终会看成NULL处理!?
select ename,(sal+IFNULL(comm,0))*12 as yearsal from emp; -- 正确写法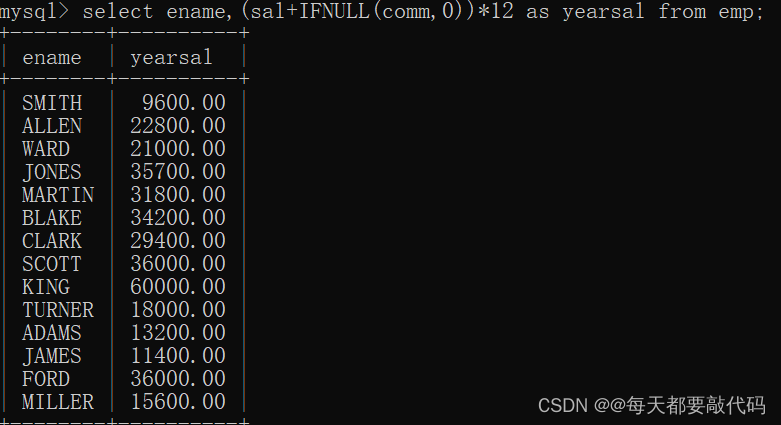
3.?avg 平均值
取得某一列的平均值,null会被自动忽略!
(1)取得平均薪水
select avg(sal) from emp;
(2)找出工资高于平均工资的员工
select ename,sal from emp where sal > avg(sal); -- 错误写法
-- ERROR 1111 (HY000): Invalid use of group function,无效的使用了分组函数原因:SQL语句当中有一个语法规则,分组函数不可直接使用在where子句当中!
解释:group by是在where执行之后才执行;分组函数avg必须在分完组才能用,而where的时候group by还没有执行,还没有分组,不能用分组函数!
select 5
..
from 1
..
where 2 --第一次的过滤
.. --这里不能直接使用分组函数
group by 3 --分组,先分组才能使用分组函数
..
having 4 --第二次的过滤
..
order by 6
..再例如:select ename,sal from emp where avg(sal) ; 错误的用法,虽然默认会有一个group by,但是它的执行需要在where执行完成之后,才会默认执行!此时在where avg(sal)后面直接使用分组函数,并没有先分组,是错误的用法!
第一步:找出平均工资
select avg(sal) from emp;
第二步:找出工资高于平均工资的员工
select ename,sal from emp where sal > 2073.214286;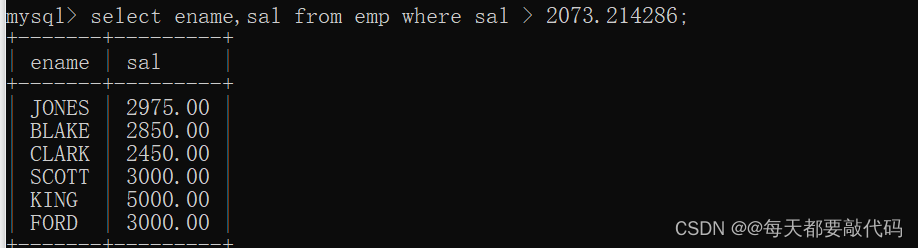
第三步:两个SQL语句联合使用
select ename,sal from emp where sal > (select avg(sal) from emp); --正确写法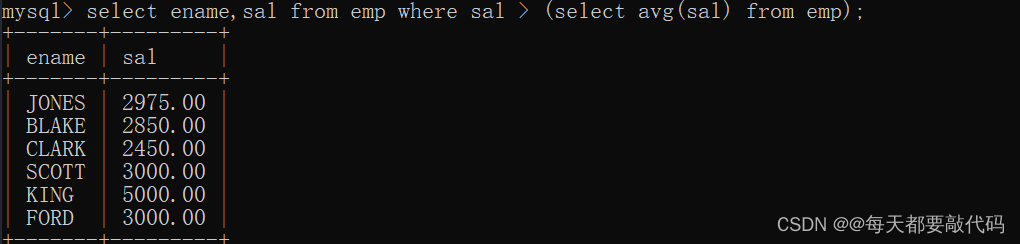
(3)avg = sum / count恒成立
这个公式是恒成立的,avg、sum、count都是提出NULL后得结果!
SELECT AVG(comm),SUM(comm)/COUNT(comm),SUM(comm)/COUNT(*)
FROM emp;执行结果:

?
?
4. max 最大值
取得某个一列的最大值,null会被自动忽略!
(1)取得最高薪水
select max(sal) from emp;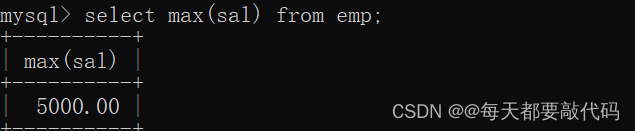
?(2)取得最晚入职得员工,hiredate表示入职时间
select max(str_to_date(hiredate,'%Y-%m-%d')) from emp;
select max(hiredate) from emp; --原表就是标准格式,str_to_date不用也行
5. min 最小值
取得某个一列的最小值,null会被自动忽略!
(1)取得最低薪水
select min(sal) from emp;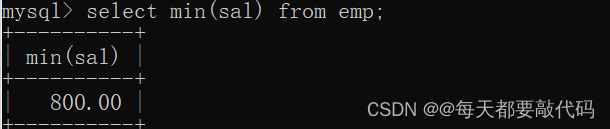
?(2)取得最早入职得员工
select min(str_to_date(hiredate, '%Y-%m-%d')) from emp;
(3)组合查询:可以将上述这些分组函数都放到select中一起使用
select count(*),sum(sal),avg(sal),max(sal),min(sal) from emp;
补充关键字:distinct(剔重)
(1)查看所有的工作
select job from emp;
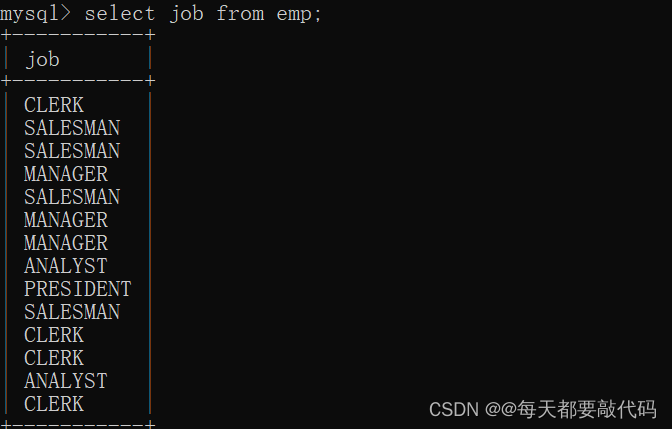
?查出来有14种结果,有很多重复的,利用distinct关键字就可以进行剔重!
select distinct job from emp;
(2)distinct只能出现在所有字段的最前面,表示后面的字段联合去重!
为什么只能出现所有字段的最前面?因为一个字段使用distinct,一个字段不使用,就会导致联合查询出来的数据无法一一对应匹配!
select ename,distinct job from emp; --错误语法
-- ename查询的结果是14条,distinct job 查询的结果是5条,根本无法匹配
-- 所以,distinct只能出现在所有字段的最前面不使用distinct:
select deptno,job from emp order by deptno;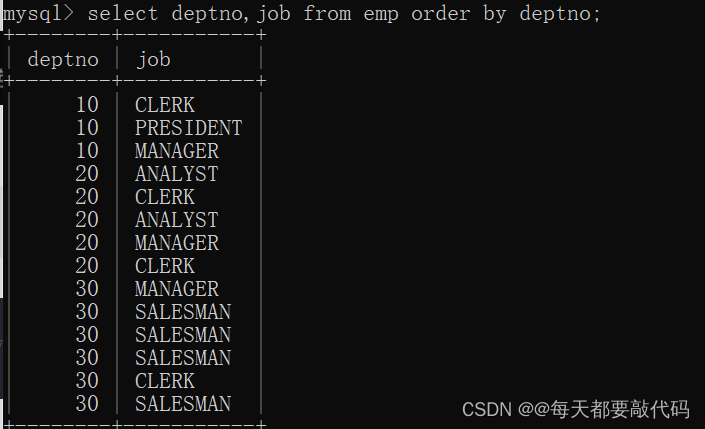
使用distinct对deptno和job联合剔重:
select distinct deptno,job from emp order by deptno;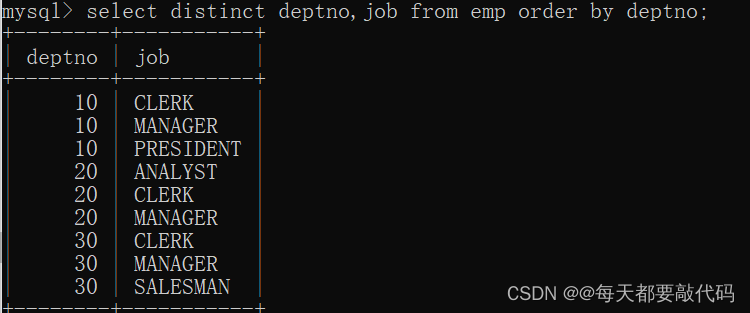
(3)取得工作岗位的种类
select count(distinct job) from emp;不进行剔重:
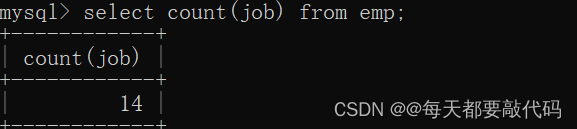
进行剔重:

二 :分组查询
分组查询主要涉及到两个子句,分别是:group by和having
①group by : 按照某个字段或者某些字段进行分组(名字相同的为一组)。
②having :having是对分组之后的数据进行再次过滤。
1.?group by
注意:分组(聚合)函数一般都会和group by联合使用!任何一个分组函数(count sum avg max min)都是在group by语句执行结束之后才会执行;当一条sql语句没有group by的话,整张表的数据会自成一组。
(1)找出每个工作岗位的最高薪资
先查看所有岗位的信息:
select * from emp;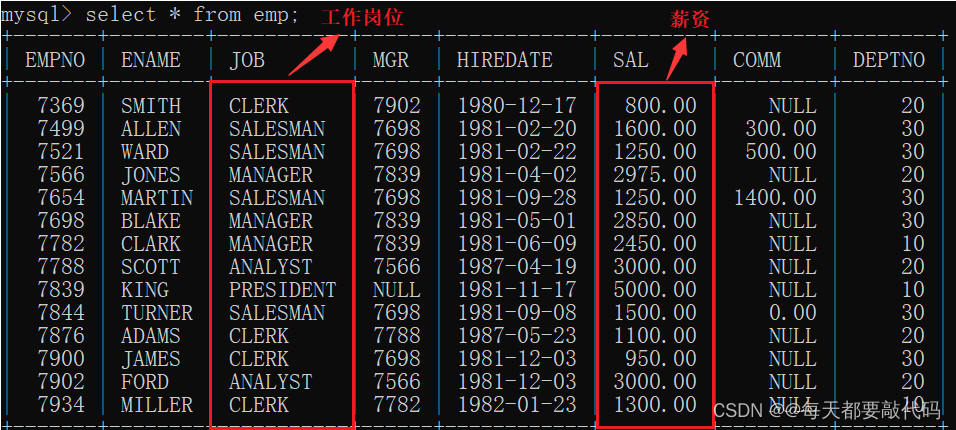
找到所有岗位里的最高薪资:
找出每个工作岗位的最高薪资,这就要先对每个岗位分组,然后找到每个组里的最大值:
select job,max(sal) from emp group by job;
-- 先执行group by进行分组,然后才会执行max(sal)找每组里的最大值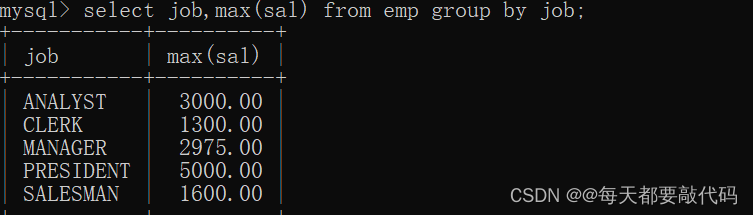
(2)取得每个工作岗位的工资合计,要求显示岗位名称和工资合计
select job, sum(sal) from emp group by job;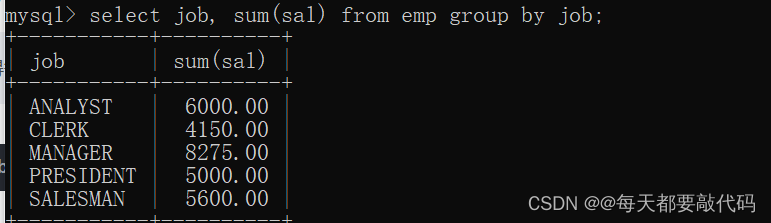
?如果再使用order by进行排序,则order by必须放到group by后面;例如:
select job, sum(sal) from emp group by job order by job;?以下是多个字段联合起来一块分组
?(3)找出每个部门不同工作岗位的最高薪资。?(两个字段进行分组)
如果多个字段进行分组,优先根据第一个字段分组,第一个字段相同在根据第二个字段进行分组,依次类推!?
select deptno,job,max(sal) from emp group by deptno,job;
--两个字段进行分组,先根据部分进行分组,部门相同在根据工作岗位分组? 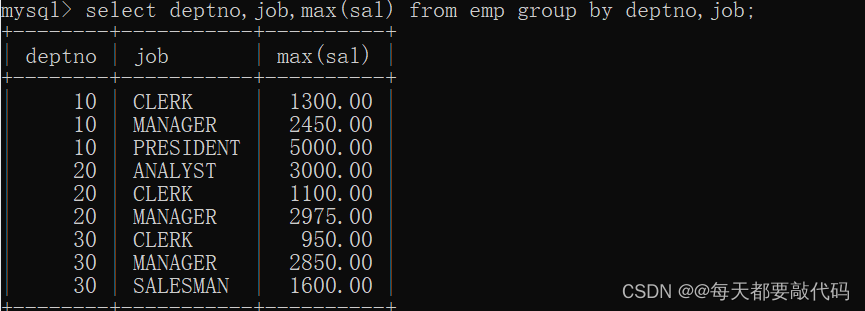
(4)按照工作岗位和部门编码分组,取得的工资合计
注:先按照job再按照deptno和先按照deptno再按照job最终的结果是相同的,只不过展示的顺序不同而已!
select job,deptno,sum(sal) from emp group by job,deptno;
select deptno,job,sum(sal) from emp group by deptno,job;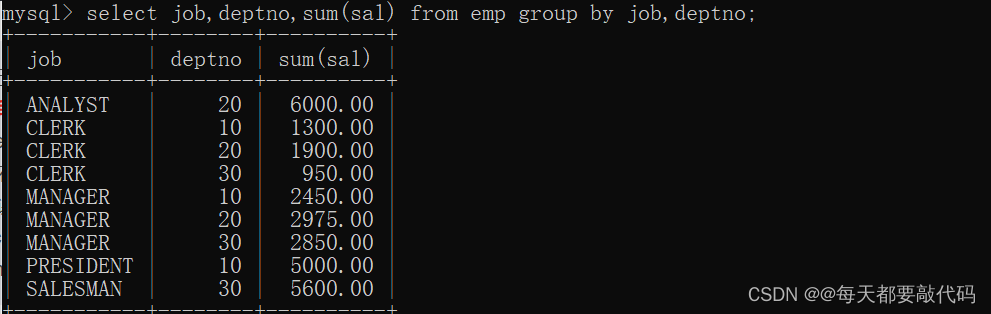
(5)规则:当一条语句中有group by的话,select后面只能跟“分组函数” 和"参与分组的字段"!
例如:查看每个工作岗位中工资最高的
select max(sal),job from emp group by job;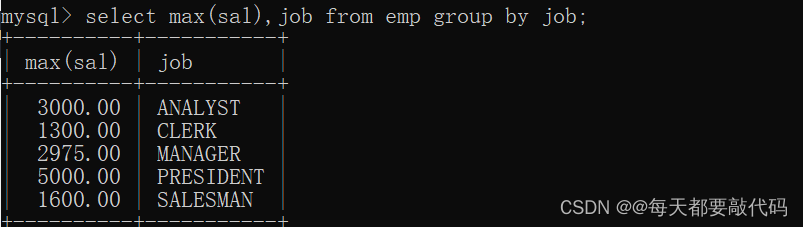
我们在加上名字ename字段:select ename,max(sal),job from emp group by job;以上在mysql当中,查询结果是有的,但是结果没有意义,在Oracle数据库当中会报错,语法错误。Oracle的语法规则比MySQL语法规则严谨。
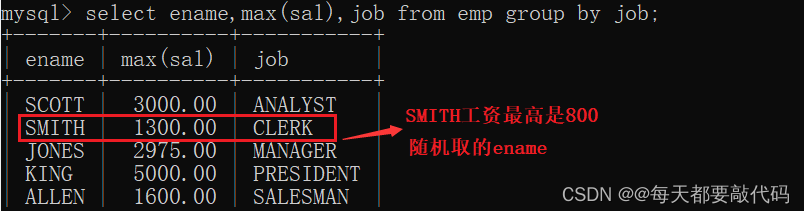
(6)MySQL8的新特性WITH ROLLUP?
MySQL中GROUP BY中使用WITH ROLLUP,表示把整体的数据在求平均值!?
SELECT deptno,AVG(sal)
FROM emp e
GROUP BY deptno; ?
?
使用WITH ROLLUP,此时会多一行数据,表示所有部门加在一起的平均值
select deptno,avg(sal)
from emp e
group by deptno with rollup;
注:当使用WITH ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即WITH ROLLUP和ORDER BY是互相排斥的。?
2. having
如果想对分组数据再进行过滤需要使用having子句;也可以使用where!
注:使用where效率较高,因为where会提前缩小范围!使用where解决不了的,在使用having!
(1)找出每个部门的最高薪资,要求显示薪资大于2900的数据。【having 和 where 都可】
?第一种方法:使用having过滤;先分组,再把小于2900的过滤掉;效率较低
select deptno,max(sal) from emp group by deptno having max(sal)>2900;
-- 先进行分组,分组以后在每一组例筛选max(sal) > 2900的
第二种方法:使用where过滤;先使用where过滤掉小于2900的数据,再分组;效率较高
select deptno,max(sal) from emp where sal > 2900 group by deptno;
-- 直接先使用where过滤掉sal < 2900的,数据减少很多;在进行分组,效率较高
总结:where就是不管其它的,上来先把不符合条件的过滤掉,在执行其它的条件,处理的数据开始就变少了;having是上来直接处理全部数据,然后一步步执行其它的条件!?
(2)找出每个部门的平均薪资,要求显示薪资大于2000的数据【只能使用having】
第一种方法:使用having过滤,可以
select deptno, avg(sal) from emp group by deptno having avg(sal) >2000;
第二种方法:使用where过滤,不可以;avg数据是要先通过整体的数据计算获得的数据,where后面只能写成avg(sal),而where后面又不能直接跟分组函数
select deptno,avg(sal) from emp where avg(sal) > 2000 group by deptno;
-- where后面不能使用分组函数,只能使用having3.?Where和Having的对比
(1)从适用范围上来讲,HAVING的适用范围更广。如果过滤条件中使用了聚合函数,则必须使用HAVING来替换WHERE。否则报错。?
(2)如果过滤条件中没有聚合函数:既可以使用WHERE也可以使用HAVING,这种情况下,WHERE的执行效率要高于HAVING。
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选
????????这决定了,在需要对数据进行分组统计的时候,HAVING 可以完成 WHERE 不能完成的任务。这是因为, 在查询语法结构中,WHERE 在 GROUP BY 之前,所以无法对分组结果进行筛选。HAVING 在 GROUP BY 之 后,可以使用分组字段和分组中的计算函数,对分组的结果集进行筛选,这个功能是 WHERE 无法完成 的。另外,WHERE排除的记录不再包括在分组中。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选
????????这一点,就决定了在关联查询中,WHERE 比 HAVING 更高效。因为 WHERE 可以先筛选,用一 个筛选后的较小数据集和关联表进行连接,这样占用的资源比较少,执行效率也比较高。HAVING 则需要 先把结果集准备好,也就是用未被筛选的数据集进行关联,然后对这个大的数据集进行筛选,这样占用 的资源就比较多,执行效率也较低。
小结:

开发中的选择:??
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点。当数据量特别大的时候,运行效率会有很大的差别!
?
三:DQL语句执行顺序总结
一个完整的select语句格式如下:
| select 字段? DISTINCT? 6 from 表名? ? ? ? ? ? ? ? ? ? ? 1 join....on....? ? ? ? ? ? ? ? ? ? 2?多表的连接条件 where …….? ? ? ? ? ? ? ? ? 3? (第一次过滤)? ?不包含聚合函数的过滤条件 group by ……..? ? ? ? ? ? ?4 having …….? ? ? ? ? ? ? ? ?5?(第二次过滤:就是为了过滤分组后的数据而存在的,不可以单独的出现)包含聚合函数的过滤条件 order by ……..? ? ? ? ? ? ? 7 limit........? ? ? ? ? ? ? ? ? ? ? ?8 |
以上语句的执行顺序:FROM ...,...->JOIN ON -> (LEFT/RIGNT ?JOIN) -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT ->?ORDER BY -> LIMIT
①首先执行where语句过滤原始数据;第一次过滤
②执行group by进行分组;
③执行having对分组数据进行操作;第二次过滤
④执行select选出数据;
⑤最后执行order by排序;
原则:能在where中过滤的数据,尽量在where中过滤,效率较高。having的过滤是专门对分组之后的数据进行过滤的!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ‘cnpm‘ 不是内部或外部命令,也不是可运行的程序
- Prometheus C++使用教程
- 【XR806开发板试用】FreeRTOS创建任务测试
- 数据结构之<堆>的介绍
- 解决Reinitialized existing Git repository
- 详细分析MybatisPlus中的orderBy、orderByDesc、orderByAsc函数
- wangeditor v4版本,基于vue3项目,实现动态拉伸编辑区大小
- 新年钜惠|泰迪智能科技免费协助企业完成3个行业AI案例建模
- 有关ruoyi 项目菜单框如何设置国际化----附上完整代码
- 在 MacOS 中安装