python中parsel模块的css解析
发布时间:2024年01月06日
一、爬虫页面分类
1.想要爬取的内容全部在标签中,可以使用xpath去进行解析如下图

2.想要爬取的内容呈现json的数据特征,用.json()转换为字典格式
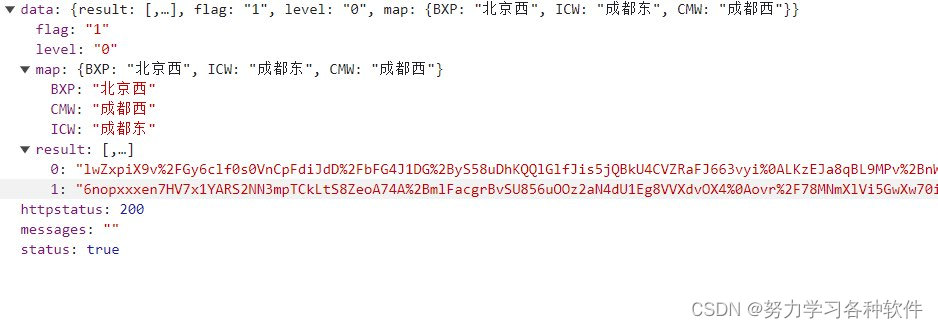
3.页面不规则,标签中包含大括号,如下面想要获取键值内容怎么做,先用re正则获取大括号内容,再转换为json格式


4.想要爬取的页面数据很零散,建议使用css选择器,如下图,想要猫咪的年龄,品种,是否接种疫苗,是否支持视频看猫等信息

二、css解析步骤:
import parsel
html_data = requests.get(url,headers).text
selector = parsel.Selector(html_data)
content = selector.css('css格式')
实例化一个selector对象?
css格式总结:
.代表class? #代表id? ::text 表示输出文本(即尖括号里面的内容) nth-child(page)表示匹配第page项? ??
例子:
div 返回的是全部div标签
div.content 返回的是class = 'content'的整个div标签
div.content? #su 返回的是class = 'content'的整个div标签下id = 'su'的标签
div.content li 返回的是class = 'content'的整个div标签下的li标签
div.content li:nth-child(1)返回的是class = 'content'的整个div标签下的li标签中的第一个li标签
div.content li:nth-child(1)::text返回的是class = 'content'的整个div标签下的li标签中的第一个li标签中的文本数据
div.content li:nth-child(1)::attr(href)返回的是class = 'content'的整个div标签下的li标签中的第一个li标签,其中的href所对应的属性值
selector.css('css样式').get() 获得一个匹配的
selector.css('css样式').getall()获得多个匹配的
可以在开发者工具中尝试:
定位要爬取的数据,在elements中ctrl+f出现
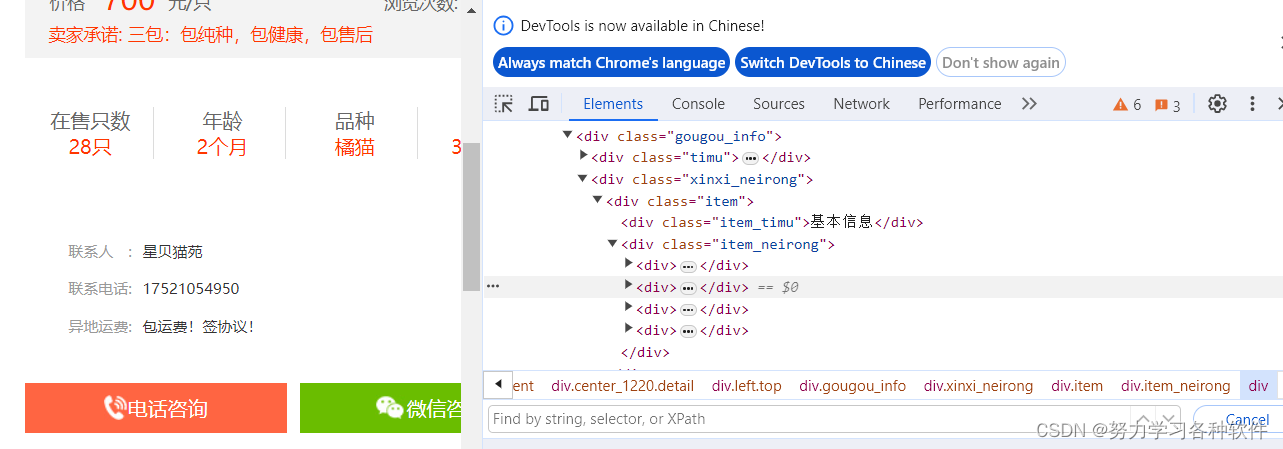
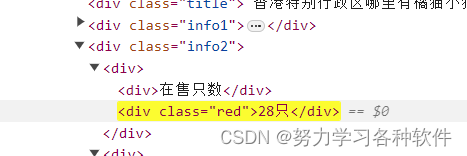
如想爬取在售只数应该怎么写:
import parsel
import requests
url = 'http://maomijiaoyi.com/index.php?/chanpinxiangqing_1038711.html'
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
}
response = requests.get(url=url,headers=headers)
response.encoding = response.apparent_encoding
selector = parsel.Selector(response.text)
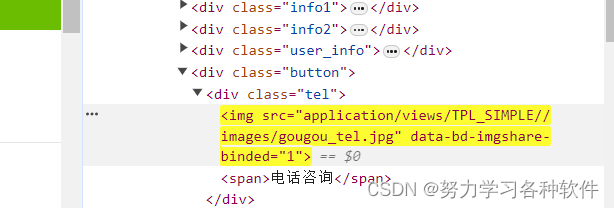
num = selector.css('.info2 div:nth-child(1) div.red::text').get()# 获取在售只数获得下图src的属性值:
 ?
?
src = selector.css('div.button div.tel img::attr(src)').get()?注意,编写css时,要像树一样,一层一层找,不能跳的太远,否则会出错
?三、在selenimu中用css选择器:代码展现
from selenium import webdriver
import parsel
import requests
path = 'chromedriver.exe'
broswer = webdriver.Chrome(path)
url = 'http://maomijiaoyi.com/index.php?/chanpinliebiao_c_2.html'
headers = {'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
}
broswer.get(url)
for page in range(1,25):
selector = broswer.find_element_by_css_selector(f'#content > div.breeds_floor > div > div > a:nth-child({page}) > div.img > img')
url = selector.get_attribute('src')
print(url)
'''
筛选标签,与css语法一致,不会可以复制,以selector方式复制。find_element_by_css_selector返回的是一个标签,find_elements_by_css_selector返回的是多个标签
获取标签的属性值用selector.get_attribute方法
'''
lis = browser.find_elements_by_css_selector('.Content li') # 获取class=Content的ul的下面所有的li标签
for li in lis:
bs = li.find_elements_by_css_selector('b') # 在li标签中找b标签
for b in bs:
print(bs.text)# 获取b标签的文本值
文章来源:https://blog.csdn.net/m0_57265868/article/details/135430094
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 顺序结构复习
- 阿里云2核4G服务器ecs.e-c1m2.large价格和性能测评
- 设计模式之避免共享的设计模式Immutability(不变性)模式
- vue使用elementui 的 table且自定义某列表头时,添加的点击事件和自带的筛选功能有类似冒泡行为
- 卷积层里的多输入与多输出通道(channel)
- 基于SpringBoot的物流管理系统
- 【HHO三维路径规划】哈里斯鹰算法无人机避障三维航迹规划【含Matlab源码 3780期】
- 全面指南:技术写作与编辑工具 Markdown、Git 研究工具
- 无心剑中译梭罗《低垂的云》
- 精品基于Uniapp+Springboot宠物用品服务销售管理系统App