大模型中的LM-BFF
LM-BFF
paper: 2020.12 Making Pre-trained Language Models Better Few-shot Learners
Prompt: 完形填空自动搜索prompt
Task: Text Classification
Model: Bert or Roberta
Take Away: 把人工构建prompt模板和标签词优化为自动搜索
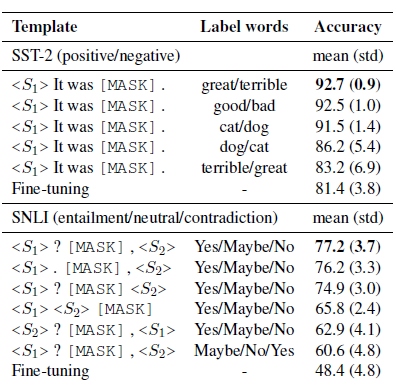
LM-BFF是陈丹琦团队在20年底提出的针对few-shot场景,自动搜索模板和触发词的Prompt方案,prompt模板延续了PET的完型填空形式,把人工构建prompt和标签词的构建优化成了自动搜索。论文先是验证了相同模板不同标签词,和相同标签词不同模板对模型效果都有显著影响,如下
以下介绍自动搜索的部分
标签词搜索
考虑在全vocab上搜索标签词搜索空间太大,在少量样本上直接微调选择最优的标签词会存在过拟合的问题。作者先通过zero-shot缩小候选词范围,再通过微调选择最优标签词。
如下,固定prompt模板(L),作者用训练集中每个分类(c)的数据,在预训练模型上分别计算该分类下MASK词的概率分布,选择概率之和在Top-k的单词作为候选词。再结合所有分类Top-K的候选词,得到n个标签词组合。这里的n和k都是超参,在100~1000不等。
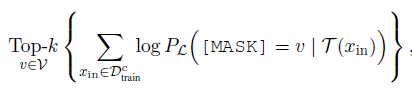
然后在n个候选标签词组合中,针对微调后在验证集的准确率,选择效果最好的标签词组合。
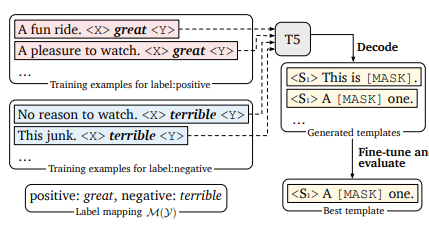
prompt模板搜索
固定标签词,作者使用T5来进行模板生成,让T5负责在标签词前、后生成符合上下文语义的prompt指令,再在所有训练样本中选择整体表现最优的prompt模板。
如下, 固定二分类的标签词是great和terrible,T5的模型输入为Input+MASK+标签对应标签词+MASK,让模型来完成对MASK部分的填充。现在预训练模型中通过Beam-Search得到多个模板,再在下游任务中微调得到表现最好的一个或多个prompt模板
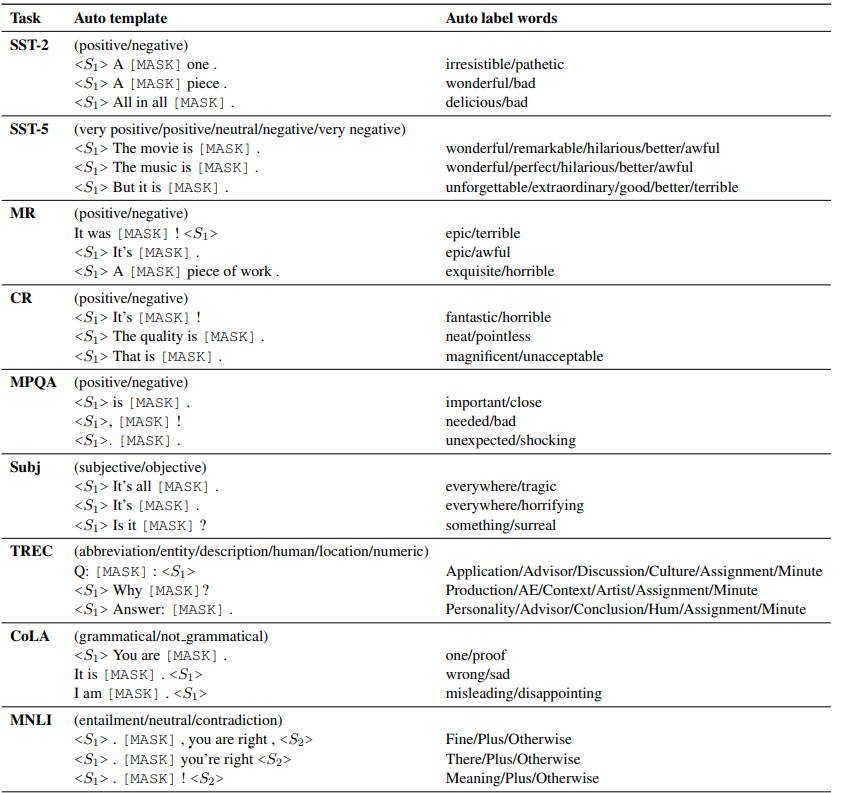
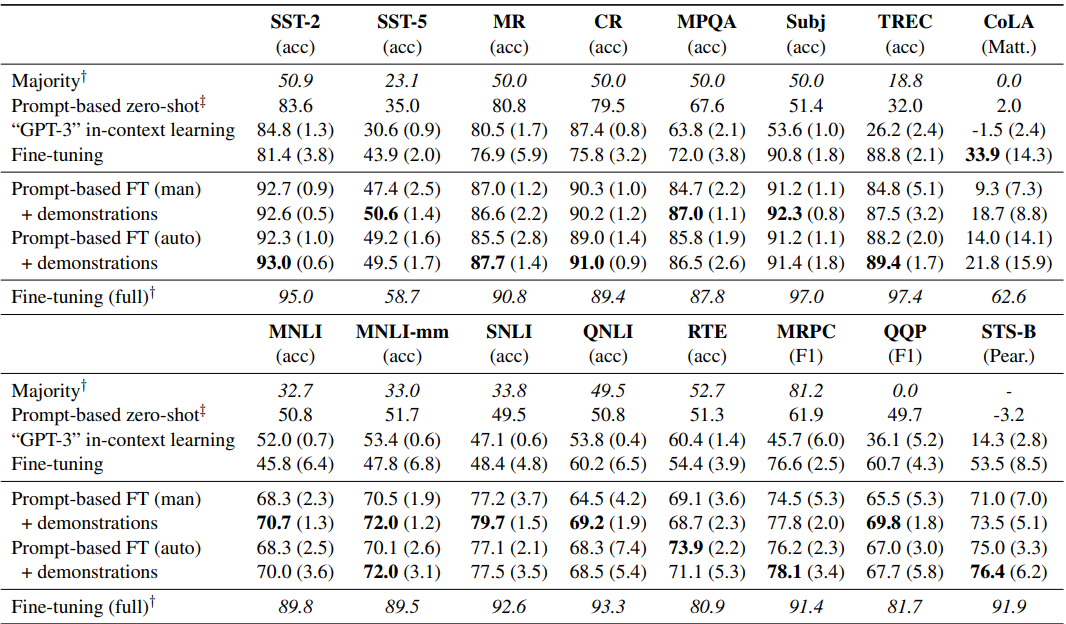
以上自动搜索prompt和标签词得到的部分结果如下,该说不说这种方案得到的标签词,至少直观看上去比AutoPrompt合(人)理(类)不(能)少(懂):
固定prompt微调LM

经过以上搜素得到最优标签词组合和prompt模板后,作者的微调过程模仿了GPT3的few-shot构建方式。如上图,先把输入填充进prompt模板,再从各个分类中各采样1个样本作为指令样本拼接进输入,为待预测文本补充更丰富的上下文,一起输入模型。在训练和推理时,补充的指令样本都是从训练集中采样。
同时为了避免加入的指令样本和待预测样本之间差异较大,导致模型可能直接无视接在prompt后面的指令样本,作者使用Sentence-Bert来筛选语义相似的样本作为指令样本。
效果上,作者给出了每类采样16个样本的小样本场景下, Roberta-Large的效果,可以得到以下insights
-
部分场景下自动模板是要优于手工模板的,整体上可以打平,自动搜索是人工成本的平价替代
-
加入指令样本对效果有显著提升
-
在16个样本的few-shot场景下,prompt微调效果是显著优于常规微调和GPT3 few-shot效果的
Google: Flan
paper: 2021.9 Finetuned Langauge Models are zero-shot learners
模型:137B LaMDA-PT
一言以蔽之:抢占先机,Google第一个提出指令微调可以解锁大模型指令理解能力
谷歌的Flan是第一个提出指令微调范式的,目的和标题相同使用指令微调来提升模型的zero-shot能力。论文使用的是137B的LAMDA-PT一个在web,代码,对话, wiki上预训练的单向语言模型。
指令集
在构建数据集上,谷歌比较传统。直接把Tensorflow Dataset上12个大类,总共62个NLP任务的数据集,通过模板转换成了指令数据集
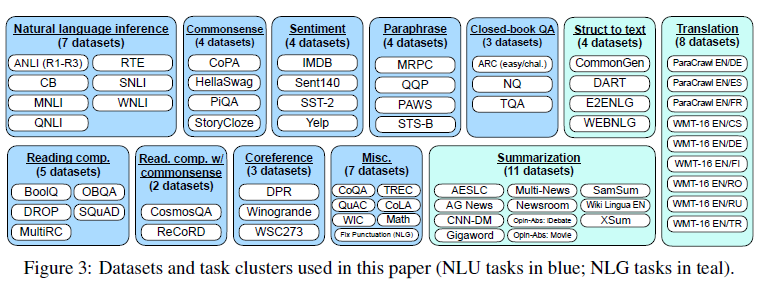
为了提高指令数据集的多样性,每个任务,会设计10个模板,所以总共是620个指令,并且会有最多3个任务改造模板。所谓的任务改造就是把例如影评的情感分类任务,转化成一个影评生成任务,更充分的发挥已有标注数据构建更丰富的指令数据集。哈哈感觉这里充满了人工的力量。
为了保证数据集的多样性和均衡性,每个数据集的训练样本限制在3万,并且考虑模型对一个任务的适应速度取决于任务数据集大小,因此按使用数据集样本大小占比按比例采样混合训练。
效果
效果上137B的指令微调模型大幅超越GPT3 few-shot, 尤其是在NLI任务上,考虑NLI的句子对基本不会在预训练文本中自然作为连续上下句出现。而指令微调中设计了更自然地模板带来了大幅的效果提升。
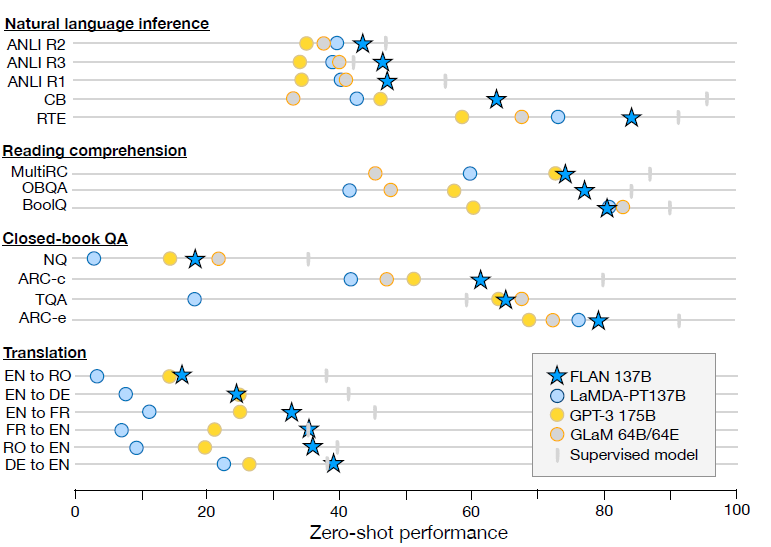
除了以上存在明显效果提升的任务,在一些任务本身就和指令相似的任务,例如常识推理和指代消歧任务,指令微调并不能带来显著的效果提升。
作者做了更多的消融实验,验证指令微调中以下几个变量
-
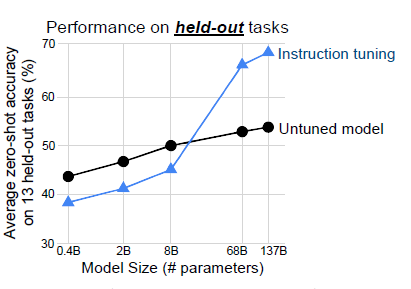
模型规模: 作者进一步论证了指令微调带来的效果提升存在明显的大模型效应,只有当模型规模在百亿左右,指令微调才会在样本外任务上带来提升。作者怀疑当模型规模较小时,在较多任务上微调可能会占用模型本就不多的参数空间,造成预训练时的通用知识遗忘,降低在新任务上的效果。
-
多任务影响: 考虑指令微调是在多任务上进行,作者希望剔除指令微调中多任务微调带来的影响。因此尝试进行多任务非指令微调(使用数据集名称代替指令),效果上指令微调显著更优,说明指令模板的设计确实存在提升模型指令理解力的效果。
-
few-shot: 除了zero-shot,Flan同时验证了few-shot的效果。整体上few-shot的效果优于zero-shot。说明指令微调对few-shot也有效果提升。
-
结合prompt-tunning 既然指令微调提升模型对指令的理解能力,作者认为应该对进一步使用soft-prompt也应该有提升。因此进一步使用了prompt-tunning对下游任务进行微调,不出意外Flan比预训练LaMDA的效果有显著的提升。
BigScience: T0
paper: 2021.10 Multitask prompted training enables zero-shot task generation
Model: 11B T5-LM
一言以蔽之: Flan你想到的我也想到了! 不过我的指令数据集更丰富多样
T0是紧随Flan发布的论文,和FLan对比有以下以下几个核心差异:
-
预训练模型差异:Flan是Decoder-only, T0是Encoder-Decoder的T5,并且考虑T5的预训练没有LM目标,因此使用了prompt-tunning中以LM任务继续预训练的T5-LM
-
指令多样性:T0使用的是PromptSource的数据集,指令要比Flan更丰富
-
模型规模:Flan在消融实验中发现8B以下指令微调效果都不好,而3B的T0通过指令微调也有效果提升。可能影响是En-Dn的预训练目标差异,以及T0的指令集更多样更有创意
-
样本外泛化任务: Flan为了验证指令微调泛化性是每次预留一类任务在剩余任务训练,训练多个模型。T0是固定了4类任务在其余任务上微调
下面我们细说下T0的指令数据和消融实验
指令集
T0构建了一个开源Prompt数据集P3(Public Pool of Prompts),包括173个数据集和2073个prompt。从丰富程度上比Flan提升了一整个数量级,不过只包含英文文本,更多数据集的构建细节可以看PromptSource的论文。
作者在指令集的多样性上做了2个消融实验
-
指令集包括的数据集数: 在T0原始指令集的基础上,作者分别加入GPT-3的验证集,以及SuperGLUE,训练了T0+和T0++模型。在5个hold-out任务上,更多的数据集并不一定带来效果的提升,并且在部分推理任务上,更多的数据集还会带来spread的上升(模型在不同prompt模板上表现的稳定性下降)
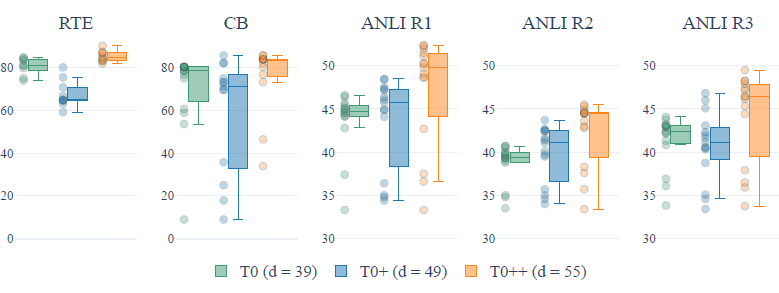
-
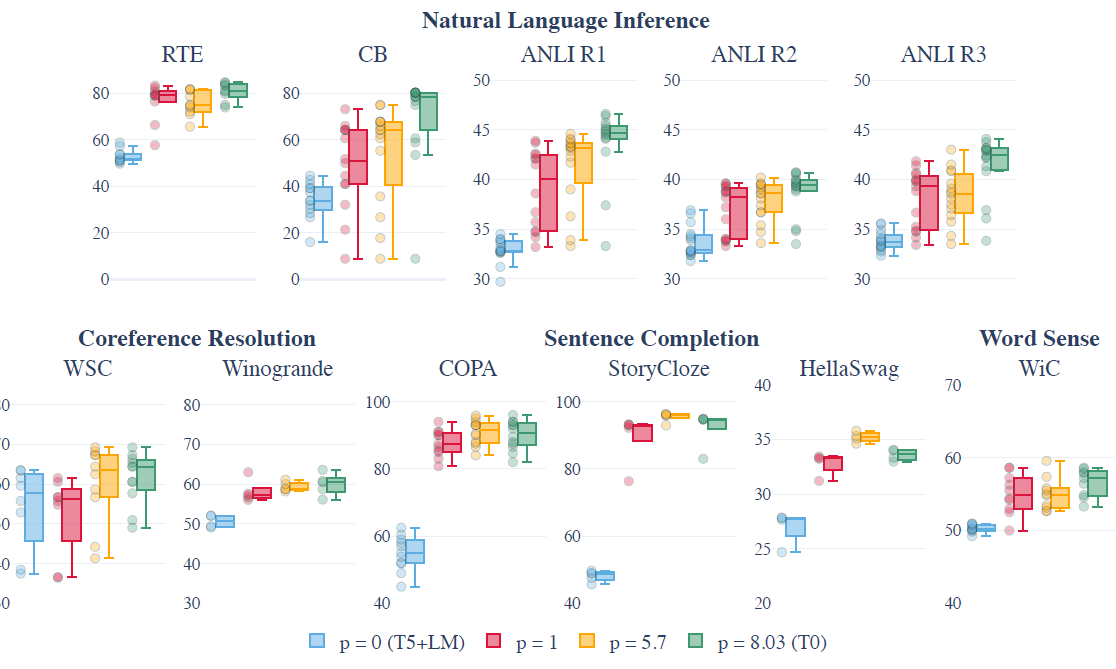
每个数据集的prompt数(p):通过每个数据集采样不同数量的prompt进行训练,作者发现随prompt数提升,模型表现的中位数会有显著提升,spread存在不同程度的下降,不过看起来存在边际递减的效应。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于Linux系统的相关试题——附答案
- GSP算法在数据挖掘中的应用
- 安达发|APS计划排产排程排单软件功能解析
- 安装vcenter7.0问题汇总
- 读写锁ReentrantReadWriteLock的原理
- WEB 3D技术 three.js 通过分组顶点 给同一个物体设置多个材质
- PCL 大地坐标转空间直角坐标(C++详细过程版)
- 服务器大量time_wait影响性能,如何解决
- 实现3x3卷积的手写FIFO
- 11K star! 这款开源神器帮你省下XX音乐的会员费